 是德科技如何提升AI數據中心集群的可擴展性
是德科技如何提升AI數據中心集群的可擴展性

引言
全球范圍內,一場高投入的競賽正在展開:各國與各類企業不斷擴建數據中心,以支撐其人工智能(AI)的發展。
最新研究預測
包括數據中心、網絡與硬件在內的 AI 基礎設施投資將于 2029 年 達到 4230 億美元,年復合增長率(CAGR)約 44%。然而,AI 的快速創新也前所未有地加劇了數據中心網絡的壓力。以 Meta 最近發布的 Llama 3 405B 訓練集群為例,其預訓練階段需要超過700 TB 內存與1.6 萬張 NVIDIA H100 GPU。Epoch AI估計,到 2030 年,AI 模型所需計算能力將達到當今領先模型的1 萬倍。
如果企業里擁有數據中心,引入 AI 就只是時間問題。關鍵問題是:
網絡基礎設施是否具備擴展能力,可以承載復雜且大流量的 AI 訓練負載?
本文聚焦 AI 數據中心集群擴展,識別關鍵網絡挑戰并闡明為何網絡成為新瓶頸;
同時說明如何借助先進模擬與仿真方案克服這些挑戰,幫助您打造可擴展、可靠的 AI 網絡以匹配 AI 戰略目標。
AI 集群的興起
思科(Cisco)的一項最新調研顯示,89% 的受訪者計劃在2026年前部署某種形式的 AI 就緒型數據中心集群。
AI 集群是一個由大量計算資源構成、高度互聯的網絡,用于承載 AI工作負載。與傳統計算集群不同,AI集群針對模型訓練、推理與實時分析進行了優化:它們依賴成千上萬張 GPU、高速互連與低時延網絡來滿足密集計算與數據吞吐的需求。
構建 AI 集群
可以把 AI 集群理解為“縮微網絡”:通過構建“微型計算機網絡”將 GPU 相互連接,使其能高效地進行數據傳輸。在面向數千—數萬 GPU 的分布式訓練中,穩健的網絡連接是長期協同訓練的基本保障。
AI 集群的關鍵組成
01計算節點:
相當于 AI 集群的“大腦”。成千上萬的 GPU 連接到機架頂層交換機(ToR);問題越復雜,所需 GPU 越多。
02高速互連:
如以太網等,用于在計算節點間快速傳輸數據。
03網絡基礎設施:
涵蓋網絡硬件與協議,支撐長期運行、成千上萬 GPU 之間的數據通信。
擴展 AI 數據中心集群
AI 集群規模需要隨業務需求與工作負載彈性擴展。隨著模型日益復雜,組織不斷推動集群擴張。Dell’Oro Group 的網絡報告指出,AI 集群規模幾乎每年以 4 倍速度增長,對網絡基礎設施提出巨大挑戰。
直至最近,網絡帶寬、時延 與 電力分配 等因素將 AI 集群規模限制在約 3 萬張 GPU。然而,xAI 的 Colossus 超級計算機項目在 2024年將規模提升到 10 萬張 NVIDIA H100,突破歷史上限。網絡與內存技術的最新創新,使 GPU 間數據通信更快,標志著 AI 集群可擴展性的重大飛躍。
擴展中的關鍵挑戰
01)網絡挑戰
當參數規模擴展到萬億級及以上時,傳統數據中心網絡可能無法高效擴展。GPU 擅長并行數學計算,但在成千上萬 GPU 協同工作時,若有任意單卡因數據不足或延遲被“卡住”,其他 GPU 也會被拖慢。擁塞網絡帶來的時延拉長或丟包觸發重傳,顯著增加 JCT(作業完成時間),讓價值數百萬美元的 GPU 效率降低。
此外,AI 工作負載下東西向(east-west)流量暴增,若缺乏針對性優化,極易引發擁塞與時延問題。
02)互連挑戰
隨著集群擴展,傳統互連難以滿足吞吐需求。升級到 400G / 800G / 1.6T 等更高速的互連往往勢在必行。但在這些速率下,高速串行鏈路必須經過精細測試及優化,以確保最佳信號完整性(SI)、更低誤碼率(BER)與更好 FEC(前向糾錯)的性能及冗余。這需要高精度、高效率的測試系統在部署前完成鏈路驗證。
03)財務挑戰
除 GPU 費用外,還必須考慮電力、冷卻、網絡設備與更廣泛的數據中心基礎設施成本。AI 訓練常持續數周甚至數月,占用昂貴的計算資源。通過更好的互連或改進的網絡性能加速訓練,不僅能縮短訓練周期,也能更早釋放資源用于其他任務——節省的每一天都可能轉化為顯著成本優勢。
AI 集群網絡的驗證
要加速模型訓練并最大化 ROI,必須對網絡結構(fabric)與 GPU 間互連進行測試與基準評測(benchmarking)。
困難在于:硬件、體系結構設計與動態工作負載三者之間存在復雜耦合,給統一、可復現的驗證帶來挑戰。
實驗室部署的現實制約
在實驗室復制生產級網絡代價高昂:設備有限、需要專業網絡工程師,且實驗室在空間/供電/散熱等方面與生產環境往往不一致。直接在生產網絡上測試,又會擠占算力、影響關鍵 AI 任務。另一方面,AI 工作負載與數據集高度多樣(大小與通信模式差異大),使得問題復現與一致性基準更為困難。最終,要洞察 GPU 之間的集體通信細節,需要先進的監測工具來分析同步與數據交換模式,診斷性能瓶頸。
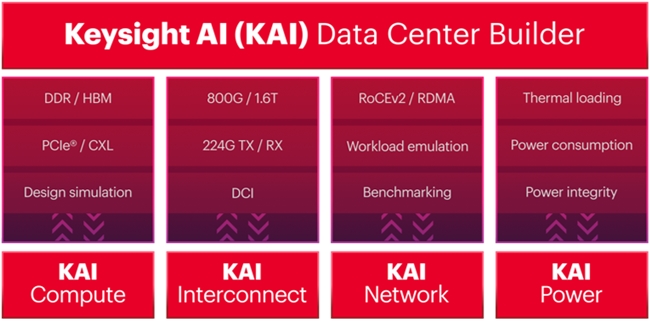
在實驗室“模擬一切”
Keysight AI Data Center Builder 通過高密度高速率測試儀器來仿真真實 AI 流量模式。
典型流程如下
先在實驗室測試目標方案的子集,對集合通信完成時間,算法帶寬,總線帶寬、P50/P95長尾等關鍵指標進行基準評測。這有助于在設計階段平衡 GPU/工作負載設置與網絡配置。當網絡架構師與工程師對結果滿意后,便可將設置應用到生產,并對新結果進行測量。憑借此方案,工程師能夠在實驗室或過渡環境中先設計與優化,隨后落地到生產;這個過程無需在實驗室部署專用的 AI 計算節點與Smart NIC。
面向未來的網絡部署
隨著 AI 重塑數據中心產業,前瞻性地建設網絡至關重要。Ultra Ethernet Consortium(UEC)正在推進開放、互操作的行業標準,面向 AI 的性能與可擴展性。UEC 引入 鏈路級重試(LLR)與擁塞管理等機制,以增強以太網在 AI 工作負載場景下的可擴展性與確定性。展望未來,Ultra Ethernet 與其他新興標準將成為“AI 就緒網絡”的關鍵推動力。
Keysight AI Data Center Builder 的優勢在于:它支持AI網絡各層的模擬和仿真,幫助客戶優化訓練時間、復現生產網絡問題、調優 AI cluster 性能、新方案新組合的驗證、為多廠商協作提供平臺。
是德科技攜手 Heavy Reading 發布《超越瓶頸:2025 年 AI 集群網絡報告》指出,AI 采用正全速推進,而現有基礎設施的就緒度已難以同步跟進。基于全球樣本的調研,報告呼吁電信與云服務提供商將戰略重心從單純“擴張”轉向“以優化為先”,以更確定、更高效的網絡承載下一代 AI 工作負載。歡迎在文末“閱讀原文”下載完整版報告,或者點擊下載參與我們的問卷。
結語
當 AI 推動數據中心進入全新階段,網絡 已成為 AI 成功的新瓶頸亦或新引擎。
借助高保真仿真與系統級驗證,企業能夠在實驗室里復刻生產難題,以可測、可復現 的方法優化網絡并縮短訓練周期,從而在 AI 基礎設施的競賽中占得先機。是德科技將持續以 KAI(Keysight Artificial Intelligence) 方案,幫助客戶在設計—仿真—驗證—部署 的全鏈路上實現“從可用到卓越”的躍遷。
關于是德科技
是德科技(NYSE:KEYS)啟迪并賦能創新者,助力他們將改變世界的技術帶入生活。作為一家標準普爾 500 指數公司,我們提供先進的設計、仿真和測試解決方案,旨在幫助工程師在整個產品生命周期中更快地完成開發和部署,同時控制好風險。我們的客戶遍及全球通信、工業自動化、航空航天與國防、汽車、半導體和通用電子等市場。我們與客戶攜手,加速創新,創造一個安全互聯的世界。
-
網絡
+關注
關注
14文章
8264瀏覽量
94696 -
數據中心
+關注
關注
18文章
5647瀏覽量
75008 -
AI
+關注
關注
91文章
39755瀏覽量
301346
原文標題:800G / 1.6T 時代,如何讓提升 AI 數據中心集群的可擴展性?
文章出處:【微信號:是德科技KEYSIGHT,微信公眾號:是德科技KEYSIGHT】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
睿海光電以高效交付與廣泛兼容助力AI數據中心800G光模塊升級
加速AI未來,睿海光電800G OSFP光模塊重構數據中心互聯標準
PCIe協議分析儀在數據中心中有何作用?
戴爾科技助力盛京醫院打造現代醫療數據中心
瑞薩電子RA系列微控制器的可擴展性強的配置軟件包 (FSP)安裝下載與使用指南
重新思考數據中心架構,推進AI的規模化落地

NVIDIA 800V HVDC 架構賦能新一代AI數據中心 挑戰傳統機架電源系統極限
施耐德電氣發布數據中心高密度AI集群部署解決方案
是德科技推出用于大規模AI數據中心的系列解決方案



 工商網監
工商網監
評論