 從炫技到量產,具身智能要突破哪些瓶頸?
從炫技到量產,具身智能要突破哪些瓶頸?


2025年年初,機器人在春晚舞臺顫顫巍巍,被網友調侃“像看到了我太奶”,等到年底,已能街舞唱跳、動作流暢。2025年具身智能的能力表現與大眾關注度,都經歷了一場飛躍。
但真正身處具身智能一線的從業者,卻清晰地看到,熱鬧之下,無形的斬殺線或將淘汰掉大量玩家。
美國明星具身智能公司Physical Intelligence的研究者曾公開表示,“它們仍經常失敗,目前狀態更像是‘演示就緒’而非‘部署就緒’”,并總結了落地難的具體難關,包括復雜任務執行能力、環境泛化能力與高可靠性性能。
在開發者社區,類似的困境比比皆是。經常見到工程師發帖求助:“我們的具身智能機器人在真實環境中總是撞墻,仿真里明明表現完美!”
解決起來卻十分困難,因為提升可靠性,意味著指數級增長的訓練輪次和算力投入。這就像一場障礙賽,每一關都可能擋住開發者的腳步。
開發者迫切需要一個更高的起跳點,一個能低成本啟動、快速迭代、真實可落地的基座。
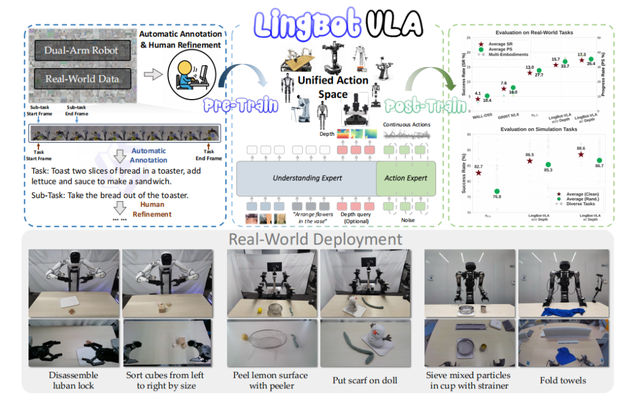
值得關注的是,近期一項來自中國團隊的開源進展,正在為這一困局提供切實可行的出口。由靈波科技發布的具身智能基座模型 LingBot-VLA,已在星海圖、松靈等多家國產本體廠商的真實機器人上完成端到端驗證。在統一的真機評測基準下,其整體任務成功率與泛化表現已超越Physical Intelligence的 Pi0.5,后者長期被視為行業性能標桿。
而LingBot-VLA 的泛化能力,部分源于其對高質量三維空間信息的深度融合,這是LingBot-Depth 模型所提供的核心能力,也在1月27日同步開源。
不難看到,開源,正在成為改變行業的一股關鍵力量,如何幫助開發者更輕松地通關?

2025年被業內人士稱為人形機器人的量產元年,但智源研究院院長王仲遠卻指出,具身智能距離真正的“ChatGPT時刻”尚有距離。
真正的“ChatGPT時刻”,需要全球上億臺機器人每天在真實環境中產生動作、觸覺、決策等全模態數據。而當前具身智能每個任務都要單獨訓練,每臺機器人都是孤島,每次部署都從零開始,陷入專用性強、泛化性弱、效率低的死循環。這種模式難以規模化。
具體來說,行業正被三條斬殺線所圍困:
一、數據荒。王仲遠院長曾提過,即使是幾十萬小時的數據,也稱不上海量,遠遠沒有達到引發智能涌現的量級。傳統仿真環境構建成本高、效率低,而真實世界數據采集又極其困難。具身智能企業普遍將數據視為核心資產,私有數據集高度封閉,而開源社區的數據集多局限于簡單任務,復雜場景數據稀缺且缺乏統一質量標準。缺乏高質量真機數據,成為中小團隊的第一道斬殺線。
二、效果差。由于數據有限,大量開源模型只在仿真環境中跑分,但仿真數據無法完全替代真實數據。一旦部署到真機,性能斷崖式下跌。加上一些模型只開放權重,后訓練代碼是閉源的,開發者拿得到也用不好。泛化性太差,導致機器人的性能表現和成功率不佳,產品競爭力低下,構成第二道斬殺線。
三、高成本。讓機器人在物理世界中“高效犯錯”,需要海量試錯。但每一次試錯,都是真金白銀。某具身智能創業公司曾測算,“訓練一個倒水動作,需要一臺超算運算千萬億次……光是模擬人晃動杯中的水這一個動作,所涉及的計算量可能就需要一臺超級計算機算十分鐘”。高昂的試錯成本與開發周期,會讓很多企業在成功之前就被斬殺。
不解決這些問題,機器人的規模量產與商業成功就十分遙遠。下面我們就來聊聊,星海圖、松靈等多家本體廠商的解法。

從公開Demo視頻來看,星海圖、松靈等廠商基于開源基座LingBot-VLA,實現了幾個飛躍:
從“一機一腦”到“通用智能大腦”,顯著降低了數據門檻。傳統模式下,不同構型機器人需要大量采集數據訓練模型。LingBot-VLA實現了跨本體復用,同一模型經過少量數據微調可控制不同構型機器人,執行剝檸檬、疊毛巾等上百種任務,減輕中小團隊的開發難度。

從“演示就緒”到“部署就緒”。
正如Physical Intelligence的研究者所說,機器人目前狀態更像是“演示就緒”而非“部署就緒”。傳統模型只能執行單一指令,真實部署時性能大跌。LingBot-VLA具備快速適應不同任務的能力,無論是抓取、放置,還是疊衣服、擦拭桌面,同一個模型全部應對,解決了專用性強、泛化性弱的問題。
LingBot-VLA在GM-100真機評測基準(覆蓋3類主流雙臂機器人、100項復雜任務、每任務130次真機試錯)上,平均成功率(SR)達17.30%,超越Pi0.5的13.02%。比指標更重要的,是多家本體廠商在真實硬件上完成了對LingBot-VLA的驗證,這意味著行業終于有一個不吹牛、能落地的模型了。
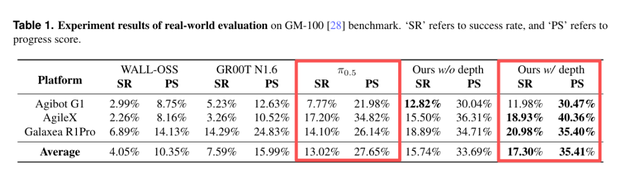
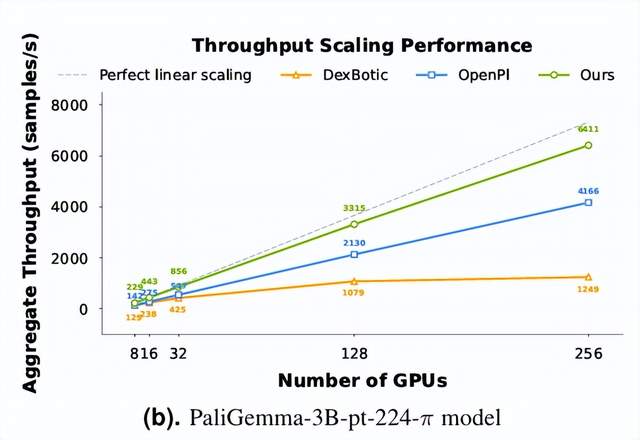
從燒錢試錯到低成本迭代。LingBot-VLA在8、16、32、128和256張GPU配置下,訓練效率都超越了OpenPI和DexBotic。而且GPU數量越大,優勢越突出。也就是說,基于LingBot-VLA可以大幅縮短訓練周期,降低開發的綜合成本。省下的算力和時間都是錢,意味著企業和開發者可以反復迭代、快速試錯,在激烈的市場競爭中搶占先機。
這是業內首次出現一個真正面向通用操作、跨本體部署的通用智能底座,也是具身智能迎來ChatGPT時刻的先決條件。
不少原本觀望的開發者,在看到星海圖、松靈等廠商的真機驗證之后,都紛紛表示要去GitHub/Hugging Face找代碼試試。
那么,LingBot-VLA到底是怎么做到的?

Physical Intelligence的Pi0.5一直是具身智能領域的性能標桿,LingBot-VLA在性能與效率上顯著超越Pi0.5,標志著開發者從此有了一個強大、高性能的開源武器。通過論文,我們來詳細拆解這把武器有哪些不同。
首先也最難的是跨本體,不同機器人在關節數量、自由度、末端執行器、傳感器布局上天差地別,如何屏蔽多元且復雜的硬件差異?
LingBot-VLA 的解法是,接收到視覺圖像、自然語言指令、機器人當前狀態等信息之后,不直接預測關節指令,把這些信號都映射到統一的操作空間(Unified Action Space),生成統一的動作向量。
不同本體的關節指令,則由輕量級模塊或廠商驅動層完成,主干模型無需知道硬件細節。
這就像人體,由大腦來統一處理信息,并生成倒水、開門等操作意圖,由神經系統轉化為具體的肢體動作,無論高矮胖瘦或人種差異,各種身體結構都能執行。LingBot-VLA就是這樣的通用大腦,只輸出通用操作指令,硬件差異由下游模塊處理。
LingBot-VLA這顆大腦的決策能力,建立在空間感知基礎之上。這就要提到最近開源的 LingBot-Depth模型。
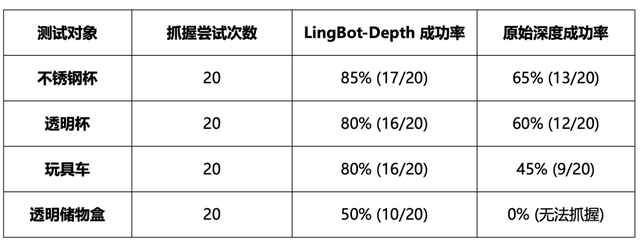
不同于普通RGB輸入,LingBot-VLA在訓練與推理中顯式融合了由LingBot-Depth生成的高質量、度量準確的深度圖。該深度模型采用創新的“掩碼深度建模”(MDM)技術,能在透明、反光等挑戰性場景中補全缺失深度,并在NYUv2、ETH3D 等基準上達到SOTA。更重要的是,它輸出的深度具備真實物理尺度,使機器人能進行精確的距離判斷與操作規劃,讓LingBot-VLA更好地看清物理世界,并與之交互。
那跨任務的強大泛化能力,又是怎么實現的呢?
傳統VLA模型只能執行訓練時見過的指令組合,比如沒訓練過擦桌子,即使包含抓抹布、移動手臂等子動作,模型也會失效。LingBot-VLA的突破在于,將語言指令動態解析為結構化動作序列,并與視覺感知對齊。
這就像是人類的舉一反三。主干模型建立了“物體-指令-動作”的關聯,Action Expert負責預測動作序列。當接收到擦桌子的指令時,哪怕以前沒有訓練過,也可以復用抓起毛巾、移動手臂等子技能,進行重組和適配,遷移到其他任務上,讓任務泛化不再是零樣本猜測。
在跨本體、跨任務的基礎上,LingBot-VLA 在訓練層面做了系統性優化,引入課程學習和稀疏獎勵蒸餾,數據效率大幅提高。研究者從大規模真實世界基準測試集GM-100中選擇了8個具有代表性的任務,在AgibotG1平臺上進行了實驗。
結果顯示,在有限預算下,LingBot-VLA的Progress Rate(進度率)和 Success Rate(成功率)都優于Pi0.5。
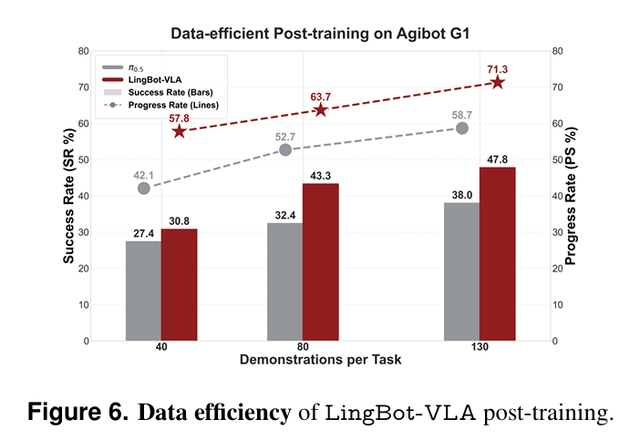
正是上述工作與創新,使得LingBot-VLA能在更低數據、更少算力的條件下,達到比Pi0.5更強的真機泛化能力,成為一個為真實世界部署而生的通用智能基座。而這,正是本體廠商跨越斬殺線的關鍵。

在智能產業中,開源開放是公認的重要力量。
以AIGC為例,Stable Diffusion開源之前,高質量圖像生成模型如DALL·E和Midjourney等閉源模型,使用受限,普通開發者無法本地部署或二次開發。SD開源后,催生了完整的生態體系,AIGC因此迎來爆發式增長。
再反觀閉源公司,OpenAI不開源的做法,被大量開發者嘲諷為“closeAI”,而曾以閉源軟件帝國著稱的微軟,如今不僅深度擁抱開源,更戰略性收購了開源社區GitHub。
為什么開源對AI乃至AGI如此重要,科技巨頭和開發者都十分重視?根本原因在于,AGI的復雜性遠超單一企業或實驗室的能力范圍,它需要全球開發者、研究者和產業伙伴,在數據、算法、工具和場景上的持續協同與迭代。
具體到具身智能領域,此前,宇樹科技、優必選等廠商各自開發了不兼容的操作系統,制約了產業生態的協同發展。這種背景下,行業迫切需要有能力的開源貢獻者,讓千千萬萬開發者不必重復造輪子,能站在巨人的肩膀上共同探索AGI的上限。
從能力層面看,LingBot-VLA作為螞蟻在AGI領域的又一成果,具備可復現、可落地、高性能等特點,且經過真機檢驗,能夠支持普通開發者,快速構建自己的具身智能體,降低創新門檻,釋放集體創造力,為行業共建提供了基礎。
從戰略意愿看,自從LLM爆發以來,螞蟻一直是全球領先的大模型開源貢獻者,以開源開放模式探索AGI,為此打造InclusionAI 開源社區,系統性地釋放了包括基礎大模型百靈、通用 AI 助手靈光、具身智能靈波在內的核心技術。LingBot-VLA是螞蟻集團開源的第一款具身智能基座模型,也是這一戰略在具身智能領域的關鍵實踐。
從持續貢獻的角度看,LingBot-VLA不僅開源了模型,還涵蓋了后訓練工具鏈,使得開發者可以更方便地進行微調和部署,可謂誠意滿滿。LingBot-Depth緊隨其后開源,進一步豐富了技術棧,這種連續性的開源動作,也讓開發者更有信心加入技術路線,繁榮生態。
所以,螞蟻所做的,是搭建起一座連接前沿研究與產業落地的開源橋梁,而這正是具身智能產業從炫技到量產,從“演示就緒”到“部署就緒”的關鍵基礎設施。
正如Stable Diffusion的開源徹底引爆了AIGC生態,LingBot-VLA正為具身智能帶來類似的轉折,觸發具身智能的“Stable Diffusion時刻”。
對開發者來說,當別人還在為數據匱乏、算力吃緊、泛化難而掙扎的時候,不妨以LingBot-VLA為起點,完成向真實世界的飛身一躍。

審核編輯 黃宇
-
AI
+關注
關注
91文章
39747瀏覽量
301338 -
具身智能
+關注
關注
0文章
388瀏覽量
857
發布評論請先 登錄
具身智能規模化落地卡在何處?靈境智源正叩響“四扇門”的最后關隘
《具身智能發展報告(2025年)》

具身智能交流會
ALVA純視覺系統如何破解具身智能大規模落地的核心瓶頸
萬億級賽道:“具身智能十大觀察”報告

什么樣的智能體才能稱為具身智能?
成都華微與具身科技開啟四川具身智能產業新篇章
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+具身智能芯片
INDEMIND亮相2025科技創變者大會,以機器人空間智能技術解鎖具身智能新邊界

商湯科技發布悟能具身智能平臺
四維圖新旗下六分科技與智身科技達成戰略合作





 工商網監
工商網監
評論