 基于開源鴻蒙的語音識別及語音合成應用開發樣例
基于開源鴻蒙的語音識別及語音合成應用開發樣例

【拆·應用】是為開源鴻蒙應用開發者打造的技術分享平臺,是匯聚開發者的技術洞見與實踐經驗、提供開發心得與創新成果的展示窗口。誠邀您踴躍發聲,期待您的真知灼見與技術火花!
引言
本期內容由AI Model SIG提供,介紹了在開源鴻蒙中,利用sherpa_onnx開源三方庫進行ASR語音識別與TTS語音合成應用開發的流程。
ASR/TTS介紹
ASR也就是自動語音識別(Automatic Speech Recognition),其主要作用是把人類語音里的詞匯內容轉變為計算機能夠讀取的文本形式。
TTS也就是文本轉語音(Text-to-Speech),它主要的功能是把計算機里以文本形式存在的信息轉變成人耳可聽見的語音。
ASR/TTS有著廣泛的用途,例如語音助手聊天、設備控制、新聞播報、有聲閱讀等。
Sherpa_onnx介紹
sherpa-onnx是一個開源語音處理工具包,具有輕量級、跨平臺和高性能的語音識別推理能力。它基于ONNX Runtime,支持CPU/GPU加速,且內存占用低、延遲小,適合實時流式語音處理。它兼容多種 端到端語音模型(如Transformer、RNN-T),提供簡潔的C++/Python API,并支持動態斷句和流式識別,開箱即用。相比傳統方案(如Kaldi),sherpa_onnx依賴更少、部署更簡單,特別適合 移動端、離線語音助手、實時字幕等場景兼顧效率與易用性。
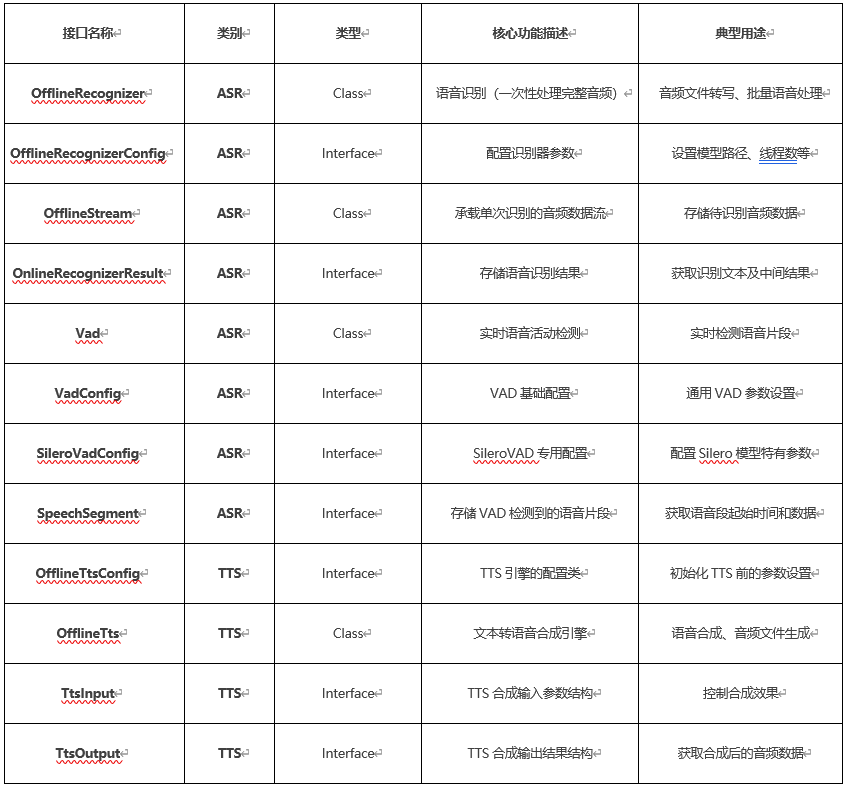
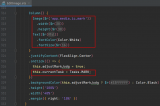
sherpa_onnx已經移植到開源鴻蒙,直接支持ArkTS接口,本示例用到的接口如下:
開發準備
1.環境搭建:確保安裝了ArkUI開發所需的IDE,如DevEco Studio,并配置好相應的開發環境,包括SDK(本示例Api11及以上)版本等。
2.了解ArkUI框架特性:熟悉ArkUI的布局和組件使用方法,例如文本輸入框用于接收用戶輸入,按鈕組件用于觸發ASR語音識別操作等。還要了解ArkUI的數據綁定機制,方便將ASR識別結果和TTS合成狀態等信息實時顯示在界面上。
示例界面設計
底部欄:語音采集與文本輸入切換按鈕,點擊切換。
中間區:文本顯示區,呈現識別后文本和輸入內容。
頭部欄:標題、語音播放按鈕(播放中間區域文本)、設置按鈕(語速設置和聲音模型切換)。

示例功能邏輯
示例基于sherpa_onnx三方庫開發,此庫在OpenHarmony三方庫中心倉下載安裝,鏈接如下:
https://ohpm.openharmony.cn/#/cn/detail/sherpa_onnx

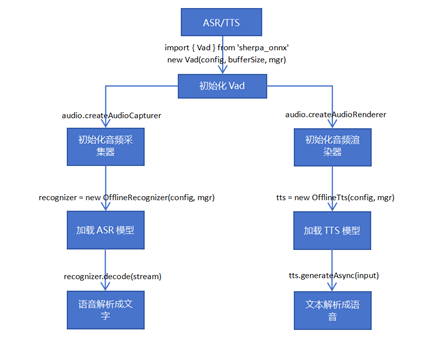
以下所展示的是本示例的流程圖,該流程圖涵蓋了從Vad聲音活動檢測的初始化階段,音頻采集器與渲染器初始化過程,接著是ASR(自動語音識別)模型和TTS(文本到語音)模型的加載,直至最終成功實現語音識別與語音生成的流程。
ASR模型解析核心實現
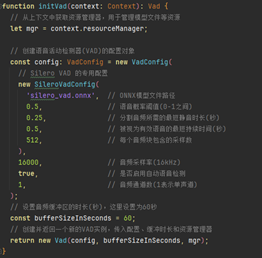
1.初始化Vad
Vad聲音活動檢測(Voice activity detection),也稱為語音活動檢測或語音檢測(speech activity detection或者speech detection),是檢測人類語音存在與否的技術,主要用于語音處理。Vad的主要用途在于說話人分割(speaker diarization)、語音編碼(speech coding)和語音識別(speech recognition),初始化vad過程如下:
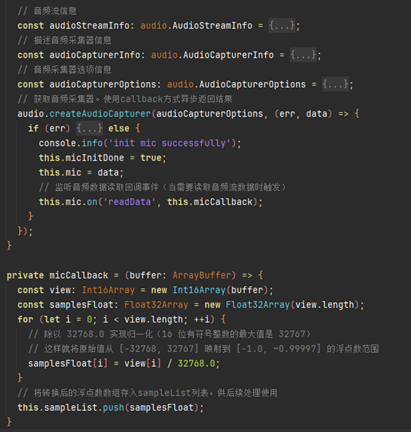
2.初始化音頻采集器
初始化一個音頻采集器,用于從麥克風硬件獲取音頻數據,注冊回調事件micCallback將音頻數據存儲到ampleList數組中。
3.加載ASR模型
語音識別需要加載一個ASR模型,用戶可依據自身業務需求下載合適的模型,模型下載地址:
https://github.com/k2-fsa/sherpa-onnx/releases/tag/asr-models。
本示例使用的是sherpa-onnx-sense-voice-zh-en-ja-ko-yue-2024-07-17模型,支持中文、英文、日文、韓文以及粵語五種語言。
將解壓后的模型文件放入指定路徑中。
路徑:src/main/resources/rawfile
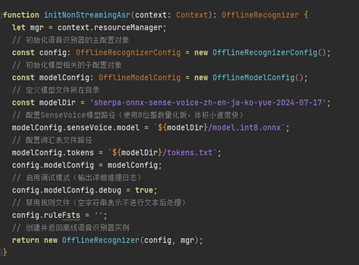
創建語音識別實例OfflineRecognizer,加載該模型。
4.語音解析成文字
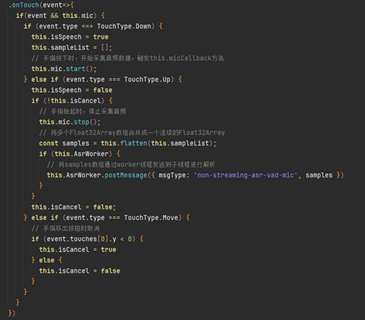
“按住說話”按鈕,當手指按下時采集音頻數據,觸發micCallback回調保存數據,手指抬起時終止采集,隨后,將數據經由worker線程發送至子線程予以解析。
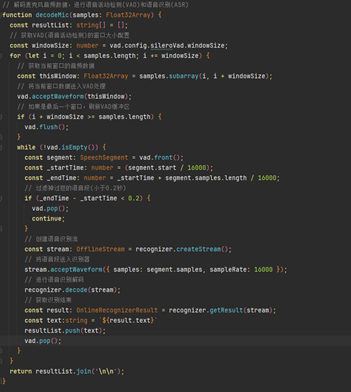
子線程在獲取音頻數據之后,將其解析為文字,最終呈現在應用界面上,具體解析流程如下:
TTS模型解析核心實現
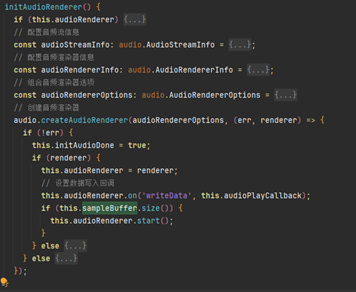
1.初始化音頻渲染器
初始化一個音頻渲染器,用于將音頻數據輸出到設備揚聲器。通過配置音頻參數和渲染屬性,確保音頻格式與硬件兼容,并建立數據寫入的回調機制audioPlayCallback。
2.加載TTS模型
語音合成需要加載一個TTS模型,用戶可依據自身業務需求下載合適的模型,模型下載地址:
https://github.com/k2-fsa/sherpa-onnx/releases/tag/tts-models。
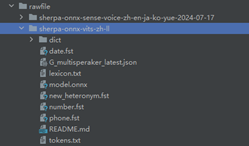
其中有多種文本轉語音模型,本示例選用了6種TTS模型,用在設置界面切換不同的聲音。
將解壓后的模型文件放到指定的路徑下。
路徑:src/main/resources/rawfile
創建語音識別實例OfflineTts,加載該模型:
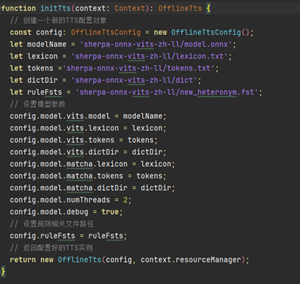
加載完TTS模型后,獲取模型相關信息,音頻采樣率、說話人(音色)數量,CPU線程數(本示例為雙線程)。
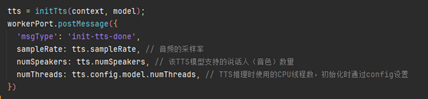
3.文本解析成音頻
點擊播放圖標,播放或暫停可將中間區域的文字以語音形式予以播放。
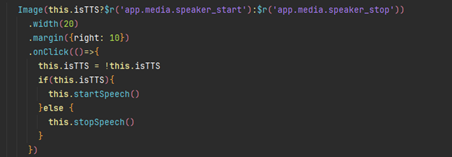
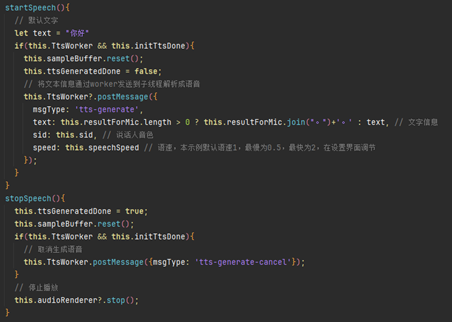
將文本信息通過worker發送至子線程進行語音合成;
text為輸入文本,當界面上無文字時默認“你好”,有文字時,將文字以句號分割,使播放句子有停頓效果;
sid說話人音色(模型相關信息numSpeakers)參數選擇(通常0 ≤ sid ≤ numSpeakers);
speed語速,默認語速為1,可在設置界面調節。
使用tts.generateAsync方法把文字轉化為語音,TtsInput為TTS合成輸入參數,文字轉成語音后,數據由worker回傳至主線程。
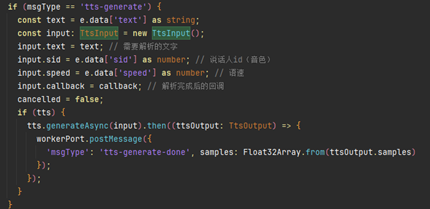
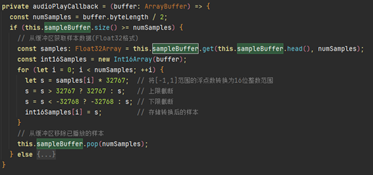
接收到語音數據后,將數據存儲在sampleBuffer數組,然后通過this.audioRenderer.start()觸發語音播放。
效果展示
ASR/TTS示例應用代碼
代碼倉鏈接:https://gitcode.com/openharmony-sig/applications_ai_model_samples/tree/master/AsrAndTts
AI Model SIG簡介
AI Model SIG 是經開源鴻蒙PMC(項目管理委員會)正式批準成立的特別興趣小組(SIG),核心目標是豐富開源鴻蒙生態下的大小應用模型,并提供端到端的實踐范例,為開發者構建 AI 應用提供高效支撐。
未來,AI Model SIG 將圍繞三大方向持續深耕:
聚焦模型推理框架與多推理后端的深度適配,夯實 AI 能力底層基座;
推進多模態模型的生態適配與優化,拓展 AI 應用場景邊界;
將技術成果分享出來,確保廣大開發者可便捷獲取與使用。
同時,小組將聯合全球開發者協同共建,持續完善開源鴻蒙 AI 技術體系,助力打造更具競爭力的全場景智能終端生態。
如果您對開源鴻蒙AI技術感興趣,歡迎加入AI Model SIG,一起探索萬物智聯的未來!
-
語音識別
+關注
關注
39文章
1812瀏覽量
116177 -
開源
+關注
關注
3文章
4280瀏覽量
46347 -
鴻蒙
+關注
關注
60文章
2995瀏覽量
46095
原文標題:拆·應用丨第3期:開源鴻蒙語音識別及語音合成應用開發
文章出處:【微信號:gh_e4f28cfa3159,微信公眾號:OpenAtom OpenHarmony】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
基于開源鴻蒙的圖片編輯開發樣例(1)

基于開源鴻蒙的圖片編輯開發樣例(2)




 工商網監
工商網監
評論