 NVIDIA硅光技術助力邁向百萬GPU AI工廠
NVIDIA硅光技術助力邁向百萬GPU AI工廠

在支撐萬億參數時代的 AI 工廠,為何網絡比以往更為重要。
在全球范圍內,AI 工廠正在崛起 —— 大量的這些新型數據中心并非為提供網頁或電子郵件服務而建,而是用于訓練和部署智能本身。互聯網巨頭們已經為其客戶在 AI 云基礎設施上投資了數十億美元,現在正在打造 AI 工廠上展開了激烈競爭,以迎接下一代的產品和服務。各國政府也紛紛加大投資,迫切希望借助 AI 實現為國民量身定制的個性化醫療及語言服務。
歡迎來到 AI 工廠時代 —— 在這個時代,規則正在被改寫,構建方式與傳統的互聯網已截然不同。這些并非典型的超大規模數據中心,它們完全是另一番模樣。可以將它們視為由數萬個乃至數十萬個 GPU 拼接而成的高性能引擎——不僅僅是將他們搭建起來,還要將其作為一個整體進行編排、運營和操作。而這種編排能力,正是關鍵所在。
這個巨大的數據中心已成為新的計算單元,而這些 GPU 的連接方式定義了此計算單元的功能。單一的網絡架構無法滿足需求,我們需要的是采用前沿技術進行分層設計,比如曾經看起來像科幻小說一樣的光電一體化封裝(CPO)技術。
這種復雜性并非缺陷,而是其核心特征。AI 基礎設施與以往所有技術的差異化正在快速加大,若不重新思考各種路徑的連接方式,將無法進行擴展。網絡層設計失誤,整臺機器將陷入停滯;設計得當,則能獲得卓越性能。
伴隨這種轉變而來的是重量的顯著增加。十年前,芯片追求輕薄設計。如今,最前沿的技術卻轉向了服務器機柜內數百公斤的銅背板,液冷通路的設計、定制的總線架以及銅背板的設計。AI 如今需要大規模、工業級的硬件支持,而且模型越復雜,越需要系統的縱向和橫向擴展。
以NVIDIA NVLink總線背板為例,它需要連接 5000 多根同軸電纜——緊密纏繞且布線精準。其每秒傳輸的數據量幾乎相當于整個互聯網的流量,可在 GPU 到 GPU 之間實現 130 TB/s 全連接帶寬。
這不僅是速度快,而是整個系統的基礎,在機架內部的 AI “超級高速路”。
數據中心即計算機
訓練現代大語言 AI 模型并非依賴單臺機器的運算能力,而是要協調數萬顆乃至數十萬顆作為 AI 計算超級加速器的 GPU 協同工作。
這些系統依賴分布式計算,將海量計算任務分配到各個節點(單個服務器),每個節點處理一部分工作負載。在訓練過程中,這些巨型數字矩陣的分片任務需要進行定期合并和更新。這種合并通過集體操作實現,例如“all-reduce”(聚合來自所有節點的數據并重新分發結果)和“all-to-all”(每個節點與所有其他節點交換數據)。
這些過程極易受網絡速度和響應能力的影響——工程師稱之為延遲(延遲時間)和帶寬(數據容量),這會導致訓練中斷。
而在推理——即通過運行訓練好的模型來生成答案或預測,面對的挑戰則完全不同。如檢索增強生成系統,將 LLM 與搜索結合,需要實時查詢和響應。在云環境中,多租戶推理要求不同客戶的工作負載順暢運行且互不干擾。這需要超高速度、高吞吐量的網絡,既能應對海量需求,又能確保用戶間的嚴格隔離。
傳統以太網專為單服務器工作負載設計,無法滿足分布式 AI 的需求。過去,抖動和不穩定傳輸尚可容忍,如今卻成了瓶頸。傳統以太網交換機架構從未針對穩定、可預測的性能進行設計,這種局限性仍影響著其最新一代產品。
分布式計算需要為零抖動運行而構建的橫向擴展基礎設施——能夠應對突發的極端吞吐量、提供低延遲、保持可預測且穩定的 RDMA 性能,并隔離網絡上其他業務的干擾。這也是為什么 InfiniBand 網絡成為高性能計算超級計算機和 AI 工廠的黃金標準。
借助NVIDIA Quantum InfiniBand,集合運算可通過 SHARP 協議(Scalable Hierarchical Aggregation and Reduction Protocol)直接運行在網絡上,使歸約操作的數據帶寬翻倍。它采用動態路由和基于遙測的擁塞控制技術,在多條路徑上分配流量,保證確定性帶寬并隔離噪聲。這些優化使 InfiniBand 能精準地擴展 AI 通信。這也是為何 NVIDIA Quantum 基礎設施連接了全球超級計算機 TOP500 榜單中的大多數系統,且僅兩年內就實現了 35% 的增長。
對于跨數十個機架的集群,NVIDIA Quantum X800 InfiniBand 交換機將 InfiniBand 性能推向新高度。每臺交換機提供 144 個 800 Gbps 端口,支持基于硬件的 SHARPv4 技術、動態路由和基于遙測的擁塞控制技術。該平臺還通過集成了 CPO 技術來最大限度地縮短了電器件與光器件的距離,降低了功耗和延遲。搭配每 GPU 提供 800 Gb/s 的 NVIDIA ConnectX-8 SuperNIC,這種網絡架構可連接萬億參數模型及利用網絡計算技術。
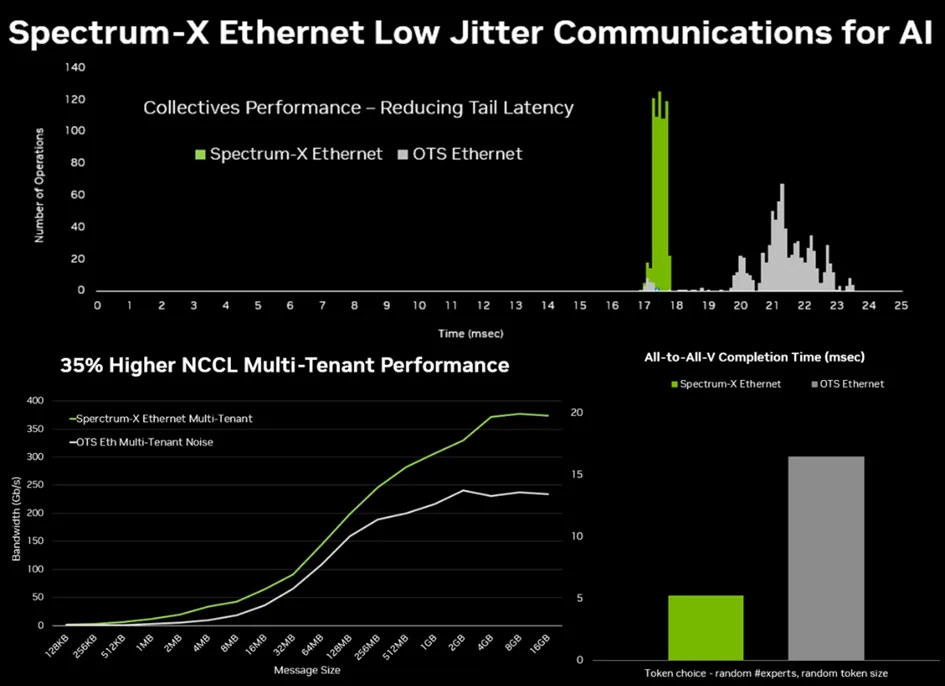
但超大規模數據中心用戶和企業級用戶已在以太網軟件基礎設施上投入數十億美元,他們需要一條能利用現有生態系統運行 AI 工作負載的快捷路徑。NVIDIA Spectrum-X是專為分布式 AI 打造的新型以太網。
Spectrum-X 以太網:將 AI 引入企業
Spectrum-X 為 AI 重塑以太網。2023 年推出的 Spectrum-X 可支持無損網絡、動態路由和性能隔離。基于 Spectrum-4 ASIC 的 SN5610 交換機支持高達 800 Gb/s 的端口速度,并通過 NVIDIA 的擁塞控制技術,在規模化場景下可保持 95% 的數據吞吐量。
Spectrum-X 完全基于標準以太網構建。除支持 Cumulus Linux 外,它還兼容開源 SONiC 網絡操作系統,為客戶提供靈活性。另一個核心組件是基于 NVIDIA BlueField-3 或 ConnectX-8 打造的 NVIDIA SuperNIC,可提供高達 800 Gb/s 的 RoCE 連接,并卸載數據包重排序和擁塞管理任務。
Spectrum-X 將 InfiniBand 的出色創新 —— 如遙測驅動的擁塞控制、動態負載均衡和直接數據放置等技術——引入以太網,使企業能夠擴展至數十萬顆 GPU。采用 Spectrum-X 的大型系統(包括全球最大的 AI 超級計算機)實現了 95% 的數據吞吐量,且應用延遲零衰減。而標準以太網架構因流量沖突,吞吐量僅能達到約 60%。
適用于縱向擴展和橫向擴展的產品組合
沒有任何單一網絡能滿足 AI 工廠的所有層級需求。NVIDIA 為不同層級匹配合適的網絡架構,通過軟件和芯片將所有部分整合在一起。
NVLink:機架內的縱向擴展
在服務器機架內部,GPU 之間的通信需如同同一芯片上的不同核之間的通信般高效。NVIDIA NVLink和 NVLink 交換機跨節點擴展了 GPU 內存和帶寬。在 NVIDIA Blackwell NVL72 系統中,36 顆 NVIDIA CPU 和 72 顆 NVIDIA GPU 連接在單一 NVLink 域中,總帶寬達 130 TB/s。NVLink 交換機技術進一步擴展該架構:單臺 NVIDIA Blackwell NVL72 系統可提供 130 TB/s 的 GPU 帶寬,使集群支持的 GPU 數量達到單臺 8-GPU 服務器的 9 倍。借助 NVLink,整個機架成為一個大型 GPU。
光子技術:下一次飛躍
要實現百萬 GPU 規模的 AI 工廠,網絡必須突破可插拔光學器件的功率和密度限制。NVIDIA Quantum-X 和 Spectrum-X 硅光網絡交換機將硅光直接集成到交換機封裝中,可提供 128 至 512 個 800 Gb/s 端口,總帶寬介于 100 Tb/s 到 400 Tb/s 之間。與傳統光學器件相比,這些交換機的能效提升 3.5 倍,可靠性增強 10 倍,為十億瓦級 AI 工廠鋪平了道路。
兌現開放標準的承諾
Spectrum-X 和 NVIDIA Quantum InfiniBand 均基于開放標準構建。Spectrum-X 是完全基于標準的以太網,支持 SONiC 等開放以太網棧;而 NVIDIA Quantum InfiniBand 和 Spectrum-X 則符合IBTA 的 InfiniBand 和 RDMA over Converged Ethernet(RoCE)規范。NVIDIA 軟件棧的核心組件(包括 NCCL 和 DOCA 庫)可在多種硬件上運行,思科(Cisco)、戴爾科技(DELL)、慧與(HPE) 和 超微(Supermicro) 等合作伙伴已將 Spectrum-X 集成到其系統中。
開放標準為互操作性奠定了基礎,但實際 AI 集群需要進行全棧(GPU、NIC、交換機、電纜和軟件)式深度優化。投入端到端集成的供應商能提供更優的延遲和吞吐量。SONiC 作為在超大規模數據中心中得到強化的開源網絡操作系統,消除了許可限制和供應商鎖定,支持高度定制化,但操作人員仍會選擇專為 AI 性能需求設計的硬件和軟件捆綁方案。實際上,僅靠開放標準無法實現確定性性能,還需要通過創新來解決這些問題。
邁向百萬 GPU 的 AI 工廠
AI 工廠正迅速擴張。歐洲多國正在建設七個國家級 AI 工廠,日本、印度和挪威的云服務商和企業也在部署 NVIDIA 驅動的 AI 基礎設施。下一個目標是具備百萬 GPU 規模的十億瓦級設施。要實現這一目標,網絡必須從附屬品轉變為 AI 基礎設施的核心支柱。
十億瓦數據中心時代帶來的啟示很簡單:數據中心如今就是計算機。NVLink 將機架內的 GPU 連接在一起;NVIDIA Quantum InfiniBand 實現跨機架擴展;Spectrum-X 將這種性能推向更廣泛的市場;硅光技術確保其可持續性。在關鍵之處保持開放,在核心之處追求優化。
-
NVIDIA
+關注
關注
14文章
5592瀏覽量
109719 -
數據中心
+關注
關注
18文章
5647瀏覽量
75009 -
AI
+關注
關注
91文章
39755瀏覽量
301361
原文標題:迎接十億瓦數據中心時代
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA Spectrum-X以太網硅光技術助力AI工廠網絡創新
NVIDIA CEO黃仁勛暢談AI時代最新藍圖
三星攜手NVIDIA 以全新AI工廠引領全球智能制造轉型
OpenAI和NVIDIA宣布達成合作,部署10吉瓦NVIDIA系統

NVIDIA如何優化AI工廠的網絡可靠性與功耗



 工商網監
工商網監
評論