") 新思科技攜手英偉達加速定制化AI芯片開發(fā)
新思科技攜手英偉達加速定制化AI芯片開發(fā)

隨著近年來機器學習技術的不斷進步,人工智能(AI)在圖像識別、自動駕駛和生成式AI等領域均實現(xiàn)了顯著發(fā)展。之所以能取得這些進展,這些進步主要歸功于能夠在日益復雜的數(shù)據(jù)集上訓練大型模型,從而實現(xiàn)更佳的學習和泛化能力,并支持創(chuàng)建更大規(guī)模的模型。隨著數(shù)據(jù)集和模型規(guī)模的增長,需要更強大、更優(yōu)化的計算集群來支持下一代人工智能。
依托25年來在交付硅驗證的IP解決方案領域的豐富經(jīng)驗,新思科技與英偉達及其NVLink生態(tài)系統(tǒng)合作,助力并加速定制化AI芯片的開發(fā)。這項戰(zhàn)略合作將充分發(fā)揮新思科技在芯片IP方面的專長,助力開發(fā)定制化AI芯片,為旨在提供下一代變革性AI體驗的先進計算集群奠定基礎。
更大的數(shù)據(jù)集和日益龐大的AI模型帶來的算力挑戰(zhàn)
在大數(shù)據(jù)集上訓練擁有超萬億參數(shù)的模型需要大量計算資源,包括圖形處理單元(GPU)和張量處理單元(TPU)等專用加速器。
AI計算集群包含三個基本功能:
計算 - 使用處理器和專用加速器。
內(nèi)存 – 通過高帶寬內(nèi)存(HBM)或雙倍數(shù)據(jù)速率(DDR)內(nèi)存,使用虛擬內(nèi)存實現(xiàn)內(nèi)存語義的跨集群實現(xiàn)。
存儲 – 基于的網(wǎng)絡接口卡(NIC),通過基于高速串行計算機擴展總線標準(PCIe)訪問固態(tài)硬盤(SSD),高效地將數(shù)據(jù)從存儲位置傳輸?shù)教幚砥骱图铀倨鳌?/p>
重定時器和交換機構(gòu)成了連接加速器和處理器的網(wǎng)絡結(jié)構(gòu)。為了增強集群的計算能力,有必要在所有功能和互連結(jié)構(gòu)中增加容量和帶寬。
為了開發(fā)日益復雜的數(shù)萬億參數(shù)模型,需要整個集群通過橫向和縱向擴展網(wǎng)絡連接,作為一個統(tǒng)一的計算平臺。
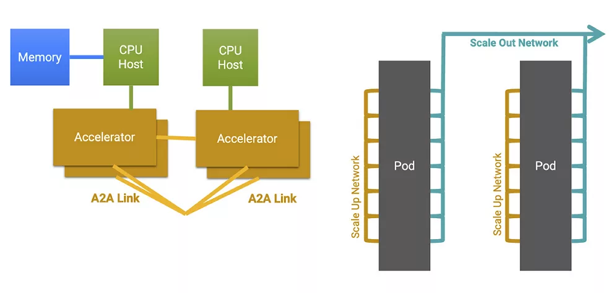
▲圖1:一個代表性的計算集群,具有橫向和縱向擴展的網(wǎng)絡。
基于標準的IP,打造真正互操作的計算集群
為了成功部署下一代計算集群,需要使用經(jīng)過硅驗證、基于先進工藝節(jié)點并能保證互操作性的互連結(jié)構(gòu)。標準化的互連結(jié)構(gòu)能夠支持不同廠商的設備在集群環(huán)境中實現(xiàn)互操作。
PCIe是針對處理器與加速器接口的成熟標準,可確保處理器、NIC、重定時器和交換機之間的互操作性。自1992年以來,PCI-SIG一直在為外設組件互連(PCI)解決方案指定標準,目前PCIe已演進到第七代。PCIe 悠久的歷史和廣泛的部署確保 IP 解決方案能夠從前幾代芯片的開發(fā)經(jīng)驗中獲益。此外,在開發(fā)包括處理器、重定時器、交換機、NIC和SSD的整個生態(tài)系統(tǒng)中,PCIe技術已積累了豐富的部署經(jīng)驗。新思科技完整的PCIe 7.0 IP解決方案建立在超過3,000個PCIe設計經(jīng)驗基礎上,于2024年6月推出,并得到了如英特爾、Rivos、Xconn、Microchip、Enfabrica和Kandou等生態(tài)系統(tǒng)合作伙伴的支持。
在云端部署訓練的模型時,超大規(guī)模云服務商希望繼續(xù)在定制處理器上使用現(xiàn)有軟件,并與各類加速器實現(xiàn)互聯(lián)。在英偉達AI工廠解決方案中,NVLink Fusion提供了另一種將處理器連接到GPU的方法。
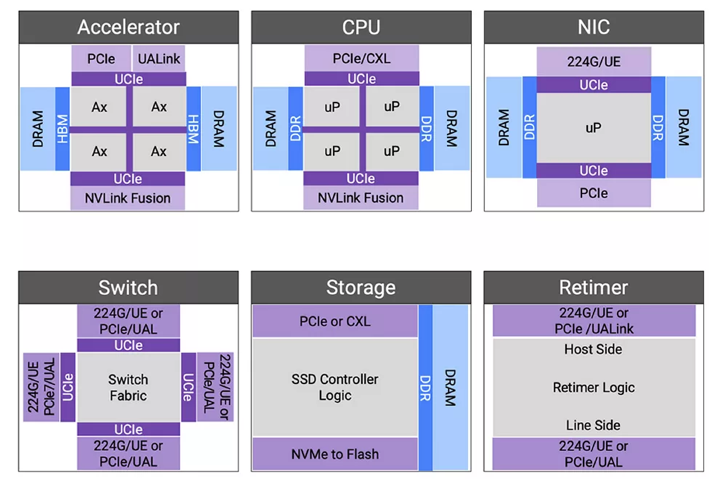
▲圖2:下一代計算集群的組件和互連。
加速器的互連配置方式多種多樣,計算集群的效率會因不同的配置而異。縱向擴展需要在集群中為虛擬內(nèi)存池提供內(nèi)存語義,而橫向擴展則涉及將數(shù)萬到數(shù)十萬片的GPU通過多層交換和擁塞管理技術連接起來。相比于縱向擴展,橫向擴展更能容忍延遲,并且專為帶寬超額使用而設計,以適應 AI 模型數(shù)據(jù)并行操作。2024年12月,新思科技推出了超加速器鏈路(UALink)和超以太網(wǎng)解決方案,能夠高效連接加速器。這個解決方案基于經(jīng)過硅驗證的224G PHY和超過2000個以太網(wǎng)設計,得到了AMD、Juniper和Tenstorrent的公開支持。
萬億參數(shù)模型需要大量內(nèi)存和高數(shù)據(jù)速率以實現(xiàn)低延遲訪問,因此需要增加內(nèi)存帶寬和總?cè)萘俊BM具有大容量和高帶寬特性。新思科技的HBM4 IP是第六代HBM技術,提供高達12 Gbps的引腳帶寬,使得整體接口帶寬超過3 TBps。
通過合封Multi-Die聚合技術,不僅可以克服先進制造工藝的限制來提升計算吞吐量,還能借助新興的光電合封(CPO)技術促進光互連結(jié)構(gòu)的集成。自2022年以來,新思科技一直在開發(fā)線性電光(EO)接口,致力于打造節(jié)能的EO鏈路。通用芯粒互連技術(UCIe)標準為多供應商互操作性提供了明確的路徑。在2023年與英特爾的合作中,新思科技成功演示了第一塊采用UCIe技術且基于芯粒的測試芯片。
多芯片集成(Multi-Die Integration)對散熱提出了諸多挑戰(zhàn),可能影響對溫度敏感的光子元件,甚至導致熱失控。新思科技的Multi-Die綜合解決方案包括Die-to-Die IP、HBM IP等,可提供可靠且強壯的Multi-Die實現(xiàn)方案。
在關鍵互連領域(從處理器加速器接口到先進的多芯片架構(gòu)和HBM),采用成熟且經(jīng)過廣泛驗證的IP解決方案,可以降低定制設計和集成帶來的風險。預先驗證的IP有助于簡化設計和驗證過程,加快開發(fā)進度,最終為一次流片成功鋪平道路,從而快速部署創(chuàng)新且可互操作的計算集群。
-
新思科技
+關注
關注
5文章
970瀏覽量
52975 -
英偉達
+關注
關注
23文章
4109瀏覽量
99532 -
AI芯片
+關注
關注
17文章
2146瀏覽量
36838
原文標題:新思科技×英偉達:互連IP引擎驅(qū)動下一代AI芯片定制革命
文章出處:【微信號:Synopsys_CN,微信公眾號:新思科技】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
中國AI芯片市場:華為將占半壁江山,英偉達跌落,這家第二

施耐德電氣與英偉達深化合作以構(gòu)建高效吉瓦級AI工廠
新思科技與英偉達多項硬核科技成果亮相GTC 2026
恩智浦與英偉達攜手推出面向先進物理AI的創(chuàng)新方案

企業(yè)級AI Agent王炸! 英偉達GTC將開源 NemoClaw


新思科技與英偉達深化戰(zhàn)略合作
黃仁勛:英偉達AI芯片訂單排到2026年 英偉達上季營收加速增長62%再超預期
英偉達斥資50億美元入股英特爾,芯片巨頭攜手重塑行業(yè)格局
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片的需求和挑戰(zhàn)
今日看點丨傳英偉達暫停為中國市場定制H20;估值10億美元的Character.AI公司或?qū)⒊鍪?/a>
外媒:英偉達正開發(fā)新款中國特供芯片B30A 或為旗艦AI芯品B300的閹割版



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論