") 聯合華為!國產大模型登頂全球,0.1元一張圖
聯合華為!國產大模型登頂全球,0.1元一張圖

電子發(fā)燒友網報道(文/莫婷婷)1月16日,智譜宣布聯合華為開源最新圖像生成模型GLM-Image登頂Hugging Face Trending。
這一事件之所以引發(fā)廣泛關注,核心在于三個關鍵詞:開源、SOTA性能、全棧國產。尤其值得注意的是,GLM-Image從數據預處理到大規(guī)模預訓練全程運行在華為昇騰Atlas 800T A2芯片與昇思MindSpore框架之上,這意味著,在高性能算力長期被海外巨頭壟斷的背景下,中國團隊首次用純國產算力底座,訓練出達到世界領先水平的多模態(tài)SOTA模型。
GLM-Image創(chuàng)新架構引領新紀元,知識密集型場景成新戰(zhàn)場
智譜此次GLM-Image的破局點,在于并非簡單復刻Stable Diffusion或Flux的技術路徑,而是面向新一代“認知型生成”范式,提出創(chuàng)新的 “自回歸 + 擴散解碼器”混合架構。
根據官方介紹,“自回歸 + 擴散解碼器”混合架構具備以下亮點,兼顧全局指令理解與局部細節(jié)刻畫,其中9B大小的自回歸模型可以負責理解語義、畫面的全局構圖,7B大小的擴散解碼器專注高頻細節(jié)還原與文字筆畫精準生成。
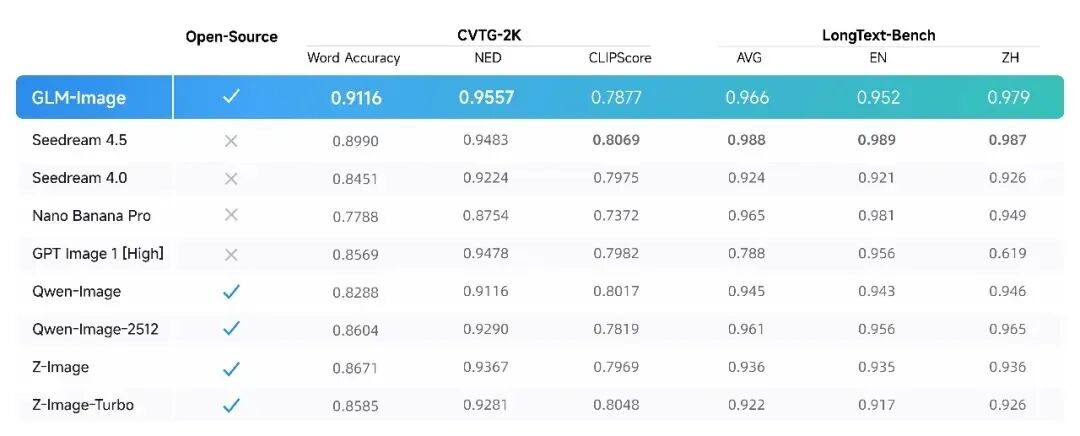
這種架構讓GLM-Image在權威評測中脫穎而出:
在 CVTG-2K(復雜視覺文字生成)榜單上,以 0.9116 的文字準確率 和 0.9557 的歸一化編輯距離(NED) 雙項第一;在 LongText-Bench(長文本渲染)中,中文得分高達 0.979,英文 0.952,穩(wěn)居開源榜首。
從智譜給出的GLM-Image生成圖片示例可以看到,GLM-Image擅長畫出包含邏輯流程的科普插畫、小紅書等社交媒體風格較為明顯的圖文,以及商業(yè)海報、人像等。

圖:GLM-Image生成圖片示例
筆者實測發(fā)現,GLM-Image在整體畫風上保持了較高的一致性,尤其在科普插畫的邏輯表達方面表現較好,但在文字生成的準確性上仍存在個別偏差。

當前,圖像生成領域競爭激烈。谷歌憑借其Gemini生態(tài)推出的 Nano Banana Pro,以“企業(yè)級”畫質和強大的語言-圖像協同能力,成為閉源圖像生成模型的標桿產品;國內如阿里通義萬相、字節(jié)即夢等也紛紛推出多模態(tài)生圖產品。
筆者用同樣的提示詞對比谷歌Nano Banana、ChatGPT、即夢等3款常見模型,看到,不同的大模型有各自的風格。
提示詞:赤壁之戰(zhàn),三國演義經典場景,熊熊大火燃燒曹軍連環(huán)戰(zhàn)船,火光沖天映紅長江夜空,周瑜指揮若定羽扇指揮,諸葛亮祭東風法壇作法,火攻場面震撼,古代中國水戰(zhàn),千帆競渡,箭矢如雨,煙霧彌漫,史詩級戰(zhàn)爭畫面,傳統(tǒng)中國畫風與電影感結合,極致細節(jié),電影級光影,8k,超震撼。
生成的圖片如下圖所示:

圖:GLM-Image生成的圖片
GLM-Image具有漫畫或游戲原畫風格,色彩飽和度高,線條分明。

圖:NanoBanana生成的圖片
Nano Banana 以“高質量、高分辨率、強氛圍渲染”著稱,對動態(tài)火焰、水波反射、衣袍飄動等細節(jié)繪制精準。

圖:ChatGPT生成的圖片
ChatGPT具備復雜場景構建、多物體協調,細節(jié)較為豐富,帶有戰(zhàn)爭史詩感。

圖:即夢生成的圖片
即夢在中文語境中則注重歷史文化準確性和中國美學表達,還原古代戰(zhàn)船結構、旗幟樣式等細節(jié)。
依舊可以期待的是,隨著技術的迭代,這些多模態(tài)圖像生成大模型生成的圖片不僅畫面精美,而且漢字準確率也大幅提升,拓展了海報、PPT、科普圖等更多知識密集型場景。
文字渲染達開源SOTA,昇騰A2+MindSpore的硬核協同
智譜認為以Nano Banana Pro為代表的閉源圖像生成模型正在推動圖像生成與大語言模型的深度融合。技術范式正從單一的圖像生成,進化為兼具世界知識與推理能力的認知型生成。
GLM-Image通過架構創(chuàng)新探索多模態(tài)大模型的技術路徑。如果說架構創(chuàng)新是GLM-Image的“靈魂”,那么華為昇騰與昇思MindSpore提供的全棧國產算力底座,則是其得以落地的“基石”。
在當前高性能GPU受限的背景下,訓練一個數十億參數、支持2048×2048分辨率的多模態(tài)SOTA模型,對算力穩(wěn)定性、通信帶寬和訓練效率提出極高要求。傳統(tǒng)觀點認為,只有英偉達的芯片集群才能勝任。但智譜與華為的合作證明:國產芯片不僅能跑推理,更能支撐最前沿的端到端訓練。
資料顯示,GLM-Image的整個訓練生命周期——包括海量圖文數據預處理、大規(guī)模預訓練、監(jiān)督微調(SFT)及強化學習后訓練(RL)均在華為Ascend A2芯片集群上完成。

為充分發(fā)揮昇騰NPU潛力,智譜與華為深度協同,基于昇思MindSpore框架,實現多項底層優(yōu)化,包括動態(tài)圖多級流水下發(fā),將Host側算子下發(fā)的關鍵階段流水化并高度重疊,消除下發(fā)瓶頸,提升訓練能力;多流并行執(zhí)行,打破文本梯度同步、圖像特征廣播等操作的通信墻,提升整體效率。使用AdamW EMA、COC、等昇騰親和高性能融合算子,提升訓練的穩(wěn)定性和性能。
智譜指出,傳統(tǒng)模型生成非正方形圖像時需后期裁剪或重繪,易導致內容失真。GLM-Image通過改進Tokenizer策略,原生支持1024×1024至2048×2048任意比例輸出,可直接生成小紅書封面、電影橫幅等圖片,無需二次處理,極大提升實用性。
值得一提的是,GLM-Image是首個開源的工業(yè)級離散自回歸圖像生成模型。相比閉源的Nano Banana Pro,它不僅性能對標甚至局部超越,還向全球開發(fā)者開放了完整技術路徑,為下一代圖像生成模型研究提供了新范本。
結語:國產AI的“分水嶺時刻”
智譜表示,API調用模式下,生成一張圖片僅需一毛錢(0.1元),將高質量AI生圖成本降至“白菜價”,讓中小企業(yè)、獨立開發(fā)者、內容創(chuàng)作者都能輕松接入SOTA能力。另一方面,通過開源,GLM-Image為學術界和工業(yè)界提供了可復現、可改進的研究基線,有望激發(fā)更多基于“認知型生成”的創(chuàng)新應用。
更為重要的是,GLM-Image是首個在國產芯片上完成全流程訓練的SOTA多模態(tài)模型,這也意味著國產大模型走進新的階段。正如智譜所說:它驗證了在國產全棧算力底座上訓練高性能多模態(tài)生成模型的可行性。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規(guī)問題,請聯系本站處理。
舉報投訴
-
華為
+關注
關注
218文章
36005瀏覽量
262106 -
大模型
+關注
關注
2文章
3650瀏覽量
5183
發(fā)布評論請先 登錄
相關推薦
熱點推薦
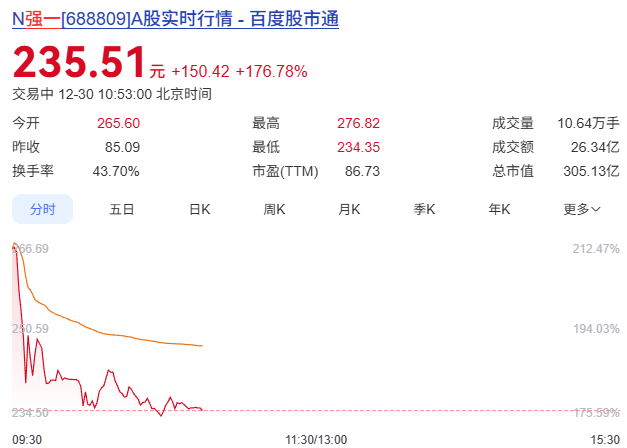
305億元!剛剛,華為入股的國產MEMS公司上市了!
半導體股價235.51元/股,漲幅達176.78%,總市值達305.13億元。 強一半導體是中國唯一打破該MEMS細分領域壟斷,進入全球前十
成都匯陽投資關于國產開源模型持續(xù)突破,國產AI 競爭力增強
、MiniMax-M2 分別位列全球開源榜單第一 、 第二 ,且榜單前五名中國產開源模型占據四席(Qwen3 235BA22B2507 和 DeepSeek V3.2 Exp 分別位列
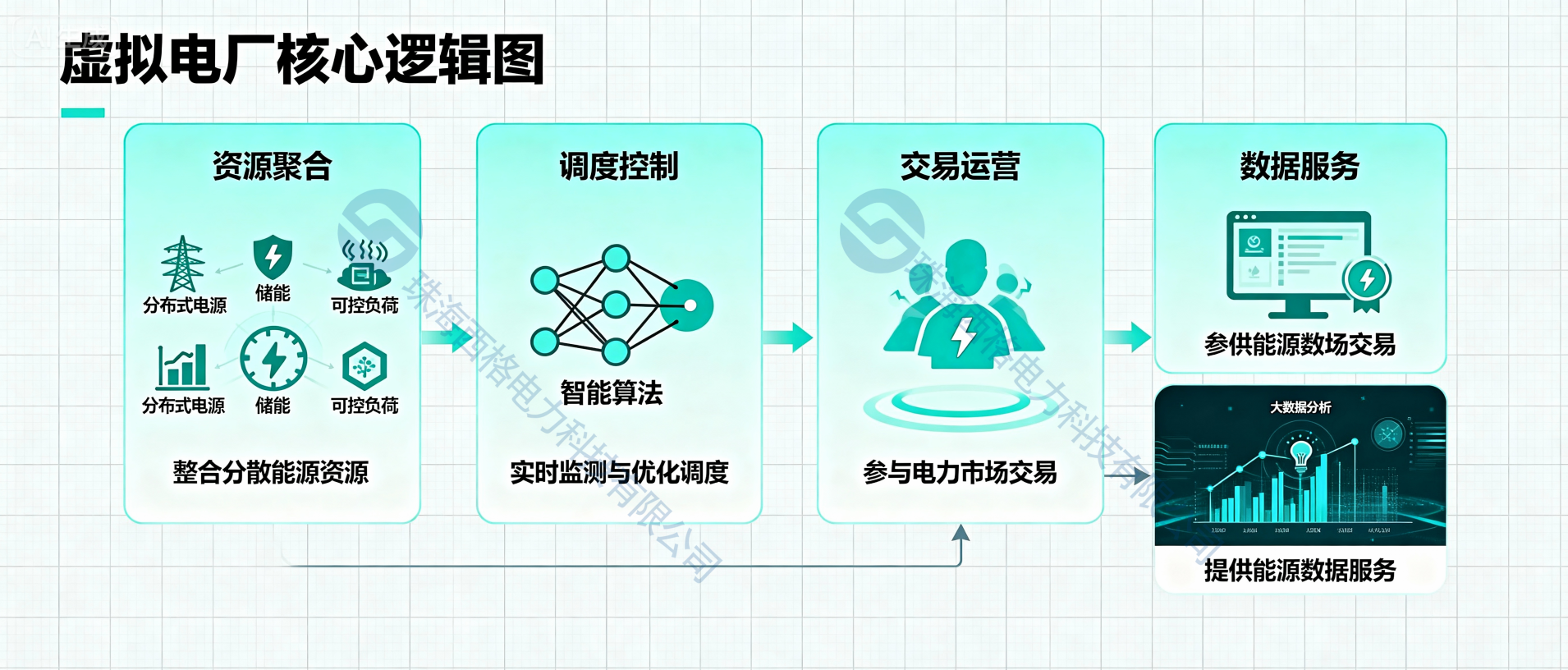
虛擬電廠的本質是什么?一張圖讀懂如何"喚醒"沉睡的電力資源
電廠一樣為電網提供調峰、調頻服務,甚至比傳統(tǒng)電廠更靈活。想要搞懂這個“看不見卻實力強”的能源新物種,一張“虛擬電廠核心邏輯圖”就足夠清晰,我們不妨順著圖的脈絡,
脈沖神經元模型的硬件實現
會發(fā)生泄漏而降低。
以下公式 用來計算LIF模型的膜電勢
其中表示神經元的膜電勢,vrest 代表神經元復位電位,為時間常數。是權重和輸入脈沖的乘累加,結果再與膜電勢相加。當神經元
發(fā)表于 10-24 08:27

指揮調度系統(tǒng)如何織就協同作戰(zhàn)一張網
信息、智能決策、高效協同,將分散的力量凝聚成一個有機整體。 一、核心挑戰(zhàn):從“信息孤島”到“態(tài)勢一張圖” 傳統(tǒng)模式下,各參與部門往往使用獨立的通信系統(tǒng)和數據平臺,形成“信息孤島”。
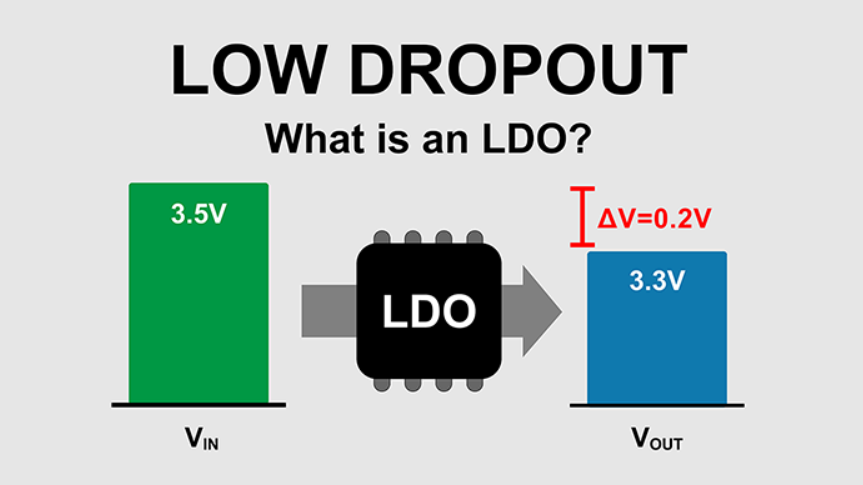
一張圖搞懂LDO的硬件設計和應用
存在誤解,這些誤解往往會導致設計失敗。? ” 我們先通過一張圖來概括 LDO 的應用: 線性穩(wěn)壓電源與 LDO 先澄清一個基礎的概念 : LDO 是線性穩(wěn)壓電源的一種 ,但不是所有線性
商湯日日新V6.5多模態(tài)大模型登頂全球權威榜單
Pro)多模態(tài)大模型以82.2的綜合成績登頂榜首,領先Gemini 2.5 Pro以及GPT-5等國際頂尖模型。
登頂!華為OceanStor A系列存儲再登MLPerf全球性能之巔
2025年8月5日,全球權威AI性能評測組織公布最新MLPerf? Storage v2.0基準測試結果,華為OceanStor A系列存儲聯合濟南超級計算技術研究院(簡稱“JNIST”)斬獲佳績
如何制作一張自動駕駛高精度地圖?
厘米級的精確參考。那么一份能夠滿足自動駕駛需求的高精度地圖到底是如何生成的?其背后又依賴了哪些關鍵技術? 想要生成一張合格的高精度地圖,需要“眼睛”先看懂路,這個“眼睛”來自于多傳感器的數據采集平臺。常見的做法是借助
南鋼集團攜手華為推出元冶鋼鐵大模型
)上,南鋼集團與華為聯合研發(fā)的“元冶·鋼鐵大模型”正式發(fā)布。同時,雙方共同設立的“鋼鐵智能制造聯創(chuàng)中心”暨“AI+工業(yè)復合型人才培訓基地”揭牌。
瑞芯微模型量化文件構建
模型是一張圖片輸入時,量化文件如上圖所示。但是我現在想量化deepprivacy人臉匿名模型,他的輸入是四個輸入。該模型訓練時數據集只標注了人臉框和關鍵點,該
發(fā)表于 06-13 09:07
華為助力武漢市全域數字化轉型
第二十屆“中國光谷”國際光電子博覽會期間,武漢市數據局與華為共同舉辦華為全球首個市級城市一張網樣板點發(fā)布儀式。



 工商網監(jiān)
工商網監(jiān)
評論