 AI推理:如何實現吞吐翻倍、時延降90%與GPU資源節省26%?
AI推理:如何實現吞吐翻倍、時延降90%與GPU資源節省26%?

引言:AI規模化落地,推理系統面臨全新挑戰
?
全球領先的市場研究和咨詢公司IDC預測,到2028年,75%的新 AI 工作負載將實現容器化,從而顯著提升模型與工作負載更新的速度、一致性與安全性。容器化技術將成為 AI 推理時代的“默認交付形態”。當前隨著大模型技術快速演進與業務場景的深度融合,AI業務對推理基礎設施的需求呈現爆發式增長。在早期小流量場景下,手動部署與定制化方案尚可應對;然而當模型規模、并發請求與業務復雜度攀升至新高度時,傳統推理系統在以下四個主要方面逐漸暴露出瓶頸。
1. 穩定性不足:
?單點故障風險:手動部署的靜態架構缺乏多副本與故障自愈機制,單節點宕機易引發服務中斷;
?負載不均衡:缺乏智能流量調度,高并發時部分節點過載導致響應延遲,低負載時資源閑置;
?故障恢復滯后:依賴人工排查與重啟,恢復周期長,影響業務連續性。
2.資源利用率低下:
?靜態資源分配:固定規模的GPU集群無法適應流量波動,高峰時段資源爭搶,低谷期GPU閑置率超40%;
?缺乏彈性機制:無法根據請求隊列長度、KV緩存利用率等指標動態擴縮容,導致周級別GPU卡時浪費超5000+。
3.推理性能瓶頸:
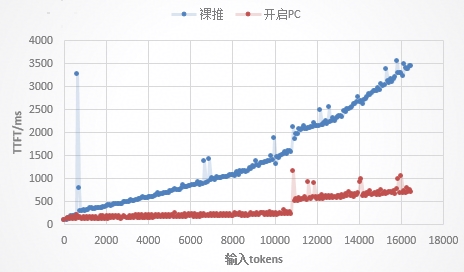
?混合請求排隊:長、短文請求混合處理時,短文首字時延(TTFT)因排隊激增90%以上;
?緩存復用率低:多副本場景下相同前綴請求隨機調度,重復計算導致KV緩存命中率不足60%;
?硬件拓撲未優化:跨交換機部署引發傳輸延遲,人工調整拓撲親和性成本高且易出錯。
4.定制成本高昂:
?多引擎適配復雜:vLLM、SGLang等引擎需獨立開發接入層,版本迭代與兼容性維護成本攀升;
?運維依賴人工:從部署、監控到故障修復全流程手動操作,人力成本占比超30%,且易引入人為錯誤。
?
為此,京東云結合實際業務需求與技術趨勢,全面擁抱云原生技術棧,積累了豐富的云原生與高性能推理經驗。自主研發了新一代云原生AI推理框架。推動推理系統完成了一次體系化升級,實現了從手動部署到全場景AutoScale,從資源浪費到GPU利用率最大化。
?流量高峰自動擴容、低谷自動縮容,GPU卡時節省高達26%;
?智能流量調度與KV緩存復用,最高提升吞吐124%,首次生成時延TTFT降低90%;
?具備多級高可用能力,支持流量隔離、故障自愈與深度可觀測;
?模型量化、引擎調優、算子開發等多項優化,推理引擎單點性能呈現局部領先優勢。
?
詳細了解一套生產級分布式AI訓練推理平臺(JoyBuilder)的云原生改造全紀實。京東云云原生AI推理框架。
?
一、系統架構設計:面向生產級的高性能云原生推理平臺
設計理念:
我們遵循三大核心設計原則,確保系統長期迭代的靈活性:
1.解耦與組合 各模塊盡量松耦合,優先復用開源成熟組件,同時避免被社區綁定,保留核心模塊的可替換能力。
2.擴展性優先 支持以插件化方式集成智能調度算法(流量調度、擴縮容決策、Prefix Cache打分等);容器編排能力可擴展,目前已支持跨機部署與基于角色的調度策略。
3.引擎無感接入 目前可同時支持vLLM、SGLang等主流推理引擎,最終實現任意推理引擎的低成本接入。
系統架構:
?
模塊詳解:
1. 智能流量調度網關
基于云原生Gateway API與Inference Extension框架,我們構建了支持多引擎、高可用、高擴展的智能推理網關,支持多層次調度策略:
?
| 核心能力 | 說明 |
| 長短文分桶推理 流量調度 | 網關基于高效的長短文分桶算法,構建跨模型集群的分流調度,顯著降低短文TTFT(首字生成時延); |
| 前綴緩存感知KV復用流量調度 | 面向不同模型上下文特征,基于 HashTrie 算法構建集群內全局pod的近似前綴緩存畫像,支持prefix cache的親和調度,有效降低推理 TTFT(首字生成時延); |
| 多維負載均衡流量調度 | 毫秒級實時采集KV Cache Utilization、Waiting Queue等server load指標,支持load aware 親和調度; |
| 交換機拓撲感知流量調度 | 為減少PD group組內KV cache傳輸的耗時,構建網絡拓撲感知,支持全局最優prefill + 局部最優decode的網絡親和調度; |
| 多引擎PD分離流量編排調度 | 已支持vLLM(PD串行)、SGLang(PD異步并行) 異構引擎無差別流量調度 |
| 多LoRA動態流量調度、模型切換的流量調度 | 實現不同引擎多LoRA的動態裝、卸載,集成LoRA-aware 的動態流量感知調度能力; |
| 精確的前綴感知Cache-aware流量調度 | 實時訂閱引擎側KV Events Metrics,構建精確的前綴緩存畫像,實現更高效的prefix cache親和調度,進一步降低推理TTFT; |
| 基于時延預測的SLO-aware 流量優先級感知調度 | 利用延遲預測來估算每個請求在每個可用節點上的首次生成時間(TTFT)和每個輸出令牌時間(TPOT),實現基于時延預測的SLO-aware智能調度; |
2. 容器編排與資源調度
?
?部署靈活:PD分離部署,具有Group和Pool兩種模式,實現彈性擴縮容與拓撲感知調度。
?高可用機制:多副本部署,避免單點故障。同時支持故障時自動摘流與容器自愈,保障服務持續可用,用戶無感知。
?
| 核心能力 | 說明 |
| 容器編排 | 根據推理引擎工作特點,基于容器之間的協作關系(Kimi多容器跨機推理、PD分離架構等),將各個推理引擎容器一定的組織方式部署成一組Pods,并聯動服務發現、重啟策略。 |
| GPU資源調度 | 自動將各個新創建的Pod調度到具有足夠GPU資源的機器節點。 |
| 拓撲感知調度 | Kimi跨機推理, TP16部署的2臺機器保證在同一個交換機下;PD分離部署,協作關系的P和D在同一個交換機下。 |
| 優先級調度和搶占 | 支持在線服務和離線任務的混合調度,高優的在線服務可以搶占低優任務的GPU資源。 |
3. 系統穩定性與可觀測
?集成流量鏡像、全鏈路告警與主備值班協同機制。
?通過網關大盤、調度模塊監控、模型性能面板等多層次觀測體系,實現問題快速發現與定位。
?
?
4. 引擎優化與性能突破
針對MoE、多模態等模型特點,通過算子優化、引擎調優與量化等手段,在多項關鍵性能指標上實現行業領先。
?
二、關鍵場景落地與收益量化
1. 長短文混合調度
問題:長、短文請求混合排隊時,短文TTFT急劇上升,集群吞吐下降。 方案:通過長短文分桶與跨集群調度,實現長短文分離處理。
收益(以Kimi-K2與DeepSeek-V3壓測為例):
?Kimi-K2:短文TTFT降低90.97%,吞吐提升124.46%;長文吞吐提升33.89%,集群整體吞吐提升67%。
?DeepSeek-V3:短文TTFT降低79.09%,吞吐提升36.7%;長文吞吐提升14.34%,集群整體吞吐提升21.82%。
?
2. KV Cache全局感知的流量調度
問題:多副本場景下相同前綴請求被隨機調度,導致每個實例都重復計算并緩存相同前綴。 方案:持續刻畫更新集群級KV Cache緩存畫像,實現前綴匹配的智能路由,KV Cache高效復用。
收益:
?DeepSeek-V3場景下,集群吞吐提升29.9%,首Token時延TTFT降低28.7%;
?Kimi-K2場景下,KV Cache命中率整體提升20%~30%。
| 舊系統:均值 60%、22%、12% | 云原生系統:均值 90%、45%、22% |
 |
 |
3. 全場景自動彈性伸縮
問題:夜間或周末的流量低谷期GPU資源閑置嚴重。 方案:通過多種彈性部署模式并基于排隊長度與KV使用率等多項指標,實現全場景自動擴縮容。
收益:
?周級別節省GPU卡時5000+,資源利用率提升26%;
?
| 占用卡量:隨負載 彈性擴縮 |
 |
?
4. 硬件拓撲親和調度
問題:跨交換機部署導致性能下降;人工修正部署成本高,維護壓力大。 方案:
?通過節點標簽與親和性規則,實現交換機級自動拓撲親和調度;
?Router實現按組進行PD配對流量調度。
收益:
?組容器間通信不跨交換機,數據高效傳輸,全程自動化,無需人工干預,保證服務SLA。

?
5. 穩定性與業務連續性
問題:容器故障后,因分發機制導致持續的客戶影響。故障恢復強依賴人工,導致故障時間長,修復難度大。
方案:通過實時健康監測,快速感知故障容器,進行隔離。啟動新副本,實現故障自愈。
收益:
?實現自動隔離,自動自愈,無需人工干預,節點人力成本,提高用戶體驗。
?
?
6.推理引擎無感接入
問題:多引擎支持成本高,定制化開發量大,維護成本高。 方案:構建統一推理引擎調度接入層,支持vLLM、SGLang等不同推理引擎一鍵接入。
收益:
?推理引擎無感快速接入。
?降低開發與維護成本。
?
?
三、收益總結
京東云云原生AI推理框架通過多維度調度與系統級優化,顯著提升了推理效率與資源利用率。短文與長文吞吐均有大幅增長,首 token 延遲明顯降低,并結合自動彈性擴縮容與 KV Cache 感知調度,進一步提升集群吞吐與緩存命中率,同時節省可觀的 GPU 卡時成本。在此基礎上,引入硬件拓撲親和調度,實現更高效的自動化部署與調度,降低大規模集群運維壓力;配合故障自愈、高可用機制與更精細的可觀測體系,使系統運行更加穩定、可控、易排障。通過針對引擎瓶頸的持續優化,不同模型場景下的吞吐能力均得到明顯增強。
| 能力 | 量化結果與效益 |
| 長短文調度 | 吞吐:短文提升120%+,長文提升30%+ TTFT:短文降低90% |
| 自動彈性擴縮容 | GPU卡時:節省GPU卡時約26% |
| KV Cache感知調度 | 提升KV Cache命中率:增長約20%~30% TTFT:降低29% 集群吞吐:增長30% |
| 硬件拓撲親和調度 | 實現自動化部署與調度,降低大規模集群運維成本 |
| 故障自愈與高可用 | 自動檢測故障、自動恢復故障,減少對人工的依賴,更具可控性 |
| 可觀測性 | 具備更細致的監控告警體系、提升故障發現和排查效率 |
| 引擎瓶頸優化 | DS-MoE模型吞吐提升9%,多模態模型吞吐最高提升39% |
四、客戶案例
客戶背景
客戶原系統面臨AI規模化落地的挑戰,在推理系統的穩定性、性能和資源利用率方面遇到了明顯瓶頸。京東云通過幫助客戶升級至云原生架構,成功改造了其推理系統,實現顯著的性能提升和資源節約。見證了新系統如何帶來切實的業務效益。
解決方案
京東云通過云原生AI推理框架對客戶原78臺節點進行逐步云原生改造,在不到一個月時間內從最初的2%切流比率提升到達到40%,實現對用戶AI推理系統的云原生重構,助力企業實現高效、穩定、低成本的AI規模化落地。核心方案包括:采用智能流量調度技術,通過長短文分桶、KV緩存復用及拓撲感知調度;基于流量波動的彈性擴縮容機制;高可用架構通過多副本部署與故障自愈保障服務連續性;支持vLLM、SGLang等主流引擎的無感接入;硬件拓撲優化實現跨交換機親和調度,減少傳輸延遲。

客戶收益
?
?GPU吞吐能力:切換云原生系統后,GPU吞吐提升幅度達74%。這一增強使客戶在高負載情況下依然能夠維持高效的模型推理速度。
?限流數量:云原生AI推理框架系統將需要限流的請求顯著減少82%,這意味著更多的客戶請求在高峰時段得到及時響應,提高了用戶體驗和滿意度。
|
? |
整體 | 舊版系統 | 云原生系統 | 收益 |
| 機器規模 | 78 (100%) | 50 (64%) | 28 (36%) | - |
| 請求數量 | 36671 (100%) | 17091 (47%) | 19580 (53%) | - |
| GPU吞吐 (TGS) | - | 183 | 319 | 提升74% |
| 限流數量 | 687 ( 1.87%) | 570 (3.3%) | 117 (0.59%) | 減少82% |
| 備注: 1、數據來源基于Kimi-K2-instruct-0905模型。 | ||||
客戶對于系統的云原生改造表示高度認可:“云原生AI系統的導入,讓我們不僅在資源利用上實現了顯著的性價比提升,同時在關鍵業務高峰期的響應能力也大大增強,顯著減少了因限流帶來的服務瓶頸問題。”
?
?
五、未來展望
京東云將繼續優化云原生AI推理框架,致力于為客戶提供更智能、高效、穩定的AI基礎設施。通過在各個行業和應用場景中的深化應用,我們的客戶可以持續依賴這一平臺,實現業務的長期可持續發展。
這個成功案例不僅展示了京東云云原生AI推理框架系統的技術優勢,也為其他企業提供了一個可借鑒的成功模型,期待更多客戶從中獲益。
京東云云原生AI推理框架的研發升級并非一蹴而就。從架構設計、配置調試再到全量上線,每一步都圍繞著業務價值、性能提升與運維提效展開。我們相信,只有將穩定性、性能、成本三者統籌兼顧的基礎設施,才能真正支撐AI業務規模化、可持續地落地與增長。如您有類似場景或技術交流需求,歡迎隨時聯系我們。
-
gpu
+關注
關注
28文章
5194瀏覽量
135474 -
AI
+關注
關注
91文章
39793瀏覽量
301450 -
模型
+關注
關注
1文章
3752瀏覽量
52112
發布評論請先 登錄
英偉達失守中國區!推理需求爆發,國產GPU搶灘上市

堪稱史上最強推理芯片!英偉達發布 Rubin CPX,實現50倍ROI

大模型 ai coding 比較
AI推理芯片需求爆發,OpenAI欲尋求新合作伙伴
使用NORDIC AI的好處
推理<2ms!Ultralytics最新YOLO26+樹莓派+國產AI加速卡實現 500 FPS 端側 AI 性能巔峰!

曦望發布新一代推理GPU芯片,單位Token推理成本降低90%
端側推理:FPGA正崛起為“非GPU”陣營的中堅力量

華為數據存儲與「DaoCloud 道客」發布AI推理加速聯合解決方案
今日看點丨華為發布AI推理創新技術UCM;比亞迪汽車出口暴增130%
研華科技推出緊湊型邊緣AI推理系統AIR-120
信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代
算力革命:RoCE實測推理時延比InfiniBand低30%的底層邏輯
提升AI訓練性能:GPU資源優化的12個實戰技巧




 工商網監
工商網監
評論