 自動駕駛為什么需要NPU?GPU不夠嗎?
自動駕駛為什么需要NPU?GPU不夠嗎?

純GPU能做自動駕駛嗎?
[首發于智駕最前沿微信公眾號]從技術上來說,純GPU可以實現一定程度的自動駕駛,但存在明顯短板,難以滿足高級別自動駕駛的需求。
GPU能夠處理自動駕駛所需的并行計算任務(如傳感器數據融合、圖像識別等),但其設計初衷是圖形渲染,存在以下局限性:
能效比低:GPU的通用計算單元在處理AI任務時功耗較高,不適合車載電池供電場景。
實時性挑戰:自動駕駛需毫秒級響應,GPU的通用架構可能導致延遲波動不確定。
成本高:高端GPU價格昂貴,且需額外散熱設計。
早期一些自動駕駛測試車輛曾嘗試使用純GPU方案。比如某款基于英偉達GTX1080GPU的測試車,在處理單路攝像頭數據時,目標檢測延遲約80毫秒,而車輛以60公里/小時行駛時,80毫秒內會前進1.33米,這在突發狀況下會帶來安全隱患。
特斯拉早期也使用GPU(NVIDIA PX2),后轉向自研NPU(FSD芯片)以優化能效。
在數據處理能力方面,L4級自動駕駛汽車每秒產生的數據量約5-10GB,純GPU處理時,需要多顆GPU協同工作。某測試顯示,用4顆英偉達TITAN X GPU處理8路攝像頭和1路激光雷達數據,功耗達到320W,這會使電動汽車續航減少約30%。
另外,在運行復雜深度學習模型時,純GPU的效率偏低。以ResNet-152模型為例,在GPU上處理一幀4K圖像需要28毫秒,而同樣的任務在專用NPU上只需8毫秒,差距明顯。
所以,純GPU可以實現低級別自動駕駛的基本功能,但在延遲、功耗和效率上的表現,難于滿足L3及以上級別自動駕駛的要求,至少性價比不高。

GPU、NPU、TPU的根本原理對比
GPU最初是為圖形渲染設計的,其核心是由大量流處理器組成的并行計算單元。以英偉達GTX 1080為例,有2560個流處理器,這些處理器以線程塊為單位工作,支持浮點、整數等多種計算類型。
在處理圖形數據時,GPU能同時對millions個像素進行計算,完成紋理映射、光照計算等操作。在深度學習中,它可以并行處理矩陣運算,但由于架構是通用設計,在執行神經網絡計算時,有30%-40%的硬件資源處于閑置狀態。
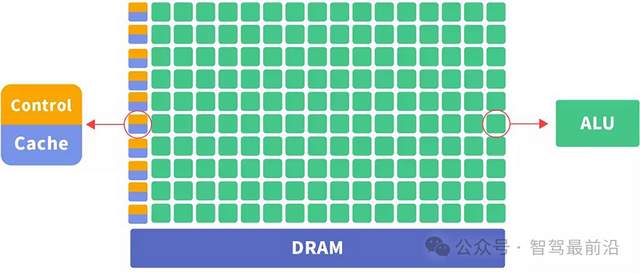
圖 GPU架構圖,來自網絡
注意到GPU的控制單元control,如果不需要控制,是不是就可以降低很多能耗和閑置算力呢?答案是的。
NPU是專門為神經網絡計算設計的芯片,內部集成了大量MAC(乘加單元)。比如華為昇騰310B,含有2048個MAC單元,這些單元以陣列形式排列,直接針對矩陣乘法和累加操作進行優化。
NPU采用數據流架構,數據在存儲單元和計算單元之間的傳輸路徑固定且簡短。在處理卷積運算時,數據從緩存進入MAC陣列后,直接完成計算并輸出結果,中間環節比GPU少60%以上。
TPU是谷歌為機器學習定制的芯片,采用脈動陣列架構。以TPU v2為例,其脈動陣列規模為512x512,數據進入陣列后,像脈搏一樣在單元間流動,每個單元完成一次乘加操作后,將結果傳遞給下一個單元。
這種架構下,數據一旦進入陣列,就會在內部持續流轉并完成計算,減少了外部存儲訪問次數。在處理大型矩陣乘法時,TPU的數據復用率比GPU高3倍以上。
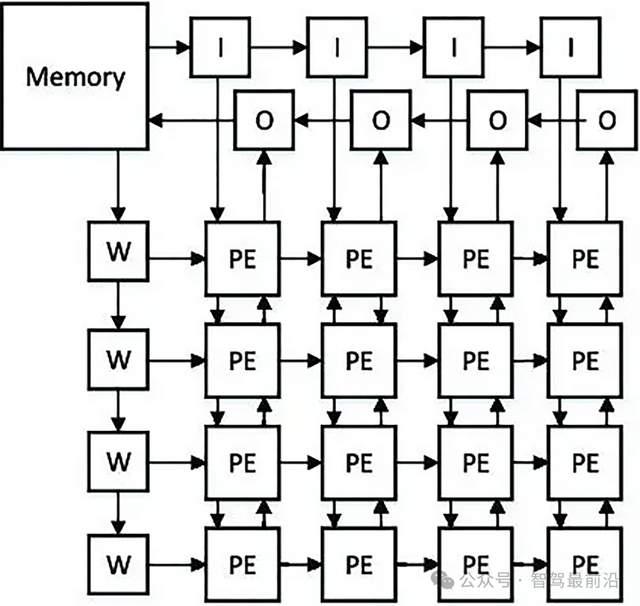
圖 NPU和TPU共有的特點,計算單元陣列,來自網絡
只不過TPU(脈動陣列就是谷歌為TPU提出來的)和部分NPU是脈動陣列,大部分NPU是MAC陣列。
脈動陣列是一種特殊的陣列結構,設計靈感源于人體血液循環系統。其核心概念是讓數據在運算單元的陣列中流動,減少訪存次數。整個陣列以“節拍”方式運行,每個處理單元(PE,Processing Element)在每個計算周期處理一部分數據,并將其傳達給下一個互連的PE。以矩陣乘法為例,在4x4的脈動網中,參與運算的矩陣元素按照特定順序在陣列單元間流動,每個單元完成一次乘加操作后,將結果傳遞給下一個單元,數據一旦進入陣列,就會在內部持續流轉并完成計算。這種結構下,數據在陣列中像脈搏跳動一樣流動,極大提升了數據復用率,減少了外部存儲訪問次數,在處理大型矩陣乘法時,其數據復用率比傳統架構高3倍以上。例如谷歌的TPU采用脈動陣列架構,像TPUv2的脈動陣列規模為512x512,在執行大型矩陣乘法等運算時,能高效利用數據,減少數據在芯片內外搬運的開銷。
MAC(乘加單元,Multiplier-Accumulator Unit)陣列則主要由大量乘加單元集成以陣列形式排列構成。乘加單元是完成一次乘法運算和一次加法運算的基本硬件單元。比如華為昇騰310B的NPU中,含有2048個MAC單元,這些單元針對神經網絡計算中的矩陣乘法和累加操作進行了專門優化。在處理卷積運算時,數據從緩存進入MAC陣列,乘加單元對輸入數據和權重數據進行乘加運算,直接完成計算并輸出結果。MAC陣列通常采用數據流驅動架構,深度優化數據在存儲單元與計算單元間的流轉路徑,通過硬件化的激活函數單元、池化單元等,直接加速神經網絡關鍵操作,減少數據搬運次數,提升計算效率,中間環節相比傳統通用架構減少60%以上。
脈動陣列和MAC陣列最主要的區別是控制時序。脈動陣列的控制時序具有嚴格的周期性,數據按固定節拍在單元間流動,每個處理單元的運算與數據傳輸精準同步,像脈搏跳動般有序;而MAC陣列的控制時序更靈活,各單元可相對獨立地響應指令,無需嚴格遵循統一的數據流節拍,更側重高效執行乘加操作。
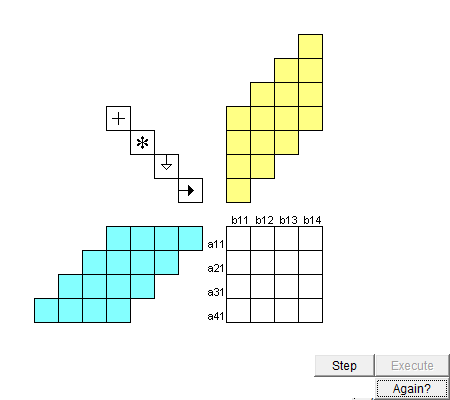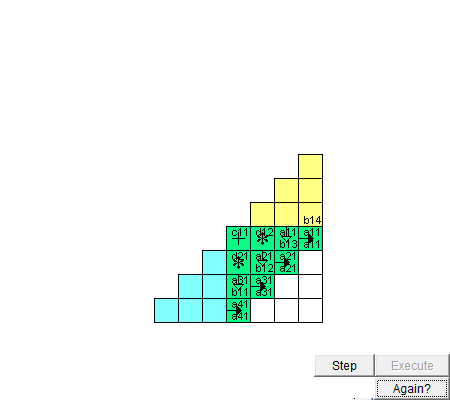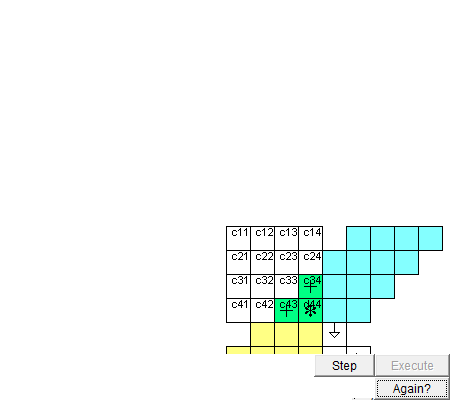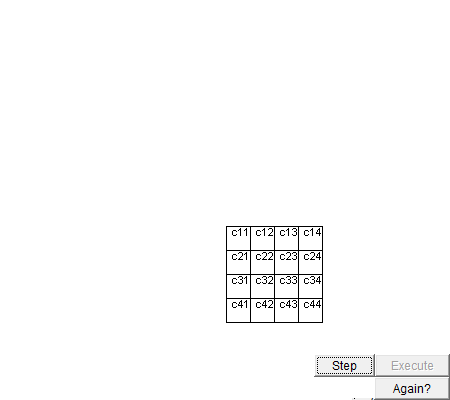
圖 脈動陣列進矩陣乘法的動圖,來自網絡
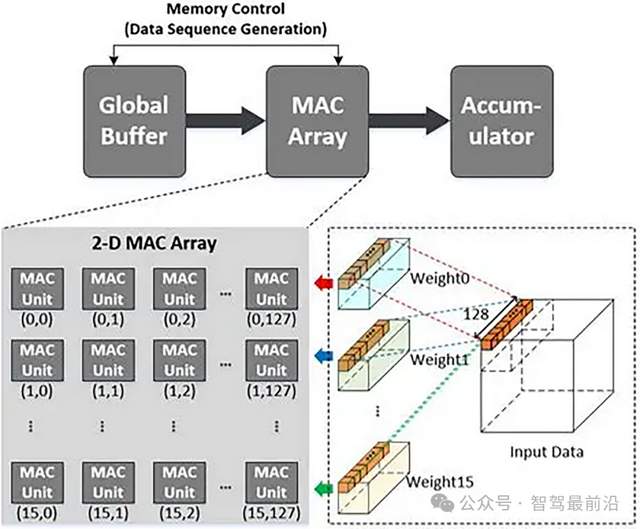
圖 MAC單元陣列,來自網絡
總結起來一句話,陣列形式的NPU和TPU,之所以在神經網絡的推理計算上,比GPU更經濟(響應時間,造價,能耗都更經濟),就是因為陣列排列的簡單計算單元,就在扮演神經網絡的神經元,而它們之間聯系的數據通路,就在扮演神經網絡的權重。就像很多文章說的,NPU和TPU內部物理結構,就是在模擬神經網絡的結構。
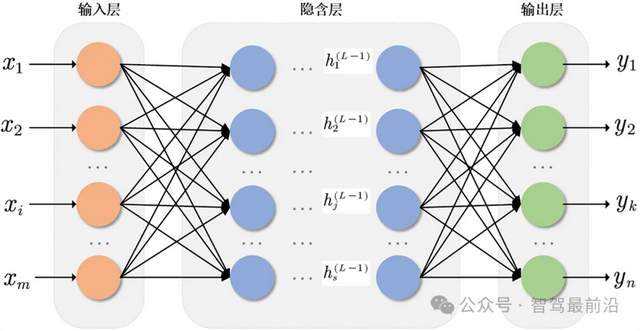
圖 神經網絡推理圖,來自網絡
相信很多讀者會問兩個問題。
第一、NPU如何處理比它的原生陣列更大的神經網絡?
從硬件架構層面來看,NPU要處理比其陣列規模大的神經網絡,確實面臨諸多挑戰,但并非完全不可行。NPU內部集成的MAC(乘加單元)陣列是其進行神經網絡計算的核心組件,像華為昇騰310B的NPU就含有2048個MAC單元。這些單元以陣列形式排列,直接針對神經網絡計算中的矩陣乘法和累加操作進行優化,在處理卷積運算等神經網絡常見操作時,數據從緩存進入MAC陣列后,能直接完成計算并輸出結果,中間環節比GPU等傳統架構減少60%以上。
然而,如果神經網絡的規模超出了MAC陣列的原生處理能力,例如在面對參數規模達到數十億甚至上百億的超大規模神經網絡時,單個NPU的MAC陣列在一個計算周期內難以完成所有數據的并行處理。因為MAC陣列的規模限制了其同時處理的數據量,就好比一條車道有限的公路,車流量過大時就會擁堵。以某款面向智能安防的NPU為例,其MAC陣列設計用于處理中等規模的圖像識別神經網絡,當嘗試運行一個專為超高清視頻分析設計的大規模神經網絡時,原本能實時處理的圖像幀率從30幀/秒驟降至5幀/秒以下,延遲大幅增加,無法滿足實際應用的實時性需求。
辦法就是分幀,把大網絡切成NPU一次能處理的小塊,但是會有性能問題。
第二、要處理比它的原生陣列小,但形狀不一致的神經網絡怎么辦?畢竟神經網絡每一層的神經元數量都可以不一樣。
答案是填充padding,空著的神經元和權重填充0(或者特殊的信號表示忽略)。目的是在乘加運算時不發生作用,因為乘0還是0,加0還是0,且沒有別的計算。
TPU是類似的。
三者的對比表如下:
| 特性 | GPU | NPU | TPU |
| 設計目標 | 圖形渲染/通用并行計算 | 神經網絡推理與訓練加速 | 張量運算(Google專用) |
| 核心架構 | 數千個SIMD核心(通用計算單元) | 專用矩陣運算單元(如MAC陣列) | 脈動陣列(數據流優化) |
| 優勢 | 靈活性強,適合多樣化任務 | 能效比高,低延遲推理 | 云端大規模訓練性能優異 |
| 典型應用 | 游戲、科學計算、AI訓練 | 自動駕駛、邊緣AI、手機端側推理 | Google Cloud AI服務 |
| 代表產品 | NVIDIA A100、AMD Radeon Instinct | 特斯拉FSD、華為昇騰 | Google TPU v4 |
原理差異:
lGPU:通過大規模并行線程處理浮點運算,但需軟件層優化AI任務。
lNPU:硬件級支持矩陣乘加(MAC)操作,直接映射神經網絡計算圖。
lTPU:采用脈動陣列減少數據搬運開銷,專為TensorFlow優化。
三者相比,GPU通用性強但針對性不足,NPU專注于神經網絡計算效率,TPU在特定機器學習任務(針對tensorflow優化)上有更高的計算密度。
如果進一步講,GPU更適合訓練,因為模型訓練時需要反向傳播算法,計算需要從兩個方向進行,變換計算方向是需要額外控制器的。但NPU(TPU)更適合對訓練好的模型進行推理,推理只需要悶著頭朝一個方向走就行了。
為什么thor要保留GPU,又有NPU
英偉達Thor是一款面向自動駕駛的計算芯片,其包含多種PU,是超異構融合芯片的典型。
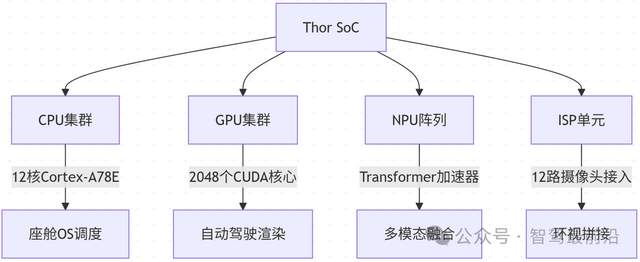
圖 雷神索爾Thor芯片的框架和功能,其中ISP不是網絡服務商,而是ImageSignalProcessor,圖像信號處理器
它保留GPU同時配備NPU,主要有以下幾方面原因。
從功能分工來看,自動駕駛系統中有不同類型的計算任務。NPU適合處理神經網絡相關任務,比如用YOLOv8模型檢測行人,Thor的NPU處理單幀圖像耗時約5毫秒;而GPU則負責傳感器數據預處理,比如將激光雷達的點云數據從極坐標轉換為笛卡爾坐標,Thor的GPU處理100萬個點云數據耗時約3毫秒。
在數據交互上,兩者需要協同工作。攝像頭采集的原始圖像先由GPU進行畸變校正,校正后的圖像再傳給NPU進行目標識別。測試顯示,這種協同模式比單一處理器處理的效率提升40%,因為避免了數據在不同芯片間的頻繁傳輸。
另外,考慮到軟件兼容性,目前有大量傳統算法基于GPU開發,比如SLAM(同步定位與地圖構建)中的部分模塊。保留GPU可以直接運行這些算法,無需重新開發,節省了至少18個月的適配時間。
從成本角度,Thor的GPU和NPU集成在同一芯片上,相比分開設計,硬件成本降低25%,同時減少了50%的電路板空間占用。
GPU、NPU在能耗和造價的對比
在相同AI算力下,NPU的能耗明顯低于GPU。
英偉達Jetson AGX Xavier(GPU方案)的AI算力為32TOPS,功耗30W,能效比1.07TOPS/W。華為昇騰310B(NPU方案)算力22TOPS,功耗8W,能效比2.75TOPS/W,是前者的2.5倍。
特斯拉FSD芯片中的NPU部分,算力144TOPS,功耗25W,能效比5.76TOPS/W。而要達到相近的AI算力,需要4顆Jetson AGX Xavier,總功耗120W,是特斯拉NPU的4.8倍。
在實際車載場景中,某L4級自動駕駛測試車采用純GPU方案(總功耗150W),相比采用NPU+GPU混合方案(總功耗60W),每100公里多消耗8度電,按電動車百公里平均15度電計算,續航減少約53公里。
單顆芯片成本方面,英偉達Jetson AGX Xavier的批量采購價約800美元/顆,華為昇騰310B約300美元/顆。
若要實現144TOPS的AI算力,純GPU方案需要5顆Jetson AGX Xavier,總成本4000美元;而采用特斯拉FSD芯片(含NPU),單顆成本約500美元,成本僅為純GPU方案的12.5%。
加上周邊電路和散熱系統,純GPU方案的硬件總成本約5500美元,NPU+GPU混合方案約1200美元,前者是后者的4.6倍。
從量產角度看,當產量達到10萬臺時,NPU的單位研發成本可分攤至每臺30美元,而GPU由于架構復雜,分攤后仍需80美元/臺。
| 指標 | GPU | NPU |
| 功耗 | 高(50-300W) | 極低(1-10W) |
| 單位TOPS功耗 | 1-5W/TOPS | 0.1-0.5W/TOPS |
| 造價 | 高(高端芯片超萬元) | 中低(規模化后成本下降快) |
| 適用場景 | 訓練/云端推理 | 端側推理/車載實時處理 |
數據來源:NPU的能效比可達GPU的10倍以上,且制程要求更低(如14nmNPU媲美7nmGPU)
總結
純GPU可以實現低級別自動駕駛,但在處理速度、能耗等方面存在明顯不足,無法滿足高級別自動駕駛的需求。
從原理上看,GPU通用但效率低,NPU專為神經網絡設計,TPU在特定場景計算密度高,三者架構差異導致適用場景不同。
英偉達Thor同時保留GPU和NPU,是因為兩者能分工協作,提高整體效率,還能兼容現有軟件,降低成本。
能耗和造價數據顯示,NPU的能效比是GPU的2.5-5倍以上,相同算力下,NPU方案的硬件成本僅為純GPU方案的12.5%-40%。
綜合來看,自動駕駛需要NPU,因為它能在低功耗下高效處理神經網絡任務,而GPU雖然在部分通用計算上有作用,但單獨使用無法滿足高級別自動駕駛的要求。未來,NPU+GPU的混合方案會成為主流,既保證處理效率,又兼顧兼容性和成本。
審核編輯 黃宇
-
gpu
+關注
關注
28文章
5194瀏覽量
135503 -
自動駕駛
+關注
關注
793文章
14887瀏覽量
179957 -
NPU
+關注
關注
2文章
374瀏覽量
21106
發布評論請先 登錄
自動駕駛汽車如何完成超車?
自動駕駛汽車如何實現自動駕駛
如何設計好自動駕駛ODD?
怎么知道自動駕駛仿真做得夠不夠?

不同等級的自動駕駛技術要求上有何不同?
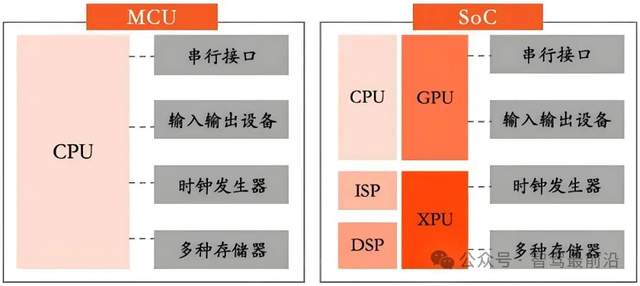
自動駕駛SoC芯片到底有何優勢?
塑造自動駕駛汽車格局的核心技術
自動駕駛汽車是如何準確定位的?
卡車、礦車的自動駕駛和乘用車的自動駕駛在技術要求上有何不同?
Vicor高效電源模塊優化自動駕駛系統
自動駕駛安全基石:ODD
新能源車軟件單元測試深度解析:自動駕駛系統視角





 工商網監
工商網監
評論