 谷歌最便宜TPU值不值得買?TPU在執行神經網絡計算方面的優勢
谷歌最便宜TPU值不值得買?TPU在執行神經網絡計算方面的優勢

谷歌本月推出千元級搭載Edge TPU芯片的開發板,性能令人期待。本文以可視化圖形的方式,對比TPU、GPU和CPU,解釋了TPU在執行神經網絡計算方面的優勢。
谷歌最便宜 TPU 值不值得買?
谷歌 Edge TPU 在本月初終于公布價格 —— 不足 1000 元人民幣,遠低于 TPU。
實際上,Edge TPU 基本上就是機器學習的樹莓派,它是一個用 TPU 在邊緣進行推理的設備。
Edge TPU(安裝在 Coral 開發板上)
云 vs 邊緣
Edge TPU顯然是在邊緣(edge)運行的,但邊緣是什么呢?為什么我們不選擇在云上運行所有東西呢?
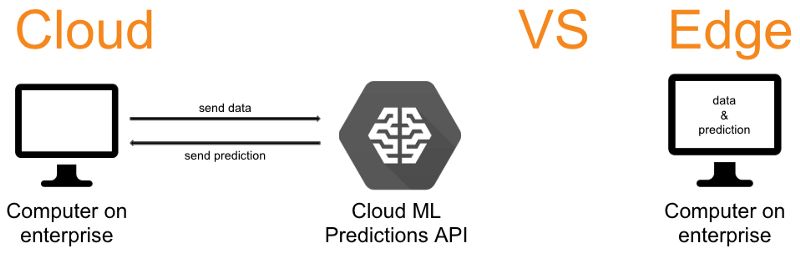
在云中運行代碼意味著你使用的CPU、GPU和TPU都是通過瀏覽器提供的。在云中運行代碼的主要優點是,你可以為特定的代碼分配必要的計算能力(訓練大型模型可能需要大量的計算)。
邊緣與云相反,意味著你是在本地運行代碼(也就是說你能夠實際接觸到運行代碼的設備)。在邊緣運行代碼的主要優點是沒有網絡延遲。由于物聯網設備通常要頻繁地生成數據,因此運行在邊緣上的代碼非常適合基于物聯網的解決方案。
對比 CPU、GPU,深度剖析 TPU
TPU(Tensor Processing Unit, 張量處理器)是類似于CPU或GPU的一種處理器。不過,它們之間存在很大的差異。最大的區別是TPU是ASIC,即專用集成電路。ASIC經過優化,可以執行特定類型的應用程序。對于TPU來說,它的特定任務就是執行神經網絡中常用的乘積累加運算。CPU和GPU并未針對特定類型的應用程序進行優化,因此它們不是ASIC。
下面我們分別看看 CPU、GPU 和 TPU 如何使用各自的架構執行累積乘加運算:
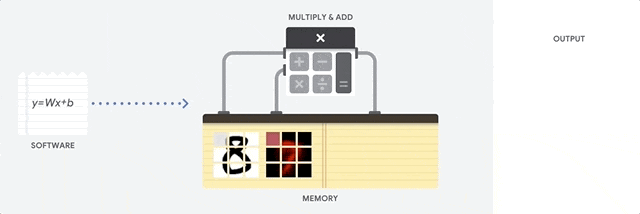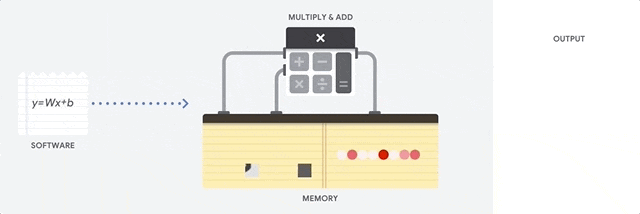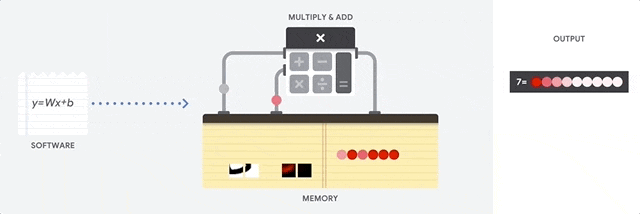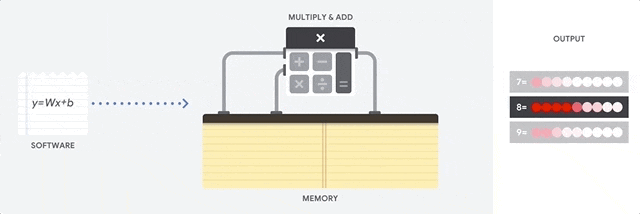
在 CPU 上進行累積乘加運算
CPU 通過從內存中讀取每個輸入和權重,將它們與其 ALU (上圖中的計算器) 相乘,然后將它們寫回內存中,最后將所有相乘的值相加,從而執行乘積累加運算。
現代 CPU 通過其每個內核上的大量緩存、分支預測和高時鐘頻率得到增強。這些都有助于降低 CPU 的延遲。

GPU 上的乘積累加運算
GPU 的原理類似,但它有成千上萬的 ALU 來執行計算。計算可以在所有 ALU 上并行進行。這被稱為 SIMD (單指令流多數據流),一個很好的例子就是神經網絡中的多重加法運算。
然而,GPU 并不使用上述那些能夠降低延遲的功能。它還需要協調它的數千個 ALU,這進一步減少了延遲。
簡而言之,GPU 通過并行計算來大幅提高吞吐量,代價是延遲增加。或者換句話說:
CPU 是一個強大而訓練有素的斯巴達戰士,而 GPU 就像一支龐大的農民大軍,但農民大軍可以打敗斯巴達戰士,因為他們人多。

讀取 TPU 上的乘加操作的權重
TPU 的運作方式非常不同。它的 ALU 是直接相互連接的,不需要使用內存。它們可以直接提供傳遞信息,從而大大減少延遲。
從上圖中可以看出,神經網絡的所有權重都被加載到 ALU 中。完成此操作后,神經網絡的輸入將加載到這些 ALU 中以執行乘積累加操作。這個過程如下圖所示:

TPU 上的乘加操作
如上圖所示,神經網絡的所有輸入并不是同時插入 ALU 的,而是從左到右逐步地插入。這樣做是為了防止內存訪問,因為 ALU 的輸出將傳播到下一個 ALU。這都是通過脈動陣列 (systolic array) 的方式完成的,如下圖所示。
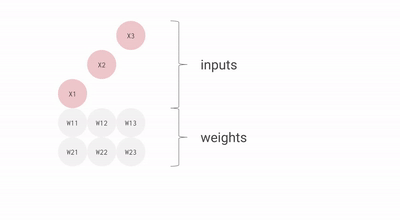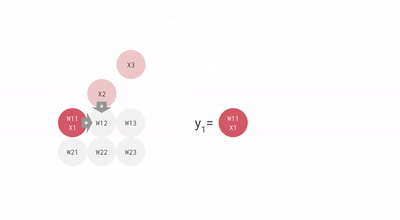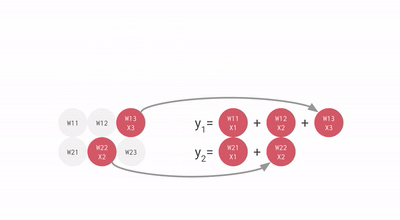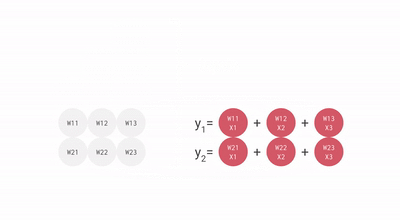
使用脈動陣列執行乘加操作
上圖中的每個灰色單元表示 TPU 中的一個 ALU (其中包含一個權重)。在 ALU 中,乘加操作是通過將 ALU 從頂部得到的輸入乘以它的權重,然后將它與從左編得到的值相加。此操作的結果將傳播到右側,繼續完成乘加操作。ALU 從頂部得到的輸入被傳播到底部,用于為神經網絡層中的下一個神經元執行乘加操作。
在每一行的末尾,可以找到層中每個神經元的乘加運算的結果,而不需要在運算之間使用內存。
使用這種脈動陣列顯著提高了 Edge TPU 的性能。
Edge TPU 推理速度超過其他處理器架構
TPU 還有一個重要步驟是量化 (quantization)。由于谷歌的 Edge TPU 使用 8 位權重進行計算,而通常使用 32 位權重,所以我們應該將權重從 32 位轉換為 8 位。這個過程叫做量化。
量化基本上是將更精確的 32 位數字近似到 8 位數字。這個過程如下圖所示:
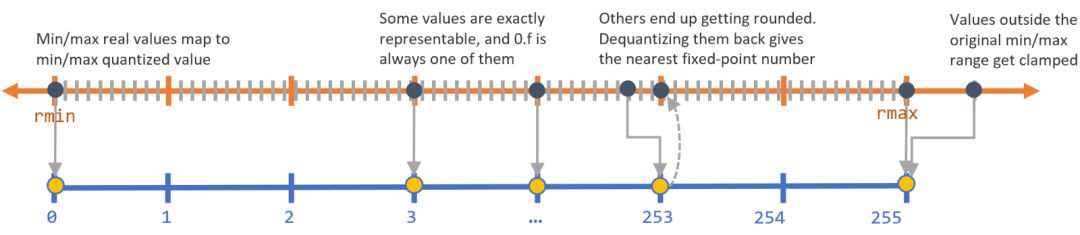
量化
四舍五入會降低精度。然而,神經網絡具有很好的泛化能力 (例如 dropout),因此在使用量化時不會受到很大的影響,如下圖所示。

非量化模型與量化模型的精度
量化的優勢更為顯著。它減少了計算量和內存需求,從而提高了計算的能源效率。
Edge TPU 執行推理的速度比任何其他處理器架構都要快。它不僅速度更快,而且通過使用量化和更少的內存操作,從而更加環保。
-
谷歌
+關注
關注
27文章
6254瀏覽量
111391 -
機器學習
+關注
關注
66文章
8553瀏覽量
136948 -
TPU
+關注
關注
0文章
170瀏覽量
21655
原文標題:一文讀懂:谷歌千元級Edge TPU為何如此之快?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI芯片大單!Anthropic從博通采購100萬顆TPU v7p芯片
神經網絡的初步認識

谷歌云發布最強自研TPU,性能比前代提升4倍

NMSIS神經網絡庫使用介紹
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
CICC2033神經網絡部署相關操作
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+神經形態計算、類腦芯片
神經網絡的并行計算與加速技術
神經網絡專家系統在電機故障診斷中的應用
神經網絡RAS在異步電機轉速估計中的仿真研究
基于FPGA搭建神經網絡的步驟解析

TPU處理器的特性和工作原理
Google推出第七代TPU芯片Ironwood
谷歌第七代TPU Ironwood深度解讀:AI推理時代的硬件革命




 工商網監
工商網監
評論