 什么是最好的深度學習GPU?分析幾款目前最優秀的GPU
什么是最好的深度學習GPU?分析幾款目前最優秀的GPU

編者按:8月份時候,我們曾出過一篇深度學習顯卡選型指南,由于當時新顯卡還沒發售,文章只能基于新一代創新做一些推測性分析,對讀者來說,這樣的結果可能太晦澀,也不夠直觀。今天,論智就給大家帶來了另一篇更具說服力的文章,它來自人工智能硬件公司Lambda,主要對比分析了RTX 2080 Ti、RTX 2080、GTX 1080 Ti、Titan V和Tesla V100的成本、價格差異。
在深度學習實踐中,很多人會經常問一個問題:什么是最好的深度學習GPU?在這篇文章中,我們將主要分析以下幾款目前最優秀的GPU:
RTX 2080 Ti
RTX 2080
GTX 1080 Ti
Titan V
Tesla V100
為了從中挑選出最佳GPU,我們會從定價、性能兩個維度對它們進行分析。
實驗結果
根據全面定性定量的實驗結果,截至2018年10月8日,NVIDIA RTX 2080 Ti是現在最好的深度學習GPU(用單個GPU運行Tensoflow)。以單GPU系統的性能為例,對比其他GPU,它的優劣分別是:
FP32時,速度比1080 Ti快38%;FP16時,快62%。在價格上,2080 Ti比1080 Ti貴25%
FP32時,速度比2080快35%;FP16時,快47%。在價格上,2080 Ti比2080貴25%
FP32時,速度是Titan V的96%;FP16時,快3%。在價格上,2080 Ti是Titan V的1/2
FP32時,速度是Tesla V100的80%;FP16時,是Tesla V100的82%。在價格上,2080 Ti是Tesla V100的1/5
請注意,所有實驗都使用Tensor Core(可用時),并且完全按照單個GPU系統成本計算。
深入分析
實驗中,所有GPU的性能都是通過在合成數據上訓練常規模型,測量FP32和FP16時的吞吐量(每秒處理的訓練樣本數)來進行評估的。為了標準化數據,同時體現其他GPU相對于1080 Ti的提升情況,實驗以1080 Ti的吞吐量為基數,將其他GPU吞吐量除以基數計算加速比,這個數據是衡量兩個系統間相對性能的指標。
訓練不同模型時,各型號GPU的吞吐量
對上圖數據計算平均值,同時按不同浮點計算能力進行分類,我們可以得到:
FP16時各GPU相對1080 Ti的加速比
FP32時各GPU相對1080 Ti的加速比
可以發現,2080的模型訓練用時和1080 Ti基本持平,但2080 Ti有顯著提升。而Titan V和Tesla V100由于是專為深度學習設計的GPU,它們的性能自然會比桌面級產品高出不少。最后,我們再將每個GPU的平均加速情況除以各自總成本:
FP16時各GPU相對1080 Ti的每美元加速情況
FP32時各GPU相對1080 Ti的每美元加速情況
根據這個評估指標,RTX 2080 Ti是所有GPU中最物有所值的。
2080 Ti vs V100:2080 Ti真的那么快嗎?
可能有人會有疑問,為什么2080 Ti的速度能達到Tesla V100的80%,但它的價格只是后者的八分之一?答案很簡單,NVIDIA希望細分市場,以便那些有足夠財力的機構/個人繼續購買Tesla V100(約9800美元),而普通用戶則可以選擇在自己價格接受范圍內的RTX和GTX系列顯卡——它們的性價比更高。
除了AWS、Azure和Google Cloud這樣的云服務商,個人和機構可能還是買2080 Ti更劃算。但這不是說亞馬遜、微軟、Google這些公司“人傻錢多”,Tesla V100確實有一些其他GPU所沒有的重要功能:
如果你需要FP64計算。如果你的研究領域是計算流體力學、N體模擬或其他需要高數值精度(FP64)的工作,那么你就得購買Titan V或V100s。
如果你對32 GB的內存有極大需求(比如11G的內存都不夠存儲模型的1個batch)。這類情況很少見,它面向的是想創建自己的模型體系架構的用戶。而大多數人使用的都是像ResNet、VGG、Inception、SSD或Yolo這樣的東西,這些人的占比可能不到5%。
面對2080 Ti,為什么還會有人買Tesla V100?這就是NVIDIA做生意的高明之處。
2080 Ti是保時捷911,V100是布加迪威龍
V100有點像布加迪威龍,它是世界上最快的、能在公路上合法行駛的車,同時價格也貴得離譜。如果你不得不擔心它的保險和維修費,那你肯定買不起這車。另一方面,RTX 2080 Ti就像一輛保時捷911,它速度非常快,操控性好,價格昂貴,但在炫耀性上就遠不如前者。
畢竟如果你有買布加迪威龍的錢,你可以買一輛保時捷,外加一幢房子、一輛寶馬7系、送三個孩子上大學和一筆客觀的退休金。
原始性能數據
FP32吞吐量
FP32(單精度)算法是訓練CNN時最常用的精度。以下是實驗中的具體吞吐量數據:
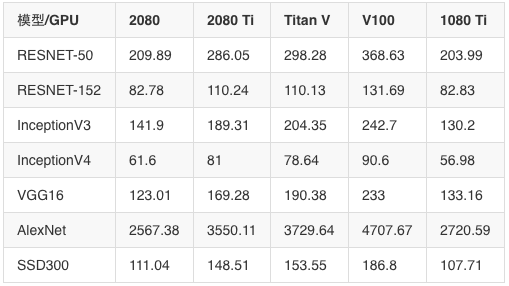
FP16吞吐量(Sako)
FP16(半精度)算法足以訓練許多網絡,這里實驗用了Yusaku Sako基準腳本:
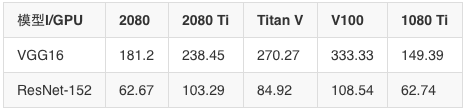
FP32(Sako)
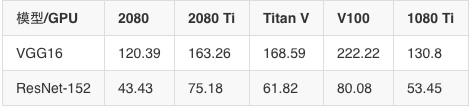
FP16時訓練加速比(以1080 Ti為基準)
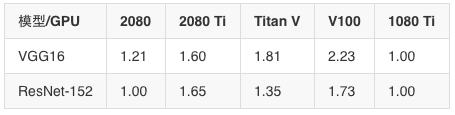
FP32時訓練加速比(以1080 Ti為基準)
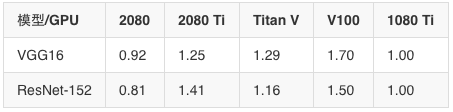
價格表現數據(加速/$1,000)FP32
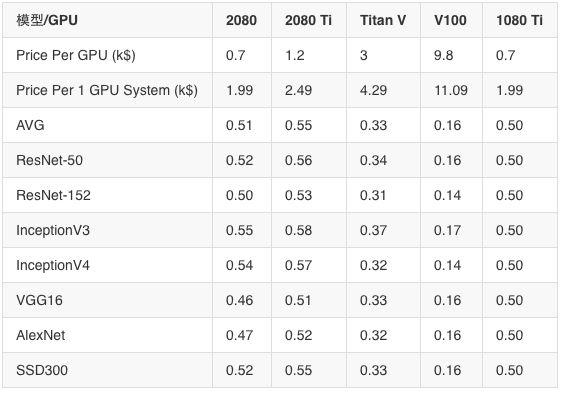
價格表現數據(加速/$1,000)FP16
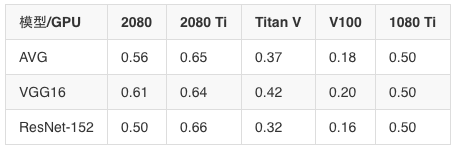
實驗方法
所有模型都在合成數據集上進行訓練,這能將GPU性能與CPU預處理性能有效隔離開來。
對于每個GPU,對每個模型進行10次訓練實驗。測量每秒處理的圖像數量,然后在10次實驗中取平均值。
計算加速基準的方法是獲取的圖像/秒吞吐量除以該特定模型的最小圖像/秒吞吐量。這基本上顯示了相對于基線的百分比改善(在本實驗中基準為1080 Ti)。
2080 Ti、2080、Titan V和V100基準測試中考慮到了Tensor Core。
實驗中使用的batch size
此外,實驗還有關于硬件、軟件和“什么是典型的單GPU系統”的具體設置,力求盡量還原普通用戶的模型訓練環境,充分保障了結果的準確性。相信看到這里,結合之前那篇長文,大家已經對該買什么GPU有了清楚認識,祝各位剁手愉快!
-
gpu
+關注
關注
28文章
5194瀏覽量
135431 -
人工智能
+關注
關注
1817文章
50094瀏覽量
265298 -
深度學習
+關注
關注
73文章
5598瀏覽量
124396
原文標題:TensorFlow GPU基準測試:2080 Ti vs V100 vs 1080 Ti vs Titan V
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
FPGA+GPU異構混合部署方案設計
汽車中的GPU是如何使用的?

如何看懂GPU架構?一分鐘帶你了解GPU參數指標


NVIDIA桌面GPU系列擴展新產品
aicube的n卡gpu索引該如何添加?
如何在Ray分布式計算框架下集成NVIDIA Nsight Systems進行GPU性能分析
別讓 GPU 故障拖后腿,捷智算GPU維修室來救場!

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】+NVlink技術從應用到原理
GPU架構深度解析
ARM Mali GPU 深度解讀
可以手動構建imx-gpu-viv嗎?
極速部署!GpuGeek提供AI開發者的云端GPU最優解



 工商網監
工商網監
評論