 LPDDR5X在AI數據中心多能打?10.7Gbps速率、互連快7倍、推理吞吐高5倍、延遲低80%!
LPDDR5X在AI數據中心多能打?10.7Gbps速率、互連快7倍、推理吞吐高5倍、延遲低80%!

作者:黃晶晶
LPDDR5X具有高帶寬、低功耗、高容量密度等特性,可用于AI推理等對能效和成本有嚴苛要求的場景。科技大廠例如英偉達、高通、微軟等都將LPDDR5X應用于AI數據中心領域。而存儲廠商們包括三星、美光、SK海力士以及長鑫存儲等也不斷拉高LPDDR5X的規格,有望拓展繼智能終端之后AI數據中心這類新應用。
三星電子
三星發布的比前代快1.25倍、功耗效率提升25%的高端低功耗DRAM LPDDR5X,不僅應用于移動設備,還廣泛用于PC、服務器、汽車以及新興的端側AI應用,未來將引領低功耗DRAM市場的擴展。
設備自身運行AI的端側AI時代。LPDDR5X支持高達10.7Gbps的驚人超高速數據處理速度。對于需要高性能計算的5G、AI、AR、VR、自動駕駛和元宇宙等未來IT技術和端側AI生態系統,LPDDR5X是優化的內存解決方案。

LPDDR5X采用了最先進的12nm工藝和創新的電路設計。通過應用更高級的電壓可變優化技術(FDVFS)和低功耗運行區間擴展技術,相較于上一代產品,性能提升且功耗減少近25%。在智能手機和筆記本電腦等移動設備中,LPDDR5X提供了更長的電池續航時間;在用于數據中心的服務器中,它有助于降低運營成本(CTO),從而減少碳排放。
移動 DRAM LPDDR5X 在單個封裝中支持高達32 GB 的容量,將應用范圍從智能手機和筆記本電腦擴展到高性能 PC、服務器和設備上的人工智能應用。三星的LPDDR5X還通過了 AEC-Q100 認證,可在極高和極低溫度下提供可靠的性能。
SK海力士
SK 海力士基于第5代10 納米級(1b nm)工藝的 16Gb LPDDR5X 內存運行速率為 10.7Gbps,相較上代 9.6Gbps LPDDR5T 速度高出約 10%,能效方面提升達到 15%。SK 海力士計劃以 SOCAMM 和 LPCAMM 的模組形態向服務器和 PC 市場推出 LPDDR5X 產品,以響應 AI 計算對高性能 DRAM 的需求。

美光科技
美光科技全球首款基于 1γ(1-gamma)工藝節點的LPDDR5X內存支持業界最快的10.7 Gbps 速率,同時功耗最高可降低 20%,封裝厚度壓縮至 0.61 毫米 ,相比競品薄 6%,較上一代產品厚度降低14%。
NVIDIA Grace Hopper GH200是首款采用 LPDDR5X 技術的商用產品。該創新系統將 ARM CPU 與H100 GPU相結合,代表高性能計算基礎設施的前沿方案。
根據美光的對比分析,基于LPDDR5X的Grace Hopper與同期的DDR5 服務器配置來看,二者的核心架構差異體現在內存封裝方式,LPDDR5X 內存直接焊接在 Grace Hopper 板卡上,而 DDR5 則是通過 64 位帶寬的模塊連接到 CPU。Grace Hopper 的架構采用32個內存控制器,每個控制器管理來自單個 LPDDR5X 封裝的16位通道。這種配置在數據處理中提供了更高的并行性與效率,因為每個通道可獨立運行。
相比之下,DDR5 系統采用了更傳統的設計,4 個內存控制器,每個控制器包含 4 條 32 位通道(使用 2 條 32 位子通道),總計 16 條 32 位通道。LPDDR5X 配置支持 4 個 rank,而 DDR5 僅支持2個rank,進一步提升訪問并行性(因為每個 rank 可獨立運行)。性能數據凸顯了 LPDDR5X 的優勢,其峰值理論帶寬達 384GB/s,略高于DDR5 的358GB/s。這種更高的數據速率、更強的并行性與更大的帶寬相結合,使 LPDDR5X 成為高性能計算應用與混合內存訪問模式的優選技術。
在 CPU/GPU系統中使用 LPDDR5X 進行大語言模型推理的效果如何呢。美光科技評估了 LPDDR5X 在兩種場景下的大語言模型推理性能:僅使用 CPU 的配置和 CPU+GPU 的配置。
在僅使用 CPU | Llama 3 8B的評估下,在 LPDDR5X 和 DDR5 系統上都運行Llama 3 8B 模型。參數規模在 80 到 200 億之間的模型通常被認為適合僅在 CPU 上運行。DDR5 系統配備了高性能的 x86 CPU,時鐘頻率為 3.9 GHz,且具有大容量的末級緩存(L3),其原始性能更優:生成tokens的速度快1.7 倍,首token延遲也低約 1.1 倍。
然而,在評估每瓦性能(衡量能效的關鍵指標)時,LPDDR5X 系統表現更出色。它借助 LPDDR5X 內存和低功耗的基于ARM架構的 Grace CPU,實現了1.1 倍的能效提升,這有望顯著降低推理部署成本。
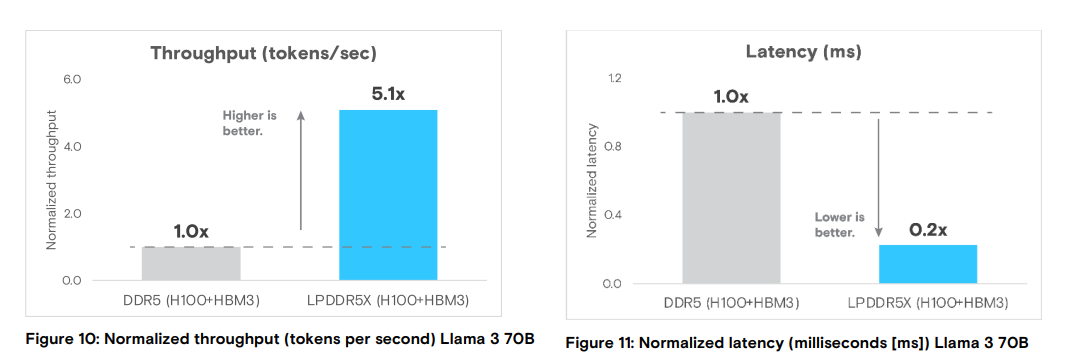
在CPU 和 GPU | Llama 3 70B的評估下,為了更好地理解在 CPU+GPU 場景下的推理運行中 LPDDR5X 所起的作用,美光科技研究了一個擁有 700 億參數的 Llama 3 模型。這種規模的模型由于對帶寬和計算有更高的要求,需要GPU 和HBM 資源。
并采用了兩種配置的 H100/HBM3 GPU:?集成了 H100/HBM3 GPU 的LPDDR5X 系統(NVIDIA Grace Hopper 超級芯片)?標準 DDR5 系統,為了使對比保持一致,在該系統中安裝了相同的 H100/HBM3。
關鍵的差異在于互連性能。Grace Hopper 超級芯片配備了集成的 NVIDIA NVLink,具有 900 GB/s 的雙向帶寬,而標準 DDR5 系統的 PCIe Gen5 鏈路僅提供 128 GB/s 的雙向帶寬。
LPDDR5X 系統的性能大幅優于 DDR5 系統,主要體現在
?互連速度(CPU - GPU)快 7 倍
?設備到主機的傳輸速度為346 GB/s,主機到設備的傳輸速度為 334 GB/s,而 DDR5 的單向傳輸速度為 55 GB/s
?推理吞吐量高 5 倍
?推理延遲低 80%
長鑫存儲
LPDDR5/5X 是第五代超低功耗雙倍速率動態隨機存儲器。通過創新的封裝技術和優化的內存設計,長鑫存儲 LPDDR5X在容量、速率、功耗上都有顯著提升,目前提供12Gb和16Gb兩種單顆粒容量,最高速率達到10667Mbps ,達到國際主流水平,較上一代LPDDR5提升了66%,同時可以兼容LPDDR5,功耗則比LPDDR5降低30%。

英偉達、微軟、高通將LPDDR應用于AI數據中心
近日,Cadence宣布與微軟合作開發出一款面向數據中心的LPDDR5X9600Mbps內存系統解決方案。
該方案將Cadence的 LPDDR5X IP 與微軟專有的糾錯算法RAIDDR(冗余獨立雙倍數據速率陣列)ECC(糾錯碼)相結合。該方案可同時實現高性能、低功耗和高可靠性。微軟計劃在其數據中心部署此方案。雙方強調,通過應用RAIDDR ECC技術,實現了與現有服務器DDR5 內存相當的數據保護能力。
此前,美光與英偉達合作開發了SOCAMM,專為支援英偉達 GB300 Grace Blackwell Ultra 超級芯片而設計,能為英偉達的相關AI平臺提供低功耗、高容量的內存支持。
去年,高通推出面向數據中心的下一代AI推理優化解決方案,基于Qualcomm AI200與AI250芯片的加速卡及機架系統。Qualcomm AI200帶來專為機架級AI推理打造的解決方案,每張加速卡支持768GB LPDDR內存,實現更高內存容量與更低成本,為AI推理提供卓越的擴展性與靈活性。
Qualcomm AI250解決方案將首發基于近存計算(Near-Memory Computing)的創新內存架構,實現超過10倍的有效內存帶寬提升并顯著降低功耗,為AI推理工作負載帶來能效與性能的跨越性提升。
兩款機架解決方案均支持直接液冷散熱,以提升散熱效率,支持PCIe縱向擴展與以太網橫向擴展,并具備機密計算,保障AI工作負載的安全性,整機架功耗為160千瓦。據悉,Qualcomm AI200與AI250預計將分別于2026年和2027年實現商用。
發布評論請先 登錄
高通挑戰英偉達,發布768GB內存AI推理芯片,“出征”AI數據中心

高通挑戰英偉達!發布768GB內存AI推理芯片,“出征”AI數據中心

邊緣AI算力臨界點:深度解析176TOPS香橙派AI Station的產業價值
Cadence推出高可靠性LPDDR5X 9600Mbps內存IP系統解決方案
長鑫存儲DDR5/LPDDR5X雙芯亮相,火力全開!

今日看點:長鑫存儲官宣發布LPDDR5X,蘋果自研 5G 芯片 C2 曝光
長鑫存儲LPDDR5X來了!速率高達10667Mbps,躋身國際主流水平!

睿海光電以高效交付與廣泛兼容助力AI數據中心800G光模塊升級
加速AI未來,睿海光電800G OSFP光模塊重構數據中心互聯標準
芯動科技全套IP通過ISO 26262汽車功能安全最高等級認證

PCIe協議分析儀在數據中心中有何作用?
Cadence推出LPDDR6/5X 14.4Gbps內存IP系統解決方案



 工商網監
工商網監
評論