") 北大開源了一個(gè)中文分詞工具包,名為——PKUSeg
北大開源了一個(gè)中文分詞工具包,名為——PKUSeg

分詞技術(shù)是一種比較基礎(chǔ)的模塊,就英文而言,詞與詞之間通常由空格分開,因此英文分詞則要簡單的多,但中文和英文的詞是有區(qū)別的,再加上中國文化的博大精深,分詞的時(shí)候要考慮的情況比英文分詞要復(fù)雜的多,如果處理不好就會直接影響到后續(xù)詞性標(biāo)注、句法分析等的準(zhǔn)確性,
目前,我們最常用的分詞工具大概有四種哈工大LTP、中科院計(jì)算所NLPIR、清華大學(xué)THULAC和jieba。
不過最近,北大開源了一個(gè)中文分詞工具包,名為 ——PKUSeg,基于Python。據(jù)介紹其準(zhǔn)確率秒殺THULAC和結(jié)巴分詞等工具。
一經(jīng)開源,pkuseg已經(jīng)在GitHub上獲得1738個(gè)Star,244個(gè)Fork(GitHub地址:https://github.com/lancopku/PKUSeg-python)
pkuseg具有如下幾個(gè)特點(diǎn):
多領(lǐng)域分詞:不同于以往的通用中文分詞工具,此工具包同時(shí)致力于為不同領(lǐng)域的數(shù)據(jù)提供個(gè)性化的預(yù)訓(xùn)練模型。根據(jù)待分詞文本的領(lǐng)域特點(diǎn),用戶可以自由地選擇不同的模型。 我們目前支持了新聞領(lǐng)域,網(wǎng)絡(luò)文本領(lǐng)域和混合領(lǐng)域的分詞預(yù)訓(xùn)練模型,同時(shí)也擬在近期推出更多的細(xì)領(lǐng)域預(yù)訓(xùn)練模型,比如醫(yī)藥、旅游、專利、小說等等。
更高的分詞準(zhǔn)確率:相比于其他的分詞工具包,當(dāng)使用相同的訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù),pkuseg可以取得更高的分詞準(zhǔn)確率。
支持用戶自訓(xùn)練模型:支持用戶使用全新的標(biāo)注數(shù)據(jù)進(jìn)行訓(xùn)練。
各類分詞工具包的性能對比
前面有提到說pkuseg的準(zhǔn)確率遠(yuǎn)超其他分詞工具包,現(xiàn)在就是用數(shù)據(jù)說話的時(shí)候了,下面就是在 Linux 環(huán)境下,各工具在新聞數(shù)據(jù) (MSRA) 和混合型文本 (CTB8) 數(shù)據(jù)上的準(zhǔn)確率測試情況
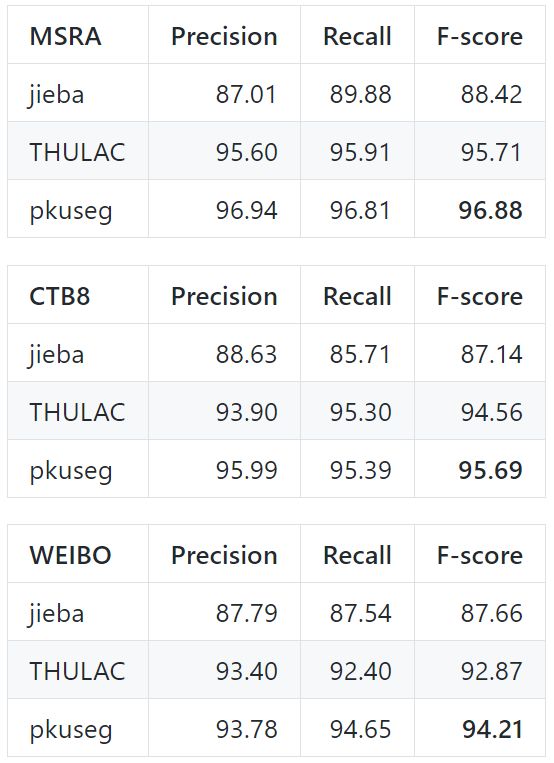
測試使用的是第二屆國際漢語分詞評測比賽提供的分詞評價(jià)腳本,從上圖看出結(jié)巴分詞準(zhǔn)確率最低,
跨領(lǐng)域測試結(jié)果
以下是在其它領(lǐng)域進(jìn)行測試,以模擬模型在“黑盒數(shù)據(jù)”上的分詞效果。
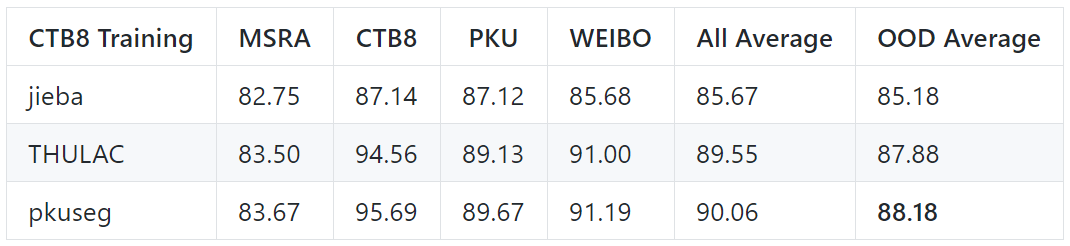
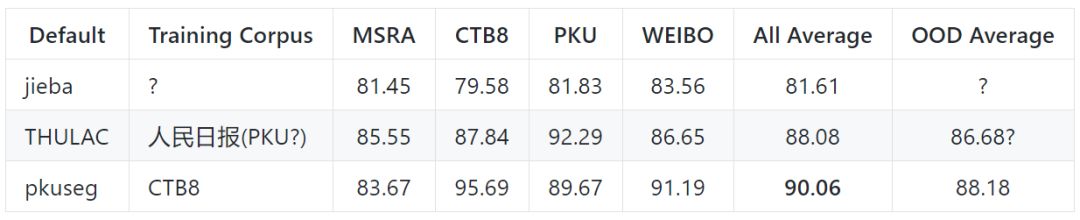
默認(rèn)模型在不同領(lǐng)域的測試效果
以下是各個(gè)工具包的默認(rèn)模型在不同領(lǐng)域的測試效果
使用方式
代碼示例1:使用默認(rèn)模型及默認(rèn)詞典分詞
importpkusegseg=pkuseg.pkuseg()#以默認(rèn)配置加載模型text=seg.cut('我愛北京***')#進(jìn)行分詞print(text)
代碼示例2:設(shè)置用戶自定義詞典
importpkuseglexicon=['北京大學(xué)','北京***']#希望分詞時(shí)用戶詞典中的詞固定不分開seg=pkuseg.pkuseg(user_dict=lexicon)#加載模型,給定用戶詞典text=seg.cut('我愛北京***')#進(jìn)行分詞print(text)
代碼示例3:使用其它模型
importpkusegseg=pkuseg.pkuseg(model_name='./ctb8')#假設(shè)用戶已經(jīng)下載好了ctb8的模型#并放在了'./ctb8'目錄下,通過設(shè)置model_name加載該模型text=seg.cut('我愛北京***')#進(jìn)行分詞print(text)
代碼示例4:對文件分詞
importpkusegpkuseg.test('input.txt','output.txt',nthread=20)#對input.txt的文件分詞輸出到output.txt中,#使用默認(rèn)模型和詞典,開20個(gè)進(jìn)程
代碼示例5:訓(xùn)練新模型
importpkuseg#訓(xùn)練文件為'msr_training.utf8'#測試文件為'msr_test_gold.utf8'#模型存到'./models'目錄下,開20個(gè)進(jìn)程訓(xùn)練模型pkuseg.train('msr_training.utf8','msr_test_gold.utf8','./models',nthread=20)
此外,pkuseg提供了三種在不同類型數(shù)據(jù)上訓(xùn)練得到的模型,根據(jù)具體需要,用戶可以選擇不同的預(yù)訓(xùn)練模型:
MSRA:在MSRA(新聞?wù)Z料)上訓(xùn)練的模型。
下載地址:https://pan.baidu.com/s/1twci0QVBeWXUg06dK47tiA
CTB8:在CTB8(新聞文本及網(wǎng)絡(luò)文本的混合型語料)上訓(xùn)練的模型。隨pip包附帶的是此模型。
下載地址:https://pan.baidu.com/s/1DCjDOxB0HD2NmP9w1jm8MA
WEIBO:在微博(網(wǎng)絡(luò)文本語料)上訓(xùn)練的模型。
下載地址:https://pan.baidu.com/s/1QHoK2ahpZnNmX6X7Y9iCgQ
最后附上前面提到的另外四大分詞工具的GitHub地址:
1、LTP:https://github.com/HIT-SCIR/ltp
2、NLPIR:https://github.com/NLPIR-team/NLPIR
3、THULAC:https://github.com/thunlp/THULAC
4、jieba:https://github.com/yanyiwu/cppjieba
-
Linux
+關(guān)注
關(guān)注
88文章
11758瀏覽量
219009 -
開源
+關(guān)注
關(guān)注
3文章
4203瀏覽量
46127 -
python
+關(guān)注
關(guān)注
57文章
4876瀏覽量
90025
原文標(biāo)題:準(zhǔn)確率秒殺結(jié)巴分詞,北大開源全新中文分詞工具包PKUSeg
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數(shù)據(jù)技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
MinGW-w64工具集壓縮包的下載
Microchip推出SDI IP內(nèi)核與四通道CoaXPress?橋接工具包,進(jìn)一步擴(kuò)展PolarFire? FPGA智能嵌入式視頻生態(tài)系統(tǒng)

中北大學(xué)以開源技術(shù)鋪就人才與產(chǎn)業(yè)共贏之路
第一個(gè)基于sdcc的MCS-51實(shí)時(shí)操作系統(tǒng)移植
東北大學(xué)開源鴻蒙技術(shù)俱樂部正式揭牌成立

FPNew開源浮點(diǎn)運(yùn)算單元工程建立
eForce無線通信軟件開發(fā)工具包兼容WLAN模塊WKR612AA1
量化評估企業(yè)軟件測試能力的評估工具包

我做了一個(gè)智能高速隔離的USBHub...開源了!
IQM 宣布 Resonance 量子云平臺重大升級,推出全新軟件開發(fā)工具包
開源工具 Made with KiCad(131):BomberCat 安全測試工具

開源鴻蒙工程工具分論壇圓滿舉辦
Open Echo:一個(gè)開源的聲納項(xiàng)目



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論