 進行數據校驗時如何保證場景覆蓋的全面性?
進行數據校驗時如何保證場景覆蓋的全面性?

在數據校驗中保證場景覆蓋的全面性,核心是從 “數據屬性 - 業務邏輯 - 異常邊界 - 環境交互” 多維度拆解場景,通過系統化梳理、優先級排序和動態迭代,避免因場景遺漏導致校驗漏洞。以下是具體的方法論和實施步驟,結合典型場景示例說明:
一、先明確場景覆蓋的核心維度:避免 “碎片化思考”
數據校驗場景的全面性,需圍繞 “數據從產生到應用的全生命周期” 展開,覆蓋以下 5 個核心維度,每個維度對應不同的校驗目標:
| 核心維度 | 覆蓋目標 | 典型場景示例 |
|---|---|---|
| 1. 數據本身屬性 | 確保數據符合基礎格式、類型、取值規則(“數據是否‘合法’”) | 數值型字段(如年齡)非負、字符串型字段(如手機號)格式正確、日期字段不超未來時間 |
| 2. 業務邏輯規則 | 確保數據符合業務場景的邏輯約束(“數據是否‘合理’”) | 訂單金額 ≤ 商品總價 + 運費、用戶注冊時間早于下單時間、庫存數量 ≥ 訂單出庫數量 |
| 3. 異常與邊界 | 覆蓋極端值、非法輸入、故障場景(“數據是否‘抗造’”) | 數值臨界值(如折扣率 0%/100%)、空值 / 重復值、數據傳輸丟包導致的格式錯亂 |
| 4. 時間與環境 | 覆蓋不同時間粒度、運行環境、數據來源的差異(“數據是否‘兼容’”) | 跨時區時間戳校驗、生產 / 測試環境數據格式兼容、Excel 導入 vs API 接口數據校驗 |
| 5. 系統集成交互 | 覆蓋多系統流轉、接口調用的數據一致性(“數據是否‘同步’”) | CRM 系統客戶 ID 同步到 ERP 系統的正確性、緩存與數據庫數據一致性校驗 |
二、分步驟落地:從 “場景拆解” 到 “驗證閉環”
步驟 1:基于 “數據生命周期” 拆解基礎場景
數據從 “產生→傳輸→存儲→應用→歸檔” 的全流程中,每個環節都存在獨特的校驗需求,需逐一拆解:
數據產生環節:用戶輸入(如表單填寫)、設備采集(如傳感器數據)、系統生成(如訂單號)。
場景示例:用戶輸入手機號含非數字字符、傳感器采集數據超出量程(如溫度 - 50℃,正常范圍 - 20~80℃)、系統生成的訂單號重復。
數據傳輸環節:跨系統接口同步(如 API 調用)、文件傳輸(如 Excel/CSV 導入)、網絡傳輸(如 5G / 物聯網)。
場景示例:接口超時導致數據部分丟失、CSV 文件字段分隔符錯誤(逗號變分號)、網絡波動導致數據亂碼。
數據存儲環節:數據庫寫入(如 MySQL/Redis)、數據格式轉換(如 JSON 轉 XML)、存儲容量限制。
場景示例:數據庫字段長度不足導致字符串截斷(如 “用戶地址” 超過 VARCHAR (200))、JSON 嵌套層級錯誤導致解析失敗。
數據應用環節:報表統計、業務決策(如風控規則)、用戶展示(如 APP 界面)。
場景示例:統計 “月度銷售額” 時包含無效訂單(如已取消訂單)、風控系統誤判正常交易(因金額字段格式錯誤)。
步驟 2:結合 “業務特性” 細化場景,避免 “通用化遺漏”
不同業務場景的校驗規則差異極大,需按 “業務模塊→核心流程→關鍵數據” 的層級拆解,確保貼合實際業務需求:
按業務模塊拆分:如電商業務可拆分為 “用戶模塊、商品模塊、訂單模塊、支付模塊、物流模塊”。
按核心流程拆解:以 “訂單模塊” 為例,流程為 “下單→支付→發貨→退款→完成”,每個節點對應專屬場景:
下單環節:商品庫存≥下單數量、用戶賬戶狀態正常(非黑名單)、收貨地址非空。
支付環節:支付金額 = 訂單金額(無額外手續費時)、支付方式與用戶綁定賬戶匹配(如微信支付對應微信綁定手機號)。
退款環節:退款金額≤已支付金額、退款申請時間≤訂單完成后 30 天(業務規則限定)。
標注 “業務特殊規則”:部分場景由業務定制化需求決定,需單獨梳理(如促銷活動中 “折扣金額≤商品原價的 50%”、金融業務中 “單筆轉賬金額≤50 萬”)。
步驟 3:聚焦 “異常與邊界場景”,補上 “容易忽略的漏洞”
邊界值、極端情況、故障場景是校驗的 “盲區重災區”,需通過以下方法系統性覆蓋:
邊界值場景:針對數值、長度、時間等字段,覆蓋 “最小值、最大值、臨界值、相鄰值”:
示例:年齡字段(邊界值 0 歲、120 歲,相鄰值 121 歲(無效)、-1 歲(無效))、密碼長度(6~20 位,邊界值 5 位(過短)、21 位(過長))。
極端情況場景:覆蓋 “數據量極值、頻率極值、邏輯沖突”:
示例:并發提交 1000 條相同訂單(高頻場景)、單條數據包含 1000 個嵌套字段(數據量極值)、“訂單發貨時間早于下單時間”(邏輯沖突)。
故障模擬場景:模擬系統異常、環境故障,驗證數據校驗的 “容錯能力”:
示例:數據源中斷(如傳感器斷電,采集數據為 null)、數據庫宕機后恢復(校驗數據一致性)、第三方接口返回錯誤碼(如支付接口返回 “系統繁忙”)。
步驟 4:考慮 “多維度交叉場景”,避免 “單一維度局限”
實際業務中,場景往往是 “多維度交叉” 的,需組合不同維度的條件,覆蓋更復雜的情況:
示例 1:“時間 + 業務規則” 交叉:促銷活動期間(時間維度),用戶下單金額≥100 元可享 8 折(業務規則),需校驗 “活動時間內的訂單是否正確計算折扣”“活動結束后是否自動取消折扣”。
示例 2:“數據來源 + 異常值” 交叉:API 接口采集的溫度數據(來源維度)超出量程(異常值)、Excel 導入的用戶數據(來源維度)包含重復 ID(異常值)。
示例 3:“用戶角色 + 數據權限” 交叉:普通用戶只能查看自己的訂單(角色維度)、管理員可查看所有訂單,需校驗 “普通用戶嘗試訪問他人訂單時是否攔截”。
步驟 5:通過 “場景清單 + 評審機制” 確保無遺漏
建立 “場景清單”:將所有拆解的場景按 “維度→模塊→場景描述→校驗規則→優先級” 整理成表格,避免碎片化記錄。
示例(訂單模塊場景清單片段):
| 維度 | 場景描述 | 校驗規則 | 優先級 |
|---|---|---|---|
| 業務邏輯 | 下單時商品庫存不足 | 庫存數量 > 下單數量 | 高 |
| 邊界值 | 訂單金額為 0 元 | 訂單金額 > 0 | 高 |
| 數據傳輸 | 支付接口超時導致數據丟失 | 接口重試 3 次,失敗則標記 “待處理” | 中 |
組織跨角色評審:聯合 “業務人員(確認業務規則)、開發人員(確認技術實現)、測試人員(確認校驗覆蓋)、運維人員(確認環境兼容性)” 評審場景清單,補充遺漏(如業務人員可能指出 “預售訂單的庫存校驗規則不同”)。
優先級排序:按 “影響范圍(核心業務 vs 邊緣業務)+ 發生概率(高頻 vs 低頻)” 排序,優先覆蓋 “高影響 + 高頻” 場景(如支付金額校驗),再補充 “低影響 + 低頻” 場景(如歸檔數據的格式校驗)。
步驟 6:動態迭代場景,適應 “業務 / 系統變化”
場景覆蓋不是 “一次性工作”,需持續更新:
業務變更時:如電商新增 “直播帶貨” 模塊,需補充 “直播間下單的庫存實時校驗、主播傭金計算數據校驗” 等場景。
系統升級時:如數據庫從 MySQL 遷移到 PostgreSQL,需補充 “數據類型兼容性校驗(如 PostgreSQL 的 JSONB 字段 vs MySQL 的 JSON 字段)”。
問題反饋時:當線上出現校驗漏洞(如用戶用 “0.01 元” 下單成功,因未校驗金額最小閾值),需將該場景補充到清單并優化校驗規則。
三、工具輔助:提升場景覆蓋效率
場景梳理工具:用思維導圖(如 XMind)可視化 “維度→模塊→場景” 的層級關系,避免邏輯混亂;用用例管理工具(如 TestRail)記錄場景清單,便于跟蹤評審和迭代。
自動化校驗工具:針對高頻場景(如接口數據校驗),用 Postman/JMeter 模擬不同場景的請求,自動驗證響應數據;針對數據庫場景,用 SQL 腳本批量校驗邊界值、重復值。
行業規范參考:如金融數據需符合《金融數據安全 數據生命周期安全規范》,醫療數據需符合《醫療數據安全指南》,可參考行業標準補充合規性場景(如患者身份證號脫敏校驗、金融交易日志不可篡改校驗)。
總結:全面性的核心是 “‘全流程 + 全維度 + 業務貼合’的系統化梳理”
保證場景覆蓋全面性,關鍵不是 “羅列所有可能”,而是 “基于數據生命周期和業務特性,用結構化方法拆解場景,再通過評審和迭代補全漏洞”。核心原則是:
不遺漏 “數據產生到應用” 的任何環節;
不脫離 “具體業務規則” 談通用場景;
不忽視 “邊界值、故障、交叉場景” 等盲區;
不停止 “隨業務 / 系統變化的動態更新”。
審核編輯 黃宇
-
數據校驗
+關注
關注
0文章
8瀏覽量
6926
發布評論請先 登錄
Neway微波的高頻覆蓋
電能質量在線監測裝置自診斷功能的軟件校驗具體是如何實現的?
PPEC Workbench 平臺拓撲全覆蓋,滿足各類電源開發需求
智能網聯汽車測試場景覆蓋度分析
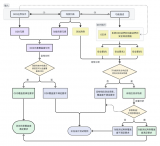
如何驗證電能質量在線監測裝置數據校驗系統的準確性?
怎樣選擇適合的數據校驗系統時間同步硬件?

如何保證數據校驗系統的時間同步以提高準確性?
電能質量監測中,有哪些方法可以提高數據校驗系統的準確性?

如何確保電能質量在線監測裝置的數據校驗的準確性?

如何收集電能質量在線監測裝置的運行數據?

如何使用運行數據趨勢分析驗證裝置準確性?

labview數據采集同步性及獲取時間問題
labview進行的數據采集
基于Verilog語言實現CRC校驗



 工商網監
工商網監
評論