 離散化架構WAGE,訓練推理合二為一
離散化架構WAGE,訓練推理合二為一

圖 1 吳雙(左側)和李國齊(右側)- 被錄用文章的兩位作者
清華大學類腦計算研究中心博士生吳雙的論文被 ICLR2018 收錄并在會上做口頭報告。迄今為止,這是中國作為第一署名單位里唯一一篇被 ICLR 會議收錄的口頭報告文章。該報告主要探討如何實現對全離散化深度神經網絡進行訓練和推理,便于部署到嵌入式設備中。
ICLR 是深度學習領域的頂會,更被譽為深度學習的“無冕之王”,得到了 google, Facebook, DeepMind, Amazon,IBM 等眾多高科技公司的高度關注和參與。ICLR2018 于當地時間 2018 年 4 月 30 日在加拿大溫哥華會展中心召開,為期 4 天。本次大會的主席是深度學習領域三巨頭中的 Yoshua Bengio(蒙特利爾大學)和 Yann LeCun (紐約大學 & Facebook),本次大會收到一千多篇投稿文章,其中僅有 23 篇被收錄為本次會議的口頭報告文章。
吳雙同學的報告題目為 “Training and Inference with Integers in Deep Neural Networks”。

離散化架構 WAGE,訓練推理合二為一
該報告主要探討如何實現對全離散化深度神經網絡進行訓練和推理,便于部署到嵌入式設備中。
在深度學習領域,高精度意味著大面積、高功耗,從而導致高成本,這背離了嵌入式設備的需求,因此硬件加速器和神經形態芯片往往采用低精度的硬件實現方式。在低精度的算法研究方面,之前的工作主要集中在對前向推理網絡的權重值和激活值的縮減,使之可以部署在硬件加速器和神經形態芯片上;而網絡的訓練還是借助于高精度浮點實現(GPU)。這種訓練和推理的分離模式往往導致需要耗費大量的額外精力,對訓練好的浮點網絡進行低精度轉換,這不僅嚴重影響了神經網絡的應用部署,更限制了在應用端的在線改善。
為應對這種情況,本文提出了一種聯合的離散化架構 WAGE,首次實現了將離散化神經網絡的反向訓練過程和前向推理合二為一。具體來說就是將網絡權重、激活值、反向誤差、權重梯度用全用低精度整形數表達,在網絡訓練時去掉難以量化的操作及操作數(比如批歸一化等),從而實現整個訓練流程全部用整數完成。
在數據集實測中,WAGE 的離散化方法能夠有效的提高測試精度。由于該方法能夠同時滿足深度學習加速器和神經形態芯片的低功耗和反向訓練需求,更使之具備高效地在線學習的能力,對未來多場景、多目標的可遷移、可持續學習的人工智能應用將大有裨益。
WAGE框架將訓練和推理中的所有層中的權重( weights ,W),激活值( activations ,A),梯度( gradients ,G)和誤差( errors ,E)限制為低位整數。首先,對于操作數,應用線性映射和方向保持移位來實現三元權重,用于激活和梯度累加的8位整數。其次,對于操作,批歸一化由一個常數因子取代。用于微調的其他技術(如具有動量和L2正則化的SGD優化器)可以簡化或放棄,性能的下降很小。考慮到整體雙向傳播,我們完全簡化了累積比較周期的推理,并分別訓練到具有對齊操作的低位乘法累加(MAC)周期。
所提出的框架在MNIST,CIFAR10,SVHN,ImageNet數據集上進行評估。相對于只在推理時離散權重和激活的框架,WAGE具有可比的準確性,并且可以進一步減輕過擬合。WAGE為DNN生成純粹的雙向低精度整數數據流,可以將其用于專門硬件的訓練和推理。我們在GitHub上發布了代碼。
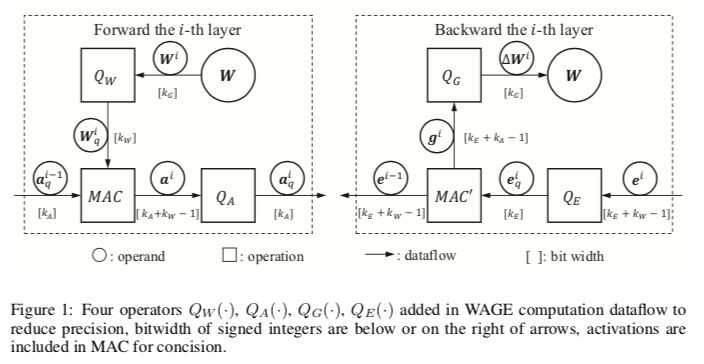
圖1
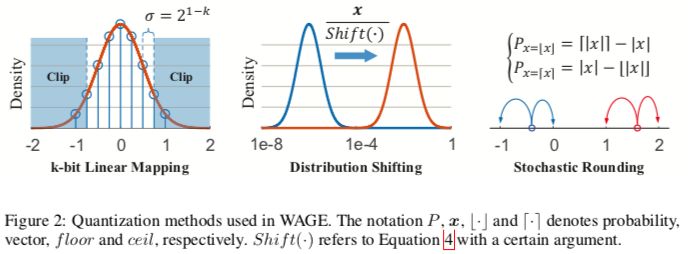
圖2:WAGE的量化方法
實現細節
MNIST:采用LeNet-5的一個變體。WAGE中的學習率η在整個100個epochs中保持為1。我們報告了測試集上10次運行的平均準確度。
SVHN&CIFAR10:錯誤率的評估方式與MNIST相同。
ImageNet:使用AlexNe模型在ILSVRC12數據集上評估WAGE框架。
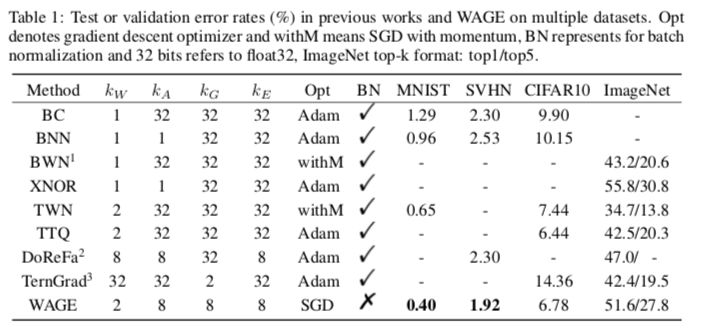
表1:WAGE及其他方法在多個數據集上的測試或驗證錯誤率(%)

圖3:訓練曲線
結論和未來工作
這項工作的目標是展示在DNN中應用低位整數訓練和推理的潛力。與FP16相比,8-bit整數運算不僅會降低IC設計的能耗和面積成本(約5倍,見Table 5),還會減少訓練期間內存訪問成本和內存大小要求,這將大大有利于具有現場學習能力的的移動設備。這個工作中有一些沒有涉及到的點,未來的算法開發和硬件部署還有待改進或解決。
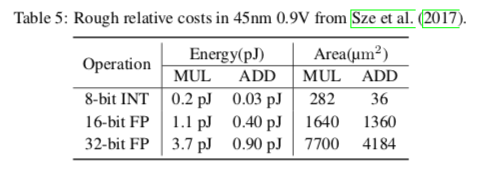
表5
WAGE使DNN的純低位整數數據流進行訓練和推理得以實現。我們引入一種新的初始化方法和分層常數比例因子來取代批歸一化,這是網絡量化的一個難點。此外,還探討了誤差計算和梯度累積的位寬要求。實驗表明,我們可以量化梯度的相對值,并且在反向傳播中丟棄大多數小值及其數量級。雖然為了穩定收斂和最終的精度,權重更新的積累是必不可少的,但仍然可以在訓練中進一步減少壓縮和內存消耗。WAGE在多個數據集實現了最高精度。通過微調、更有效的映射、批歸一化等量化方法,對增量工作有一定的應用前景。總而言之,我們提出了一個沒有浮點表示的框架,并展示了在基于整數的輕量級ASIC或具有現場學習能力的FPGA上實現離散訓練和推理的潛力。
-
神經網絡
+關注
關注
42文章
4838瀏覽量
107753 -
gpu
+關注
關注
28文章
5194瀏覽量
135431
原文標題:ICLR oral:清華提出離散化架構WAGE,神經網絡訓練推理合二為一
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄



 工商網監
工商網監
評論