 618 大促技術實踐:定時任務異常重試的探索與沉淀?
618 大促技術實踐:定時任務異常重試的探索與沉淀?

在 618 大促的技術戰場上,每一行代碼、每一個配置都影響著一線的實實在在的業務。一次看似平常的發版,卻意外暴露了我們系統中的定時任務管理短板,這促使我們深入剖析分布式任務調度中異常重試機制的技術細節,并最終將其轉化為守護系統穩定性的堅固防線。?
一、異常事件回溯:隱藏在發版背后的定時炸彈?
發版次日,業務部門反饋商家未收到門店收貨明細郵件,導致門店收貨業務收到影響。技術團隊迅速啟動應急流程,通過全鏈路日志追蹤和系統狀態分析,發現了問題的根源是:發版過程中,由于服務重啟,中斷了定時任務進程,正在執行的郵件發送任務被意外終止。而該任務在管理平臺上并未配置任何重試策略,業務代碼上也沒有進行相關的檢測和重試,這就導致任務失敗后無法自動恢復執行,也未被及時感知到,進而引發業務阻斷。?
為解決燃眉之急,研發人員立即登錄任務管理平臺,手工觸發郵件發送任務,確保業務及時恢復。但這次事件給我們敲響了警鐘:在分布式任務調度場景下,面對網絡抖動、進程異常終止等場景,異常重試機制是保障業務可靠性的關鍵。?
二、重試策略設計:從理論到代碼的深度解析?
2.1 驗證EasyJob的重試策略
在復盤問題的過程中,我們發現了EasyJob分布式任務是具有重試策略的,只是默認不開啟,而不是默認開啟。

該策略以三個核心參數為基礎:首次重試間隔時間 F、重試間隔乘數 M 和最大重試次數 C。
通過這三個參數的組合,我們可以靈活控制任務重試節奏,平衡系統負載與任務恢復效率。?
例如:配置t=10s, M=2, C=10,則間隔時間依次是:
| 重試次數 nn | 間隔時間計算方式 | 間隔時間結果 |
|---|---|---|
| 1 | 10s(初始間隔,無計算) | 10s |
| 2 | 10s×2 | 20s |
| 3 | 20s×2 | 40s |
| 4 | 40s×2 | 80s |
| 5 | 80s×2 | 160s |
驗證日志:
21:45:29.990 [main-schedule-worker-pool-1-thread-1] INFO cn.jdl.tech_and_data.EmailSendingTask - 開始執行發送郵件任務 21:45:40.204 [main-schedule-worker-pool-1-thread-2] INFO cn.jdl.tech_and_data.EmailSendingTask - 開始執行發送郵件任務 21:46:00.674 [main-schedule-worker-pool-1-thread-3] INFO cn.jdl.tech_and_data.EmailSendingTask - 開始執行發送郵件任務 21:46:41.749 [main-schedule-worker-pool-1-thread-4] INFO cn.jdl.tech_and_data.EmailSendingTask - 開始執行發送郵件任務 21:48:02.398 [main-schedule-worker-pool-1-thread-5] INFO cn.jdl.tech_and_data.EmailSendingTask - 開始執行發送郵件任務 21:50:43.008 [main-schedule-worker-pool-1-thread-1] INFO cn.jdl.tech_and_data.EmailSendingTask - 開始執行發送郵件任務
| 任務序號 | 開始時間 | 與前一任務的間隔 |
|---|---|---|
| 第 1 個任務 | 21:45:29.990 | - |
| 第 2 個任務 | 21:45:40.204 | 10.214 秒 |
| 第 3 個任務 | 21:46:00.674 | 20.47 秒 |
| 第 4 個任務 | 21:46:41.749 | 41.075 秒 |
| 第 5 個任務 | 21:48:02.398 | 80.649 秒(約 1 分 20.65 秒) |
| 第 6 個任務 | 21:50:43.008 | 160.61 秒(約 2 分 40.61 秒) |
與上面計算的一致。
驗證方案:
1、實現接口:com.wangyin.schedule.client.job.ScheduleFlowTask,并設置任務返回失敗:

2、創建CRON觸發器

3、設置自動重試參數


4、暫停任務并手工觸發一次

2.2 實現一個簡單的重試策略
根據上述策略,簡單實現了一個靈活可配置的任務重試機制。
public class TaskRetryExecutor {
@Getter
private final ScheduledExecutorService executor = newScheduledThreadPool(10);
private final long firstRetryInterval;
private final int intervalMultiplier;
private final int maxRetryCount;
public TaskRetryExecutor(long firstRetryInterval, int intervalMultiplier, int maxRetryCount) {
this.firstRetryInterval = firstRetryInterval;
this.intervalMultiplier = intervalMultiplier;
this.maxRetryCount = maxRetryCount;
}
public void submitRetryableTask(Runnable task) {
executeWithRetry(task, 1);
}
private void executeWithRetry(Runnable task, int currentRetryCount) {
executor.schedule(() -> {
try {
task.run();
log.info("任務在第{}次嘗試時成功執行", currentRetryCount);
} catch (Exception e) {
log.error("任務在第{}次嘗試時執行失敗", currentRetryCount, e);
if (currentRetryCount <= maxRetryCount) {
long delay = calculateRetryDelay(currentRetryCount);
log.info("計劃在{}毫秒后進行第{}次重試", delay, currentRetryCount);
executeWithRetry(task, currentRetryCount + 1);
} else {
log.error("超過最大重試次數。任務執行最終失敗。");
}
}
}, currentRetryCount == 1 ? 0 : calculateRetryDelay(currentRetryCount), TimeUnit.MILLISECONDS);
}
public long calculateRetryDelay(int retryCount) {
if (retryCount == 1) {
return firstRetryInterval;
} else if (retryCount > 1 && retryCount <= maxRetryCount) {
long previousDelay = calculateRetryDelay(retryCount - 1);
return previousDelay * intervalMultiplier;
}
return -1; // 超出最大重試次數,返回錯誤標識
}
}
?在上述代碼中:
1.TaskRetryExecutor類封裝了任務重試的核心邏輯。構造函數接收三個關鍵參數:firstRetryInterval、intervalMultiplier和maxRetryCount,用于配置重試策略,對應于EasyJob的F、M、C參數。
2.submitRetryableTask方法接收一個可執行任務,并啟動重試流程。它調用executeWithRetry方法,初始重試次數為1。
3.executeWithRetry方法是重試邏輯的核心。它使用ScheduledExecutorService來調度任務執行:
?如果任務執行成功,記錄成功日志。
??如果任務執行失敗且未超過最大重試次數,計算下一次重試的延遲時間,并遞歸調用自身進行重試。
??如果超過最大重試次數,記錄最終失敗日志。
4.calculateRetryDelay方法實現了重試間隔的計算規則:
?第一次重試使用firstRetryInterval。
?之后的重試間隔是前一次間隔乘以intervalMultiplier。
?如果超出最大重試次數,返回-1表示錯誤。
通過這種設計,我們實現了一個可復用、可配置的任務重試機制。它能夠根據配置的參數自動調整重試間隔,在任務失敗時進行有策略的重試,同時避免無限重試導致的資源浪費。
詳細代碼可在以下Git倉庫中找到:git@coding.jd.com:newJavaEngineerOrientation/TaskRetryStrategies.git
2.3 重試策略的理論分析
2.3.1 EasyJob對乘數和最大重試次數的限制
在對EasyJob也進行了重試的驗證中發現:
1.每次重做的乘數取值范圍是[1,8],可以是具有一位小數位的浮點數,比如3.5,
2.最多重做次數是[1,16]間的整數,第一次重試的間隔沒有限制,單位是秒。

2.3.2 梯度分析
通過上面的驗證和重試相關概念的定義,可以得到:第n次重試的間隔時間=第一次間隔時間*乘數^(n-1),即:

其中:

對乘數M的梯度:

對重試次數n的梯度:

詳細推導: http://xingyun.jd.com/codingRoot/newJavaEngineerOrientation/TaskRetryStrategies/blob/master/src/main/resources/%E5%85%AC%E5%BC%8F%E6%8E%A8%E5%AF%BC.md
從下圖可以看出,重試次數n較大時(比如8),乘數 M 的細微變化都會導致,任務的間隔時間發生劇烈變化,因此n超過8之后,M基本不可調。

同樣的,從下圖可以看到,乘數M較大時(比如4),n的細微變化也會導致任務的間隔時間爆發式的增加。

1、乘數在1.5-4 的合理性
過小乘數 (<1.5) 的問題:
當乘數 = 1.2,重試 10 次的間隔時間是:1次:1, 2次:1.2, 3次:1.44, ..., 10次:5.16,
10 次重試總間隔僅 5 倍,接近固定間隔,可能導致 "驚群效應"(大量請求同時重試)。
過大乘數 (>4) 的問題
當乘數 = 8,重試 5 次的間隔時間:1次:1, 2次:8, 3次:64, 4次:512, 5次:4096
5 次重試后間隔已超 1 小時(假設初始間隔時間是最小的1s,4096s>1小時),可能導致請求長時間等待,用戶體驗差。
因此,乘數 = 1.5-4 在 "退避效率" 和 "資源消耗" 間取得平衡,一般取乘數= 2 (標準指數退避)。
行業實踐:AWS SDK 默認乘數 = 2,Google gRPC 重試策略推薦乘數 = 1.5-3,多數 HTTP 客戶端庫 (如 requests) 默認乘數 = 2。
2、最大重試次數3-10的合理性
假設單次重試成功概率為P(比如網絡/服務臨時故障,重試成功概率通常較高),重試 n次至少成功 1 次的概率為:

當 p=0.5,(單次重試 50% 成功概率):
n=3 時,成功概率 =1?(0.5)^3=87.5%
n=5 時,成功概率 =1?(0.5)^5=96.875%
n=10 時,成功概率 =1?(0.5)^10≈99.9%
實際場景中,臨時故障的單次成功概率遠高于 50%(比如網絡抖動重試成功概率可能達 80%)
若 p=0.8,n=3時成功概率已達 1?0.2^3=99.2%幾乎覆蓋所有臨時故障。
因此,3 - 10 次重試,能以極高概率(99%+)覆蓋“臨時故障”場景,再增加次數對成功概率提升極有限(邊際效應遞減)。
因為已知的任務延遲時間的公式是:
,
n從1到C進行累加得到總耗時:

,
根據等比數列求和公式可以得到:

令 M=2(常用乘數),F=1 秒(最小可能值):
n=3時,T=(2^3-1)/(2-1)=7秒
n=5時,T=(2^5-1)/(2-1)=31秒
n=10時,T=2^10-1=1023秒≈17分鐘
n=13時,T=2^13-1≈2.3小時
n=15時,T=2^15-1≈9.1小時
當n超過10后,每次增加都會導致總耗時急劇增長,很容易超過業務的容忍上限(具體業務具體分析),也可能因為重試過多,導致被調用的系統壓力增加,甚至造成系統崩潰。
故:3 - 10 次重試可將總耗時控制在“業務可接受范圍”(幾秒到十幾分鐘),同時避免資源過載。
行業實踐:Kafka 消費者重試:默認 10 次、Redis 客戶端重試:默認 5 次、Hadoop 任務重試:默認 3-5 次、RFC 建議:RFC 6582(HTTP 重試)建議:3-5 次重試。
3、最佳實踐速查表
| 參數 | 短期任務(分鐘級) | 中期任務(小時級) | 長期任務(天級) |
|---|---|---|---|
| 乘數 | 2 | 2 | 1.75 |
| 重試次數 | 3 - 5 | 5 - 8 | 8 - 12 |
| 初始間隔(秒) | 1 - 5 | 30 - 60 | 300 - 600 |
| 總耗時范圍 | <60秒 | 5 - 10分鐘 | 1 - 2小時 |
| 適用場景 | 臨時網絡波動 服務重啟、發版 | 服務短暫過載 | 資源密集型操作 |
三、經驗沉淀:異常重試機制的設計原則?
通過這次實踐和對行業方案的研究,我們總結出異常重試機制設計的四大核心原則:?
1.動態適應性原則:重試策略應支持參數化配置,根據業務場景和系統負載動態調整重試間隔和次數,避免 “一刀切” 的重試策略對系統造成沖擊。?
2.冪等性保障原則:確保任務在多次重試過程中不會產生重復數據或副作用,通過唯一標識、狀態機等技術手段,實現任務的冪等執行。?
3.故障隔離原則:將重試邏輯與業務邏輯分離,通過消息隊列、異步調度等方式,降低重試操作對主線程的影響,避免因重試失敗導致系統整體崩潰。?
4.可觀測性原則:建立完善的監控和告警體系,實時追蹤任務重試狀態,在達到最大重試次數時及時發出告警,便于運維人員快速定位和解決問題。?
四、結語:以技術沉淀筑牢大促防線?
這次線上異常事件,猶如一面鏡子,讓我們清晰地看到了系統中的潛在風險,也為我們提供了一次寶貴的技術提升機會。通過對異常重試機制的深入研究和實踐,我們不僅解決了當前問題,更將這些經驗轉化為團隊的技術資產。在未來的 618 大促及其他關鍵業務場景中,我們將以更完善的技術方案、更嚴謹的設計原則,守護系統的穩定運行,為業務發展提供堅實的技術保障。
?審核編輯 黃宇
-
分布式
+關注
關注
1文章
1095瀏覽量
76643 -
任務調度
+關注
關注
0文章
28瀏覽量
10206
發布評論請先 登錄
基于知識工程JoyAgent雙RAG的智能代碼評審系統的探索與實踐
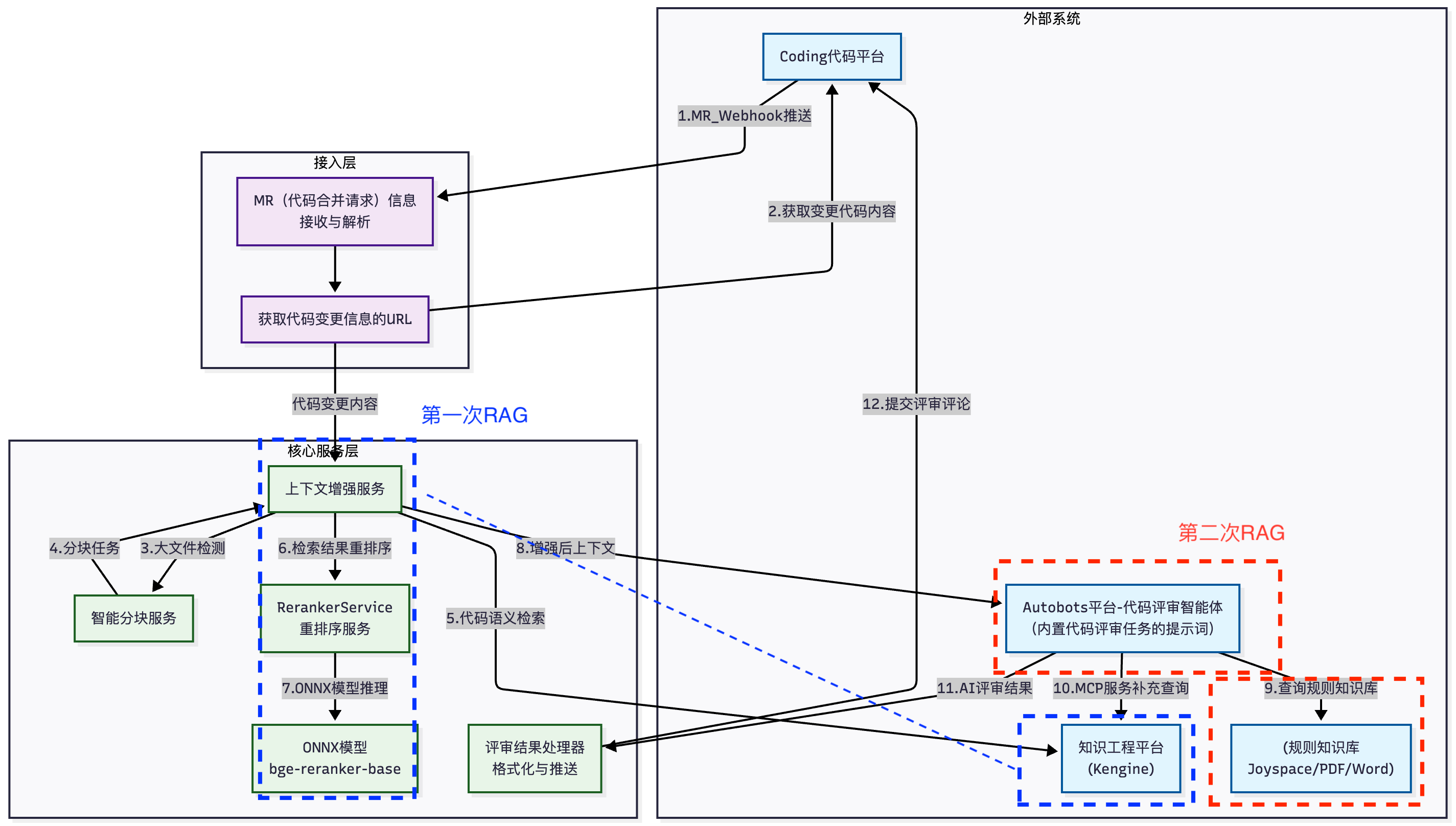
基于知識工程&JoyAgent雙RAG的智能代碼評審系統的探索與實踐
探索HMC618ALP3E:高性能低噪聲放大器的卓越之選
看門狗定時器、復位源、異常處理機制科普

Crontab定時任務完全指南
基于 AS32X601 微控制器的定時器模塊(TIM)技術研究與應用實踐
使用C#實現西門子PLC數據定時讀取保存
機器學習異常檢測實戰:用Isolation Forest快速構建無標簽異常檢測系統

德施曼618首戰全平臺銷額、銷量雙冠軍!京東天貓官榜第一!

HarmonyOS優化應用文件上傳下載慢問題性能優化一
德施曼618首戰全平臺銷額、銷量雙冠軍!京東天貓官榜第一!

555定時器設計異常現象
linux服務器挖礦病毒處理方案




 工商網監
工商網監
評論