 梁文鋒署名DeepSeek新論文:突破GPU內存限制的技術革命
梁文鋒署名DeepSeek新論文:突破GPU內存限制的技術革命

電子發燒友網報道 DeepSeek團隊發布了一篇由創始人梁文鋒署名的新論文,主題為《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》(直譯為《基于可擴展查找的條件記憶:大語言模型稀疏性的新維度》)。這篇論文不僅揭示了當前大語言模型在知識檢索方面的低效問題,還通過創新的Engram架構,將模型的“條件記憶”與“計算”分離,從而大幅降低錯誤率并節省算力。
條件記憶與Engram架構
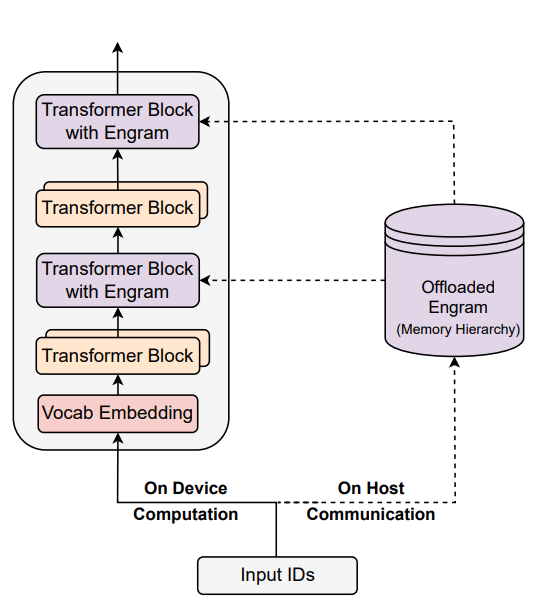
論文的核心創新點在于提出了“條件記憶”這一概念,旨在解決當前大語言模型在知識檢索方面的低效和算力消耗問題。梁文鋒團隊指出,語言建模本質上包含兩類子任務:一類是組合式推理,需要依賴深層、動態計算完成;另一類是知識檢索,面向命名實體等相對靜態的內容,理論上可以通過簡單查找更高效地處理。然而,現有Transformer架構缺乏原生的查找組件,遇到靜態信息時往往仍需反復調用深層網絡進行重建,加劇了算力浪費并推高了推理成本。
為了解決這一問題,DeepSeek團隊提出了Engram架構(記憶痕跡架構),通過將靜態知識存儲與動態計算分離,實現了靜態模式的常數時間O(1)查找。具體而言,條件記憶通過Engram模塊實現,模型能夠基于輸入中的局部上下文模式,從大規模參數化記憶中快速檢索并融合靜態知識表示,從而避免在推理過程中反復通過深層計算重建高頻、模板化信息。
突破GPU內存限制
在GPU內存限制方面,DeepSeek的新論文同樣帶來了革命性的突破。傳統上,GPU內存容量有限,處理大規模數據集時往往需要頻繁的數據傳輸和復雜的數據管理策略。而Engram架構通過稀疏存儲模式,支持更大規模的知識存入,突破了傳統注意力窗口的物理限制。當大約20%至25%的稀疏參數預算分配給Engram,剩余部分留給混合專家模型(MoE)時,模型性能達到最佳。
此外,DeepSeek團隊還通過優化數據流動和調度機制,進一步降低了GPU內存的壓力。例如,采用預取策略預測后續計算所需數據,提前從低速層加載至高速層;通過淘汰策略根據訪問頻率與重要性,將不活躍數據逐出至低速層;以及利用壓縮策略對暫存于內存或磁盤的數據進行無損或有損壓縮,減少I/O開銷。這些技術手段的結合,使得GPU在處理大規模數據集時能夠更加高效地利用內存資源。
當前,全球高端GPU資源90%集中于美國企業,且美國政府通過《芯片與科學法案》對中國實施高端GPU限售,直接導致中國AI企業面臨“硬件卡脖子”困境。以訓練千億參數模型為例,傳統架構需配置數萬塊H100 GPU,單次訓練成本超1億美元,而內存瓶頸更使模型規模受限于物理顯存容量。
DeepSeek的Engram架構通過稀疏存儲與動態計算分離技術,使模型在同等硬件條件下可處理3-5倍規模的參數。實驗數據顯示,其27B參數模型在32k上下文任務中,內存占用僅增加25%卻實現13%的準確率提升。這種技術突破不僅降低中國AI企業對進口芯片的依賴度,更通過內存效率優化使現有硬件產能釋放3倍以上算力。
結語
DeepSeek團隊此次發布的新論文,不僅揭示了當前大語言模型在知識檢索方面的低效問題,還通過創新的Engram架構和條件記憶概念,實現了GPU內存限制的革命性突破。這一技術突破不僅提高了模型運行效率,還為中國AI發展提供了戰略支撐。在全球AI競爭日益激烈的背景下,DeepSeek的探索為中國AI企業開辟了一條自主創新、突破封鎖的發展道路。
條件記憶與Engram架構
論文的核心創新點在于提出了“條件記憶”這一概念,旨在解決當前大語言模型在知識檢索方面的低效和算力消耗問題。梁文鋒團隊指出,語言建模本質上包含兩類子任務:一類是組合式推理,需要依賴深層、動態計算完成;另一類是知識檢索,面向命名實體等相對靜態的內容,理論上可以通過簡單查找更高效地處理。然而,現有Transformer架構缺乏原生的查找組件,遇到靜態信息時往往仍需反復調用深層網絡進行重建,加劇了算力浪費并推高了推理成本。
為了解決這一問題,DeepSeek團隊提出了Engram架構(記憶痕跡架構),通過將靜態知識存儲與動態計算分離,實現了靜態模式的常數時間O(1)查找。具體而言,條件記憶通過Engram模塊實現,模型能夠基于輸入中的局部上下文模式,從大規模參數化記憶中快速檢索并融合靜態知識表示,從而避免在推理過程中反復通過深層計算重建高頻、模板化信息。
突破GPU內存限制
在GPU內存限制方面,DeepSeek的新論文同樣帶來了革命性的突破。傳統上,GPU內存容量有限,處理大規模數據集時往往需要頻繁的數據傳輸和復雜的數據管理策略。而Engram架構通過稀疏存儲模式,支持更大規模的知識存入,突破了傳統注意力窗口的物理限制。當大約20%至25%的稀疏參數預算分配給Engram,剩余部分留給混合專家模型(MoE)時,模型性能達到最佳。
此外,DeepSeek團隊還通過優化數據流動和調度機制,進一步降低了GPU內存的壓力。例如,采用預取策略預測后續計算所需數據,提前從低速層加載至高速層;通過淘汰策略根據訪問頻率與重要性,將不活躍數據逐出至低速層;以及利用壓縮策略對暫存于內存或磁盤的數據進行無損或有損壓縮,減少I/O開銷。這些技術手段的結合,使得GPU在處理大規模數據集時能夠更加高效地利用內存資源。
當前,全球高端GPU資源90%集中于美國企業,且美國政府通過《芯片與科學法案》對中國實施高端GPU限售,直接導致中國AI企業面臨“硬件卡脖子”困境。以訓練千億參數模型為例,傳統架構需配置數萬塊H100 GPU,單次訓練成本超1億美元,而內存瓶頸更使模型規模受限于物理顯存容量。
DeepSeek的Engram架構通過稀疏存儲與動態計算分離技術,使模型在同等硬件條件下可處理3-5倍規模的參數。實驗數據顯示,其27B參數模型在32k上下文任務中,內存占用僅增加25%卻實現13%的準確率提升。這種技術突破不僅降低中國AI企業對進口芯片的依賴度,更通過內存效率優化使現有硬件產能釋放3倍以上算力。
結語
DeepSeek團隊此次發布的新論文,不僅揭示了當前大語言模型在知識檢索方面的低效問題,還通過創新的Engram架構和條件記憶概念,實現了GPU內存限制的革命性突破。這一技術突破不僅提高了模型運行效率,還為中國AI發展提供了戰略支撐。在全球AI競爭日益激烈的背景下,DeepSeek的探索為中國AI企業開辟了一條自主創新、突破封鎖的發展道路。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
gpu
+關注
關注
28文章
5235瀏覽量
135901 -
DeepSeek
+關注
關注
2文章
837瀏覽量
3351
發布評論請先 登錄
相關推薦
熱點推薦
內存要取代GPU?HBM之父警告:以英偉達GPU為核心的架構要被顛覆
電子發燒友網報道(文/梁浩斌)“主板插顯卡上”,是PC DIY玩家對高性能顯卡體積越來越大的調侃,隨著顯卡功率越來越高,碩大的散熱模組讓顯卡投影面積甚至已經大于ITX規格的主板,在PC里顯卡取代了

DeepSeek V3.1發布!擁抱國產算力芯片
電子發燒友網報道(文/李彎彎)2025年8月21日,DeepSeek正式官宣發布DeepSeek-V3.1大模型。新版本不僅在技術架構上實現重大升級,更通過參數精度優化與國產芯片深度適

探索DeepSeek多樣化技術路徑,英特爾架構師用至強CPU嘗鮮
近期大模型領域里最火的熱詞,或者說技術創新點,非Engram (DeepSeek最新論文里設計的Engram機制) 莫屬。今天我們想分享的,是英特爾圍繞Engram開展的早期探索——用至強? 處理器
《電子發燒友電子設計周報》聚焦硬科技領域核心價值 26年第1期:2026.1.4--2025.1.16
:具身智能邁入“大小腦協同”新紀元
8、全球首款5G-A車載模組發布!打開萬億車聯網市場發展新維度
9、梁文鋒署名DeepSeek
發表于 01-16 20:20
DeepSeek開源Engram:讓大模型擁有"過目不忘"的類腦記憶
2026年1月13日凌晨,DeepSeek突然發布由創始人梁文鋒署名的新論文《Condition
TGV產業發展:玻璃通孔技術如何突破力學瓶頸?
在后摩爾時代,芯片算力提升的突破口已從單純依賴制程工藝轉向先進封裝技術。當硅基芯片逼近物理極限,2.5D/3D堆疊技術通過Chiplet(芯粒)拆分與異構集成,成為突破光罩
【「DeepSeek 核心技術揭秘」閱讀體驗】+混合專家
感謝電子發燒友提供學習Deepseek核心技術這本書的機會。
讀完《Deepseek核心技術揭秘》,我深受觸動,對人工智能領域有了全新的認識。了解D
發表于 07-22 22:14
【「DeepSeek 核心技術揭秘」閱讀體驗】--全書概覽
感謝平臺提供的書籍,實物如下
這本書主講從年前開始火熱的DeepSeek 。書籍看起來輕薄,但言簡意賅,通俗易懂,總覽全局,比較精煉。
第一章 介紹DeepSeek的一系列技術突破與創
發表于 07-21 00:04
【「DeepSeek 核心技術揭秘」閱讀體驗】第三章:探索 DeepSeek - V3 技術架構的奧秘
時間減少,數據處理更流暢。這讓我聯想到工業生產中的流水線,AI 訓練在此處借鑒類似思路,通過優化任務分配和流程,突破硬件限制,追求更高效率,體現了技術發展中持續優化、突破瓶頸的智慧。
發表于 07-20 15:07
【「DeepSeek 核心技術揭秘」閱讀體驗】書籍介紹+第一章讀后心得
這本書有150多頁,而且是彩色印刷的,圖、表很多而且很有條理性。
書籍前言介紹如下:
第1章 介紹 DeepSeek 的一系列技術突破與創新,如架構創新、訓練優化、推理與部署優化等,讓讀者
發表于 07-17 11:59
【書籍評測活動NO.62】一本書讀懂 DeepSeek 全家桶核心技術:DeepSeek 核心技術揭秘
DeepSeek-V3技術突破
DeepSeek-V3 的模型架構整體上基于 Transformer 的 MoE 架構,并在細節實現上做了大量的創新和優化,如大量小專家模型、多頭潛在
發表于 06-09 14:38
DeepSeek 引領邊緣 AI 芯片向更高性能、更低功耗、更強泛化能力的方向演進
)等優化技術,從而在性能上取得優異表現。但其計算和內存需求也極高:部署原始的大型模型往往需要多卡 GPU 集群(如數十到上百塊 H100)才能在
顛覆傳統連接認知:M12 航空接頭的快速插拔技術革命
M12 航空接頭的快速插拔技術,不僅為工業連接帶來了顛覆性的變革,更是打開了設備升級發展的全新大門。從智能制造到智慧檢測,從交通樞紐到能源工程,這場技術革命正以磅礴之勢重塑工業連接的新格局,引領連接領域邁向高效、智能的嶄新時代。

DeepSeek創始人梁文鋒入選《時代》最具影響力100人
據外媒報道,美國《時代》周刊2025年全球100最具影響力人物正式公布了榜單。根據榜單數據顯示,DeepSeek創始人梁文鋒上榜。《時代》周刊這樣描述;
曝黃仁勛會見DeepSeek創始人梁文鋒
的創始人梁文鋒,雙方就如何為中國設計下一代芯片進行討論,以滿足客戶需求以及中美雙方的監管要求。 同時我們還看到央視新聞的報道,中國貿促會會長任鴻斌4月17日在北京與英偉達公司首席執行官黃仁勛舉行會談。黃仁勛在會談中表示,中國是英



 工商網監
工商網監
評論