 自動駕駛攝像頭為什么很難處理純色背景場景?
自動駕駛攝像頭為什么很難處理純色背景場景?

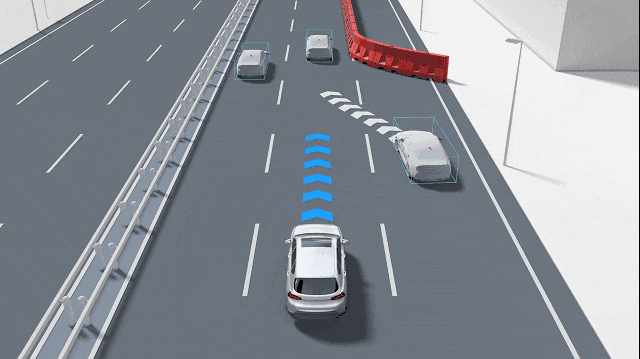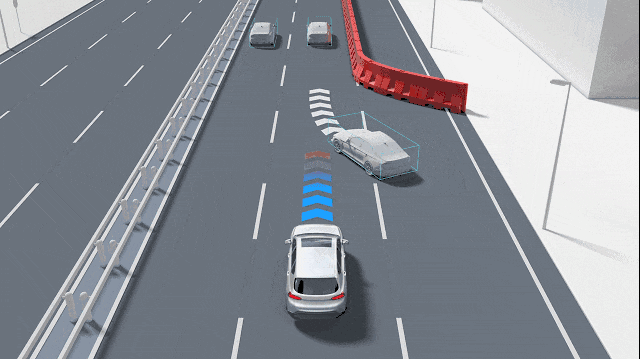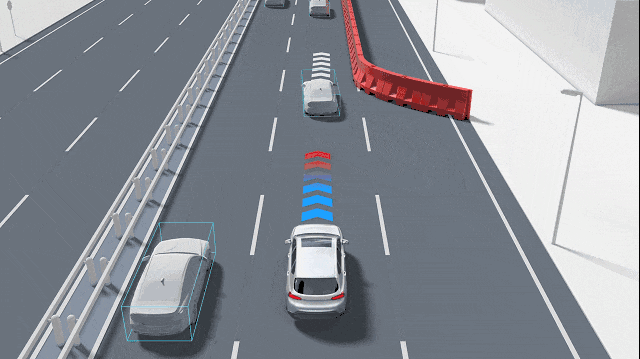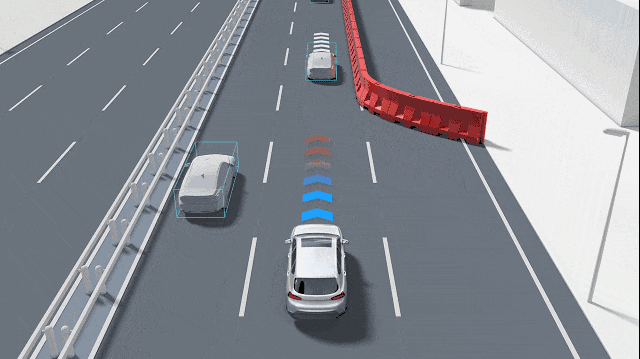
[首發于智駕最前沿微信公眾號]在自動駕駛技術的感知體系中,攝像頭一直被視為復刻人類視覺能力的核心組件。這種傳感器通過捕捉環境光線并將其轉化為像素矩陣,為車輛提供識別交通標志、車道線以及其他交通參與者的基礎。然而,在實際的駕駛場景中,攝像頭經常會遭遇一種極其棘手的情況,那就是面對如一堵粉刷平整的白墻、一輛橫向行駛的白色大型貨車,或是一片晴朗無云的藍天等大面積的純色、無紋理背景。在這種環境下,原本高度智能的視覺算法會出現性能驟降,甚至完全失去對前方障礙物的感知能力。
計算機是如何“看”世界的?
要理解為什么攝像頭難以識別純色背景,首先需要知道計算機是如何“看”世界的。與人類大腦能夠基于常識理解“這是一塊平整的墻面”不同,計算機視覺系統必須通過尋找圖像中的特征點構建對場景的認知。這些特征點通常是圖像中如角點、邊緣或特定的紋理模式等亮度變化劇烈的區域。在紋理豐富的場景中,算法可以從樹木的枝葉、路面的裂紋或建筑的窗戶中提取出成千上萬個具有唯一性的數學描述符。這些描述符使系統能夠在連續的視頻幀之間追蹤物體,或者在雙目相機的左右圖像中找到同一個物理點的對應位置。
當攝像頭面對純色背景時,圖像中的像素點呈現出的是極高的齊次性,這意味著在相當大的區域內,像素的亮度值和顏色值幾乎完全一致,這種場景的紋理強度極低。在很多技術中,常用灰度共生矩陣來定量描述這種空間分布的特性。通過計算同質性、能量、相關性和對比度等指標,可以發現純色背景在能量和同質性上表現極高,但在對比度和差異性上幾乎為零。這種極端的數據分布直接導致特征提取算子失效。無論是SIFT算法還是SURF算法,它們的設計初衷都是尋找梯度的變化。當一個區域內所有方向的梯度都趨近于零時,算法將無法提取到任何有效的關鍵點。

圖片源自:網絡
這種特征點的缺失會迅速引發連鎖反應,首當其沖的就是“對應關系問題”。在自動駕駛的深度估計中,無論是雙目視覺還是多視圖幾何,其核心都是通過計算視差來推斷距離。系統需要在兩張具有微小視差的圖像中找到相同的特征,然后通過三角形測量原理計算出物體到攝像頭的距離。如果圖像中只有一片純白的畫面,系統將無法確定左圖中某個像素點對應右圖中的哪一個位置。這種匹配歧義會導致深度圖在這些區域產生大量的空洞或錯誤噪聲點。由于系統無法在純色物體上建立可靠的對應關系,它可能錯誤地認為前方是一片虛無的空曠區域,或者是將極遠處的背景信息錯誤地投影到了近處的物體上。
此外,這種危機在運動恢復結構(SfM)和視覺里程計(VO)中同樣存在。自動駕駛車輛依靠追蹤場景中的靜態特征來估計自身的位移和姿態變化。當車輛進入一個像是地下車庫等充滿無紋理白墻和立柱的環境時,SfM會因為無法建立跨幀的特征對應而導致跟蹤丟失。這種感知能力的“失明”對于依賴視覺定位的系統來說是致命的,因為它直接剝奪了車輛感知自身運動和周圍幾何結構的能力。

純色區域在數學建模中的問題
純色背景帶來的挑戰不僅停留在靜態特征的提取上,它還深深扎根于動態感知所需的數學模型中。光流(Optical Flow)是自動駕駛系統感知物體運動矢量的重要手段,其核心假設是“亮度恒定”,即圖像中某個物理點在運動過程中,其像素亮度值保持不變。基于這一假設,我們可以得到基本的光流約束方程:Ixu+Iyv+It=0,其中Ix,Iy是圖像的空間梯度,It是隨時間變化的亮度梯度,而(u,v) 是我們要求解的像素運動速度。
在純色或紋理極其稀疏的區域,由于亮度分布非常均勻,圖像的空間梯度Ix和Iy幾乎全部為零。從代數角度看,這導致了一個“病態問題”,我們只有一個包含兩個未知數(u,v)的線性方程,且系數項趨近于零。在這種情況下,方程將有無數個解,或者說解對于噪聲極其敏感。在物理上,這表現為“孔徑問題”。即當一個純色的邊緣移動時,如果觀察范圍受限,系統只能感知到垂直于邊緣方向的運動,而無法感知平行于邊緣方向的運動分量。如果整個區域連邊緣都沒有,即完全的純色,那么系統將無法判斷物體是否在移動。

圖片源自:網絡
這種數學上的不確定性迫使算法需引入額外的正則化約束,例如假設光流場是全局平滑的。像是Horn-Schunck方法就是通過最小化包含平滑項的能量泛函來強制生成稠密的光流圖。然而,在處理大面積純色背景時,這種平滑假設會產生誤導。算法可能會將有紋理區域(如路面)的運動趨勢錯誤地傳播到純色區域(如白色車身),從而產生虛假的運動估計。這種“虛假感知”在復雜的交通流量中極其危險,因為它可能導致自動駕駛決策層誤判障礙物的實際速度和軌跡。
純色背景一般是如墻壁或大型車輛的側面等平面幾何結構,在多視圖幾何中,平面上的點滿足單應性矩陣(Homography)變換,即x'=Hx。單應性描述了兩個視圖之間平面的投影關系,具有8個自由度。雖然單應性矩陣可以用來對平面進行重構,但前提依然是必須在平面上找到足夠的對應點對。當平面完全純色時,單應性矩陣的解算會變得極不穩定。任何微小的像素噪聲都會導致重構出來的平面發生劇烈的偏轉或產生錯誤的距離估計。這種幾何重構的失敗,使得攝像頭難以精確計算出與大型純色物體(如橫向擋在路中間的白色貨車)之間的物理距離,從而無法及時觸發緊急制動。
物理環境中的光影挑戰與傳感器極限
理論上的數學難題在復雜的真實駕駛環境中會被物理因素放大,攝像頭的成像質量極大地依賴于光照條件和物體的表面材質。自動駕駛中一個常見的假設是“朗伯反射”,即假設物體表面是粗糙的啞光面,能夠將入射光向各個方向均勻散射。然而,像是白色烤漆的車身、光滑的建筑物外墻或反光的金屬表面等很多純色物體,都具有顯著的鏡面反射特性。
鏡面反射會在物體表面產生眩光和熱點,這些高亮區域對于攝像頭來說就是失去細節的“純白色塊”。在這種過曝光的區域,原本可能存在的微弱紋理會被傳感器的飽和電流徹底淹沒。當強烈的陽光直射在白色大貨車側面時,該表面在攝像頭畫面中呈現出的亮度和顏色可能與背景中過曝的天空完全一致。這種極低對比度的環境使得基于像素差異的感知系統徹底癱瘓。2016年在美國佛羅里達州發生的特斯拉Autopilot事故,正是由于系統未能分辨出陽光下白色的拖車側面與明亮的天空背景,導致車輛在未采取任何減速措施的情況下直接撞擊了貨車。

圖片源自:網絡
傳感器的信噪比(SNR)也是限制其處理低對比度純色場景的關鍵物理因素。在亮度極其均勻的區域,圖像中的微小波動往往不是來自物體的真實特征,而是來自傳感器的散粒噪聲和熱噪聲。對于圖像處理算法而言,這些噪聲會被誤認為是微弱的紋理,從而產生雜亂無章的虛假特征點。當環境光較暗或對比度極低時,有用信號將淹沒在噪聲中,SNR將顯著下降,系統對物體邊界的提取能力會變得極其微弱。軟件層面的降噪算法雖然可以平滑圖像,但代價往往是模糊了原本就難以察覺的微弱對比度邊界,這進一步加劇了識別的難度。
此外,材質的反射屬性還會隨著觀察角度的變化而發生劇變。對于人類駕駛員來說,我們可以通過偏振現象或環境倒影識別出光滑表面的存在,但現有的自動駕駛攝像頭大多缺乏捕獲這些高級物理特性的能力。
純色背景下的陰影處理也是一個難題。在缺乏紋理的白色墻面上,陰影具有極其清晰的人造邊緣,算法極易將這些由光照產生的臨時邊緣誤認為是物理實體的邊界,從而在建圖和定位時引入嚴重的拓撲錯誤。
從主動探測到全局注意力機制的演進
既然攝像頭在處理純色背景時存在難以逾越的天然障礙,很多技術方案開始轉向多維度、跨領域的感知增強方案。目前最主流的路徑是打破“被動視覺”的局限,引入具有主動探測能力的傳感器。
激光雷達(LiDAR)是應對純色背景最有效的武器之一。由于激光雷達不依賴環境光,而是通過發射近紅外激光并接收回波來測量距離,它對物體的顏色和表面紋理完全免疫。攝像頭看來是一片虛無白墻的場景,在激光雷達的原始點云中卻能呈現出精確的平面幾何結構。這種幾何信息的引入,為視覺感知提供了一個堅實的“地基”,使得系統即便在圖像特征缺失的情況下,依然能夠通過多傳感器融合確認障礙物的存在。
另一種在視覺系統內部進行的改進是引入“主動雙目視覺”。通過在攝像頭組件中集成一個紅外圖案投影儀,系統可以向原本無紋理的純色表面投射特殊的隨機散斑圖案。這些人為制造的散斑在攝像頭畫面中將形成豐富的“偽紋理”,從而讓匹配算法能夠在原本無法識別的白墻或純色板材上找到對應的特征點。這種技術已經在室內物流機器人和部分高級乘用車中得到了應用,極大地提升了系統在極簡裝修環境下的三維建模能力。
在極端惡劣天氣或光照條件下,門控成像技術展現出了巨大的潛力。該技術利用高速脈沖激光和同步快門,通過在時間軸上對光線進行“切片”,只保留特定距離范圍內的反射信號。這不僅能有效濾除雨霧產生的反向散射,還能在成像時極大增強物體的輪廓對比度。即使在面對純色物體時,門控成像也能通過距離切片的邊緣識別出物體的三維形貌,而不會像普通攝像頭那樣受限于表面的顏色分布。
此外,感知算法也正在從依賴局部特征的卷積神經網絡(CNN)向具備全局建模能力的視覺Transformer演進。CNN的核心操作是局部卷積核,這意味著它只能看到一個很小的像素窗口。如果這個窗口內全是白色,CNN將無法提取任何有意義的信息。而Transformer利用自注意力機制,能夠捕捉整張圖像中的長程依賴關系。即便某個局部區域是純色的,Transformer也可以根據該區域與遠處路面、天空、交通燈或其他已知紋理區域的相對位置關系,通過全局上下文信息推斷出該區域的語義屬性。這種從“局部看圖”到“全局看場”的轉變,為解決純色背景下的感知缺失提供了軟件層面的可能性。
最后的話
自動駕駛攝像頭在純色背景下的問題,是算法特征依賴與物理成像極限共同作用的結果。雖然這種“視覺荒漠”曾導致嚴重的事故,但隨著主動傳感器的普及以及深度學習架構從局部特征向全局語義的跨越,自動駕駛系統正在構建更加魯棒的多維感知網絡。未來的感知系統將不再僅僅是被動地接收圖像,而是能夠像人類一樣,通過主動探索和全局邏輯推理,在純色背景中準確地洞察危險。這不僅需要更先進的硬件,更需要在數學模型層面實現從“像素匹配”到“語義理解”的提升。
審核編輯 黃宇
-
算法
+關注
關注
23文章
4784瀏覽量
98038 -
自動駕駛
+關注
關注
793文章
14879瀏覽量
179782
發布評論請先 登錄
油電同智?為什么燃油車很難做自動駕駛?

高清數字攝像頭視頻卡頓?黑屏?

自動駕駛汽車如何依靠攝像頭判斷距離?

純視覺自動駕駛的優勢和劣勢有哪些?

自動駕駛攝像頭要如何做標定?
自動駕駛既然有雙目攝像頭了,為什么還要三目攝像頭?

實戰指南:用攝像頭模塊實現多場景智能拍攝全流程!

多場景智能拍攝實戰:攝像頭模塊集成與調試指南!
自動駕駛技術發展會讓邊緣場景的范圍發生改變嗎?
決定自動駕駛攝像頭質量的因素有哪些?
自動駕駛汽車如何處理“鬼探頭”式的邊緣場景?
激光振鏡掃描錫焊技術在車載攝像頭模組中的應用
自動駕駛汽車是如何準確定位的?
索尼FCB-EV9520L攝像頭:賦能自動駕駛新體驗
一文聊聊自動駕駛攝像頭



 工商網監
工商網監
評論