 瑞芯微(EASY EAI)RV1126B 語音識別
瑞芯微(EASY EAI)RV1126B 語音識別

1. 語音識別簡介
語音識別技術,也被稱為自動語音識別(Automatic Speech Recognition,ASR),其目標是將人類的語音中的詞匯內容轉換為計算機可讀的輸入,例如按鍵、二進制編碼或者字符序列。與說話人識別及說話人確認不同,后者嘗試識別或確認發出語音的說話人而非其中所包含的詞匯內容。
我們的語音算法是基于Whisper是OpenAI設計的。Whisper作為一個通用的語音識別模型,它使用了大量的多語言和多任務的監督數據來訓練,能夠在英語語音識別上達到接近人類水平的魯棒性和準確性。Whisper還可以進行多語言語音識別、語音翻譯和語言識別等任務。Whisper的架構是一個簡單的端到端方法,采用了編碼器-解碼器的Transformer模型,將輸入的音頻轉換為對應的文本序列,并根據特殊的標記來指定不同的任務。
基于EASY-EAI-Nano-TB(RV1126B)硬件主板的運行效率:

2. 快速上手
2.1 開發環境準備
如果您初次閱讀此文檔,請閱讀《入門指南/開發環境準備/Easy-Eai編譯環境準備與更新》,并按照其相關的操作,進行編譯環境的部署。
在PC端Ubuntu系統中執行run腳本,進入EASY-EAI編譯環境,具體如下所示。
cd ~/develop_environment
./run.sh 2204
2.2 源碼下載
在EASY-EAI編譯環境下創建存放源碼倉庫的管理目錄:
cd /opt
mkdir EASY-EAI-Toolkit
cd EASY-EAI-Toolkit通過git工具,在管理目錄內克隆遠程倉庫
git clone https://github.com/EASY-EAI/EASY-EAI-Toolkit-1126B.git
注:
* 此處可能會因網絡原因造成卡頓,請耐心等待。
* 如果實在要在gitHub網頁上下載,也要把整個倉庫下載下來,不能單獨下載本實例對應的目錄。
2.3 模型部署
要完成算法Demo的執行,需要先下載語音算法模型。
百度網盤鏈接為: https://pan.baidu.com/s/18okeW8ZIJ6zapTvuxcFoRw?pwd=1234 (提取碼:1234 )。

同時需要把下載的語音識別算法模型復制粘貼到Release/目錄:
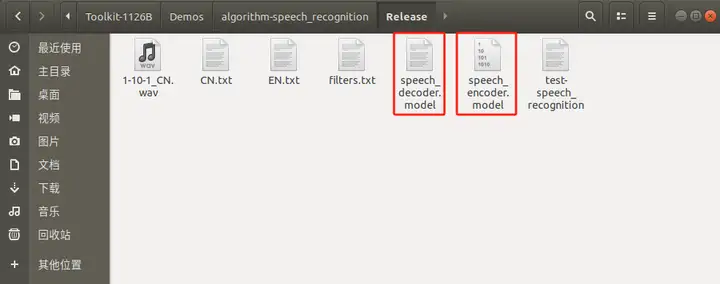
2.4 例程編譯
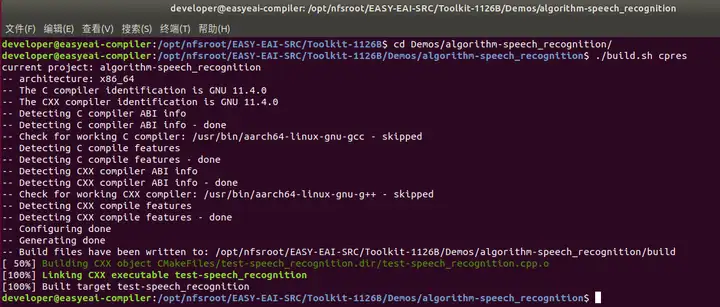
進入到對應的例程目錄執行編譯操作,具體命令如下所示:
cd EASY-EAI-Toolkit-1126B/Demos/algorithm-speech_recognition/
./build.sh cpres注:
* 由于依賴庫部署在板卡上,因此交叉編譯過程中必須保持/mnt掛載。
* 若build.sh腳本帶有cpres參數,則會把Release/目錄下的所有資源都拷貝到開發板上。
2.5 例程運行及效果
通過串口調試或ssh調試,進入板卡后臺,定位到例程部署的位置,如下所示:
cd /userdata/Demo/algorithm-speech_recognition/
運行例程命令如下所示:
sudo ./test-speech_recognition speech_encoder.model speech_decoder.model filters.txt CN.txt cn 1-10-1_CN.wav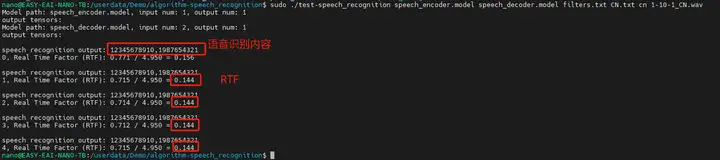
API的詳細說明,以及API的調用(本例程源碼),詳細信息見下方說明。
3. 語音識別API說明
3.1 引用方式
為方便客戶在本地工程中直接調用我們的EASY EAI api庫,此處列出工程中需要鏈接的庫以及頭文件等,方便用戶直接添加。

3.2 語音識別檢測初始化函數
設置語音識別初始化函數原型如下所示。
int speech_recognition_init(const char *p_encoder_path, const char *p_decoder_path, const char *p_filter_path,
const char *p_vocab_path, rknn_whisper_t *p_whisper);具體介紹如下所示。

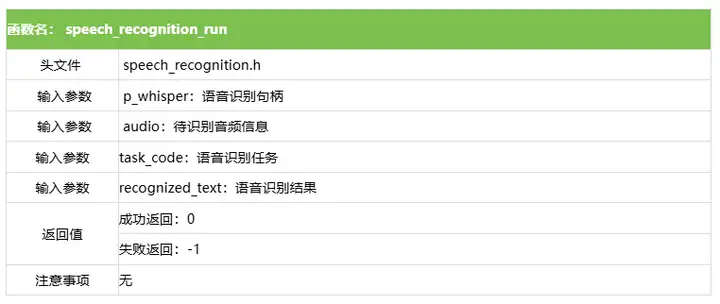
3.3 語音識別運行函數
設置語音識別運行原型如下所示。
int speech_recognition_run(rknn_whisper_t *p_whisper, audio_buffer_t audio, int task_code, std::vector &recognized_text);具體介紹如下所示。
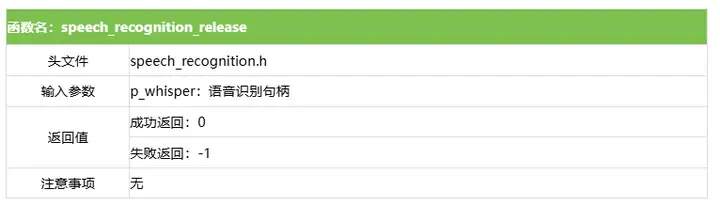
3.4 語音識別釋放函數
設置語音識別釋放原型如下所示。
int speech_recognition_release(rknn_whisper_t *p_whisper);具體介紹如下所示。
4. 語音識別算法例程
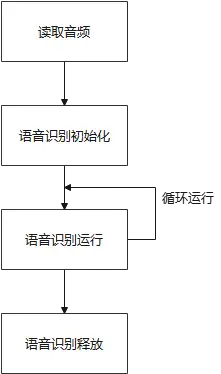
例程目錄為Demos/algorithm-speech_recognition/test-speech_recognition.cpp,操作流程如下所示:
#include
#include
#include
#include
#include
#include "sndfile.h"
#include "speech_recognition.h"
#include "audio_utils.h"
int main(int argc, char **argv)
{
if (argc != 7){
printf("%s \n", argv[0]);
printf("Example: %s speech_encoder.model speech_decoder.model filters.txt CN.txt cn 1-10-1_CN.wav\n", argv[0]);
return -1;
}
const char *p_encoder_path = argv[1]; // 編碼模型地址
const char *p_decoder_path = argv[2]; // 解碼模型地址
const char *p_filter_path = argv[3]; // 濾波器頻譜
const char *p_vocab_path = argv[4]; // 詞組文件
const char *p_task = argv[5]; // 識別語種(cn/en)
const char *p_audio_path = argv[6]; // 待識別音頻
int task_code = 0;
std::vector recognized_text;
// Tokenizer 預定義控制符號(切換語言或任務)
if (strcmp(p_task, "en") == 0){
task_code = 50259;
}
else if (strcmp(p_task, "cn") == 0){
task_code = 50260;
}
else{
printf("\n\033[1;33mCurrently only English or Chinese recognition tasks are supported. Please specify as en or zh\033[0m\n");
return -1;
}
// 讀取音頻,并對音頻進行處理
audio_buffer_t audio;
int ret = read_audio(p_audio_path, &audio);
if (ret != 0){
printf("read audio fail! ret=%d audio_path=%s\n", ret, p_audio_path);
return -1;
}
if (audio.num_channels == 2){
ret = convert_channels(&audio);
}
if (audio.sample_rate != SAMPLE_RATE){
ret = resample_audio(&audio, audio.sample_rate, SAMPLE_RATE);
}
// speech recognition初始化
rknn_whisper_t whisper;
ret = speech_recognition_init(p_encoder_path, p_decoder_path, p_filter_path, p_vocab_path, &whisper);
int iter = 0;
for (int i=0; i < 5; i++)
{
clock_t start = clock();
recognized_text.clear();
// speech recognition語音識別
ret = speech_recognition_run(&whisper, audio, task_code, recognized_text);
clock_t end = clock(); // 記錄結束時間
double infer_time = ((double)(end - start)) / CLOCKS_PER_SEC; // 轉換為秒
// 結果輸出
std::cout << "\nspeech recognition output: ";
for (const auto &str : recognized_text){
std::cout << str;
}
std::cout << std::endl;
float audio_length = audio.num_frames / (float)SAMPLE_RATE; // sec
audio_length = audio_length > (float)CHUNK_LENGTH ? (float)CHUNK_LENGTH : audio_length;
float rtf = infer_time / audio_length;
printf("%d, Real Time Factor (RTF): %.3f / %.3f = %.3f\n", iter++, infer_time, audio_length, rtf);
}
// speech recognition釋放
speech_recognition_release(&whisper);
return 0;
}-
Linux
+關注
關注
88文章
11782瀏覽量
219252 -
瑞芯微
+關注
關注
27文章
801瀏覽量
54501 -
EASY-EAI靈眸科技
+關注
關注
4文章
67瀏覽量
3685 -
RV1126B
+關注
關注
0文章
56瀏覽量
206
發布評論請先 登錄
瑞芯微(EASY EAI)RV1126B 音頻輸入

瑞芯微(EASY EAI)RV1126B PWM使用

如何用瑞芯微RV1126B核心板贏得AI紅利?

【EASY EAI Nano-TB(RV1126B)開發板試用】+初識篇
【EASY EAI Nano-TB(RV1126B)開發板試用】命令行功能測試-shell腳本進行IO控制-燈閃
【EASY EAI Nano-TB(RV1126B)開發板試用】命令行功能測試-shell腳本進行IO控制-紅綠燈項目
【EASY EAI Nano-TB(RV1126B)開發板試用】命令行功能測試-shell腳本進行IO控制-紅綠燈按鈕項目
請問各位大佬,如何解決,瑞芯微 RV1126B 使用 mpp 自帶工具 調試時,內核直接報錯崩潰!
【EASY EAI Nano-TB(RV1126B)開發板試用】+1、開箱上電
【EASY EAI Nano-TB(RV1126B)開發板試用】介紹、系統安裝
RV1126系列選型指南:從RV1126到RV1126B,一文看懂升級差異

【免費試用】EASY EAI Nano-TB(RV1126B)開發套件評測

瑞芯微RV1126B特性概述
替代升級實錘!實測RV1126B,CPU性能吊打RV1126

瑞芯微(EASY EAI)RV1126B 人體關鍵點識別




 工商網監
工商網監
評論