") 探索無限可能:生成式推薦的演進(jìn)、前沿與挑戰(zhàn)
探索無限可能:生成式推薦的演進(jìn)、前沿與挑戰(zhàn)

TL;DR
過去一年間,生成式推薦取得了長(zhǎng)足的實(shí)質(zhì)性進(jìn)展,特別是在憑借大型語言模型強(qiáng)大的序列建模與推理能力提升整體推薦性能方面。基于LLM(Large Language Models, LLMs)的生成式推薦(Generative Recommendations, GRs)正逐步形成一種區(qū)別于判別式推薦的新范式,展現(xiàn)出替代依賴復(fù)雜手工特征的傳統(tǒng)推薦系統(tǒng)的強(qiáng)大潛力。本文系統(tǒng)全面地介紹了基于LLM的生成式推薦系統(tǒng)(GRs)的演進(jìn)歷程、前沿核心技術(shù)要點(diǎn)、關(guān)鍵工程落地挑戰(zhàn)以及未來探索方向等內(nèi)容,旨在幫助讀者系統(tǒng)理解GRs在“是什么”(What)、“為什么”(Why)和“怎么做”(How)三個(gè)關(guān)鍵維度上的內(nèi)涵。
一、引言:傳統(tǒng)推薦的困境與LLM的破局
隨著推薦系統(tǒng)的發(fā)展,建模算法大致經(jīng)歷了三種不同的技術(shù)范式:
?基于機(jī)器學(xué)習(xí)的推薦(Machine Learning-based Recommendation,MLR);
?基于深度學(xué)習(xí)的推薦(Deep Learning-based Recommendation,DLR);
?生成式推薦(Generative Recommendations,GRs)。
1.1 傳統(tǒng)推薦范式的瓶頸
傳統(tǒng)推薦范式(即MLR和DLR),側(cè)重于基于手工特征工程和復(fù)雜的級(jí)聯(lián)建模結(jié)構(gòu)來預(yù)測(cè)相似性或排序分?jǐn)?shù):
?MLR 主要依賴傳統(tǒng)的機(jī)器學(xué)習(xí)算法,通常建立在顯式的特征工程之上。關(guān)鍵技術(shù)包括協(xié)同過濾(基于與其他用戶或物品的相似性預(yù)測(cè)用戶偏好)和基于內(nèi)容的過濾(基于物品屬性推薦與用戶喜歡過的物品相似的物品)。
?DLR 主要利用深度神經(jīng)網(wǎng)絡(luò)的力量,直接從原始或稀疏特征中自動(dòng)學(xué)習(xí)復(fù)雜的非線性表示。在工業(yè)推薦系統(tǒng)中,DLR已被使用了近十年。
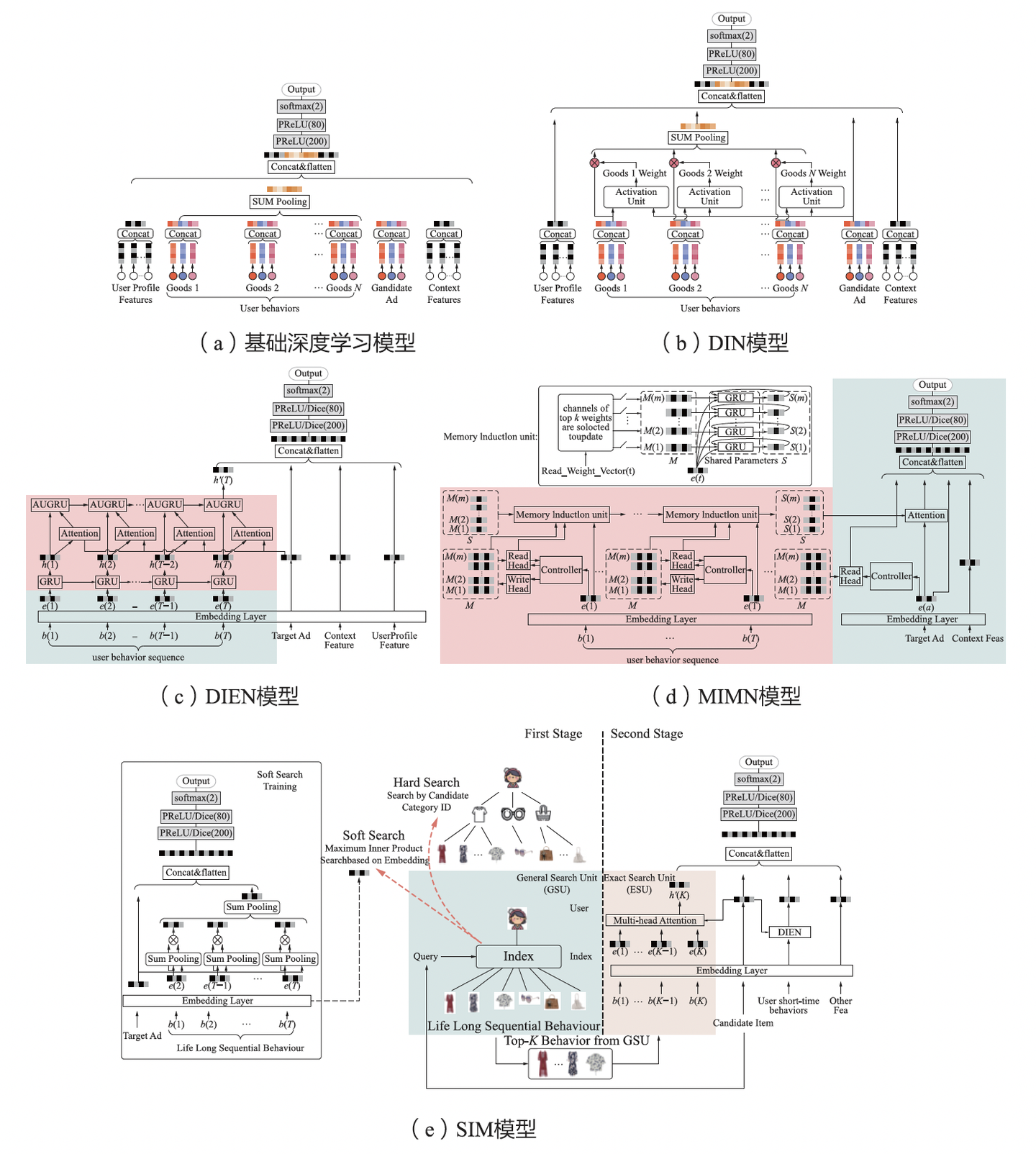
圖一:DLRM模型逐漸復(fù)雜化
如上圖,展示了DLRM模型從簡(jiǎn)單到復(fù)雜的演進(jìn):從早期的DWE(Deep Wide and Embedding)模型,到DIN(Deep Interest Network)模型,再到SIM(Search-based user Interest Model)長(zhǎng)序列建模,傳統(tǒng)推薦對(duì)特征和模型結(jié)構(gòu)做了大量迭代和極致挖掘,現(xiàn)階段暴露了“模型越復(fù)雜,優(yōu)化邊際效益越低”的問題,遭遇了明顯的增長(zhǎng)瓶頸。
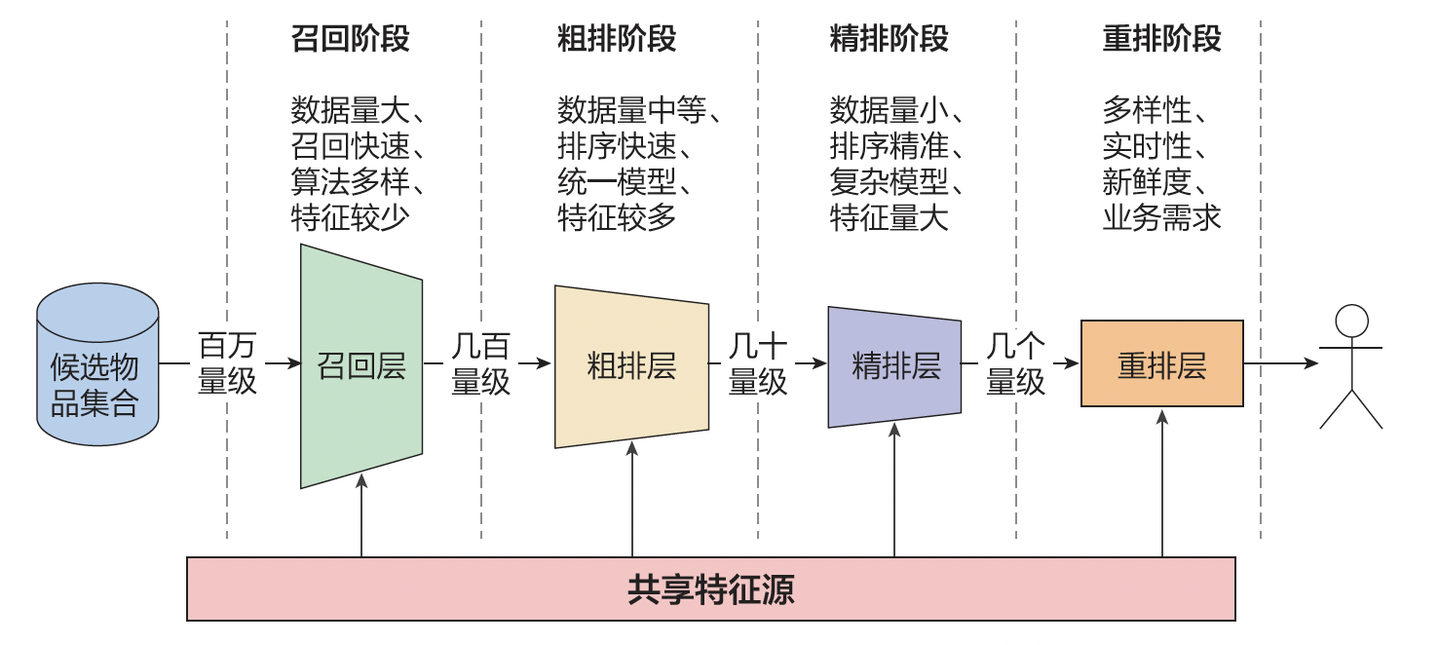
圖二:多階段級(jí)聯(lián)架構(gòu)
一線算法工程師普遍面臨一個(gè)困境:簡(jiǎn)單地增加一些特征或擴(kuò)大現(xiàn)有模型規(guī)模,并不能帶來預(yù)期的效果提升,模型本身也難以有效“變大”。
分析背后深層次的原因,可以概括成以下幾點(diǎn):
?特征工程依賴:成熟業(yè)務(wù)特征工程“礦山”基本被挖掘殆盡,“精心”設(shè)計(jì)的手工特征(如用戶/物品統(tǒng)計(jì)特征、交叉特征等),迭代成本驟升且泛化性差;
?模型工程天花板:現(xiàn)有架構(gòu)無法有效建模“世界知識(shí)”、“用戶意圖Reasoning”,對(duì)多領(lǐng)域、多模態(tài)、用戶行為等吸收、表達(dá)有限;
?級(jí)聯(lián)架構(gòu)導(dǎo)致誤差放大:級(jí)聯(lián)多階段架構(gòu)(如上圖二所示,召回-粗排-精排-重排),算法目標(biāo)被分散到不同階段和不同算法團(tuán)隊(duì)去優(yōu)化,出現(xiàn)了嚴(yán)重的目標(biāo)割裂和誤差傳播。
同時(shí)系統(tǒng)架構(gòu)中還發(fā)現(xiàn)以下問題:
?在級(jí)聯(lián)架構(gòu)中,資源存在嚴(yán)重浪費(fèi)。各模塊之間的通信、緩存的代價(jià)越來越大,以某實(shí)際場(chǎng)景為例:線上服務(wù)超過50%的資源消耗在模塊間的通信和數(shù)據(jù)存儲(chǔ)上,而非核心的模型計(jì)算上。
?核心的模型計(jì)算GPU資源利用率低。大模型的爆火催動(dòng)了硬件芯片TensorCore(矩陣乘)的配比提升,但傳統(tǒng)CTR模型難以對(duì)其有效利用,業(yè)界普遍存在訓(xùn)推資源利用率低的情況。以某實(shí)際場(chǎng)景為例,訓(xùn)練MFU(Model FLOPs Utilization,模型浮點(diǎn)運(yùn)算利用率) 4.6%,推理MFU 11.2%。相比之下,大語言模型(LLM)在H100上訓(xùn)練時(shí)MFU可高達(dá)40-50% 。
針對(duì)上述問題,大語言模型(LLM)提供了解決問題的新思路。
?
1.2 LLM的顛覆性潛力
大語言模型(LLM)和視覺語言模型(VLM)等領(lǐng)域已經(jīng)出現(xiàn)了關(guān)鍵技術(shù)突破,如Scaling Law和先進(jìn)的強(qiáng)化學(xué)習(xí)(RL)方法等。
大模型研究熱點(diǎn)
同時(shí)大語言模型的鏈?zhǔn)酵评砟芰τ楷F(xiàn),帶來了推薦范式躍遷新契機(jī),可重構(gòu)推薦系統(tǒng)的“推理邏輯”:
?長(zhǎng)序列建模強(qiáng)化:將用戶行為視作時(shí)序信號(hào)(如[點(diǎn)擊A, 收藏B, 購買C]),通過自回歸預(yù)測(cè)捕捉復(fù)雜依賴,解決用戶行為深度挖掘的瓶頸;
?世界知識(shí)注入:LLM/VLM預(yù)訓(xùn)練語料蘊(yùn)含跨領(lǐng)域、多模態(tài)知識(shí)(如“滑雪板與護(hù)具的關(guān)聯(lián)性”),破解新用戶、新商品的冷啟動(dòng)難題;
?端到端生成:?jiǎn)我荒P椭苯虞敵雠判蛄斜恚?jí)聯(lián)誤差。
范式變革的本質(zhì):從“預(yù)測(cè)相似性”到“推理用戶需求”,LLM可讓推薦系統(tǒng)具備推理與創(chuàng)造能力。
?
1.3 為什么是現(xiàn)在?
生成式推薦在2025年迎來爆發(fā)并非偶然,而是LLM技術(shù)成熟度與推薦工業(yè)場(chǎng)景需求共振的結(jié)果。
1、LLM生態(tài)成熟
?訓(xùn)練能力提升:分布式訓(xùn)練框架,通過數(shù)據(jù)并行、模型并行和流水線并行策略,結(jié)合混合精度訓(xùn)練、梯度累積等優(yōu)化技術(shù),顯著縮短了模型訓(xùn)練周期。同時(shí),融合監(jiān)督微調(diào)(Supervised Fine-Tuning,SFT)與人類反饋強(qiáng)化學(xué)習(xí)(Reinforcement Learning from Human Feedback, RLHF)技術(shù)棧,有效提升了模型與復(fù)雜業(yè)務(wù)目標(biāo)(如點(diǎn)擊、轉(zhuǎn)化)的對(duì)齊能力。
?推理性能優(yōu)化:大模型推理框架,通過 FlashAttention/PagedAttention、連續(xù)批處理(Continuous Batching)和分布式并行等核心技術(shù),顯著降低了千億級(jí)大模型的推理延遲,提升了吞吐量并減少了資源消耗,有力支撐了其大規(guī)模、低成本的生產(chǎn)部署。
京東自研大模型推理引擎xLLM優(yōu)化: https://aicon.infoq.cn/2025/beijing/presentation/6530 xLLM已經(jīng)開源, https://github.com/jd-opensource/xllm/,敬請(qǐng)關(guān)注!
?
2、工業(yè)級(jí)驗(yàn)證
在過去一年中,Scaling Law在推薦場(chǎng)景的驗(yàn)證打破了傳統(tǒng)DLRM的性能天花板,各種GRs系統(tǒng)在實(shí)際工業(yè)場(chǎng)景中取得了較好的線上效果提升,驗(yàn)證了商業(yè)價(jià)值。這其中包括Meta GR、美團(tuán)MTGR、百度COBRA、字節(jié)RankMixer和快手OneRec等公司的工作,
工業(yè)屆落地: 召回: Google TIGER [2023.5]:https://arxiv.org/pdf/2305.05065 Meta LIGER [2024.11]:https://arxiv.org/pdf/2411.18814 百度 COBRA [2025.3]:https://arxiv.org/pdf/2503.02453v1 排序: Meta GR [2024.2]:https://arxiv.org/pdf/2402.17152 美團(tuán)MTGR [2025.5]:https://zhuanlan.zhihu.com/p/1906722156563394693 百度GRAB [2025.5]:https://mp.weixin.qq.com/s/mT8DmHzgc3ag57PVMqZ3Rw 字節(jié)RankMixer [2025.7]:https://www.arxiv.org/abs/2507.15551 端到端生成: OneRec Technical Report [2025.6]:https://arxiv.org/abs/2506.13695 (2月份初版:https://arxiv.org/abs/2502.18965) 美團(tuán)EGA-v2 [2025.5]:https://arxiv.org/abs/2505.17549
迎來爆發(fā)的前提本質(zhì)是生產(chǎn)力的躍遷,LLM能同時(shí)解決效果、效率和冷啟動(dòng)三大難題,為傳統(tǒng)架構(gòu)升級(jí)提供了新方案。
?
二、技術(shù)演進(jìn):從模塊化到端到端的生成式架構(gòu)
2.1 LLM4Rec:技術(shù)探索前夜
LLM爆火伊始,學(xué)術(shù)界和工業(yè)屆便有不少嘗試和探索:
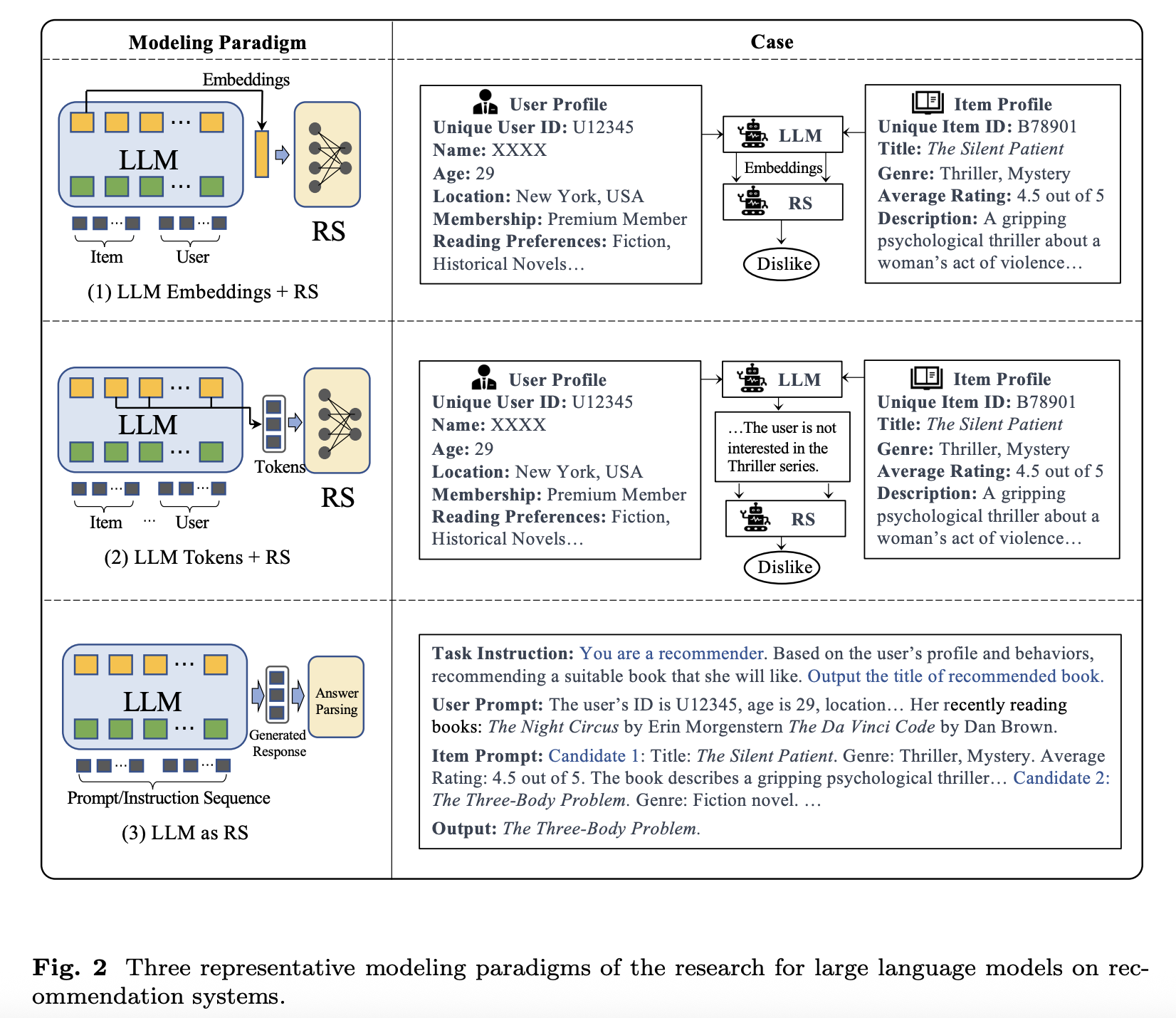
reference: 《A Survey on Large Language Models for Recommendation》
總的來說有三種探索范式:
1、LLM Embeddings + RS
?將大型語言模型(LLM)作為特征抽取器,輸入用戶(User)或物品(Item)的特征,LLM輸出對(duì)應(yīng)特征的嵌入向量(Embedding)。推薦系統(tǒng)(RS)隨后利用這些Embedding進(jìn)行推薦。
?生產(chǎn)應(yīng)用(Production Use): 主要在離線環(huán)境下預(yù)先生成Embedding,例如為物品的文本描述或圖像生成Embedding。
2、LLM Tokens + RS
?向LLM輸入用戶和物品的特征,LLM生成蘊(yùn)含潛在偏好信息的特定標(biāo)識(shí)符(Token)。推薦系統(tǒng)則基于這些Token執(zhí)行推薦任務(wù)。
?生產(chǎn)應(yīng)用(Production Use): 在離線階段預(yù)生成Token(也可稱作標(biāo)簽,Tag),用于推薦系統(tǒng)的標(biāo)簽到物品(tag2item)召回策略或作為模型輸入特征。
3、LLM as RS
?直接將LLM作為推薦系統(tǒng)核心。輸入包括用戶偏好、用戶歷史行為以及明確的任務(wù)指令(Instruction),由LLM生成最終的推薦結(jié)果列表。
?現(xiàn)狀: 目前基本尚未達(dá)到生產(chǎn)可用水平,主要應(yīng)用于學(xué)術(shù)研究領(lǐng)域。
小結(jié):探索落地主要集中在離線鏈路的預(yù)加工任務(wù),未對(duì)推薦系統(tǒng)(RS)的在線鏈路產(chǎn)生實(shí)質(zhì)影響。 范式3(LLM as RS)直接引入原生LLM的成本過高,實(shí)際落地難度大。
?
2.2 生成式推薦Online應(yīng)用范式
LLM4Rec之后,最近半年在線鏈路GRs的應(yīng)用落地如雨后春筍,目前業(yè)界主流有兩大類方式:
1、與傳統(tǒng)級(jí)聯(lián)系統(tǒng)的相應(yīng)模塊協(xié)作或模塊替換
?召回策略增加,開山代表工作:Google TIGER [2023.5]
?精排模型升級(jí),開山代表工作:Meta GR [2024.2]
2、直接應(yīng)用生成模型進(jìn)行端到端推薦
?召排一體,用一個(gè)模型直接生成推薦列表,避免傳統(tǒng)方法中的誤差傳播和目標(biāo)不一致的問題。
?開山代表工作:快手OneRec [2025.6]
本文后續(xù)章節(jié)將結(jié)合核心技術(shù)要點(diǎn),對(duì)幾個(gè)開山代表作Paper做簡(jiǎn)要介紹。
?
2.3 GRs核心技術(shù)要點(diǎn):抽絲剝繭
2.3.1 判別式->生成式的轉(zhuǎn)變
2.3.1.1 什么是生成式推薦?
判別式推薦:
?給定用戶、物品和上下文特征,模型預(yù)估一個(gè)用戶喜歡物品的概率。
?例如:用戶A、物品B —→ 模型預(yù)測(cè)點(diǎn)擊概率是0.76,把候選集中的物品逐個(gè)預(yù)估點(diǎn)擊率,取出top N個(gè)推薦給用戶。
生成式推薦:
?利用用戶的行為歷史序列,基于生成式模型的結(jié)構(gòu),在無輸入候選的情況下直接生成若干用戶最有可能交互的物品。
?例如電影推薦,用戶歷史:[電影A, 電影B, 電影C] —→生成下一個(gè)或者下面N個(gè)用戶最有可能看的電影 D, E, F。
總的來說,判別式推薦是封閉式的,從圈定的候選集合中去排序,產(chǎn)生用戶喜歡的物品列表。而生成式推薦是開放式的,無中生有的生成用戶喜歡的物品列表。
那么,“無中生有”的生成具體是怎么做的呢?
2.3.1.2 Google TIGER:召回階段用自回歸生成式模型
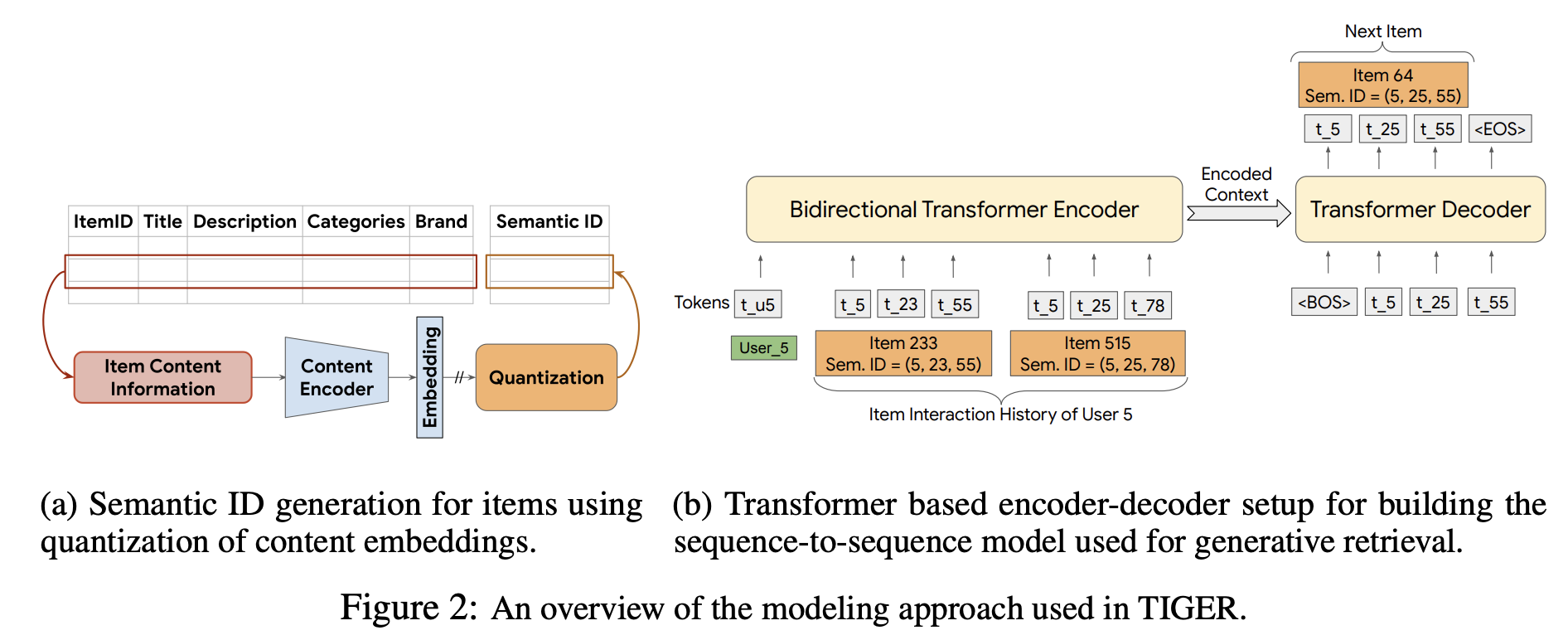
核心價(jià)值:首次將自回歸生成引入召回階段,通過語義 ID 壓縮 Item 空間,為生成式推薦提供了“無中生有”的技術(shù)范式。 局限性:僅適用于召回階段,未解決精排與重排的端到端問題。 Paper:《Recommender Systems with Generative Retrieval》
作者借鑒LLM的模型結(jié)構(gòu)以及自回歸生成的方法,以自回歸方式直接預(yù)測(cè)標(biāo)識(shí)下一個(gè)item的編碼詞組,因此它被視為生成式檢索模型。
?生成式模型結(jié)構(gòu):基于Transformer的T5模型。
?輸入與輸出:均為語義ID序列(Semantic ID Sequence)。
?自回歸生成過程:Transformer解碼器塊(Decoder Block)計(jì)算得到隱狀態(tài)(hidden_states),將其與全庫詞嵌入(Vocab Embedding)計(jì)算得到logits,再進(jìn)行TopK采樣,進(jìn)而得到可能要輸出的Token ID。
?采用束搜索(Beam Search)采樣策略。
詞嵌入(Vocab Embedding):以LLM為例,詞嵌入規(guī)模即所有Token ID大小(與英文單詞有對(duì)應(yīng)關(guān)系,約15萬規(guī)模)。
“無中生有”的生成過程本質(zhì)是與整個(gè)詞嵌入計(jì)算概率分布,再根據(jù)概率取Top。
?
2.3.1.3 Meta GR:精排階段發(fā)現(xiàn)Scaling Law
核心價(jià)值:驗(yàn)證了推薦場(chǎng)景的 Scaling Law,在特征構(gòu)建、模型結(jié)構(gòu)和訓(xùn)練方法上采用了生成式模型的理念和方法論,推動(dòng)生成式推薦向精排階段滲透。 局限性:特征工程簡(jiǎn)化過度導(dǎo)致復(fù)現(xiàn)難度高,需結(jié)合傳統(tǒng) DLRM 特征才能提升效果。另外它是精排模型的替換升級(jí),并非端到端直接生成推薦結(jié)果。 Paper:《Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations》
Meta GR模型結(jié)構(gòu)創(chuàng)新HSTU
Meta GR特征設(shè)計(jì)
?模型架構(gòu)設(shè)計(jì):提出一種新的HSTU(Hierarchical Sequential Transduction Units,層級(jí)序貫轉(zhuǎn)導(dǎo)單元),針對(duì)高基數(shù)、非平穩(wěn)的流式推薦數(shù)據(jù)設(shè)計(jì),通過修改注意力機(jī)制和利用推薦數(shù)據(jù)集特性,在長(zhǎng)序列上比FlashAttention2-based Transformers快5.3x到15.2x。
?推理優(yōu)化:提出一種新的推理算法M-FALCON,通過微批處理(micro-batching)完全分?jǐn)傆?jì)算成本,在相同的推理預(yù)算下,能夠服務(wù)復(fù)雜度高285x的模型,同時(shí)實(shí)現(xiàn)1.50x-2.99x的速度提升。
?Scaling Law:模型參數(shù)量高達(dá)萬億,計(jì)算量提升1000x,第一次達(dá)到GPT-3 175B/LLaMa-2 70B等LLM訓(xùn)練算力,且第一次在推薦模態(tài)觀測(cè)到了語言模態(tài)的Scaling Law。
?
2.3.2 基于語義ID的生成:壓縮Item空間,提升泛化性與生成效率
自Google TIGER提出后, 基于語義ID(Semantic ID)方式的生成式推薦就成為了近兩年的研究熱點(diǎn),各大公司也提出了不少優(yōu)化方案,例如百度的COBRA、快手的OneRec等都使用了語義ID的方案,并做了微創(chuàng)新。
1、為什么語義ID這么受青睞?
前文提到自回歸生成過程需與整個(gè)Vocab Embedding進(jìn)行 Logits 計(jì)算。當(dāng)前大語言模型(如Qwen3,多國語言)的Vocab Embedding大小約為 15 萬 Token。若將生成計(jì)算依賴的全庫Vocab Embedding替換為京東的40億商品,
?這將導(dǎo)致詞嵌入存儲(chǔ)與計(jì)算開銷爆炸;
?且已知大規(guī)模稀疏 Embedding 易引發(fā)過擬合與訓(xùn)練不充分問題,進(jìn)而也影響模型效果;
因此,要實(shí)現(xiàn)高效的商品“無中生有”式生成,必須壓縮Vocab Embedding規(guī)模。
?
語義ID(Semantic ID)通過將十億級(jí)稀疏Item ID抽象、歸納為更高層的萬級(jí)別語義表示,實(shí)現(xiàn)了Vocab Embedding規(guī)模的顯著壓縮,其核心目的有二:
(1)大幅減少稀疏參數(shù)規(guī)模、降低過擬合風(fēng)險(xiǎn):將item參數(shù)體量與傳統(tǒng)LLM的Vocab Embedding對(duì)齊至同一量級(jí)(從40億壓縮到萬級(jí)),有效降低過擬合風(fēng)險(xiǎn),結(jié)合多模態(tài)提取item語義ID,提升模型泛化能力;
(2)支持高效生成式范式:語義ID即Token的總量可控(萬級(jí)別),不僅支撐生成式訓(xùn)練,更能實(shí)現(xiàn)高效的生成推理。通過語義ID將Item空間從40億壓縮至萬級(jí),使自回歸生成的logits計(jì)算開銷降低 99.9%。
?
2、語義ID的生成過程
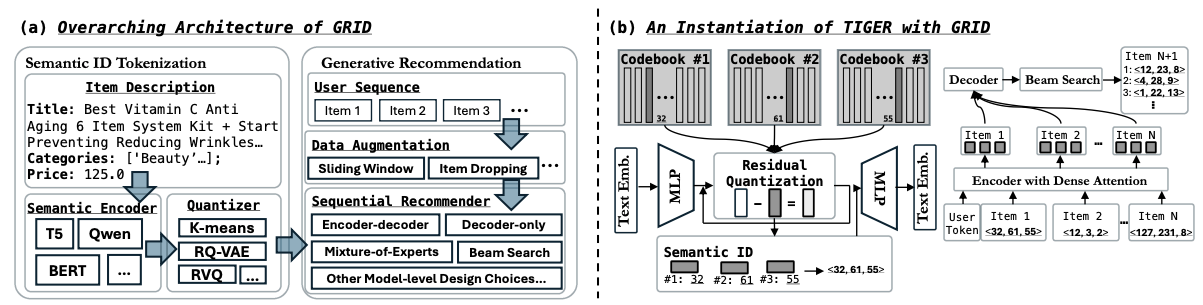
基于語義ID的生成式推薦過程
如上圖所示,基于語義ID的生成式推薦主要分為兩個(gè)階段:
1)Item提取Embedding,再量化成語義ID
使用預(yù)訓(xùn)練LLM/LVM(文本、圖像多模態(tài))對(duì)Item提取Embedding之后, 業(yè)界最常用以下兩種量化方式來提取語義ID:
?RQ-VAE(Residual Quantized VAE): 基于殘差量化, 會(huì)有多層的語義ID, 每一層對(duì)應(yīng)一套Codebook。
?RQ-Kmeans: 沒有了VAE的部分, 并且Codebook是由Kmeans聚類算法得到。
語義ID提取完成后,每個(gè)item會(huì)被表示為類似<32, 61, 55>的三元組,該三元組與item一一對(duì)應(yīng)。
2)Next語義ID生成預(yù)測(cè)
基于Beam Search的自回歸生成方式,可生成多個(gè)Semantic ID三元組(如<12, 23, 8>、<4, 28, 9>等)。實(shí)際在生成階段可能會(huì)遇到“模型幻覺”問題,并不是所有的三元組都能映射成真實(shí)的item_id,需要邊生成邊做有效性過濾。
?
2.3.3 稀疏特征依然很重要
生成式模型結(jié)構(gòu)以及基于Semantic語義ID的自回歸生成提供了很好的范式,但輸入信號(hào)表達(dá)上很快發(fā)現(xiàn)了瓶頸。
1、Meta GR效果難以復(fù)現(xiàn)
分析原因是對(duì)特征工程簡(jiǎn)化太厲害,只保留了行為序列item id和action,其余dense特征、item side info等特征全部刪除,導(dǎo)致輸入信號(hào)表達(dá)有限。
美團(tuán)MTGR基于Meta GR基礎(chǔ)上,保留了全部DLRM原始特征,線上效果有大幅提升。
?保留全部DLRM原始特征,并針對(duì)樣本進(jìn)行無損壓縮,同時(shí)建設(shè)稀疏化存儲(chǔ)以及計(jì)算框架將padding導(dǎo)致的冗余計(jì)算降低至0。
?利用Group LayerNorm以及動(dòng)態(tài)混合掩碼策略,實(shí)現(xiàn)用統(tǒng)一的HSTU架構(gòu)針對(duì)不同語義空間的Token信息進(jìn)行編碼。
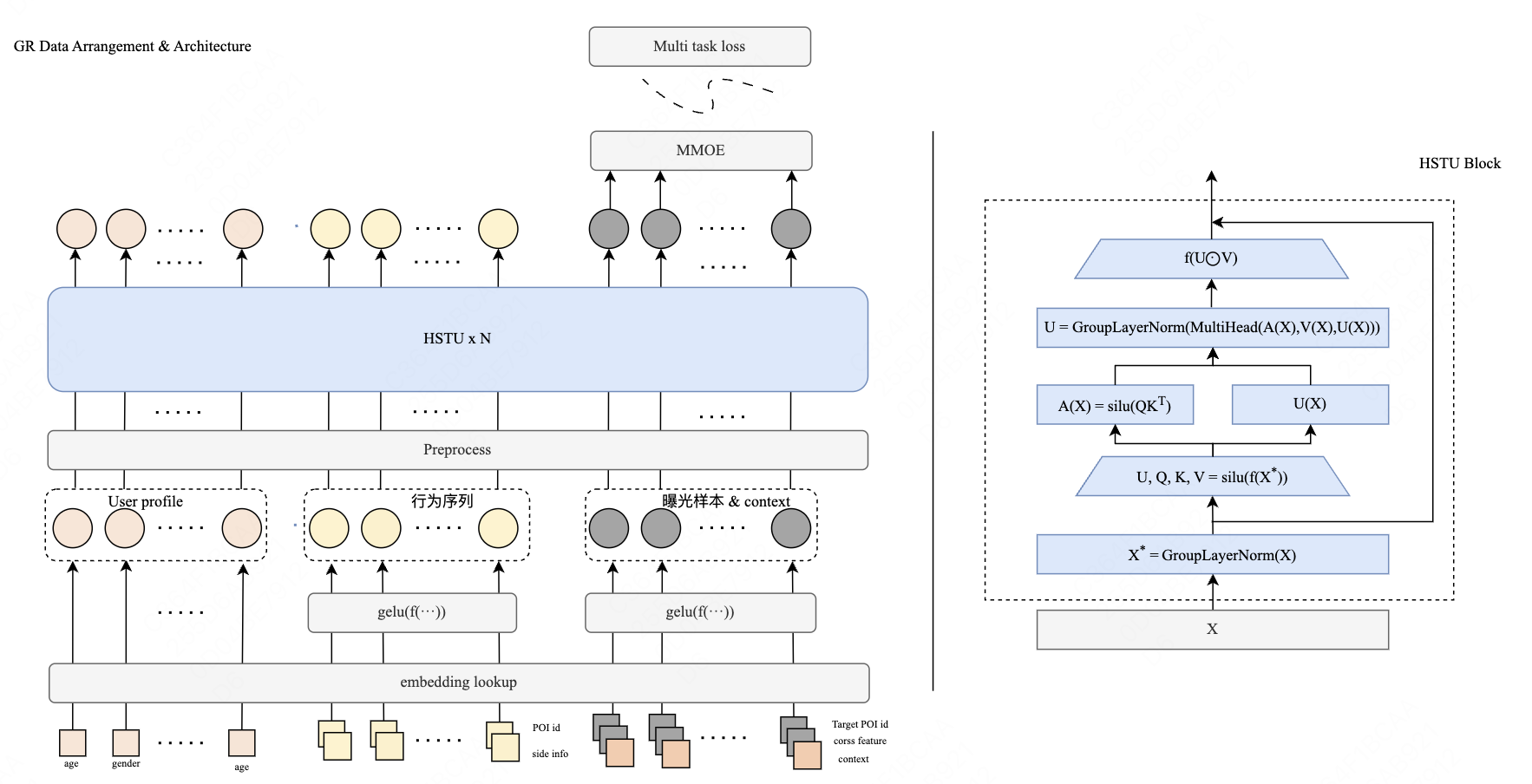
MTGR模型架構(gòu)圖
2、快手OneRec在最新技術(shù)方案里也加上了稀疏特征
OneRec 2月份技術(shù)方案( https://arxiv.org/pdf/2502.18965 )模型輸入為Semantic ID序列(與TIGER一致,由用戶行為序列item id轉(zhuǎn)化而來),而四個(gè)月后,OneRec Technical Report和OneRec V2方案輸入已改為稀疏ID特征,主要原因還是Semantic ID的表達(dá)能力有限。
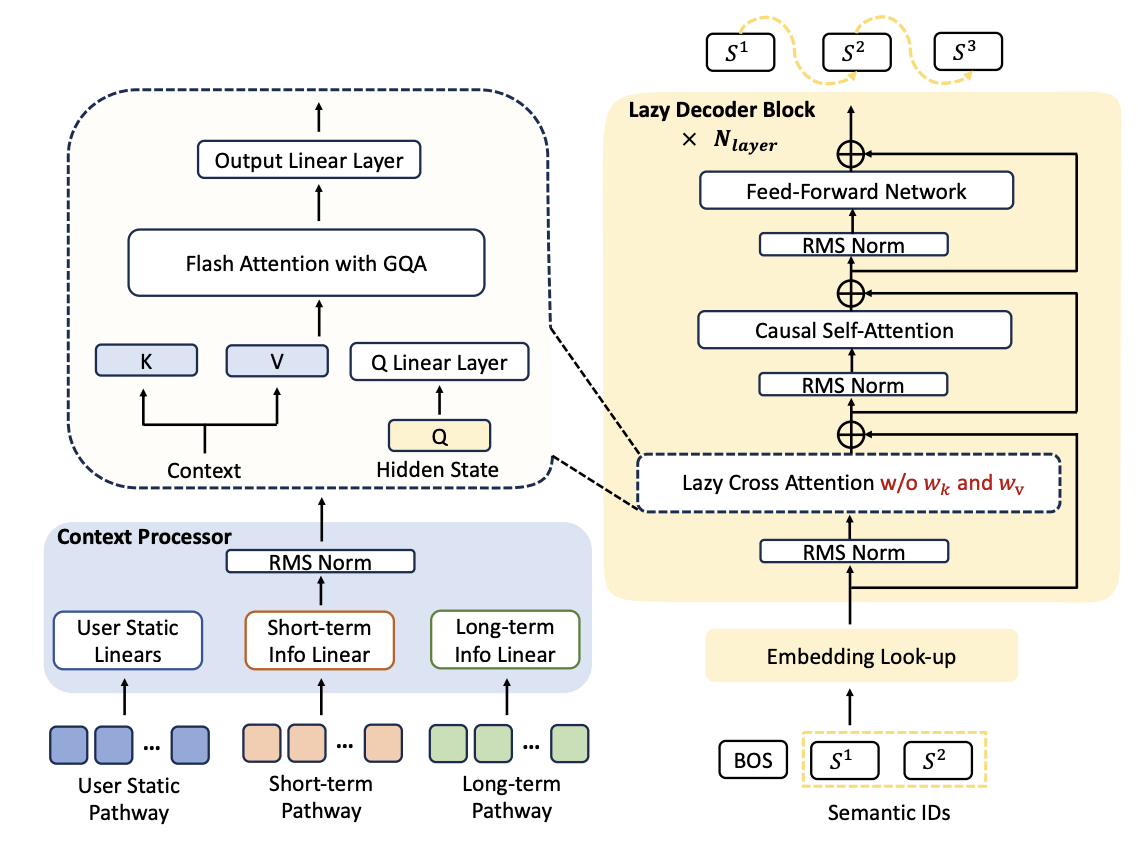
OneRec V2技術(shù)架構(gòu)
OneRec沿用了Encoder-Decoder結(jié)構(gòu),相較于Google TIGER原生方案,主要異同點(diǎn)如下:
?變化1:Encoder結(jié)構(gòu)輸入調(diào)整為傳統(tǒng)DLRM稀疏模型結(jié)構(gòu)(含用戶基礎(chǔ)屬性、偏好及行為序列等)。
?變化2:Decoder結(jié)構(gòu)保留了Cross Attention(本質(zhì)上類似于Target Attention),F(xiàn)FN替換為MoE(Mixture of Experts)結(jié)構(gòu)(推測(cè)受DeepSeek模型啟發(fā))。
?變化3:Semantic ID生成階段,利用miniCPM-V-8B模型聯(lián)合建模item文本與圖像信息,采用RQ-Kmeans量化算法。
需要注意的是OneRec V2模型架構(gòu)換稱“Lazy Decoder-Only”,在筆者看來仍然是Encoder-Decoder結(jié)構(gòu),只是Encoder部分去掉了雙向Attention變簡(jiǎn)單了,用戶行為序列還需要與CrossAttention結(jié)合,這個(gè)是與LLM Decoder-Only最關(guān)鍵的區(qū)別。
?
從工程視角看,
?稀疏圖(Encoder輸入): 特征設(shè)計(jì)沿用傳統(tǒng)長(zhǎng)序列建模方案,采用稀疏特征及Embedding。這其中涉及用戶行為序列的高性能存儲(chǔ)/查詢,以及10TB級(jí)、流式更新的大規(guī)模稀疏Embedding高性能存儲(chǔ)是長(zhǎng)序列建模效果提升的關(guān)鍵依賴。
?稠密圖(Encoder-Decoder): 采用類T5結(jié)構(gòu)(Encoder-Decoder),包含Self Attention、Cross Attention、MoE、自回歸解碼及Beam Search采樣策略等技術(shù)。當(dāng)前模型規(guī)模在0.1B~1B之間,目前已經(jīng)驗(yàn)證MoE Scaling Up可帶來大幅的效果提升,預(yù)計(jì)模型規(guī)模很快會(huì)擴(kuò)展到10B規(guī)模。
?
2.3.4 Encoder-Decoder vs Decoder-Only
目前基于Next Token預(yù)測(cè)的生成式模型架構(gòu)主要分為兩類:
?Decoder-Only架構(gòu):LLM的廣泛實(shí)踐,如Llama、Qwen、DeepSeek等模型均采用此架構(gòu);
?Encoder-Decoder架構(gòu):而目前工業(yè)屆生成式推薦廣泛應(yīng)用的是Encoder-Decoder架構(gòu),例如Google TIGER和快手OneRec等。
在當(dāng)前階段,Encoder-Decoder架構(gòu)在推薦系統(tǒng)中處理長(zhǎng)用戶行為序列以編碼用戶興趣的任務(wù)上效果可能更優(yōu)(注:目前尚缺消融實(shí)驗(yàn)對(duì)比,結(jié)論將持續(xù)更新)。相比于LLM Decoder-Only架構(gòu),Decoder采用Fully Visible Cross Attention,核心在于關(guān)聯(lián)用戶興趣與候選Item。其計(jì)算復(fù)雜度顯著低于自注意力,有效降低了長(zhǎng)序列建模的資源消耗與推理時(shí)延,是實(shí)現(xiàn)高性能推薦的關(guān)鍵設(shè)計(jì)。
不過Decoder-Only架構(gòu)在LLM大語言建模上取得了巨大成功,基于開源模型做微調(diào)天然可保留“世界知識(shí)”的能力,同時(shí)隨著GRs模型規(guī)模的持續(xù)擴(kuò)大和訓(xùn)練數(shù)據(jù)的積累,其在推薦領(lǐng)域的潛力仍需密切關(guān)注和探索。
?
三、工程攻堅(jiān):主要考量和挑戰(zhàn)
作為推薦領(lǐng)域的新范式,GRs在工業(yè)應(yīng)用中面臨諸多挑戰(zhàn)。
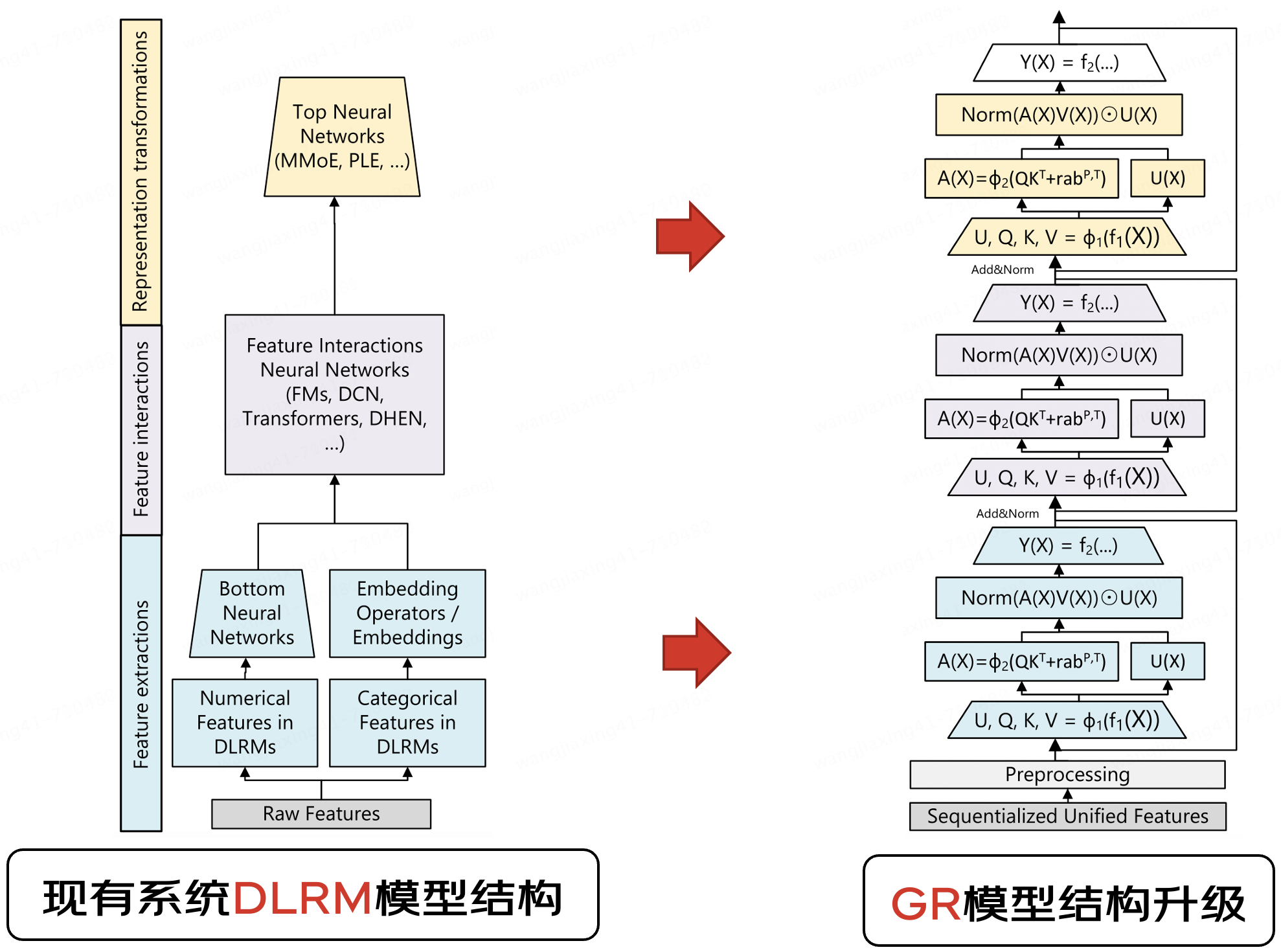
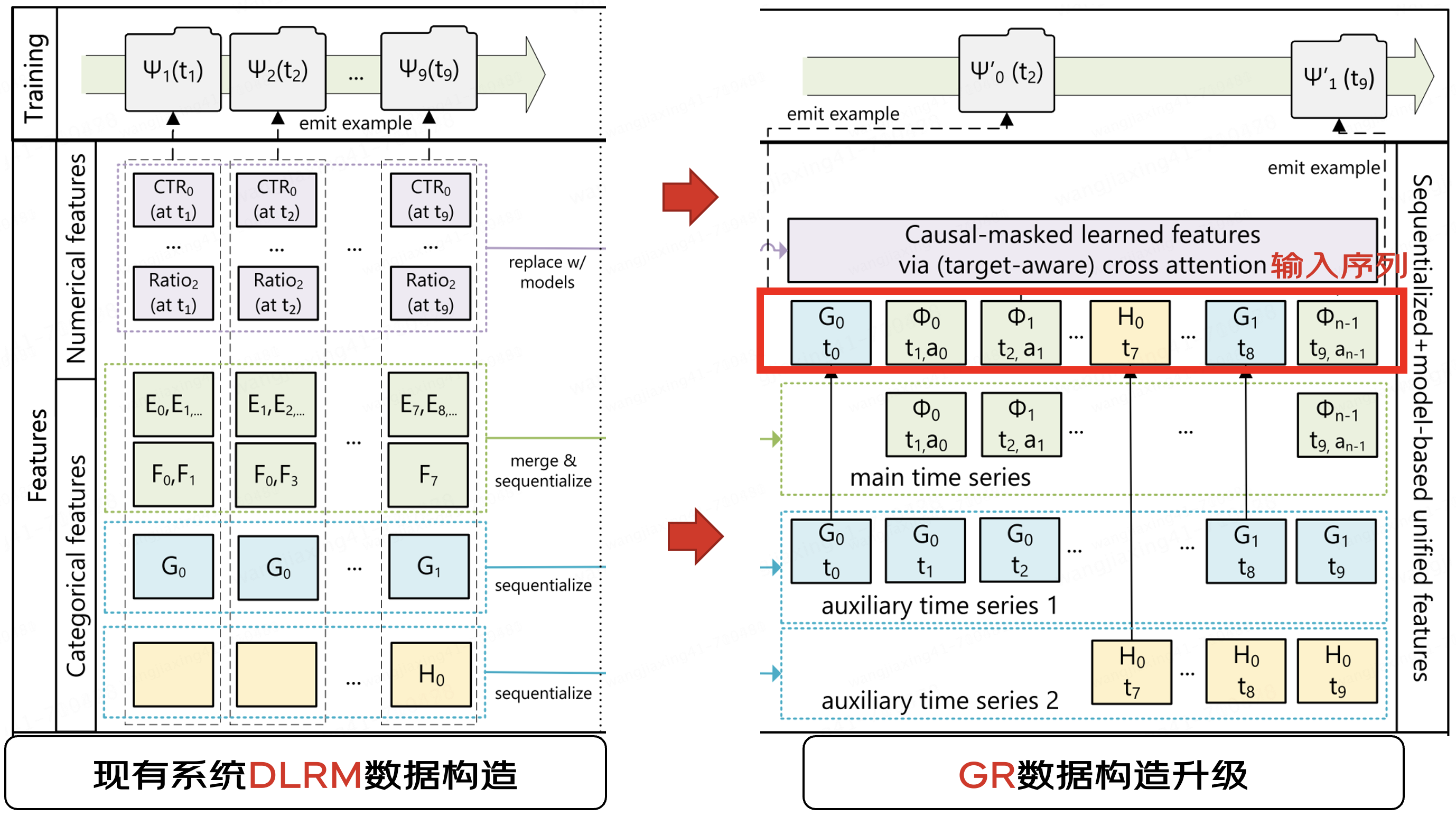
3.1 模型的演變驅(qū)動(dòng)工程架構(gòu)升級(jí)
3.1.1 LLM/DLRM/GRs異同點(diǎn)
|
? |
DLRM 傳統(tǒng)推薦模型 | LLM 大語言模型 | GRs 生成式推薦模型 |
| Feature Engineering | ID化、分桶、交叉組合統(tǒng)計(jì)特征... | ? | ? 稀疏長(zhǎng)序列建模,需求與特性同DLRM |
| ? | Tokenizer,token字符到token id的轉(zhuǎn)換 | ? Tokenizer/DeTokenizer,原始用戶行為序列與Semantic ID(int)的轉(zhuǎn)換 | |
| Feature Store | 100G~10T量級(jí),用戶屬性、用戶行為序列、商品信息等 | ? | ? 行為序列特征,量級(jí)同DLRM |
| ? | Tokenizer詞表,M級(jí)別 | ? Tokenizer詞表,用戶序列Item ID與Semantic ID的KV映射,量級(jí)十GB級(jí) | |
| Embedding | 稀疏ID Embedding:10G~1TB級(jí)大規(guī)模稀疏參數(shù) | ? | ? 稀疏ID同DLRM |
| ? | Vocab Embedding(即Token Embedding): <10G | ? Semantic ID(Vocab Embedding)大小基本同LLM,GB級(jí)大小 | |
| Model | 復(fù)雜模型結(jié)構(gòu): DNN+Attention等變種結(jié)合; Dense大小幾十M | ? | ? 行為序列建模同DLRM |
| ? | Transformer為主體,模型結(jié)構(gòu)收斂; Dense參數(shù)量1B~1T | ? Dense Transformer/HSTU等,Dense大小0.1B~10B | |
| 生成方式 | Point-wise Scoring | Autoregressive generation | Autoregressive generation |
從上述歸納表格可以看到,在特征抽取、特征存儲(chǔ)、Embedding規(guī)模以及Dense模型復(fù)雜度以及結(jié)果生成方式等角度,GRs融合了DRLM的稀疏處理和LLM的稠密生成特性,這使得AI Infra工程實(shí)現(xiàn)面臨獨(dú)特的復(fù)雜性和資源挑戰(zhàn)。
?
3.1.2 生成式推薦GRs的發(fā)展趨勢(shì)
結(jié)合以上特點(diǎn),我們大膽地對(duì)生成式推薦GRs的發(fā)展趨勢(shì)做了預(yù)判,總結(jié)成了Dense Scaling Up、Sparse Scaling Up和生成范式三個(gè)技術(shù)象限,如何在三維技術(shù)象限上既要、又要、還要是個(gè)亟需解決的技術(shù)命題。
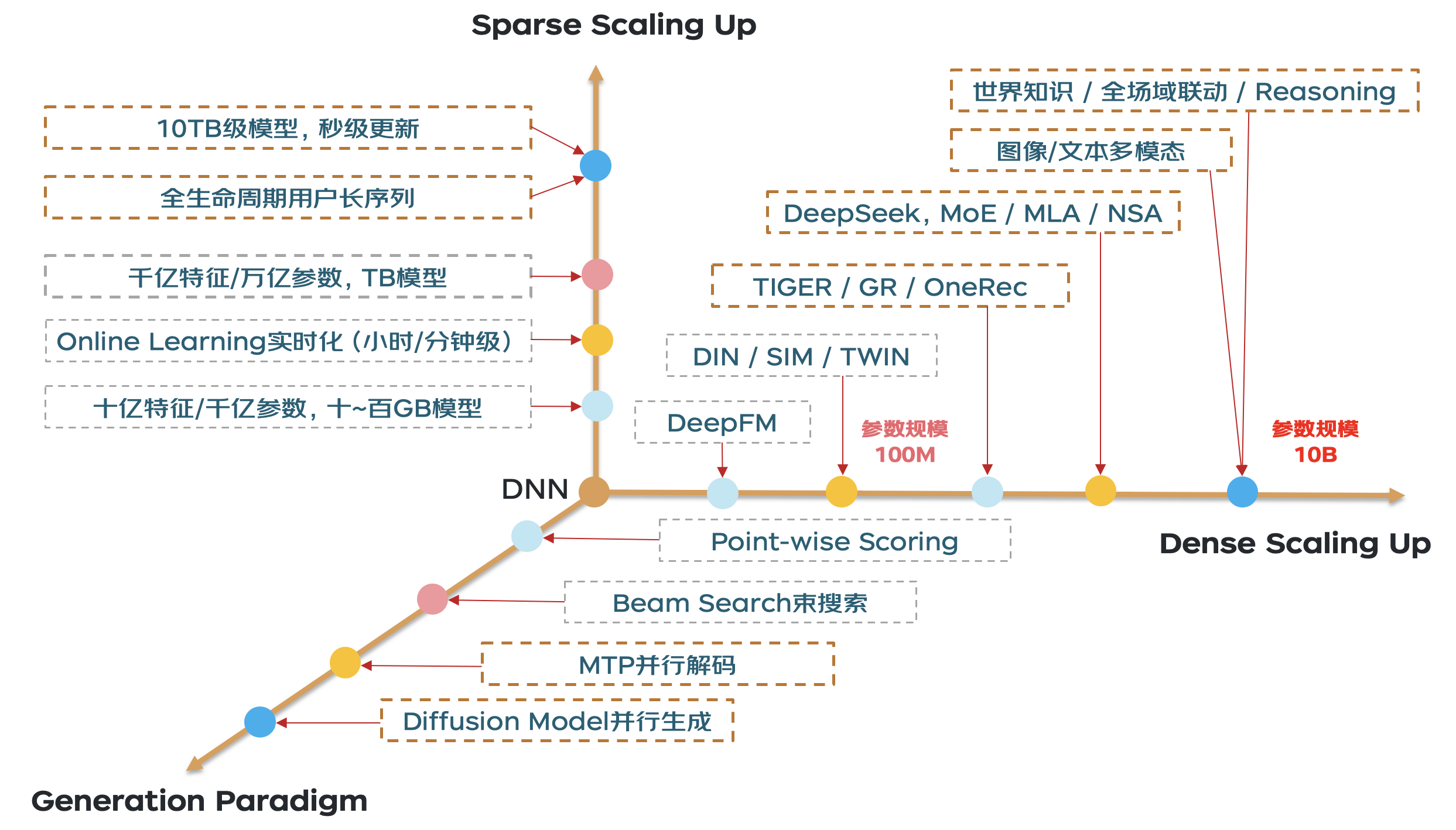
生成式推薦GRs發(fā)展趨勢(shì)研判
(1)Sparse Scaling Up:由于用戶序列中的稀疏特征仍然非常重要,生成式推薦系統(tǒng)(GRs)仍需應(yīng)對(duì)大規(guī)模稀疏Embedding的分布式擴(kuò)展與Online Learning在線學(xué)習(xí)時(shí)效性的挑戰(zhàn)。在全站全域數(shù)據(jù)以及全生命周期用戶長(zhǎng)序列建模的加持下,實(shí)現(xiàn)10TB級(jí)別Embedding的秒級(jí)流式更新,仍是一個(gè)值得持續(xù)深入探索的技術(shù)方向。
(2)Dense Scaling Up:目前傳統(tǒng)的DLRM或類似Meta GR的精排模型中,稠密參數(shù)規(guī)模大多不到百兆,而大語言模型(LLM)已經(jīng)達(dá)到了幾百B甚至上T的參數(shù)量級(jí)。未來若要實(shí)現(xiàn)基于世界知識(shí)的全場(chǎng)景聯(lián)動(dòng)甚至推理能力,必然需要引入圖像、文本更多模態(tài),擴(kuò)大模型參數(shù)規(guī)模。同時(shí)考慮到推理計(jì)算資源成本,結(jié)合混合專家(MoE)結(jié)構(gòu)達(dá)到10B參數(shù)規(guī)模是一條可行路徑。
(3)Generation Paradigm:傳統(tǒng)DLRM的輸入是預(yù)先確定的候選目標(biāo)(Target),對(duì)每個(gè)Target與公共的用戶/上下文信息進(jìn)行兩兩打分,這是一種逐點(diǎn)打分(Point-wise Scoring)范式。當(dāng)前生成式推薦已采用廣度優(yōu)先的束搜索(Beam Search)生成方式,但這僅是一個(gè)起點(diǎn),束搜索的自回歸生成方式調(diào)度開銷較大,導(dǎo)致生成效率偏低。借鑒大語言模型(如DeepSeek)中的MTP并行解碼技術(shù),以及擴(kuò)散模型(Diffusion Model)的并行生成能力,我們相信未來會(huì)出現(xiàn)更高效的并行生成方案。
小結(jié):我們的初衷是工程先行,借鑒大語言模型(LLM)領(lǐng)域的前沿技術(shù)能力(如MLA/NSA、MTP/Diffusion等),構(gòu)建能夠同時(shí)支持Sparse Scaling Up、Dense Scaling Up以及多種生成范式的高效生成與推理系統(tǒng)。這不僅涵蓋若干前沿技術(shù)點(diǎn),更是一條具備高度可行性的技術(shù)發(fā)展路徑!
?
3.2 訓(xùn)練策略升級(jí):多階段訓(xùn)練與強(qiáng)化學(xué)習(xí)
3.2.1 TensorFlow到PyTorch的技術(shù)棧轉(zhuǎn)變
傳統(tǒng)DLRM模型的訓(xùn)練與推理主要基于TensorFlow技術(shù)棧,而LLM模型則普遍采用PyTorch技術(shù)棧,其在低精度量化、FlashAttention加速、TP/DP/PP等多維分布式并行訓(xùn)練能力建設(shè)較為完善。
在生成式推薦的新范式下,Dense模型的訓(xùn)練與推理優(yōu)化若基于PyTorch技術(shù)棧迭代、復(fù)用LLM能力,將具有較高的ROI。
理論上這些工作沒有可行性風(fēng)險(xiǎn),但工作量巨大,包括但不限于以下內(nèi)容:
?基于PyTorch生態(tài)構(gòu)建稀疏Embedding參數(shù)服務(wù)器(PS)能力;
?基于PyTorch生態(tài)構(gòu)建特征準(zhǔn)入、淘汰、展現(xiàn)/點(diǎn)擊(Show/Click)統(tǒng)計(jì)等能力;
?解決離線(Offline)到在線(Online)原生圖化導(dǎo)出的交付與約束等問題。
PyTorch動(dòng)態(tài)圖便于離線靈活構(gòu)圖,允許純Python邏輯與PyTorch代碼混合編寫,但在線推理無法執(zhí)行Python代碼,因此必須從離線導(dǎo)出僅包含原生PyTorch OP表達(dá)的靜態(tài)圖(類似于TensorFlow)。如何有效約束算法邏輯,以及如何高效、自動(dòng)化地導(dǎo)出原生計(jì)算圖,是務(wù)必解決的關(guān)鍵問題。
3.2.2 多階段聯(lián)合訓(xùn)練與強(qiáng)化學(xué)習(xí)
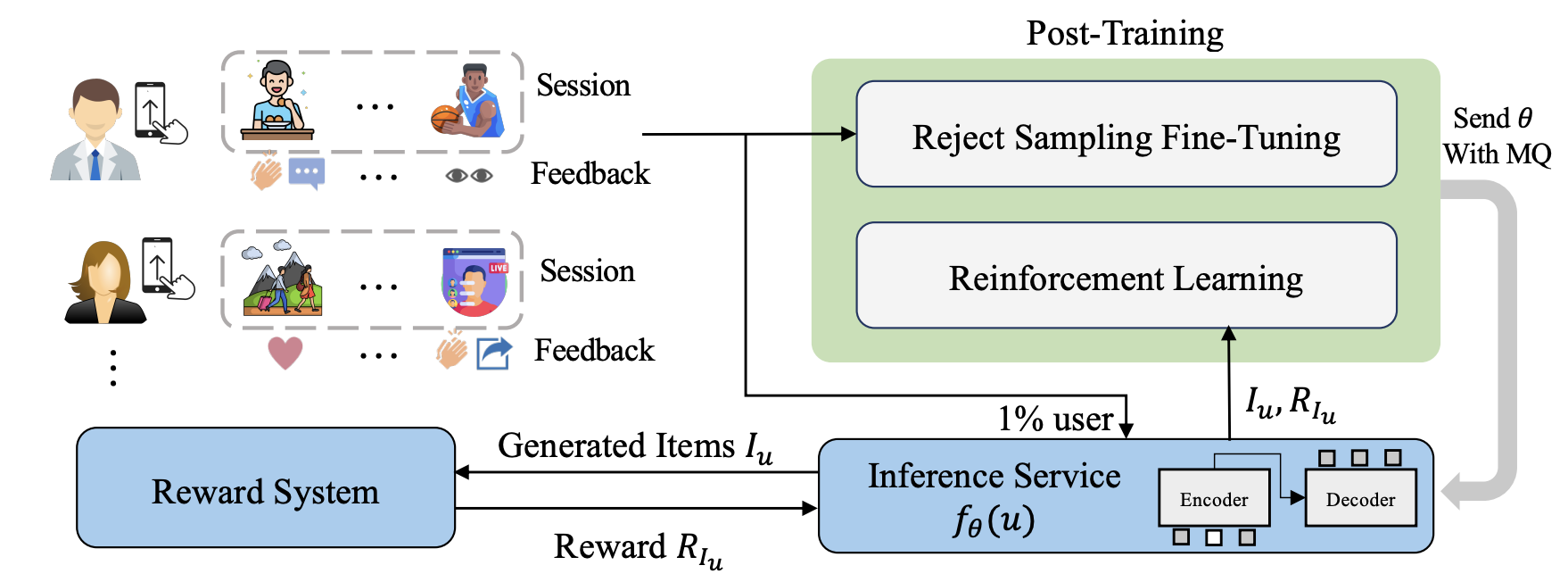
The overall process of GRs post-training
GRs 的核心問題在于如何設(shè)計(jì)訓(xùn)練方法和目標(biāo)以適配推薦任務(wù),需要從傳統(tǒng)的單階段訓(xùn)練,躍遷式的往多階段訓(xùn)練模式升級(jí)。
單階段訓(xùn)練:模型在一個(gè)階段完成推薦任務(wù), 通常專注于召回或排序。
多階段訓(xùn)練:分為預(yù)訓(xùn)練和微調(diào)兩階段。根據(jù)微調(diào)方式不同,又分為:
?基于表征的微調(diào):如字節(jié)跳動(dòng)的 HLLM、快手的 LEARN 通過對(duì)比學(xué)習(xí)生成用戶和物品表征,再用于傳統(tǒng)排序模型。
?基于模型的微調(diào):如快手的 OneRec 和 OneSug 等采用端到端框架,結(jié)合GRPO強(qiáng)化學(xué)習(xí)提升排序能力、通過精巧的獎(jiǎng)勵(lì)系統(tǒng)設(shè)計(jì),為多目標(biāo)優(yōu)化、業(yè)務(wù)策略調(diào)控和團(tuán)隊(duì)協(xié)作模式提供了全新的、更高效的解決方案。
這些訓(xùn)練模式、解決方案的升級(jí),極大的增加了離線鏈路的復(fù)雜性。
?
3.3 推理性能瓶頸:工業(yè)級(jí)在線的百毫秒級(jí)生死線
推薦系統(tǒng)在線鏈路時(shí)延要求較高,通常全鏈路在百毫秒級(jí)別要求,同時(shí)用戶流量在幾萬~幾十萬QPS。伴隨LLMs復(fù)雜架構(gòu)帶來的是推理時(shí)延和資源成本的增加,這是GRs落地的極大挑戰(zhàn)和阻礙。
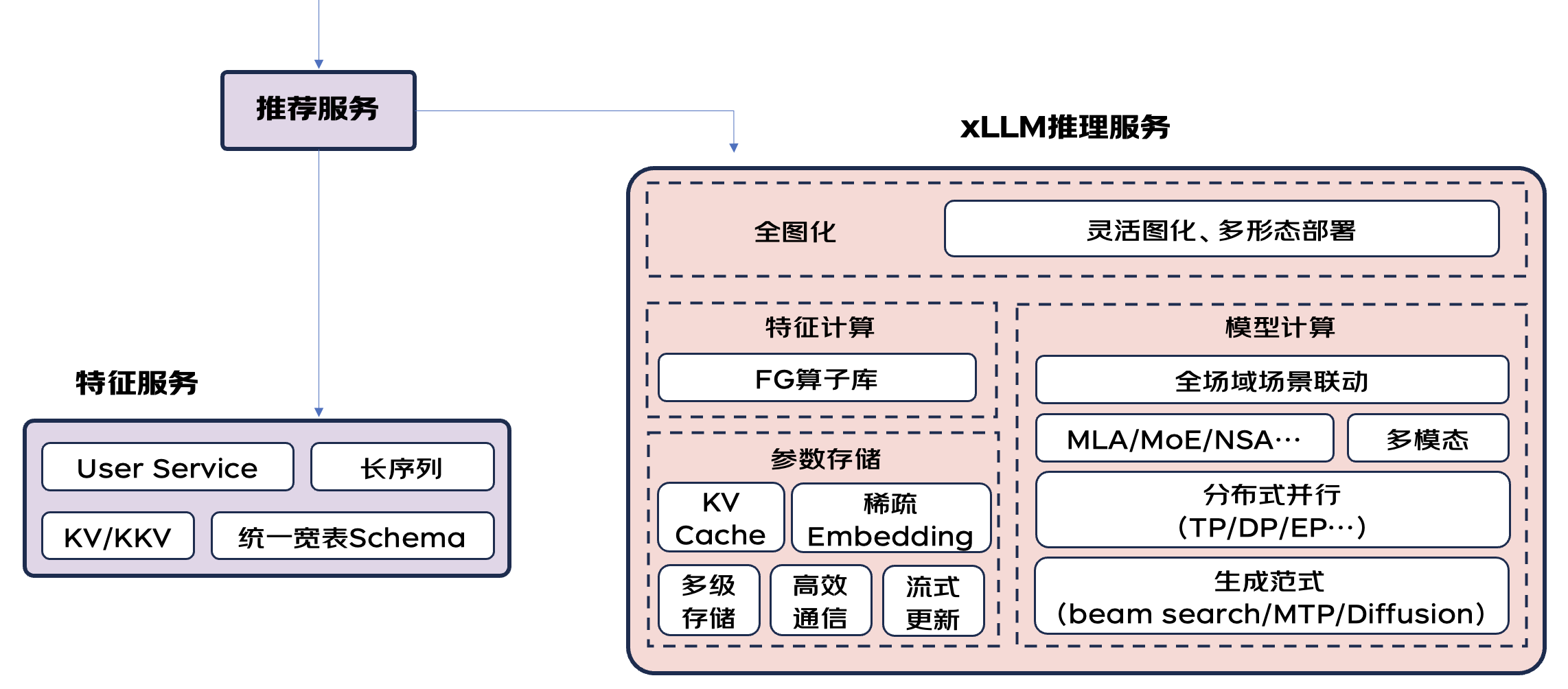
生成式推薦在線架構(gòu)示意
3.3.1 用戶行為序列的高效生產(chǎn)、存儲(chǔ)與查詢
用戶行為序列(如瀏覽、點(diǎn)擊、收藏、加工等時(shí)序事件)是生成式推薦范式的核心驅(qū)動(dòng)數(shù)據(jù),相比于傳統(tǒng)推薦,生成式推薦由于去掉了很多item相關(guān)的特征,這使得用戶行為數(shù)據(jù)的重要性成為核中核。
在新范式下,
?如何采集整個(gè)APP全域場(chǎng)景的更多、更全面用戶行為事件(包括頁面停留軌跡等);
?如何把行為序列做到更長(zhǎng),萬級(jí)->十萬級(jí)->甚至Life Long全生命周期;
為實(shí)現(xiàn)上述目標(biāo),對(duì)數(shù)據(jù)時(shí)序保證、毫秒級(jí)時(shí)效性、通信數(shù)據(jù)量、存儲(chǔ)資源量等都提出了較大的挑戰(zhàn)。
?
3.3.2 生成式推理優(yōu)化
盡管可借鑒 LLM 的成熟經(jīng)驗(yàn),但在訓(xùn)練和推理環(huán)節(jié)仍需大量結(jié)合特定場(chǎng)景和模型結(jié)構(gòu)的針對(duì)性優(yōu)化工作,LLM 技術(shù)并不是總能開箱即用于 GRs。
目前在深入探索并實(shí)踐多項(xiàng)關(guān)鍵技術(shù)路徑:
?高性能計(jì)算Kernel: 針對(duì)模型關(guān)鍵算子(如Self-Attention、Cross-Attention及上Transformer變體)進(jìn)行深度硬件感知優(yōu)化。通過開發(fā)高度融合的計(jì)算核心,將訪存密集與計(jì)算密集操作深度結(jié)合,最大化利用硬件(如GPU/NPU)的計(jì)算單元和顯存帶寬,顯著提升算子的執(zhí)行效率。
?序列表征壓縮:動(dòng)態(tài)識(shí)別并保留序列中的高價(jià)值信息,顯著縮短有效處理長(zhǎng)度。在保證模型效果的前提下,將冗長(zhǎng)輸入序列精煉為緊湊的表征,大幅降低長(zhǎng)序列帶來的計(jì)算與存儲(chǔ)開銷。
?端到端推理流程優(yōu)化:整體生成過程的效率與資源協(xié)同,其中包括CPU/GPU異構(gòu)計(jì)算并行Overlap、高效的Beam Search實(shí)現(xiàn)、有效性過濾早停機(jī)制(及早終止低潛力分支)等,提高整個(gè)推理流水線的高吞吐與低延遲等。
?模型架構(gòu)革新: 通過設(shè)計(jì)創(chuàng)新的稀疏激活機(jī)制、狀態(tài)傳遞機(jī)制或特征解耦架構(gòu),將Transformer核心組件的計(jì)算復(fù)雜度從O(N2)顯著降至線性O(shè)(N)或近似線性水平等。
如下圖所示,借鑒LLM大模型推理目前在系統(tǒng)、模型和硬件層面的深水區(qū)優(yōu)化工作和進(jìn)展,生成式推薦GRs也是如此:未來的核心優(yōu)化技術(shù)手段,都需要深刻理解業(yè)務(wù)場(chǎng)景、深入理解模型結(jié)構(gòu),挖掘場(chǎng)景、模型和硬件的性能極限。
LLM大模型推理核心優(yōu)化方向
限于篇幅原因,未來會(huì)將更多的工程實(shí)現(xiàn)解密,與大家分享這一路以來的優(yōu)秀工程優(yōu)化實(shí)踐經(jīng)驗(yàn)。
四、未來方向
未來GRs的探索將聚焦于以下幾個(gè)前沿方向:
?從“生成”到“深度推理”(Reasoning): 當(dāng)前生成式模型仍處初級(jí)階段,具備基礎(chǔ)生成能力但缺乏真正的“思考”與“深度推理”能力。提升模型的復(fù)雜推理能力,做到不僅能根據(jù)用戶歷史購買“滑雪板”推薦相似商品,還能進(jìn)一步推理用戶可能計(jì)劃去極限運(yùn)動(dòng),進(jìn)而推薦“護(hù)具”這類具有深層關(guān)聯(lián)或場(chǎng)景延伸性的商品。
?獎(jiǎng)勵(lì)機(jī)制的前沿探索: “什么是好的推薦?”,目前仍是開放性問題。生成式端到端架構(gòu)極大凸顯了獎(jiǎng)勵(lì)系統(tǒng)的核心作用,使其成為極具價(jià)值的研究焦點(diǎn)。超越簡(jiǎn)單的點(diǎn)擊率(CTR)/ 轉(zhuǎn)化率(CVR),設(shè)計(jì)能捕捉用戶長(zhǎng)期滿意度、探索價(jià)值以及平臺(tái)生態(tài)(如多樣性、公平性)等的復(fù)合獎(jiǎng)勵(lì)信號(hào),是構(gòu)建真正智能GRs系統(tǒng)的關(guān)鍵。
?真正的多模態(tài)對(duì)齊: 將“用戶行為”視為一種模態(tài),與文本、圖像、視頻等在統(tǒng)一強(qiáng)大的LLM基礎(chǔ)模型中實(shí)現(xiàn)對(duì)齊。達(dá)成此目標(biāo),推薦模型有望在文本空間進(jìn)行思考與推理,達(dá)到全新智能高度。
?并行生成優(yōu)化: 探索 MTP(Multi-Token Prediction,在DeepSeek模型中大放異彩)等并行解碼策略,以及LLaDA(Large Language Diffusion Models)之類的Diffusion Models在GRs場(chǎng)景的應(yīng)用,充分發(fā)揮其并行生成潛力以大幅提升推理效率。
?全鏈路聯(lián)動(dòng)與決策:實(shí)現(xiàn)首頁→推薦→商詳→支付→售后等全鏈路的端到端生成與實(shí)時(shí)聯(lián)合優(yōu)化決策,達(dá)成跨場(chǎng)景全局收益最大化。
?
五、結(jié)語:技術(shù)拐點(diǎn)已至
生成式推薦并非簡(jiǎn)單的漸進(jìn)式優(yōu)化,而是推薦系統(tǒng)的一次認(rèn)知升維:
?突破天花板:Scaling Law 拓展性能邊界,世界知識(shí)破解冷啟動(dòng)難題,端到端架構(gòu)根除級(jí)聯(lián)誤差;
?重構(gòu)價(jià)值鏈:從“猜你喜歡”走向“懂你所想”,甚至創(chuàng)造未知需求。
未來十年,生成式推薦將重新定義人、貨、場(chǎng)的連接方式——這要求我們?cè)谒惴▌?chuàng)新、工程實(shí)踐與業(yè)務(wù)洞察上持續(xù)突破,共同打造推薦系統(tǒng)智能化的新紀(jì)元。
?
附錄參考:
?https://aicon.infoq.cn/2025/beijing/presentation/6530?
?https://arxiv.org/abs/2506.13695?
?https://arxiv.org/pdf/2305.05065?
?https://arxiv.org/abs/2507.06507?
?https://arxiv.org/abs/2503.02453?
?https://arxiv.org/abs/2402.17152
?https://mp.weixin.qq.com/s/eS01m0pam0boYC4WQdZ-lA?
?https://zhuanlan.zhihu.com/p/1906722156563394693?
?https://zhuanlan.zhihu.com/p/1918350919508140128?
?https://mp.weixin.qq.com/s/mT8DmHzgc3ag57PVMqZ3Rw?
?https://www.arxiv.org/abs/2507.15551?
審核編輯 黃宇
-
AI
+關(guān)注
關(guān)注
91文章
40579瀏覽量
302213 -
LLM
+關(guān)注
關(guān)注
1文章
349瀏覽量
1380
發(fā)布評(píng)論請(qǐng)先 登錄
生成式AI加速向終端側(cè)演進(jìn),NPU、異構(gòu)計(jì)算提供強(qiáng)大算力支持
峰會(huì)回顧第7期 | 視窗繪制技術(shù)演進(jìn)和新趨勢(shì)
InfinX?:創(chuàng)造高速板對(duì)板應(yīng)用的無限可能!
探索兩大芯片巨頭的演進(jìn)之道
美的樓宇科技探索數(shù)智電梯的無限可能,李建國剖析優(yōu)勢(shì)
虹科方案 | 工業(yè)樹莓派的Socket通信之旅:探索智能工業(yè)應(yīng)用的無限可能

亞馬遜云科技中國峰會(huì)聚焦生成式AI等前沿科技,探討當(dāng)下時(shí)代的挑戰(zhàn)與機(jī)遇
利用 NVIDIA Jetson 實(shí)現(xiàn)生成式 AI
駕馭創(chuàng)造的力量: 生成式 AI 時(shí)代的 MLOps 演進(jìn)
博世與微軟攜手探索生成式人工智能應(yīng)用新領(lǐng)域

亞馬遜云科技推出由前沿生成式AI技術(shù)驅(qū)動(dòng)的創(chuàng)新服務(wù)
智慧綜合桿路燈與物聯(lián)網(wǎng)融合與發(fā)展 車路協(xié)同——探索智慧路燈系統(tǒng)的無限可能




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論