 推理<2ms!Ultralytics最新YOLO26+樹莓派+國產AI加速卡實現 500 FPS 端側 AI 性能巔峰!
推理<2ms!Ultralytics最新YOLO26+樹莓派+國產AI加速卡實現 500 FPS 端側 AI 性能巔峰!

關鍵詞:YOLO26、樹莓派、國產AI加速卡、M5Stack、邊緣AI
速度快、功耗低、純國產,樹莓派終于有了真正實用的 AI 加速方案
近年來,隨著 AI 技術的爆發式發展,邊緣智能設備正成為行業布局的重點。從工業質檢到智能安防,從機器人視覺到車載感知,AI 模型正快速從“云端”走向“終端”。然而,邊緣設備往往受限于計算資源與功耗,如何在有限資源下實現高效、實時的 AI 推理,一直是技術落地的關鍵挑戰。
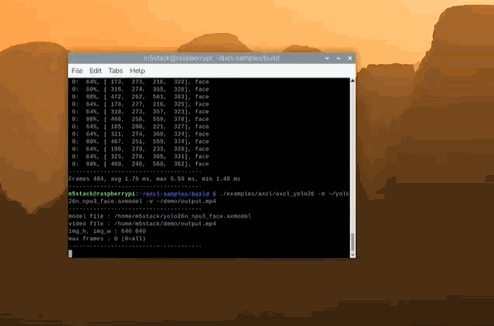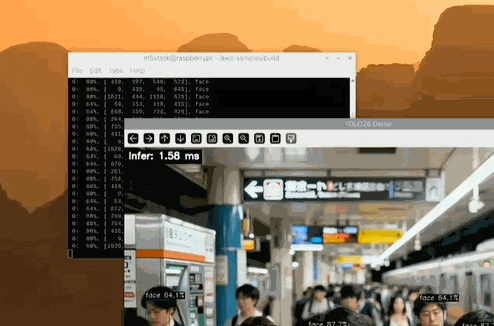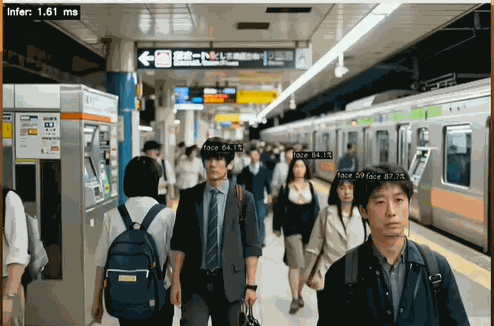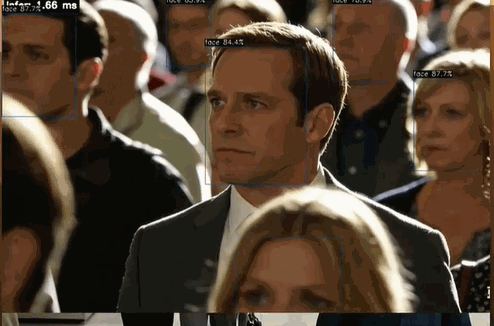
左上角可以清晰看到 Infer 時間 < 2ms
- Ultralytics 最新 YOLO26 +樹莓派+國產AI 加速卡實現 500 FPS 端側 AI 性能巔峰!
- 代碼:https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
- 模型:https://huggingface.co/AXERA-TECH/yolo26
- 文檔:https://docs.m5stack.com/zh_CN/ai_hardware/LLM-8850_Card
- 4000 字,閱讀 13 分鐘,播客 14 分鐘
相關推薦
- 讓手機CPU,GPU,NPU協同!浙大端側AI“超級記憶”AME硬件感知引擎:7倍索引加速,6倍插入提速,隱私與速度兼得!
- 小語言模型量化基準體系 SLMQuant:8 位近無損與 W4A8 低比特效能研究
- HeteroLLM:利用移動端 SoC 實現 NPU-GPU 并行異構 LLM 推理!以 高通8 Gen 3的NPU GPU為例
今天,我們為大家帶來一套純國產、高性能、易部署的邊緣 AI 解決方案:M5Stack LLM-8850-Card(國產 AI 加速卡)與Ultralytics YOLO26n(新一代端側檢測模型)的強強組合,讓樹莓派等低成本開發板也能輕松實現 < 2 ms 級目標檢測。

左上角可以清晰看到 Infer 時間 < 2ms
相比樹莓派單靠 CPU 運行 YOLO26n 模型,性能提升達幾十到幾百倍:
| 運行環境 | 模型 | 運行時間 | 備注 |
|---|---|---|---|
| ncnn | yolo26n(輸入尺寸640) | 63.30 ms | CPU 4線程 |
| pytorch | yolo26n(輸入尺寸640) | 288.6 ms | CPU,Ultralytics框架 |
| onnx | yolo26n(輸入尺寸640) | 133~142 ms | CPU,Ultralytics框架 |
| axmodel | yolo26n(輸入尺寸640) | 1.5~1.6 ms | 國產AI加速卡LLM8850 |
本文目錄unsetunset
- 一、YOLO26n:為邊緣而生的新一代檢測模型
- 二、M5Stack LLM-8850-Card:樹莓派 AI“小鋼炮”
- 2.1 硬件參數
- 2.2 NPU 工具鏈與軟件生態
- 2.3 部分模型 benchmark:視覺、LLM、VLM 模型
- 三、實戰:在樹莓派+LLM-8850 上跑通 YOLO26n
- 3.1 實現步驟:核心代碼講解
- 3.2 編譯與運行
- 四、性能實測:推理< 2ms,幀率高達 500+FPS
- 總結:國產邊緣 AI 生態正當時
交流加群請在NeuralTalk 公眾號后臺回復:加群
unsetunset一、YOLO26n:為邊緣而生的新一代檢測模型unsetunset
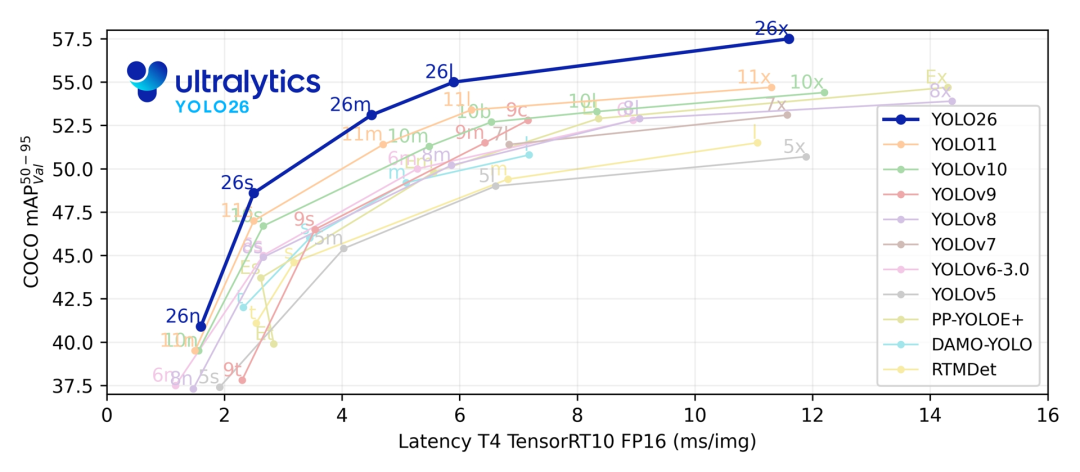 Ultralytics YOLO26 與系列前代模型的性能對比可視化。聚焦精度、推理速度、硬件適配性等核心維度。直觀呈現 YOLO26 在移除 DFL 模塊、采用 MuSGD 優化器后,于邊緣設備場景下的優勢
Ultralytics YOLO26 與系列前代模型的性能對比可視化。聚焦精度、推理速度、硬件適配性等核心維度。直觀呈現 YOLO26 在移除 DFL 模塊、采用 MuSGD 優化器后,于邊緣設備場景下的優勢
YOLO26 是 Ultralytics 在 2026 年發布的最新版本[1],專為邊緣與低功耗設備優化設計。其核心特點包括:
- 端到端無 NMS 推理:首次實現真正的端到端預測,無需后處理中的非極大值抑制(NMS),大幅簡化部署流程、降低延遲,提升系統穩定性。
- 去除 DFL 模塊:移除了傳統的分布焦點損失(DFL),提升模型導出兼容性,更適合各類邊緣硬件部署。
- CPU 推理性能大幅提升:相比前代,YOLO26 在 CPU 上的推理速度提升最高達 43%,為無 GPU 的設備帶來實時的 AI 處理能力。
- 支持多任務統一架構:一個模型家族覆蓋檢測、分割、分類、姿態估計、旋轉框檢測五大任務,極大簡化開發與維護成本。
下面表格展示了 YOLO26 系列 5 個不同規模模型在 COCO 目標檢測數據集上的核心性能指標,清晰呈現了模型精度、推理速度、參數量和計算量的權衡關系,為不同部署場景的模型選型提供依據。
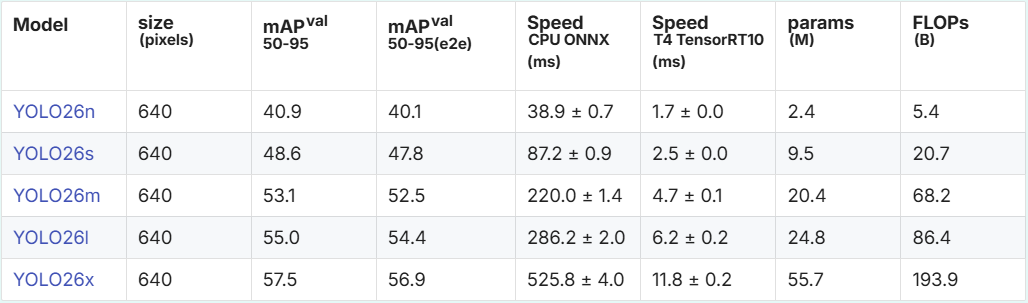
本次我們重點使用的是其最小尺寸版本——YOLO26n,其模型參數僅2.4M,在 COCO 數據集上仍能實現40.9% 的 mAP,是邊緣設備上平衡精度與速度的理想選擇。
unsetunset二、M5Stack LLM-8850-Card:樹莓派 AI“小鋼炮”unsetunset
盡管樹莓派等開發板生態豐富、用戶基數龐大,但其本身缺乏專用的 NPU(神經網絡處理單元),依賴 CPU 進行 AI 推理往往速度慢、占用率高,難以滿足實時性要求。雖然樹莓派官方有 Hailo 等加速方案,但多為國外芯片,國內開發者面臨采購與技術支持的不便。
2.1 硬件參數

在此背景下,深圳 M5Stack 基于愛芯元智(AXERA) AX8850國產 AI SoC,精心打造了一款M.2 M-KEY 2242 形態的 AI 加速卡——LLM-8850-Card,堪稱樹莓派 AI“小鋼炮”。
 LLM?8850Card 是一款面向邊緣設備的 M.2 M-KEY 2242 AI 加速卡,把 42mm 的袖珍體積與 Axera AX8850 SoC 的 24 TOPS@INT8 算力結合起來,為 Raspberry Pi 5、RK3588 SBCs、x86 PC 等主機 “一插即強” 地擴展多模態大模型與視頻分析能力
LLM?8850Card 是一款面向邊緣設備的 M.2 M-KEY 2242 AI 加速卡,把 42mm 的袖珍體積與 Axera AX8850 SoC 的 24 TOPS@INT8 算力結合起來,為 Raspberry Pi 5、RK3588 SBCs、x86 PC 等主機 “一插即強” 地擴展多模態大模型與視頻分析能力
這款計算模塊在性能與體積上實現了完美平衡:
- 它搭載了 AX8850 芯片,集成八核 Cortex-A55 CPU 并提供高達 24 TOPS @ INT8 的 NPU 算力,同時配備 8GB LPDDR4x 大內存,為多模型、多任務并行提供了充足的帶寬與強勁算力支持。
- 在多媒體處理方面,該模塊集成了強大的硬件視頻引擎,支持 8K H.264/H.265 編解碼,可同時處理 16 路 1080p 視頻流,從而實現“視頻+AI”的一站式高效處理。

盡管性能強大,其體積卻極為小巧精悍42.6 × 24.0 × 9.7 mm,采用 M.2 2242 標準尺寸,可直接插入樹莓派 5、RK3588 等開發板的 M.2 接口,真正做到即插即用;為了確保長時間滿載運行的穩定性,模塊還內置了微型渦輪風扇與鋁合金一體化散熱片,并由板載 EC 智能溫控系統進行精準調節。
2.2 NPU 工具鏈與軟件生態
Pulsar2 由愛芯元智自主研發 的 all-in-one 新一代神經網絡編譯器[2],即轉換、 量化、 編譯、 異構四合一,實現深度學習神經網絡模型快速、 高效的部署需求。
針對 NPU 特性進行了深度定制優化,充分發揮片上異構計算單元(CPU+NPU)算力, 提升神經網絡模型的產品部署效率。
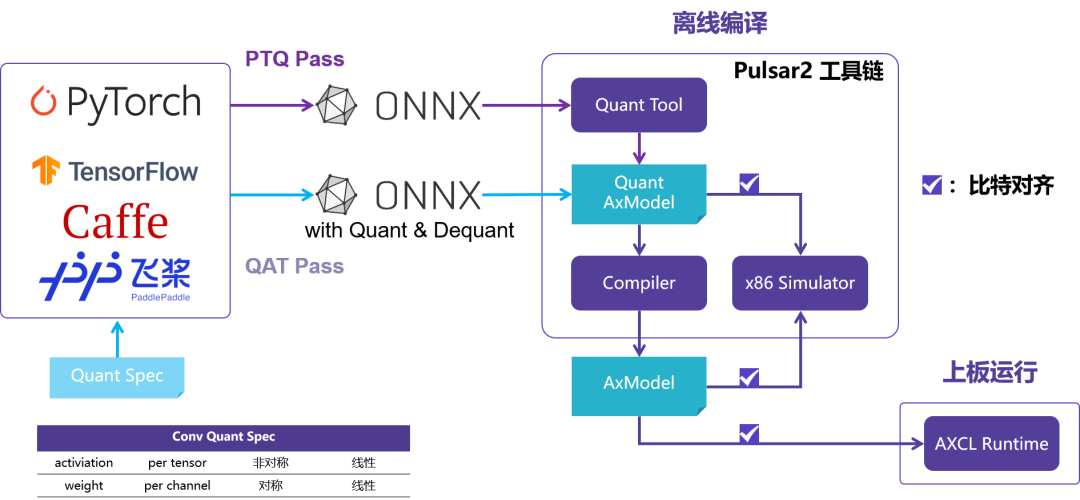 Pulsar2 NPU 工具鏈從模型量化到部署全流程:從 PyTorch/TensorFlow 等框架導出 ONNX 模型,經 Pulsar2 工具鏈量化、編譯,生成 AxModel,經比特對齊驗證后,通過 AXCL Runtime 在上板運行
Pulsar2 NPU 工具鏈從模型量化到部署全流程:從 PyTorch/TensorFlow 等框架導出 ONNX 模型,經 Pulsar2 工具鏈量化、編譯,生成 AxModel,經比特對齊驗證后,通過 AXCL Runtime 在上板運行
而AXCL[3]是用于在 AXERA 芯片平臺上開發深度神經網絡推理、轉碼等應用的 C、Python 語言 API 庫。其能力提供運行資源管理,內存管理,模型加載和執行,媒體數據處理等 API。
在軟件生態上,基于完善的AXCL Runtime[4]能力,其不僅支持 C / Python API,更已集成對 YOLO 系列、CLIP、Whisper、Llama3.2、InternVL3、Qwen3 等主流 CNN、Transformer、LLM 與多模態模型的一鍵部署能力,極大地降低了開發門檻。
2.3 部分模型 benchmark:視覺、LLM、VLM 模型
下面是部分視覺、LLM、VLM 模型 benchmark 數據,更多數據見 benchmark[5]:
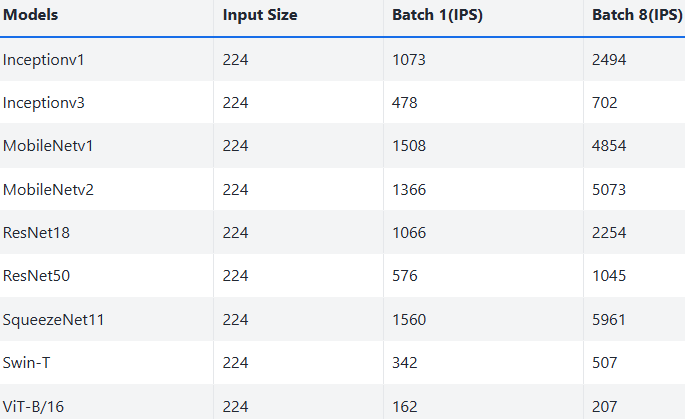
Vision 模型在 NPU 上的推理性能測試表,IPS 是每秒處理圖像數(Images Per Second),是衡量計算機視覺(CV)模型推理速度和吞吐量的核心指標
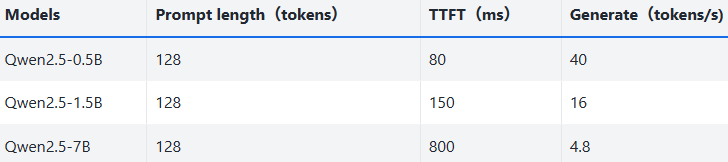
LLM 模型在 NPU 上的性能測試表,展示 Qwen2.5 系列(0.5B/1.5B/7B)在 128 tokens 提示下的表現:TTFT 是首次 token 生成延遲(數值越小越快),Generate 是持續生成速度(數值越大越快),模型參數量越大,性能通常越低
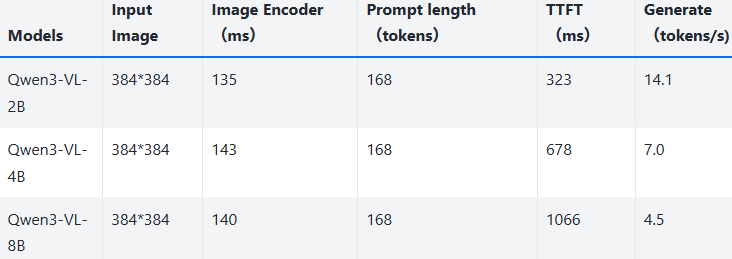
Qwen3-VL 多模態模型的 NPU 性能測試表,展示 2B/4B/8B 參數量版本的表現:輸入圖像規格均為 384*384,提示詞長度 168 tokens;參數量越大,圖像編碼器耗時、首次 token 生成延遲(TTFT)越高,持續生成速度(tokens/s)越低
unsetunset三、實戰:在樹莓派+LLM-8850 上跑通 YOLO26nunsetunset
目前,愛芯元智官方已在開源倉庫axcl-samples[6]中提供了YOLO26 在 AX8850 平臺上的完整 C++ 示例代碼,并已將預訓練模型發布在HuggingFace[7]上。
3.1 實現步驟:核心代碼講解
以下是基于ax_yolo26_steps.cc的核心實現步驟解析如下:
原始圖像 → Letterbox縮放 → RGB轉換 → 設備內存 → NPU推理
↑ ↓
保存結果 ← 繪制框 ← 坐標映射 ← 多尺度解析
- 步驟一:讀圖
- 使用OpenCV的cv::imread,默認BGR格式,保持原始分辨率
- 代碼中檢查了圖像是否為空,有錯誤處理
- 步驟二:Letterbox 預處理
- 關鍵算法:保持長寬比的縮放,不足部分填充灰色
- 數據排布:轉換為HWC格式的RGB連續內存
- 優化:避免了不必要的內存拷貝,直接操作原始數據
- 步驟三:設備初始化
- 禁用虛擬NPU,使用物理NPU
- 只初始化一次,后續可重復使用
- 步驟四:模型加載與輸入
- 模型格式:.axmodel是 AXera 平臺專有的優化模型格式
- 預熱:5 次預熱推理,避免首次推理的冷啟動延遲
- 步驟五:推理過程。輸出結構為:6個tensor = 3個尺度 × (box + cls)
- box: 4個值(x, y, w, h)或者(x1, y1, x2, y2)
- cls: 80個類別的置信度
- 計時:精確記錄每次推理時間,用于性能分析
- 步驟六:后處理,generate_proposals_yolo26() → 坐標映射 → 繪制
- 坐標轉換:從 640×640 的 letterbox 坐標映射回原始圖像坐標
- 多尺度融合:3個尺度(80×80, 40×40, 20×20)分別處理后合并
- 可視化:不同類別用不同顏色,顯示類別名和置信度
通過 “讀圖 → Letterbox → 上電 → 喂模型 → 推理 → 后處理”這 6 步,就把整個 AXCL-YOLO 流程串起來了。完整代碼見examples/ax650/ax_yolo26_steps.cc[8]。
3.2 編譯與運行
了解了執行流程,下面先給出我們編譯axcl-samples[9]和推理圖片的視頻,性能結果包含推理時間,后處理時間等,最后會有推理結果展示。
為了方便大家復制粘貼,下面給出視頻中用到的腳本和相關文件如模型、圖片等。
1. 編譯 axcl-sample
gitclonehttps://github.com/Abandon-ht/axcl-samples.git
cdaxcl-samples
mkdir build
cdbuild/
cmake ..
make -j4
2. 輸入圖片并執行推理
# 拉取代碼倉庫
wget -c https://github.com/Abandon-ht/YOLO26.axera/releases/download/v0.2/bus.jpg
# 下載 yolo26n 模型
wget -c https://github.com/Abandon-ht/YOLO26.axera/releases/download/v0.2/yolo26n_npu3_new.axmodel
# 執行推理
./examples/axcl/axcl_yolo26 -m yolo26n_npu3_new.axmodel -i bus.jpg
上面最后一行命令會執行推理,如下所示:

檢測結果如下圖所示:

檢測結果為 1.59 ms,執行日志詳情如下:

unsetunset四、性能實測:推理< 2ms,幀率高達 500+FPSunsetunset
作為性能實測的對比,下面是樹莓派 CPU A76 運行 yolo26n 的性能數據:
| 運行環境 | 模型 | 運行時間 | 備注 |
|---|---|---|---|
| ncnn | yolo26n(輸入尺寸640) | 63.30 ms | CPU 4線程 |
| pytorch | yolo26n(輸入尺寸640) | 288.6 ms | CPU, Ultralytics框架 |
| onnx | yolo26n(輸入尺寸640) | 133~142 ms | CPU,Ultralytics框架 |
| axmodel | yolo26n(輸入尺寸640) | 1.5~1.6 ms | 國產AI加速卡LLM8850 |
將代碼從圖片檢測修改為視頻檢測,即圖片輸入改成攝像頭讀取輸入。cv::imwrite改成cv::show效果如下:
左上角可以清晰看到 Infer 時間 < 2ms

左上角 Infer 時間在 1.60 ms 左右
unset
結合根據社區實測與官方示例數據,在M5Stack LLM-8850-Card + YOLO26n組合下:
- 單幀推理時間(含前后處理)可穩定在2 毫秒以內。
- 相當于500+ FPS的超高幀率,足以應對絕大多數實時視頻流分析場景。
- 相比樹莓派單靠 CPU 多線程運行 YOLO26n 模型,性能提升相比 CPU 多線程達幾十到幾百倍,且 CPU 占用率大幅降低。
完整實測視頻如下
注:左上角為推理時間,需要說明的是,在遠程桌面 + Raspberry Pi 這種場景下,推理時間比觀察到的 FPS 更可靠,原因如下:
- 顯示瓶頸不影響推理時間:遠程桌面傳輸和屏幕渲染可能成為瓶頸(比如只能達到 60 FPS),但這不代表模型本身慢
- 推理時間能準確反映 "預處理→推理→后處理" 的真實計算耗時
綜合上面性能表現,使得樹莓派這類低成本、高普及率的開發板,真正具備了部署實時多路視頻 AI 分析的能力,可廣泛應用于:
- 智能安防:人臉識別、行為分析、車牌識別。
- 工業視覺:零件質檢、缺陷檢測、流水線監控。
- 機器人:實時環境感知、自主導航、手勢交互。
- 教育與創客:低門檻的 AI 項目開發與原型驗證。
unsetunset總結:國產邊緣 AI 生態正當時unsetunset
M5Stack LLM-8850-Card與YOLO26n的組合,不僅為樹莓派用戶提供了一個高性能、易用的 AI 加速方案,更展現了國產芯片與開源算法在邊緣計算領域的深度融合與快速落地能力。
對于開發者而言,這意味著:
- 更低的門檻:無需復雜硬件設計,插卡即用。
- 更高的性能:毫秒級推理,滿足實時性要求。
- 更優的成本:國產方案性價比突出,供貨穩定。
- 更全的生態:從芯片、硬件到算法、示例[10],全棧開源支持。
目前,相關代碼、模型與文檔均已開源,歡迎開發者前往以下鏈接獲取資源,親手體驗這款“國產小鋼炮”帶來的邊緣 AI 加速魅力:
- 代碼倉庫:https://github.com/AXERA-TECH/ax-samples[11]
- 模型下載:https://huggingface.co/AXERA-TECH/yolo26[12]
- 產品信息:M5Stack LLM-8850-Card[13],https://docs.m5stack.com/zh_CN/ai_hardware/LLM-8850_Card
邊緣 AI 的未來,正在每一位開發者的手中加速到來。
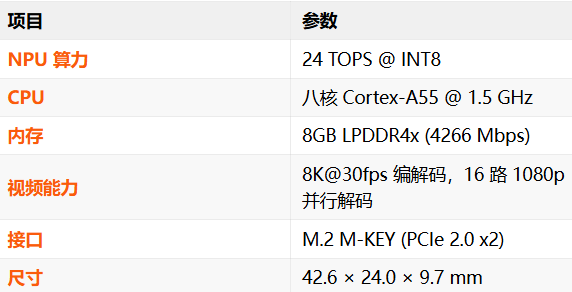
M.2 M-KEY 2242 形態的 AI 加速卡——LLM-8850-Card關鍵參數如下所示:
除了本文的 YOLO26n 模型,LLM-8850 還支持更多模型,關于入額快速上手和支持模型列表(包含VLM、LLM、多模態、音頻、生成模型等)見:https://docs.m5stack.com/zh_CN/guide/ai_accelerator/overview
參考資料[1]
Ultralytics YOLO26:https://docs.ultralytics.com/models/yolo26/
[2]
Pulsar2 工具鏈:https://pulsar2-docs.readthedocs.io/zh-cn/latest/pulsar2/introduction.html
[3]
AXERA 運行時庫 AXCL:https://axcl-docs.readthedocs.io/zh-cn/latest/doc_introduction.html
[4]
the python api for axengine runtime:https://github.com/AXERA-TECH/pyaxengine/
[5]
NPU Benchmark:https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_npu_benchmark.html
[6]
ax-samples:https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
[7]
YOLO26 模型:https://huggingface.co/AXERA-TECH/yolo26
[8]
ax-samples:https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
[9]
ax-samples:https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
[10]
doc_guide_npu_samples:https://axcl-docs.readthedocs.io/zh-cn/latest/doc_guide_npu_samples.html
[11]
examples/axcl/ax_yolo26_steps.cc:https://github.com/AXERA-TECH/axcl-samples/blob/main/examples/axcl/ax_yolo26_steps.cc
[12]
huggingface.co/AXERA-TECH/yolo26:https://huggingface.co/AXERA-TECH/yolo26
[13]
M5Stack LLM-8850-Card:https://docs.m5stack.com/zh_CN/ai_hardware/LLM-8850_Card
-
AI
+關注
關注
91文章
40494瀏覽量
302088 -
加速卡
+關注
關注
1文章
74瀏覽量
11357 -
樹莓派
+關注
關注
122文章
2080瀏覽量
110626
發布評論請先 登錄
國內首個國產AI推理千卡集群落地,采用云天勵飛全自研AI推理芯片
Hailo-8算力卡 + RK3588實測!26TOPS加持,助力AI視覺升級!

新品 | LLM-8850 Kit,高性能AI加速卡套件 DinMeter v1.1,1/32DIN標準嵌入式開發板

邁向云端算力巔峰:昆侖芯K200 AI加速卡全面解讀

算力密度翻倍!江原D20加速卡發布,一卡雙芯重構AI推理標桿

愛芯元智攜手合作伙伴M5Stack亮相YOLO Vision 2025

此芯科技發布“合一”AI加速計劃,賦能邊緣與端側AI創新

這個套件讓樹莓派5運行幾乎所有YOLO模型!Conda 與 Ultralytics!

如何在樹莓派 AI HAT+上進行YOLO姿態估計?
如何在樹莓派 AI HAT+上進行YOLO目標檢測?
新品上線|Maix4-HAT 大模型 AI 加速套件 ,一鍵解鎖樹莓派多模態 AI 力量!

完整指南:如何使用樹莓派5、Hailo AI Hat、YOLO、Docker進行自定義數據集訓練?

邊緣AI運算革新 DeepX DX-M1 AI加速卡結合Rockchip RK3588多路物體檢測解決方案




 工商網監
工商網監
評論