 谷歌Gemma 3n模型的新功能
谷歌Gemma 3n模型的新功能

作者 / 資深開發者關系工程師 Omar Sanseviero 和高級開發者關系工程師 Ian Ballantyne
從第一個 Gemma 模型于去年年初推出以來,已逐漸發展為生機勃勃的 Gemmaverse 生態系統,累計下載量突破 1.6 億。這個生態系統包括十余款專業模型系列,涵蓋從安全防護到醫療應用的各領域。其中,最令人振奮的是來自社區的無數創新。從像 Roboflow 這樣的創新者構建的企業級計算機視覺,到東京科學研究所創建的高性能日語 Gemma 變體,各位的作品為我們指明了未來的發展路徑。
乘此發展勢頭,我們宣布 Gemma 3n 現已全面發布。雖然預覽版已先行展示了一些功能,但這一移動設備優先的架構現在能夠發揮出全部的潛能。Gemma 3n 為幫助塑造了 Gemma 的開發者社區而生。包括 Hugging Face Transformers、llama.cpp、Google AI Edge、Ollama 和 MLX 在內,您熟悉和慣用的多種工具都支持該模型,讓您能輕松針對特定的設備端應用進行微調和部署。本篇文章將以開發者視角深入探索,介紹 Gemma 3n 背后的一些創新,分享新的基準測試結果,并向您展示如何立即開始構建。
Gemma 3n 的新功能
Gemma 3n 代表了設備端 AI 的重大進步,為邊緣設備帶來了強大的多模態功能;過去,這些性能僅在去年基于云端的一些前沿模型中有所展現。
多模態設計: Gemma 3n 原生支持圖像、音頻、視頻和文本輸入以及文本輸出。
針對設備端優化: Gemma 3n 模型的設計以效率為重點,基于有效參數提供兩種尺寸: E2B 和 E4B。雖然其原始參數數量分別為 5B 和 8B,但憑借架構創新,它們能夠以媲美傳統 2B 和 4B 模型的內存占用運行,E2B 僅需 2GB 內存、E4B 僅需 3GB 內存即可運行。
突破性架構: Gemma 3n 的核心特征包括新穎的組件,如用于計算靈活性的 MatFormer 架構、用于內存效率的逐層嵌入 (PLE)、用于架構效率的 LAuReL 和 AltUp,以及針對設備端用例優化的全新音頻編碼器和基于 MobileNet-v5 的視覺編碼器。
改進的質量: Gemma 3n 在多語言 (支持 140 種語言的文本和 35 種語言的多模態理解)、數學、編碼和推理方面的質量均有提升。E4B 版本的 LMArena 得分超過 1,300,是首個達到該基準且參數低于 100 億的模型。
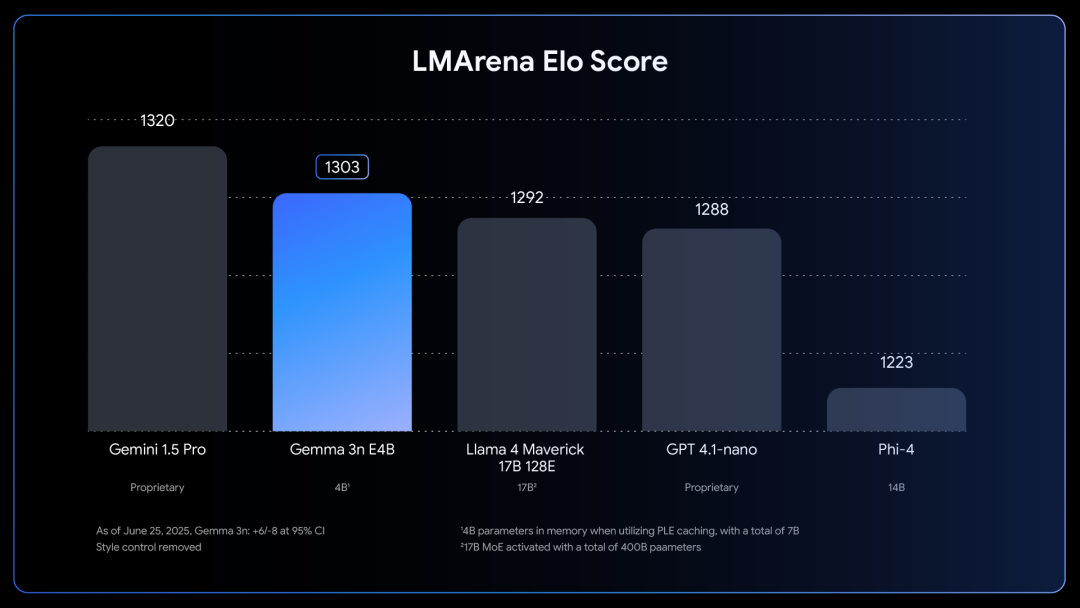
有效
https://developers.googleblog.com/zh-hans/introducing-gemma-3n-developer-guide/
要實現這種設備端性能的飛躍,需要從零開始,對模型進行顛覆性的重新構思和設計,其基礎是 Gemma 3n 獨特的移動設備優先架構,而這一切都源于 MatFormer。
MatFormer:
一個模型,多種尺寸
Gemma 3n 的核心是 MatFormer (Matryoshka Transformer) 架構,這是一種專為彈性推理而構建的新型嵌套式 Transformer。您可以把它想象成俄羅斯套娃: 一個更大的模型包含著更小、功能齊全的自身版本。這種方法將 Matryoshka 表征學習的概念從嵌入層擴展到所有 Transformer 組件。

MatFormer
https://arxiv.org/abs/2310.07707
Matryoshka 表征學習
https://huggingface.co/papers/2205.13147
如上圖所示,在對 4B 有效參數 (E4B) 模型進行 MatFormer 訓練期間,2B 有效參數 (E2B) 子模型在其內部同時得到優化。這在當下為開發者提供了兩種強大的功能和用例:
預提取的模型: 您可以直接下載并使用主 E4B 模型以獲得最高級的功能,也可以使用我們已經為您提取的獨立 E2B 子模型,獲得主模型 2 倍的推理速度。
使用混合匹配 (Mix-n-Match) 自定義調整尺寸: 為了更精細地控制以適應特定的硬件限制,您可以使用我們稱之為 "混合匹配" 的方法,創建介于 E2B 和 E4B 之間的各種自定義尺寸模型。此技術允許您精確切分 E4B 模型的參數,主要是通過調整每層前饋網絡隱藏維度 (從 8,192 到 16,384) 并選擇性地跳過某些層來實現。我們即將發布 MatFormer Lab,該工具可演示如何檢索這些最優模型,這些模型是在 MMLU 等基準測試中通過評估多種配置組合而篩選出來的。
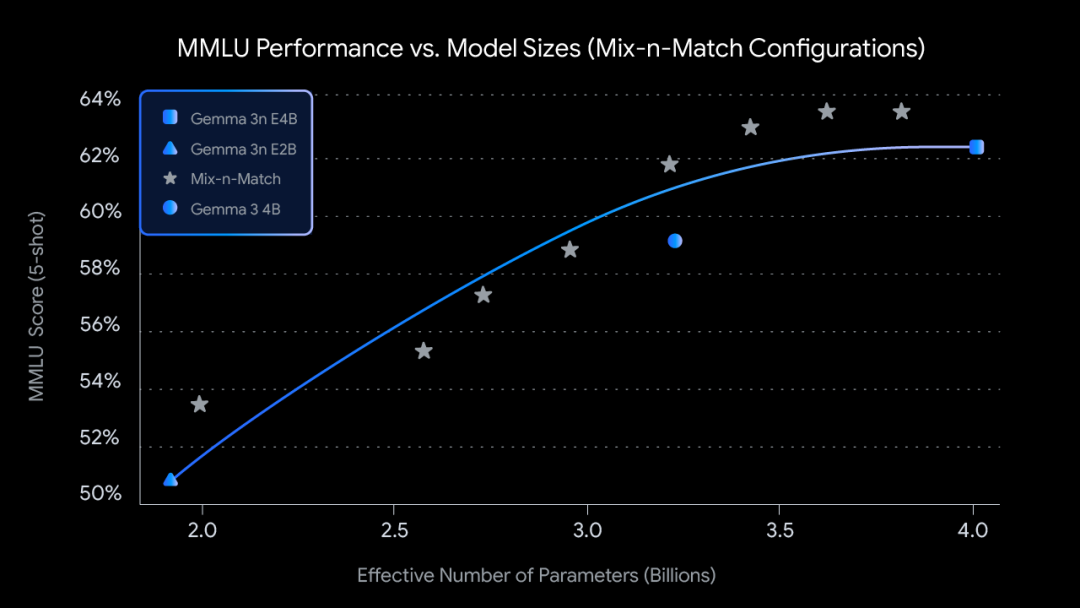
△ 不同模型尺寸的預訓練 Gemma 3n 檢查點的 MMLU 分數 (使用混合匹配)
MatFormer Lab
https://goo.gle/gemma3n-matformer-lab
展望未來,MatFormer 架構也為彈性執行鋪平了道路。雖然這項能力并非本次發布實現的一部分,但它允許單個部署的 E4B 模型在 E4B 和 E2B 推理路徑之間動態切換,從而根據當前任務和設備負載,實時優化性能和內存用量。
逐層嵌入 (PLE):
解鎖更高的內存效率
Gemma 3n 模型包含逐層嵌入 (PLE)。這項創新專為設備端部署量身定制,它在不增加設備加速器 (GPU/TPU) 所需的高速內存占用量的情況下,顯著提升了模型質量。
雖然 Gemma 3n E2B 和 E4B 模型的總參數量分別為 5B 和 8B,但逐層嵌入 (PLE) 技術卻能讓這些參數中的很大一部分 (即與各層相關的嵌入),在 CPU 上高效地加載和計算。這意味著通常在更為受限的加速器內存 (VRAM) 中,只需加載核心 Transformer 權重 (E2B 約為 2B,E4B 約為 4B)。

△ 使用逐層嵌入,您可以在加速器中僅加載約 2B 參數的情況下使用 Gemma 3n E2B
KV 緩存共享:
更迅速的長上下文處理
對于諸多先進的設備端多模態應用而言,處理長輸入 (例如源自音頻和視頻流的連續序列) 至關重要。Gemma 3n 引入了 KV 緩存共享功能,旨在極大縮短流式響應應用的首個 token 生成時間。
KV 緩存共享優化了模型處理初始輸入階段 (通常稱為 "預填充" 階段) 的方式。將局部注意力和全局注意力中間層的鍵 (Keys) 和值 (Values) 直接與所有頂層共享,與 Gemma 3 4B 相比,預填充性能顯著提升了 2 倍。這意味著該模型可以比以前更快地注入和理解冗長的提示序列。
音頻理解:
語音轉文本和翻譯功能
Gemma 3n 使用基于通用語音模型 (USM) 的高級音頻編碼器。編碼器為每 160ms 的音頻生成一個 token (約每秒 6 個 tokens),然后將其作為輸入集成到語言模型中,從而為模型提供高度精細的聲音上下文表征。
通用語音模型
https://arxiv.org/abs/2303.01037
這種集成的音頻功能解鎖了設備端開發的多種關鍵特性,包括:
自動語音識別 (ASR): 直接在設備端實現高質量的語音轉文字。
自動語音翻譯 (AST): 將口語翻譯成另一種語言的文本。
我們觀察到,對于英語和西班牙語、法語、意大利語及葡萄牙語之間的翻譯,AST 的表現尤為出色,為針對這些語言的應用開發者提供了巨大潛力。對于語音翻譯等任務,利用思維鏈提示可以顯著改進結果。以下是一個示例:
```
Transcribe the following speech segment in Spanish, then translate it into English:
```
截至文章發布時,Gemma 3n 編碼器可處理長達 30 秒的音頻片段。然而,這并不是一個根本上的限制。底層的音頻編碼器是一種流式編碼器,通過額外的長篇格式音頻訓練,編碼器可以處理任意長度的音頻。后續實現將解鎖延遲更低、時間更長的流媒體應用。
MobileNet-V5:
最先進的全新視覺編碼器
除了集成的音頻功能外,Gemma 3n 還配備了全新的高效視覺編碼器 MobileNet-V5-300M,可為邊緣設備上的多模態任務提供最先進的性能。
MobileNet-V5 旨在為受限的硬件賦予靈活性和強大功能,為開發者提供:
支持多種輸入分辨率: 原生支持 256x256、512x512 和 768x768 像素的分辨率,讓您可以根據特定應用需求平衡性能和細節。
廣泛的視覺理解力: 該功能采用海量的多模態數據集協同訓練,擅長各種圖像和視頻理解任務。
高吞吐量: 在 Google Pixel 上每秒處理幀數高達 60 幀,實現設備端實時視頻分析和交互式體驗。
這種性能水平是通過多項架構創新實現的,包括:
MobileNet-V4 模塊的先進基礎 (包括通用倒置瓶頸和移動 MQA)。
顯著擴展的架構,采用混合深度金字塔模型,其規模是最大的 MobileNet-V4 變體的 10 倍。
一種新型的多尺度融合 VLM 適配器,可優化 token 質量,以提高準確性和效率。
得益于新穎的架構設計和先進的蒸餾技術,MobileNet-V5-300M 在 Gemma 3 中的性能大大優于基準 SoViT (使用 SigLip 訓練,無蒸餾)。在 Google Pixel Edge TPU 上,該編碼器在有量化情況下提速 13 倍 (無量化時為 6.5 倍),所需參數減少 46%,內存占用減少為原來的 1/4,同時在視覺-語言任務上的準確性顯著提升。
我們很期待與大家分享該模型的更多研發工作,后續即將發布的 MobileNet-V5 技術報告將深入探討模型架構、數據擴展策略和先進的蒸餾技術。
與社區共建
我們始終將 Gemma 3n 的易用性放在首位,也非常榮幸能與眾多杰出的開源開發者合作,確保模型能在多個熱門工具和平臺得到廣泛支持,其中包括來自 AMD、Axolotl、Docker、Hugging Face、llama.cpp、LMStudio、MLX、NVIDIA、Ollama、RedHat、SGLang、Unsloth 和 vLLM 等團隊的貢獻。
這個生態系統僅僅是開始,這項技術的真正價值在于用它構建的成果。正因如此,我們推出了 "Gemma 3n 挑戰賽",使用 Gemma 3n 獨特的 On-Device、離線和多模態能力,打造一款造福世界的產品。即刻參與挑戰賽,提交引人注目的視頻介紹,并通過精妙的演示展現產品的現實影響力,就有機會贏取 15 萬美元的獎金和精美禮品!歡迎加入挑戰,共創美好未來。
開始使用 Gemma 3n
準備好即刻探索 Gemma 3n 的潛力了嗎?請查收以下攻略:
直接體驗: 只需點擊幾下,即可使用 Google AI Studio 試用 Gemma 3n。Gemma 模型也可以直接從 AI Studio 部署到 Cloud Run。
下載模型: 在 Hugging Face 和 Kaggle 上查找模型權重。
學習&集成: 深入了解我們的綜合文檔,快速將 Gemma 集成到您的項目中,或從我們的推理和微調指南開始入門。
使用您青睞的設備端 AI 工具構建,包括 Google AI Edge Gallery/LiteRT-LLM、Ollama、MLX、llama.cpp、Docker 和 transformers.js 等。
使用您喜愛的開發工具: 利用您偏好的工具和框架,包括 Hugging Face Transformers 和 TRL、NVIDIA NeMo Framework、Unsloth 和 LMStudio。
隨心部署: Gemma 3n 提供多種部署選項,包括 Google GenAI API、Vertex AI、SGLang、vLLM 和 NVIDIA API Catalog。
-
計算機
+關注
關注
19文章
7806瀏覽量
93190 -
AI
+關注
關注
91文章
39755瀏覽量
301360 -
模型
+關注
關注
1文章
3751瀏覽量
52099
原文標題:深入了解 Gemma 3n: 創新的設備端 AI 模型
文章出處:【微信號:Google_Developers,微信公眾號:谷歌開發者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
谷歌推出TranslateGemma全新開放翻譯模型系列
CastFox利用Google開放模型Gemma 3n重塑播客互動體驗
解鎖谷歌FunctionGemma模型的無限潛力

谷歌正式發布Gemma Scope 2模型
谷歌正式推出Gemini 3 Flash模型
借助谷歌FunctionGemma模型構建下一代端側智能體

每年10億美元,蘋果與谷歌官宣合作,Gemini大模型注入Siri
谷歌與耶魯大學合作發布最新C2S-Scale 27B模型
NVIDIA RTX AI加速FLUX.1 Kontext現已開放下載
谷歌Gemma 3n預覽版全新發布
樹莓派5上的Gemma 2:如何打造高效的邊緣AI解決方案?

Google Gemma 3開發者指南
Google發布最新AI模型Gemma 3




 工商網監
工商網監
評論