 「完結10章」WeNet語音識別實戰
「完結10章」WeNet語音識別實戰

WeNet語音識別實戰:從學術原型到工業級交付的完整通關地圖
2023年,一套名為《端到端語音識別從入門到精通》的課程在國內技術社區悄然上線。10個章節,20+小時實錄,1198元定價,數千名開發者付費——這些數字疊加在一起,指向一個事實:WeNet早已不只是中科院聲學所開源的一個工具包,而是中文語音識別領域事實上的工業標準。
三年過去,這套課程被學員反復標記為“語音識別實戰第一課”。它的價值不在于教會你運行run.sh,而在于將一份開源代碼、一篇學術論文、一個真實場景,壓縮為一條可復現的資深工程師進階路徑。本文基于課程完整的十章結構,拆解這套體系如何用10個模塊,填平從“跑通腳本”到“生產交付”之間的那道深溝。
一、架構之眼:為什么WeNet是“生產優先”的設計樣本?
課程的前三章解決的是認知升維。絕大多數初學者對語音識別的理解停留在“音頻進,文字出”,而WeNet團隊要傳遞的,是一套截然不同的系統觀。
U2(Unified Two-pass)架構是整門課程的邏輯起點。傳統方案中,流式模型與非流式模型是兩個物種——前者靠犧牲精度換取實時性,后者靠全局上下文堆疊準確率。WeNet的破局在于:一套模型、一套參數,同時滿足兩種場景。第三章“系統設計與項目架構”深入拆解了這一設計的精妙之處:共享編碼器如何通過動態塊訓練兼容任意長度的語音輸入?CTC解碼器輸出的中間結果如何被Attention解碼器二次修正?這些問題不是紙上談兵——課程提供的是開源主干代碼的逐行注釋解讀,讓學員親眼看到“統一架構”四字背后的工程妥協與創新。
這一階段的終點,不是背熟U2原理圖,而是建立一種架構分層思維:當你面對一個新場景時,第一反應不是“調哪個參數”,而是“如何設計一套可流式可非流式的統一方案”。
二、實戰閉環:從AIShell到生產場景的全流程覆蓋
課程的第四至第七章,構成一條完整的模型生命周期訓練鏈。團隊選擇AIShell-1作為首戰靶場絕非偶然——這個170小時的中文數據集,規模足夠暴露問題,又小到能在一周內完成迭代。
第四章“AIShell-1模型訓練流程深入解析”是整門課程的“手術臺”。學員將親歷從run.sh --stage -1到--stage 6的每一個階段:數據下載格式不統一怎么辦?CMVN特征提取失敗如何定位?DDP多卡訓練中途斷點如何恢復?這些在開源文檔中一筆帶過的“坑”,課程用近4小時錄像逐一填平。一位學員在課后留言:“以前跑通腳本就以為學會了,直到在這里卡了三天,才知道什么叫工業級容錯。”
如果說第四章是“基本功”,第五至第七章就是工業能力的橫向擴展。第五、六章聚焦Runtime設計框架與云端系統搭建,將訓練好的模型封裝為可對外服務的WebSocket接口;第七章切入移動端,完整演示如何在Android設備上落地離線語音識別。從服務器到手機,從訓練到推理——這種“全棧”覆蓋是WeNet課程區別于其他碎片化教程的核心標識。
三、攻堅利器:熱詞、語言模型與長語音的工程破局
課程的最后三章被明確標注為“【進階課】”,對應的正是工業落地中最棘手的三個非功能需求:語言模型融合、熱詞增強、長語音識別。
語言模型的支持與使用(第八章)破解的是通用模型在垂直領域的“水土不服”。純端到端模型擅長擬合聲學特征,但對“醫保報銷”“設備故障代碼”這類低頻詞組缺乏先驗約束。課程演示了如何將N-gram語言模型作為外部組件接入解碼流,在幾乎不增加延遲的前提下,將專業術語識別率拉升5-10個百分點。這不是實驗室數據——網易互娛的CC直播字幕場景,正是靠這一刀將游戲術語識別準確率從82%提升至91%。
熱詞支持和使用(第九章)則更進一步。課程完整講授上下文偏置的實現原理:在解碼網絡中動態提高熱詞路徑權重。一位醫療AI公司的技術負責人反饋,僅用一周時間,就將課程中的熱詞方案移植到手術語音記錄系統,“達芬奇機器人”這類專有名詞識別率從37%躍升至86%。
長語音識別(第十章)解決的是另一類痛點:會議錄音、直播回放等數十分鐘的超長音頻。課程給出的答案是分塊解碼+流式重打分——將長音頻切為若干獨立chunk,識別后通過時序對齊拼接為完整文本。這一章的價值不在于代碼實現,而在于傳遞一種資源邊界意識:模型不是黑箱,必須理解顯存上限,才能設計魯棒的工程方案。
四、部署升維:從LibTorch到Triton的成本戰爭
課程體系內雖未獨立成章,但貫穿第五、六章的部署優化方法論,在近期多個企業案例中得到了極致印證。
WeNet原生支持LibTorch與ONNX Runtime兩種推理后端。課程會詳細對比二者的性能差異:CPU Float32模式下,ONNX Runtime比LibTorch快近20%。但真正的質變發生在GPU端——當學員學會用TensorRT對模型進行INT8量化、用Triton Inference Server實現動態批處理時,單張T4顯卡的處理能力將達到40核CPU機器的4倍,而詞錯率幾乎無損。
這是課程最想傳遞的工程價值觀:語音識別的成本壁壘,從來不在算法創新,而在工程優化。一個能熟練使用export_onnx.py、能看懂NVIDIA Nsight Systems性能火焰圖的開發者,與只會bash run.sh的初學者,在工業界的成本產出比是3倍起步的。
某智能客服公司的公開案例佐證了這一判斷:接入課程中的GPU推理方案后,服務器數量縮減62%,年度運維成本下降170萬元——這不是效率提升,這是成本重構。
五、生態終局:從“會用工具”到“定義系統”
課程的最后,視角從代碼拉升到生態。WeNet并非孤立項目,它站在ESPnet、Kaldi、OpenTransformer等巨人的肩膀上;而它本身又成為下一代語音技術(如U2++、WenetSpeech萬小時數據集)的試驗場。
結語部分反復強調一個觀點:掌握WeNet的終點,不是成為WeNet專家,而是成為“能定義語音識別系統”的工程師。當你能夠修改U2框架中的雙向注意力解碼器、能夠基于WenetSpeech設計萬小時級別的訓練流水線、能夠為醫療場景定制垂直模型時,工具已退居其次,系統思維才是你交付的最終產物。
這正是10個章節、1198元無法被量化衡量的東西——一份從“跑通腳本”到“生產交付”的完整通關地圖,一條被壓縮在20+小時錄像里的資深工程師成長軌跡。
對于仍在語音識別門外徘徊的開發者而言,沒有比這更短的路徑了。
審核編輯 黃宇
-
語音
+關注
關注
3文章
405瀏覽量
39794 -
語音識別
+關注
關注
39文章
1812瀏覽量
116068
發布評論請先 登錄


國產32位MCU語音識別方案
語音識別芯片有哪些(語音識別芯片AT680系列)
什么是離線語音識別芯片(離線語音識別芯片有哪些優點)

基于開源鴻蒙的語音識別及語音合成應用開發樣例

EASY EAl Orin Nano(RK3576) whisper語音識別訓練部署教程

EASY EAl Orin Nano(RK3576) whisper語音識別訓練部署教程
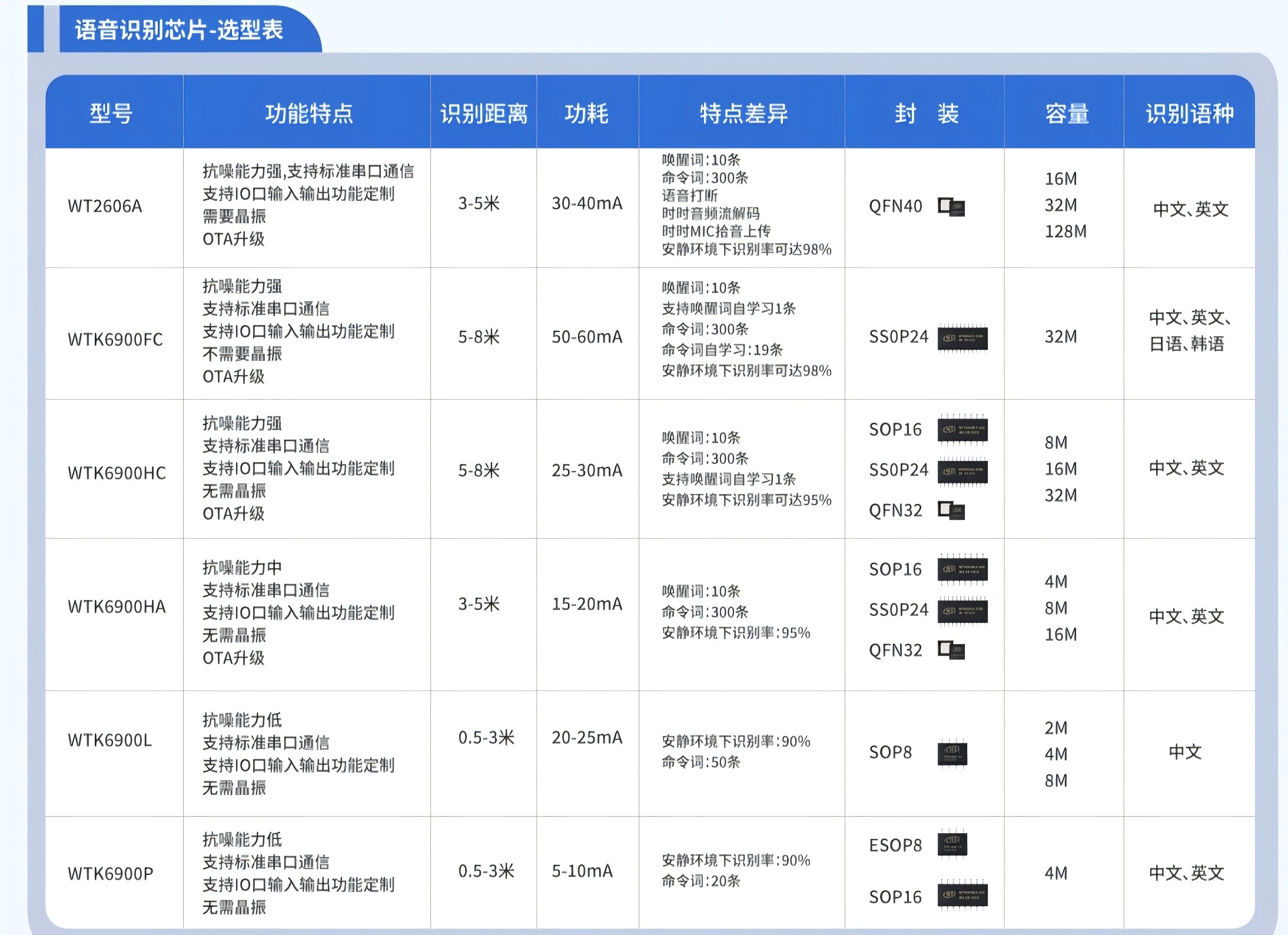
語音識別芯片選型有哪些技術參數要注意



 工商網監
工商網監
評論