") 緩存之美:Guava Cache 相比于 Caffeine 差在哪里?
緩存之美:Guava Cache 相比于 Caffeine 差在哪里?

本文將結(jié)合 Guava Cache 的源碼來(lái)分析它的實(shí)現(xiàn)原理,并闡述它相比于 Caffeine Cache 在性能上的劣勢(shì)。為了讓大家對(duì) Guava Cache 理解起來(lái)更容易,我們還是在開篇介紹它的原理:
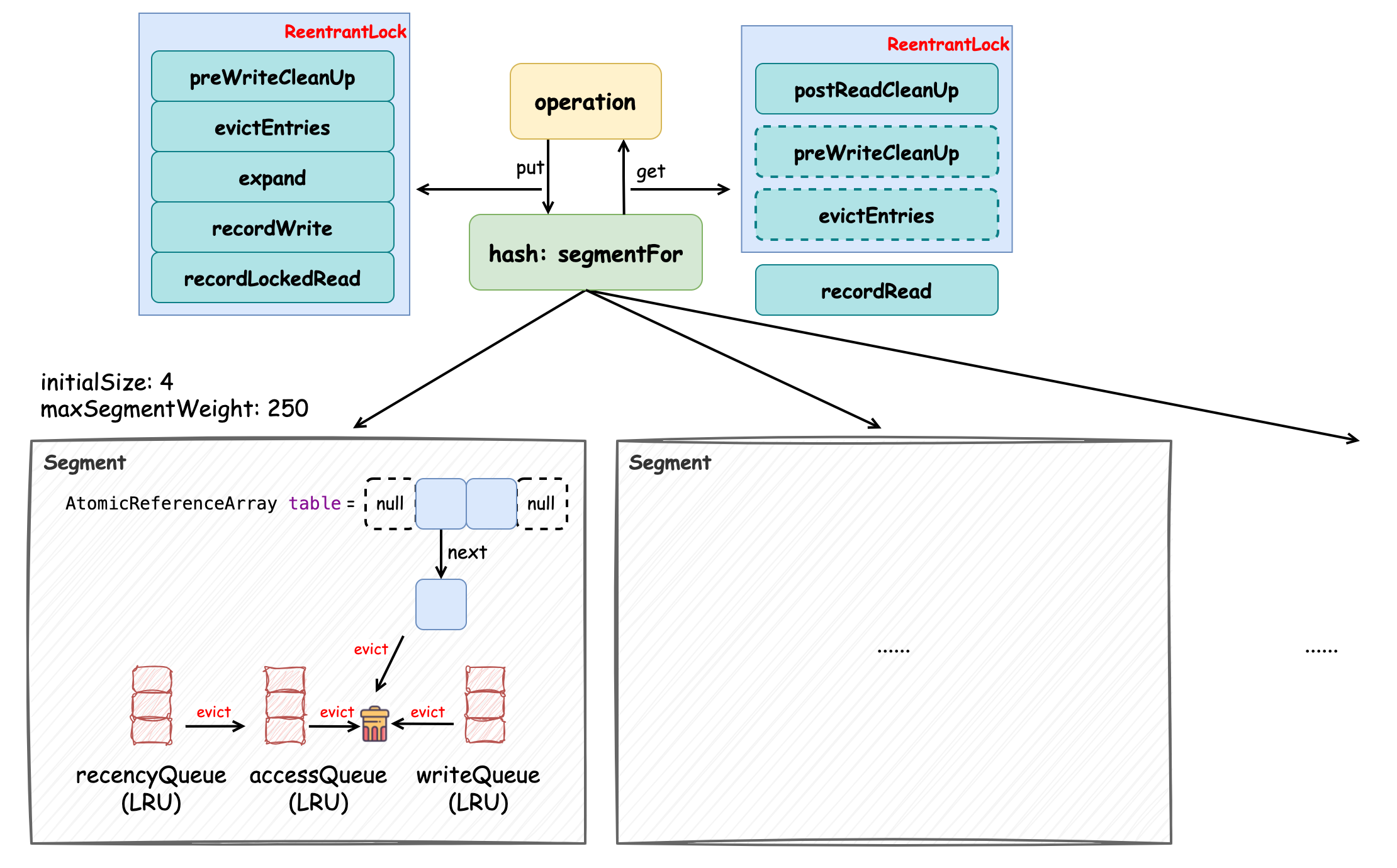
Guava Cache 通過(guò)分段(Segment)鎖(ReentrantLock)機(jī)制、volatile 變量和多種緩存策略實(shí)現(xiàn)了性能相對(duì) Caffeine 性能較差的緩存,它的數(shù)據(jù)結(jié)構(gòu)如上圖所示。它會(huì)將緩存分成多個(gè)段(Segment)去管理,單個(gè)段內(nèi)寫操作加鎖互斥,如果要?jiǎng)?chuàng)建大小為 1000 的緩存,那么實(shí)際上會(huì)分配 4 個(gè)段,每個(gè)段的最大容量為 250。讀寫操作在執(zhí)行時(shí)都會(huì)經(jīng) segmentFor 方法“路由”到某一個(gè)段。數(shù)據(jù)結(jié)構(gòu)的實(shí)現(xiàn)都在 Segment 中,它對(duì)元素的管理采用的是 AtomicReferenceArray 數(shù)組,在初始化時(shí)是較小的容量,并隨著元素的增多觸發(fā)擴(kuò)容機(jī)制。我們稱數(shù)組中每個(gè)索引的位置為“桶”,每個(gè)桶中保存了元素的引用,這些元素是通過(guò)單向鏈表維護(hù)的,每當(dāng)有新元素添加時(shí),采用的是“頭插法”。此外,在 Segment 中還維護(hù)了三個(gè)基于 LRU 算法 的隊(duì)列,處于尾部的元素最“新”,分別是 accessQueue、writeQueue 和 recencyQueue,它們分別用于記錄被訪問(wèn)的元素、被寫入的元素和“最近”被訪問(wèn)的元素。accessQueue 的主要作用是在對(duì)超過(guò)最大容量(超過(guò)訪問(wèn)后過(guò)期時(shí)間)的元素進(jìn)行驅(qū)逐時(shí),優(yōu)先將最近被訪問(wèn)的越少的元素驅(qū)逐(頭節(jié)點(diǎn)開始遍歷);writeQueue 的主要作用是對(duì)寫后過(guò)期的元素進(jìn)行驅(qū)逐時(shí),優(yōu)先將最近最少被訪問(wèn)的元素驅(qū)逐,因?yàn)樵皆绫惶砑拥脑卦皆邕^(guò)期,當(dāng)發(fā)現(xiàn)某元素未過(guò)期時(shí),后續(xù)隊(duì)列中的元素是不需要判斷的;recencyQueue 的作用是記錄被訪問(wèn)過(guò)的元素,它們最終都會(huì)被移動(dòng)到 accessQueue 中,并根據(jù)訪問(wèn)順序添加到其尾節(jié)點(diǎn)中。
對(duì)元素生命周期的管理主要是在 put 方法中完成的,put 相關(guān)的操作都需要加鎖,如圖中左上方所示,這些方法均與緩存元素的管理相關(guān)。Guava Cache 為了在不觸發(fā)寫操作而有大量讀操作時(shí)也能正常觸發(fā)對(duì)緩存元素的管理,添加了一個(gè) readCount 變量,每次讀請(qǐng)求都會(huì)使其累加,直到該變量超過(guò)規(guī)定閾值,也會(huì)觸發(fā)緩存元素的驅(qū)逐(postReadCleanUp),保證數(shù)據(jù)的一致性,如圖中右上方所示。
接下來(lái)我們通過(guò)創(chuàng)建最大大小為 1000,并配置有訪問(wèn)后和寫后過(guò)期時(shí)間的 LoadingCache 來(lái)分析 Guava Cache 的實(shí)現(xiàn)原理,主要關(guān)注它的構(gòu)造方法,put 方法和 get 方法:
public class TestGuavaCache {
@Test
public void test() {
LoadingCache cache = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.SECONDS)
.expireAfterAccess(10, TimeUnit.SECONDS)
.build(
new CacheLoader() {
@Override
public String load(String key) {
return String.valueOf(key.hashCode());
}
}
);
cache.put("key1", "value1");
try {
System.out.println(cache.get("key"));
} catch (ExecutionException e) {
throw new RuntimeException(e);
}
}
}
constructor
首先我們來(lái)看一下它的構(gòu)造方法,它會(huì)將創(chuàng)建緩存時(shí)指定的參數(shù)記錄下來(lái),比如訪問(wèn)后過(guò)期時(shí)間(expireAfterAccessNanos),寫后過(guò)期時(shí)間(expireAfterWriteNanos)等等,除此之外還包括 Segment 分段對(duì)象的創(chuàng)建,定義分段的數(shù)量和每個(gè)分段的大小,并將這些 Segment 對(duì)象保存在一個(gè)數(shù)組中,以創(chuàng)建最大元素?cái)?shù)量為 1000 的緩存為例,它會(huì)創(chuàng)建 4 個(gè)分段,每個(gè)分段分配 250 個(gè)元素。源碼如下所示,均為賦值操作,可關(guān)注 Segment 相關(guān)邏輯:
class LocalCache extends AbstractMap implements ConcurrentMap {
static final int MAX_SEGMENTS = 1 keyEquivalence;
final Equivalence valueEquivalence;
final long maxWeight;
final Weigher weigher;
final long expireAfterAccessNanos;
final long expireAfterWriteNanos;
final long refreshNanos;
final RemovalListener removalListener;
final Queue> removalNotificationQueue;
final Ticker ticker;
final EntryFactory entryFactory;
final StatsCounter globalStatsCounter;
@CheckForNull final CacheLoader defaultLoader;
final int segmentMask;
final int segmentShift;
final Segment[] segments;
LocalCache(CacheBuilder builder, @CheckForNull CacheLoader loader) {
// 并發(fā)級(jí)別,不指定默認(rèn)為 4
concurrencyLevel = min(builder.getConcurrencyLevel(), MAX_SEGMENTS);
// key 和 value 的引用強(qiáng)度,默認(rèn)為強(qiáng)引用
keyStrength = builder.getKeyStrength();
valueStrength = builder.getValueStrength();
// 鍵值比較器,默認(rèn)為強(qiáng)引用比較器
keyEquivalence = builder.getKeyEquivalence();
valueEquivalence = builder.getValueEquivalence();
// maxWeight 最大權(quán)重,指定了為 1000
maxWeight = builder.getMaximumWeight();
// weigher 沒(méi)有指定,默認(rèn)為 1,表示每個(gè)元素的權(quán)重為 1
weigher = builder.getWeigher();
// 訪問(wèn)后和寫后過(guò)期時(shí)間,默認(rèn)為 0,表示不設(shè)置過(guò)期時(shí)間
expireAfterAccessNanos = builder.getExpireAfterAccessNanos();
expireAfterWriteNanos = builder.getExpireAfterWriteNanos();
// 刷新時(shí)間,默認(rèn)為 0,表示不刷新
refreshNanos = builder.getRefreshNanos();
// 元素驅(qū)逐監(jiān)聽器
removalListener = builder.getRemovalListener();
removalNotificationQueue =
(removalListener == NullListener.INSTANCE) ? LocalCache.discardingQueue() : new ConcurrentLinkedQueue();
// 定義 Ticker 可以模擬時(shí)間流動(dòng)來(lái)驗(yàn)證邏輯
ticker = builder.getTicker(recordsTime());
entryFactory = EntryFactory.getFactory(keyStrength, usesAccessEntries(), usesWriteEntries());
globalStatsCounter = builder.getStatsCounterSupplier().get();
defaultLoader = loader;
// 初始化大小,默認(rèn)為 16
int initialCapacity = min(builder.getInitialCapacity(), MAXIMUM_CAPACITY);
if (evictsBySize() && !customWeigher()) {
initialCapacity = (int) min(initialCapacity, maxWeight);
}
// 基于大小的驅(qū)逐策略是針對(duì)每個(gè)段而不是全局進(jìn)行驅(qū)逐的,因此段數(shù)過(guò)多會(huì)導(dǎo)致隨機(jī)的驅(qū)逐行為
// 計(jì)算分段數(shù)量和分段位移(shift)的邏輯
int segmentShift = 0;
int segmentCount = 1;
// 保證分段數(shù)量不低于并發(fā)級(jí)別 且 段數(shù)*20不超過(guò)最大權(quán)重,保證每個(gè)段的元素?cái)?shù)量至少為 10
while (segmentCount < concurrencyLevel && (!evictsBySize() || segmentCount * 20L <= maxWeight)) {
// 分段位移+1
++segmentShift;
// 分段數(shù)量為 2的n次冪
segmentCount [] newSegmentArray(int ssize) {
return (Segment[]) new Segment[ssize];
}
}
我們接著看下創(chuàng)建 Segment 的方法 LocalCache#createSegment,它直接調(diào)用了 Segment 的構(gòu)造方法:
class LocalCache extends AbstractMap implements ConcurrentMap {
// ...
Segment createSegment(int initialCapacity, long maxSegmentWeight, StatsCounter statsCounter) {
return new Segment(this, initialCapacity, maxSegmentWeight, statsCounter);
}
}
Segment 是 LocalCache 內(nèi)的靜態(tài)內(nèi)部類,它在緩存中起到了將數(shù)據(jù)分段管理的作用。它繼承了 ReentrantLock,主要為了簡(jiǎn)化鎖定的操作:
static class Segment extends ReentrantLock {
// ...
}
在該類中有一段 JavaDoc 值得讀一下:
Segments 內(nèi)部維護(hù)了緩存本身(final LocalCache map),所以它能一直保持?jǐn)?shù)據(jù)一致性,也因此可以在不加鎖的情況下進(jìn)行讀操作。被緩存的鍵值對(duì)對(duì)象(構(gòu)成單向鏈表)中的 next 字段被 final 修飾,所有的添加操作都只能在每個(gè)桶的前面進(jìn)行(頭插法),這也就使得檢查變更比較容易,并且遍歷速度也比較快。當(dāng)節(jié)點(diǎn)需要更改時(shí),會(huì)創(chuàng)建新節(jié)點(diǎn)來(lái)替換它們(深拷貝)。這對(duì)于哈希表來(lái)說(shuō)效果很好,因?yàn)橥傲斜硗芏蹋ㄆ骄L(zhǎng)度小于二)。
讀操作可以在不加鎖的情況下進(jìn)行,但依賴于被 volatile 關(guān)鍵字修飾的變量,因?yàn)檫@個(gè)關(guān)鍵字能確保“可見性”。對(duì)大多數(shù)操作來(lái)說(shuō),可以將記錄元素?cái)?shù)量的字段 count 來(lái)作為確保可見性的變量。它帶來(lái)了很多便利,在很多讀操作中都需要參考這個(gè)字段:
未加鎖的讀操作必須首先讀取 count 字段,如果它是 0,則不應(yīng)讀任何元素
加鎖的寫操作在任何桶發(fā)生結(jié)構(gòu)性更改后都需要修改 count 字段值,這些寫操作不能在任何情況下導(dǎo)致并發(fā)讀操作發(fā)生讀取數(shù)據(jù)不一致的情況,這樣的保證使得 Map 中的讀操作更容易。比如,沒(méi)有操作可以揭示 Map 中添加了新的元素但是 count 字段沒(méi)有被更新的情況,因此相對(duì)于讀取沒(méi)有原子性要求。
作為提示,所有被 volatile 修飾的字段都很關(guān)鍵,它們的讀取和寫入都會(huì)用注釋標(biāo)記。
* Segments maintain a table of entry lists that are ALWAYS kept in a consistent state, so can * be read without locking. Next fields of nodes are immutable (final). All list additions are * performed at the front of each bin. This makes it easy to check changes, and also fast to * traverse. When nodes would otherwise be changed, new nodes are created to replace them. This * works well for hash tables since the bin lists tend to be short. (The average length is less * than two.) * * Read operations can thus proceed without locking, but rely on selected uses of volatiles to * ensure that completed write operations performed by other threads are noticed. For most * purposes, the "count" field, tracking the number of elements, serves as that volatile * variable ensuring visibility. This is convenient because this field needs to be read in many * read operations anyway: * * - All (unsynchronized) read operations must first read the "count" field, and should not look * at table entries if it is 0. * * - All (synchronized) write operations should write to the "count" field after structurally * changing any bin. The operations must not take any action that could even momentarily cause a * concurrent read operation to see inconsistent data. This is made easier by the nature of the * read operations in Map. For example, no operation can reveal that the table has grown but the * threshold has not yet been updated, so there are no atomicity requirements for this with * respect to reads. * * As a guide, all critical volatile reads and writes to the count field are marked in code * comments.
通過(guò)它的 JavaDoc 我們可以了解到它通過(guò)寫操作對(duì)數(shù)據(jù)一致性的保證和被 volatile 修飾的字段來(lái)實(shí)現(xiàn)無(wú)鎖的讀操作,不過(guò)其中鍵值對(duì)中被 final 修飾的 next 字段究竟是怎么回事就需要在后文中去探究了。下面我們根據(jù)它的構(gòu)造方法看一下該類中比較重要的字段信息:
static class Segment extends ReentrantLock {
// 在某一段(Segment)中元素的數(shù)量
volatile int count;
// 總的權(quán)重值
@GuardedBy("this")
long totalWeight;
// 修改次數(shù)
int modCount;
// 繼上一次寫操作后讀操作的數(shù)量
final AtomicInteger readCount = new AtomicInteger();
@Weak final LocalCache map;
final long maxSegmentWeight;
final StatsCounter statsCounter;
int threshold;
@CheckForNull volatile AtomicReferenceArray> table;
final Queue> recencyQueue;
@GuardedBy("this")
final Queue> writeQueue;
@GuardedBy("this")
final Queue> accessQueue;
Segment(LocalCache map, int initialCapacity, long maxSegmentWeight, StatsCounter statsCounter) {
// LocalCache 對(duì)象的引用
this.map = map;
// 最大分段權(quán)重,我們的例子中它的值是 250
this.maxSegmentWeight = maxSegmentWeight;
this.statsCounter = checkNotNull(statsCounter);
// 根據(jù)初始化容量創(chuàng)建支持原子操作的 AtomicReferenceArray 對(duì)象
initTable(newEntryArray(initialCapacity));
// 管理弱引用和虛引用的 Key,Value 隊(duì)列
keyReferenceQueue = map.usesKeyReferences() ? new ReferenceQueue() : null;
valueReferenceQueue = map.usesValueReferences() ? new ReferenceQueue() : null;
// 用于記錄“最近”元素被訪問(wèn)的順序
recencyQueue = map.usesAccessQueue() ? new ConcurrentLinkedQueue() : LocalCache.discardingQueue();
// 用于記錄元素的寫入順序,元素被寫入時(shí)會(huì)被添加到尾部
writeQueue = map.usesWriteQueue() ? new WriteQueue() : LocalCache.discardingQueue();
// 記錄元素的訪問(wèn)順序,元素被訪問(wèn)后會(huì)被添加到尾部
accessQueue = map.usesAccessQueue() ? new AccessQueue() : LocalCache.discardingQueue();
}
AtomicReferenceArray> newEntryArray(int size) {
return new AtomicReferenceArray(size);
}
void initTable(AtomicReferenceArray> newTable) {
// 默認(rèn)負(fù)載因子為 0.75
this.threshold = newTable.length() * 3 / 4;
if (!map.customWeigher() && this.threshold == maxSegmentWeight) {
// 在執(zhí)行驅(qū)逐操作前防止不必要的擴(kuò)張操作,將閾值+1
this.threshold++;
}
this.table = newTable;
}
// ...
}
根據(jù)上述代碼和注釋信息,每個(gè) Segment 的數(shù)據(jù)結(jié)構(gòu)由 AtomicReferenceArray(本質(zhì)上是 Object[] 數(shù)組)和三個(gè)基于LRU算法的隊(duì)列組成,AtomicReferenceArray 初始化時(shí)為一個(gè)較小容量(4)的數(shù)組,在緩存的操作過(guò)程中會(huì)根據(jù)元素添加的情況觸發(fā)擴(kuò)容,在這里我們已經(jīng)能看到 Guava Cache 數(shù)據(jù)結(jié)構(gòu)的全貌了,如下所示:
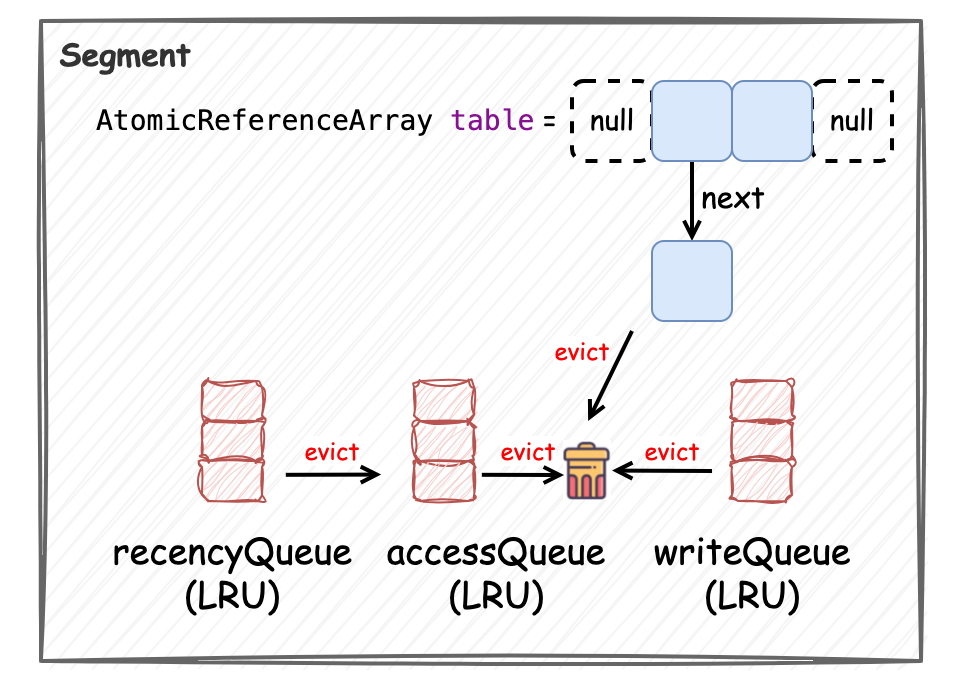
在接下來(lái)的兩個(gè)小節(jié)中,我們將深入討論 put 和 get 方法的實(shí)現(xiàn),分析這些數(shù)據(jù)結(jié)構(gòu)是如何為這些操作提供支持的。
put
在深入 put 方法前,我們需要先了解下創(chuàng)建鍵值對(duì)元素的邏輯。在調(diào)用 LocalCache 的構(gòu)造方法時(shí),其中 entryFactory 字段我們沒(méi)具體講解,在這里詳細(xì)描述下,因?yàn)樗c鍵值對(duì)元素的創(chuàng)建有關(guān)。EntryFactory 是一個(gè)枚舉類,它其中定義了如 STRONG_ACCESS_WRITE 和 WEAK_ACCESS_WRITE 等一系列枚舉,并根據(jù)創(chuàng)建緩存時(shí)指定的 Key 引用類型和元素管理策略來(lái)決定具體是哪個(gè)枚舉,如其中的 EntryFactory#getFactory 方法所示:
enum EntryFactory {
STRONG {
// ...
},
STRONG_ACCESS {
// ...
},
STRONG_WRITE {
// ...
},
STRONG_ACCESS_WRITE {
// ...
},
// ...
WEAK_ACCESS_WRITE {
// ...
};
static final int ACCESS_MASK = 1;
static final int WRITE_MASK = 2;
static final int WEAK_MASK = 4;
static final EntryFactory[] factories = {
STRONG,
STRONG_ACCESS,
STRONG_WRITE,
STRONG_ACCESS_WRITE,
WEAK,
WEAK_ACCESS,
WEAK_WRITE,
WEAK_ACCESS_WRITE,
};
static EntryFactory getFactory(Strength keyStrength, boolean usesAccessQueue, boolean usesWriteQueue) {
int flags = ((keyStrength == Strength.WEAK) ? WEAK_MASK : 0)
| (usesAccessQueue ? ACCESS_MASK : 0)
| (usesWriteQueue ? WRITE_MASK : 0);
return factories[flags];
}
}
當(dāng)不指定 Key 的引用類型時(shí)為強(qiáng)引用,結(jié)合指定的訪問(wèn)后和寫后過(guò)期策略,會(huì)匹配到 STRONG_ACCESS_WRITE 枚舉,根據(jù)它的命名也能理解它表示 Key 為強(qiáng)引用且配置了訪問(wèn)后和寫后過(guò)期策略。下面主要關(guān)注下它的邏輯:
enum EntryFactory {
STRONG_ACCESS_WRITE {
@Override
ReferenceEntry newEntry(
Segment segment, K key, int hash, @CheckForNull ReferenceEntry next) {
return new StrongAccessWriteEntry(key, hash, next);
}
// ...
}
}
其中 EntryFactory#newEntry 為創(chuàng)建鍵值對(duì)元素的方法,創(chuàng)建的鍵值對(duì)類型為 StrongAccessWriteEntry,我們看下它的具體實(shí)現(xiàn):
class LocalCache extends AbstractMap implements ConcurrentMap {
static class StrongEntry extends AbstractReferenceEntry {
final K key;
final int hash;
@CheckForNull final ReferenceEntry next;
volatile ValueReference valueReference = unset();
StrongEntry(K key, int hash, @CheckForNull ReferenceEntry next) {
this.key = key;
this.hash = hash;
this.next = next;
}
// ...
}
static final class StrongAccessWriteEntry extends StrongEntry {
volatile long accessTime = Long.MAX_VALUE;
volatile long writeTime = Long.MAX_VALUE;
@Weak ReferenceEntry nextAccess = nullEntry();
@Weak ReferenceEntry previousAccess = nullEntry();
@Weak ReferenceEntry nextWrite = nullEntry();
@Weak ReferenceEntry previousWrite = nullEntry();
StrongAccessWriteEntry(K key, int hash, @CheckForNull ReferenceEntry next) {
super(key, hash, next);
}
}
}
StrongAccessWriteEntry 與它的父類 StrongEntry 均為定義在 LocalCache 內(nèi)的靜態(tài)內(nèi)部類,構(gòu)造方法需要指定 Key, hash, next 三個(gè)變量,這三個(gè)變量均定義在 StrongEntry 中,注意第三個(gè)變量 ReferenceEntry next,它被父類中 StrongEntry#next 字段引用,并且該字段被 final 修飾,這與前文 JavaDoc 中所描述的內(nèi)容相對(duì)應(yīng):
鍵值對(duì)對(duì)象中的 next 字段被 final 修飾,所有的添加操作都只能在每個(gè)桶的前面進(jìn)行(頭插法),這也就使得檢查變更比較容易,并且遍歷速度也比較快。
所以實(shí)際上在添加新的鍵值對(duì)元素時(shí),針對(duì)每個(gè)桶中元素操作采用的是“頭插法”,這些元素是通過(guò) next 指針引用的 單向鏈表。現(xiàn)在了解了元素的類型和創(chuàng)建邏輯,我們?cè)賮?lái)看下 put 方法的實(shí)現(xiàn)。
Guava Cache 是不允許添加 null 鍵和 null 值的,如果添加了 null 鍵或 null 值,會(huì)拋出 NullPointerException 異常。注意其中的注解 @GuardedBy 表示某方法或字段被調(diào)用或訪問(wèn)時(shí)需要持有哪個(gè)同步鎖,在 Caffeine 中也有類似的應(yīng)用:
class LocalCache extends AbstractMap implements ConcurrentMap {
// ...
final Segment[] segments;
final int segmentShift;
final int segmentMask;
@GuardedBy("this")
long totalWeight;
@CheckForNull
@CanIgnoreReturnValue
@Override
public V put(K key, V value) {
checkNotNull(key);
checkNotNull(value);
// 計(jì)算 hash 值,過(guò)程中調(diào)用了 rehash 擾動(dòng)函數(shù)使 hash 更均勻
int hash = hash(key);
// 根據(jù) hash 值路由到具體的 Segment 段,再調(diào)用 Segment 的 put 方法
return segmentFor(hash).put(key, hash, value, false);
}
Segment segmentFor(int hash) {
// 位移并位與運(yùn)算,segmentMask 為段數(shù)組長(zhǎng)度減一,保證計(jì)算結(jié)果在有效范圍內(nèi)
return segments[(hash >>> segmentShift) & segmentMask];
}
}
可以發(fā)現(xiàn)在執(zhí)行 put 操作前,會(huì)根據(jù)鍵的哈希值來(lái)將其路由(segmentFor)到具體的 Segment 段,再調(diào)用 Segment 的 put 方法,而具體的 put 方法邏輯是在 Segment 中實(shí)現(xiàn)的。我們接著看 Segment#put 方法的實(shí)現(xiàn)(為了保證可讀性,其中標(biāo)注了數(shù)字的方法會(huì)在接下來(lái)小節(jié)中具體分析):
static class Segment extends ReentrantLock {
final AtomicInteger readCount = new AtomicInteger();
@GuardedBy("this")
final Queue> accessQueue;
final Queue> recencyQueue;
@GuardedBy("this")
final Queue> writeQueue;
// guava cache 本身
@Weak
final LocalCache map;
// Segment 中保存元素的數(shù)組
@CheckForNull
volatile AtomicReferenceArray> table;
// 計(jì)數(shù)器
final StatsCounter statsCounter;
// 該段中的元素?cái)?shù)量
volatile int count;
// 總的權(quán)重,不配置也表示元素?cái)?shù)量,每個(gè)元素的權(quán)重為 1
@GuardedBy("this")
long totalWeight;
// capacity * 0.75
int threshold;
// 更新次數(shù),用于確保在批量讀取的情況下,保證數(shù)據(jù)一致性,如果多次讀取時(shí) modCount 不一致則需要重試
int modCount;
@CanIgnoreReturnValue
@CheckForNull
V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 先加鎖 ReentrantLock#lock 實(shí)現(xiàn)
lock();
try {
long now = map.ticker.read();
// 1. 寫前置的清理操作,包括處理過(guò)期元素等
preWriteCleanup(now);
int newCount = this.count + 1;
// 如果超過(guò)閾值,則擴(kuò)容
if (newCount > this.threshold) {
// 2. 擴(kuò)容操作
expand();
newCount = this.count + 1;
}
// 根據(jù)元素的 hash 值找到對(duì)應(yīng)的桶索引 index,并拿到頭節(jié)點(diǎn) first
AtomicReferenceArray> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry first = table.get(index);
// 嘗試遍歷鏈表尋找被新添加的元素是否已經(jīng)存在
for (ReferenceEntry e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
// 如果新 put 的元素在緩存中已經(jīng)存在
if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference valueReference = e.getValueReference();
V entryValue = valueReference.get();
// 通過(guò)元素的 value 是否為 null 的情況來(lái)判斷
if (entryValue == null) {
++modCount;
// StrongValueReference 類型默認(rèn) active 為 true 表示 value 值是有效的
if (valueReference.isActive()) {
// 但是此時(shí)元素的 value 值為空,說(shuō)明該 value 值已經(jīng)被垃圾回收了,所以需要將該元素 value 被垃圾回收的通知加入到通知隊(duì)列中
// 并在總權(quán)重中將該元素的權(quán)重減去
enqueueNotification(key, hash, entryValue, valueReference.getWeight(), RemovalCause.COLLECTED);
// 更新為新的 value
setValue(e, key, value, now);
// 元素總數(shù)不變更
newCount = this.count;
} else {
// 賦值新的 Value 并需要將元素?cái)?shù) +1
setValue(e, key, value, now);
newCount = this.count + 1;
}
// 變更 count 值(可見性)
this.count = newCount;
// 3. 驅(qū)逐元素
evictEntries(e);
return null;
} else if (onlyIfAbsent) {
// 如果 onlyIfAbsent 為 true,那么已存在元素的 value 是不會(huì)被覆蓋的,只需要記錄讀操作即可
recordLockedRead(e, now);
return entryValue;
} else {
// 這種情況是 value 不為空,需要將舊值替換成新值
// 變更修改次數(shù)
++modCount;
// 同樣是先將該元素的權(quán)重減去,并將元素 value 被替換的通知加入到通知隊(duì)列中
enqueueNotification(key, hash, entryValue, valueReference.getWeight(), RemovalCause.REPLACED);
setValue(e, key, value, now);
// 3. 驅(qū)逐元素
evictEntries(e);
return entryValue;
}
}
}
// put 的元素是一個(gè)新元素
++modCount;
// 創(chuàng)建一個(gè)新元素,并指定 next 節(jié)點(diǎn)為 first 頭節(jié)點(diǎn)
ReferenceEntry newEntry = newEntry(key, hash, first);
setValue(newEntry, key, value, now);
// 將該元素封裝到數(shù)組中
table.set(index, newEntry);
// 更新 count 值
newCount = this.count + 1;
this.count = newCount;
// 3. 驅(qū)逐元素
evictEntries(newEntry);
return null;
} finally {
// 執(zhí)行完操作,解鎖
unlock();
// 4. 寫后操作,主要是處理通知,在后文中介紹
postWriteCleanup();
}
}
@GuardedBy("this")
void setValue(ReferenceEntry entry, K key, V value, long now) {
ValueReference previous = entry.getValueReference();
// 計(jì)算元素權(quán)重,如果沒(méi)有執(zhí)行權(quán)重計(jì)算函數(shù)默認(rèn)為 1
int weight = map.weigher.weigh(key, value);
checkState(weight >= 0, "Weights must be non-negative");
// 更新元素的 value 值
ValueReference valueReference = map.valueStrength.referenceValue(this, entry, value, weight);
entry.setValueReference(valueReference);
// 處理寫操作
recordWrite(entry, weight, now);
// StrongValueReference 該方法為空實(shí)現(xiàn)
previous.notifyNewValue(value);
}
@GuardedBy("this")
void recordWrite(ReferenceEntry entry, int weight, long now) {
// 將元素的最近被訪問(wèn)隊(duì)列 recencyQueue 清空,并使用尾插法將它們都放到訪問(wèn)隊(duì)列 accessQueue 的尾節(jié)點(diǎn)
drainRecencyQueue();
// 變更總權(quán)重
totalWeight += weight;
// 如果配置了訪問(wèn)后或?qū)懞筮^(guò)期則更新元素的訪問(wèn)后或?qū)懞髸r(shí)間
if (map.recordsAccess()) {
entry.setAccessTime(now);
}
if (map.recordsWrite()) {
entry.setWriteTime(now);
}
// 添加到訪問(wèn)隊(duì)列和寫隊(duì)列中
accessQueue.add(entry);
writeQueue.add(entry);
}
@GuardedBy("this")
void recordLockedRead(ReferenceEntry entry, long now) {
// 配置了訪問(wèn)后過(guò)期時(shí)間則更新該元素的訪問(wèn)時(shí)間
if (map.recordsAccess()) {
entry.setAccessTime(now);
}
// 將該元素添加到訪問(wèn)隊(duì)列中
accessQueue.add(entry);
}
}
上述源碼中,我們能夠發(fā)現(xiàn) Guava Cache 是在 Segment 的級(jí)別加鎖 的,通過(guò)這樣的方式來(lái)減少競(jìng)爭(zhēng),其中 preWriteCleanup 方法負(fù)責(zé)處理元素的過(guò)期;evictEntries 方法負(fù)責(zé)驅(qū)逐保證緩存不超過(guò)最大的容量,根據(jù) LRU 算法將最近最少訪問(wèn)的元素移除;expand 方法負(fù)責(zé) Segment 的擴(kuò)容;setValue, recordWrite 和 recordLockedRead 方法負(fù)責(zé)處理元素的更新并記錄訪問(wèn)情況(更新 accessQueue 和 writeQueue 隊(duì)列)。它對(duì)元素的管理相對(duì)簡(jiǎn)單也比較容易理解,接下來(lái)我們分步驟看下其中方法的實(shí)現(xiàn)。
preWriteCleanup
首先我們重點(diǎn)看下 preWriteCleanup 方法,該方法負(fù)責(zé)處理元素的過(guò)期,而元素過(guò)期的判斷也非常簡(jiǎn)單,它會(huì)在每個(gè)元素中記錄它們最新的訪問(wèn)或?qū)懭霑r(shí)間,將當(dāng)前時(shí)間與這些時(shí)間作差后與配置的訪問(wèn)或?qū)懭脒^(guò)期時(shí)間作比較,如果超過(guò)了配置的時(shí)間則表示元素過(guò)期,并將它們進(jìn)行驅(qū)逐。除此之外還有兩個(gè)小細(xì)節(jié)需要留意,隊(duì)列中維護(hù)元素的變動(dòng)采用的是 LRU 算法,并規(guī)定元素越靠近尾部表示它越“新”,另一點(diǎn)是 readCount 會(huì)在寫后標(biāo)記為 0,這個(gè)變量的作用是保證在沒(méi)發(fā)生寫操作的情況下,而讀次數(shù)超過(guò)一定閾值也會(huì)執(zhí)行 cleanUp 的方法,這個(gè)在后文的 get 方法邏輯中還會(huì)提到。源碼如下所示:
static class Segment extends ReentrantLock {
final AtomicInteger readCount = new AtomicInteger();
@GuardedBy("this")
final Queue> accessQueue;
final Queue> recencyQueue;
@GuardedBy("this")
final Queue> writeQueue;
// guava cache 本身
@Weak final LocalCache map;
// Segment 中保存元素的數(shù)組
@CheckForNull volatile AtomicReferenceArray> table;
// 計(jì)數(shù)器
final StatsCounter statsCounter;
// 該段中的元素?cái)?shù)量
volatile int count;
// 總的權(quán)重,不配置也表示元素?cái)?shù)量,每個(gè)元素的權(quán)重為 1
@GuardedBy("this")
long totalWeight;
@GuardedBy("this")
void preWriteCleanup(long now) {
// 執(zhí)行加鎖的清理操作,包括處理引用隊(duì)列和過(guò)期元素
runLockedCleanup(now);
}
void runLockedCleanup(long now) {
// 仍然是 ReentrantLock#tryLock 實(shí)現(xiàn)
if (tryLock()) {
try {
// 處理引用隊(duì)列(本文不對(duì)指定 Key 或 Value 為 weekReference 的情況進(jìn)行分析)
drainReferenceQueues();
// 處理元素過(guò)期
expireEntries(now);
// 寫后讀次數(shù)清零
readCount.set(0);
} finally {
unlock();
}
}
}
@GuardedBy("this")
void expireEntries(long now) {
// 處理最近訪問(wèn)隊(duì)列 recencyQueue 和訪問(wèn)隊(duì)列 accessQueue
drainRecencyQueue();
ReferenceEntry e;
// 從頭節(jié)點(diǎn)開始遍歷寫隊(duì)列 writeQueue,將過(guò)期的元素移除
while ((e = writeQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) {
if (!removeEntry(e, e.getHash(), RemovalCause.EXPIRED)) {
throw new AssertionError();
}
}
}
// 將元素的最近被訪問(wèn)隊(duì)列 recencyQueue 清空,并使用尾插法將它們都放到訪問(wèn)隊(duì)列 accessQueue 的尾節(jié)點(diǎn)
@GuardedBy("this")
void drainRecencyQueue() {
ReferenceEntry e;
// 遍歷元素最近被訪問(wèn)隊(duì)列 recencyQueue
while ((e = recencyQueue.poll()) != null) {
// 如果該元素在訪問(wèn)隊(duì)列 accessQueue 中
if (accessQueue.contains(e)) {
// 則將其放到尾節(jié)點(diǎn)
accessQueue.add(e);
}
// 源碼中對(duì)這里的 IF 判斷,標(biāo)注了如下內(nèi)容來(lái)解釋如此判斷的原因:
// 盡管元素已經(jīng)在緩存中刪除,但它仍可能在 recencyQueue 隊(duì)列中。
// 這種情況可能出現(xiàn)在開發(fā)者操作元素刪除或清空段中所有元素的同時(shí)執(zhí)行讀操作
}
}
@VisibleForTesting
@GuardedBy("this")
@CanIgnoreReturnValue
boolean removeEntry(ReferenceEntry entry, int hash, RemovalCause cause) {
int newCount = this.count - 1;
AtomicReferenceArray> table = this.table;
// 位與運(yùn)算找到對(duì)應(yīng)的桶,獲取頭節(jié)點(diǎn)
int index = hash & (table.length() - 1);
ReferenceEntry first = table.get(index);
for (ReferenceEntry e = first; e != null; e = e.getNext()) {
// 找到了對(duì)應(yīng)的元素則操作移除
if (e == entry) {
++modCount;
// 在鏈表chain中移除元素,注意 e 表示待移除的元素
ReferenceEntry newFirst = removeValueFromChain(first, e, e.getKey(), hash,
e.getValueReference().get(), e.getValueReference(), cause);
// 注意這里又重新計(jì)算了 newCount,防止在方法執(zhí)行前的 newCount 快照值發(fā)生變更
newCount = this.count - 1;
// 桶的位置更新為新的鏈表頭節(jié)點(diǎn)
table.set(index, newFirst);
// count 被 volatile 修飾,可見性寫操作
this.count = newCount;
return true;
}
}
return false;
}
/**
* 將元素從隊(duì)列中移除
*
* @param first 隊(duì)列的頭節(jié)點(diǎn)
* @param entry 待移除元素
* @param key 待移除元素的 key
* @param hash 待移除元素的 hash 值
* @param value 待移除元素的 value 值
* @param valueReference 帶移除元素的 value 引用對(duì)象
* @param cause 被移除的原因
* @return 返回鏈表頭節(jié)點(diǎn)
*/
@GuardedBy("this")
@CheckForNull
ReferenceEntry removeValueFromChain(ReferenceEntry first, ReferenceEntry entry,
@CheckForNull K key, int hash, V value, ValueReference valueReference,
RemovalCause cause) {
// 入隊(duì)元素被移除的通知等操作
enqueueNotification(key, hash, value, valueReference.getWeight(), cause);
// 在寫隊(duì)列和訪問(wèn)隊(duì)列中移除元素
writeQueue.remove(entry);
accessQueue.remove(entry);
if (valueReference.isLoading()) {
valueReference.notifyNewValue(null);
return first;
} else {
// 將元素在鏈表中移除
return removeEntryFromChain(first, entry);
}
}
@GuardedBy("this")
@CheckForNull
ReferenceEntry removeEntryFromChain(ReferenceEntry first, ReferenceEntry entry) {
// 初始化計(jì)數(shù)跟蹤數(shù)量變化
int newCount = count;
// 被移除元素的 next 元素,作為新的頭節(jié)點(diǎn)
ReferenceEntry newFirst = entry.getNext();
// 遍歷從 原頭節(jié)點(diǎn) first 到 被移除元素 entry 之間的所有元素
for (ReferenceEntry e = first; e != entry; e = e.getNext()) {
// 創(chuàng)建一個(gè)新的節(jié)點(diǎn),該節(jié)點(diǎn)是節(jié)點(diǎn) e 的副本,并把新節(jié)點(diǎn)的 next 指針指向 newFirst 節(jié)點(diǎn)
ReferenceEntry next = copyEntry(e, newFirst);
// 如果 next 不為空,變更 newFirst 的引用,指向剛剛創(chuàng)建的節(jié)點(diǎn)
// 如果原鏈表為 a -> b -> c -> d 移除 c 后鏈表為 b -> a -> d
if (next != null) {
newFirst = next;
} else {
// 如果 next 為空,表示發(fā)生了垃圾回收,將該被回收的元素的移除
removeCollectedEntry(e);
// 計(jì)數(shù)減一
newCount--;
}
}
// 更新計(jì)數(shù)
this.count = newCount;
// 返回新的頭節(jié)點(diǎn)
return newFirst;
}
@GuardedBy("this")
void removeCollectedEntry(ReferenceEntry entry) {
// 入隊(duì)元素被移除的通知等操作
enqueueNotification(entry.getKey(), entry.getHash(), entry.getValueReference().get(),
entry.getValueReference().getWeight(), RemovalCause.COLLECTED);
writeQueue.remove(entry);
accessQueue.remove(entry);
}
@GuardedBy("this")
void enqueueNotification(@CheckForNull K key, int hash, @CheckForNull V value, int weight, RemovalCause cause) {
// 將當(dāng)前元素的權(quán)重在總權(quán)重中減去
totalWeight -= weight;
// 如果元素被驅(qū)逐,則在計(jì)數(shù)器中記錄
if (cause.wasEvicted()) {
statsCounter.recordEviction();
}
// 如果配置了驅(qū)逐通知,則將該元素被驅(qū)逐的原因等信息放入隊(duì)列
if (map.removalNotificationQueue != DISCARDING_QUEUE) {
RemovalNotification notification = RemovalNotification.create(key, value, cause);
map.removalNotificationQueue.offer(notification);
}
}
}
class LocalCache extends AbstractMap implements ConcurrentMap {
// 判斷元素是否過(guò)期,它的邏輯非常簡(jiǎn)單,如果配置了對(duì)應(yīng)的過(guò)期模式,如訪問(wèn)后過(guò)期或?qū)懞筮^(guò)期
// 會(huì)根據(jù)當(dāng)前時(shí)間與元素的訪問(wèn)時(shí)間或?qū)懭霑r(shí)間進(jìn)行比較,如果超過(guò)配置的過(guò)期時(shí)間,則返回 true,否則返回 false
boolean isExpired(ReferenceEntry entry, long now) {
checkNotNull(entry);
if (expiresAfterAccess() && (now - entry.getAccessTime() >= expireAfterAccessNanos)) {
return true;
}
if (expiresAfterWrite() && (now - entry.getWriteTime() >= expireAfterWriteNanos)) {
return true;
}
return false;
}
}
expand
接下來(lái)是擴(kuò)容方法,因?yàn)樵诔跏蓟瘯r(shí),Segment 對(duì)象的 table 數(shù)組并沒(méi)有被創(chuàng)建為最大的分段的大小,而是采取了較小的值 4 作為初始大小,所以隨著元素的增加,會(huì)觸發(fā)數(shù)組的擴(kuò)容以滿足元素的存儲(chǔ),它的負(fù)載因子默認(rèn)為 0.75,每次擴(kuò)容的大小為原有長(zhǎng)度的 2 倍。其中對(duì)原有數(shù)組中元素的遷移蠻有意思,它會(huì)將能夠哈希到同一個(gè)桶的元素直接賦值到新的數(shù)組,而不能被哈希到同一個(gè)桶的元素則創(chuàng)建它們的深拷貝,一個(gè)個(gè)放入新的數(shù)組中,如下:
static class Segment extends ReentrantLock {
static final int MAXIMUM_CAPACITY = 1 > table;
// 該段中的元素?cái)?shù)量
volatile int count;
// 總的權(quán)重,不配置也表示元素?cái)?shù)量,每個(gè)元素的權(quán)重為 1
@GuardedBy("this")
long totalWeight;
// capacity * 0.75
int threshold;
@GuardedBy("this")
void expand() {
AtomicReferenceArray> oldTable = table;
int oldCapacity = oldTable.length();
// 如果容量已經(jīng)達(dá)到最大值,則直接返回
if (oldCapacity >= MAXIMUM_CAPACITY) {
return;
}
int newCount = count;
// 創(chuàng)建一個(gè)原來(lái)兩倍容量的 AtomicReferenceArray
AtomicReferenceArray> newTable = newEntryArray(oldCapacity head = oldTable.get(oldIndex);
if (head != null) {
// 獲取頭節(jié)點(diǎn)的 next 節(jié)點(diǎn)
ReferenceEntry next = head.getNext();
// 計(jì)算頭節(jié)點(diǎn)在新數(shù)組中的索引
int headIndex = head.getHash() & newMask;
// 頭節(jié)點(diǎn)的 next 節(jié)點(diǎn)為空,那么證明該桶位置只有一個(gè)元素,直接將頭節(jié)點(diǎn)放在新數(shù)組的索引處
if (next == null) {
newTable.set(headIndex, head);
} else {
// 遍歷從 next 開始的節(jié)點(diǎn),找到所有能 hash 到同一個(gè)桶的一批節(jié)點(diǎn),然后將這些節(jié)點(diǎn)封裝在新數(shù)組的對(duì)應(yīng)索引處
ReferenceEntry tail = head;
int tailIndex = headIndex;
for (ReferenceEntry e = next; e != null; e = e.getNext()) {
int newIndex = e.getHash() & newMask;
if (newIndex != tailIndex) {
tailIndex = newIndex;
tail = e;
}
}
newTable.set(tailIndex, tail);
// 將這些剩余的不能 hash 到同一個(gè)桶的節(jié)點(diǎn),依次遍歷,將它們放入新數(shù)組中
for (ReferenceEntry e = head; e != tail; e = e.getNext()) {
int newIndex = e.getHash() & newMask;
ReferenceEntry newNext = newTable.get(newIndex);
// 注意這里創(chuàng)建節(jié)點(diǎn)是深拷貝,并且采用的是頭插法
ReferenceEntry newFirst = copyEntry(e, newNext);
if (newFirst != null) {
newTable.set(newIndex, newFirst);
} else {
// 如果 next 為空,表示發(fā)生了垃圾回收,將該被回收的元素的移除
removeCollectedEntry(e);
newCount--;
}
}
}
}
}
// 操作完成后更新 table 和 count
table = newTable;
this.count = newCount;
}
}
evictEntries
元素的驅(qū)逐方法 evictEntries 主要負(fù)責(zé)維護(hù)緩存不超過(guò)最大容量限制,實(shí)現(xiàn)原理也非常簡(jiǎn)單,它會(huì)根據(jù) accessQueue 隊(duì)列,將最近最少訪問(wèn)的元素優(yōu)先移除:
static class Segment extends ReentrantLock {
@Weak final LocalCache map;
final long maxSegmentWeight;
@GuardedBy("this")
long totalWeight;
@GuardedBy("this")
final Queue> accessQueue;
@GuardedBy("this")
void evictEntries(ReferenceEntry newest) {
if (!map.evictsBySize()) {
return;
}
// 這個(gè)方法我們?cè)谇拔闹薪榻B過(guò)
// 將元素的最近被訪問(wèn)隊(duì)列 recencyQueue 清空,并使用尾插法將它們都放到訪問(wèn)隊(duì)列 accessQueue 的尾節(jié)點(diǎn)
drainRecencyQueue();
// 如果新加入的元素權(quán)重超過(guò)了最大權(quán)重,那么直接將該元素驅(qū)逐
if (newest.getValueReference().getWeight() > maxSegmentWeight) {
if (!removeEntry(newest, newest.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
// 如果當(dāng)前權(quán)重超過(guò)最大權(quán)重,那么不斷地驅(qū)逐元素直到滿足條件
while (totalWeight > maxSegmentWeight) {
// 在 accessQueue 中從頭節(jié)點(diǎn)遍歷元素,依次移除最近沒(méi)有被訪問(wèn)的元素
ReferenceEntry e = getNextEvictable();
if (!removeEntry(e, e.getHash(), RemovalCause.SIZE)) {
throw new AssertionError();
}
}
}
@GuardedBy("this")
ReferenceEntry getNextEvictable() {
for (ReferenceEntry e : accessQueue) {
int weight = e.getValueReference().getWeight();
if (weight > 0) {
return e;
}
}
throw new AssertionError();
}
}
postWriteCleanup
寫后清理操作需要關(guān)注的內(nèi)容并不多,它主要處理監(jiān)聽器相關(guān)的邏輯,因?yàn)樵谖覀兊睦又胁](méi)有創(chuàng)建監(jiān)聽器所以就不在詳細(xì)分析了。
static class Segment extends ReentrantLock {
@Weak final LocalCache map;
void postWriteCleanup() {
runUnlockedCleanup();
}
void runUnlockedCleanup() {
// locked cleanup may generate notifications we can send unlocked
if (!isHeldByCurrentThread()) {
map.processPendingNotifications();
}
}
}
class LocalCache extends AbstractMap implements ConcurrentMap {
final Queue> removalNotificationQueue;
final RemovalListener removalListener;
void processPendingNotifications() {
RemovalNotification notification;
while ((notification = removalNotificationQueue.poll()) != null) {
try {
removalListener.onRemoval(notification);
} catch (Throwable e) {
logger.log(Level.WARNING, "Exception thrown by removal listener", e);
}
}
}
}
get
接下來(lái)我們要深入 get 方法的分析了,同樣地它也會(huì)被路由(segmentFor)到具體的 Segment:
static class LocalManualCache implements Cache, Serializable {
final LocalCache localCache;
// ...
}
static class LocalLoadingCache extends LocalManualCache
implements LoadingCache {
@Override
public V get(K key) throws ExecutionException {
return localCache.getOrLoad(key);
}
}
class LocalCache extends AbstractMap implements ConcurrentMap {
@CheckForNull final CacheLoader defaultLoader;
V getOrLoad(K key) throws ExecutionException {
return get(key, defaultLoader);
}
@CanIgnoreReturnValue
V get(K key, CacheLoader loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}
}
它的核心邏輯也在 Segment 中,注意讀操作是不加鎖的,它相比與 put 方法要簡(jiǎn)單,其中要注意的是 recordRead 方法,它會(huì)將被訪問(wèn)的元素添加到 recencyQueue 最近訪問(wèn)隊(duì)列中,用于記錄最近被訪問(wèn)元素的順序,后續(xù)執(zhí)行維護(hù)(cleanUp)相關(guān)的邏輯時(shí),會(huì)將該隊(duì)列中的元素全部移動(dòng)到 accessQueue 隊(duì)列中,用于根據(jù)元素的訪問(wèn)順序來(lái)判斷元素是否被驅(qū)逐。除此之外,因?yàn)樵氐尿?qū)逐大多都是在 put 方法中完成的,為了在不發(fā)生寫操作的情況下也能正常管理元素的生命中期,在 get 方法中也有相關(guān)的實(shí)現(xiàn),比如 postReadCleanup 方法,它通過(guò) readCount 的計(jì)數(shù)和 DRAIN_THRESHOLD 的閾值來(lái)判斷是否需要驅(qū)逐元素,當(dāng)計(jì)數(shù)超過(guò)閾值時(shí)則調(diào)用 cleanUp 方法進(jìn)行驅(qū)逐,當(dāng)然這并不會(huì)強(qiáng)制執(zhí)行(因?yàn)樗鼒?zhí)行的是 ReentrantLock#tryLock 方法),嘗試獲取鎖來(lái)執(zhí)行,即使沒(méi)有獲取到鎖,那么證明有寫操作在執(zhí)行,元素的驅(qū)逐操作也不需要再多關(guān)心了。源碼如下所示:
static class Segment extends ReentrantLock {
static final int DRAIN_THRESHOLD = 0x3F;
volatile int count;
@Weak final LocalCache map;
final Queue> recencyQueue;
final StatsCounter statsCounter;
final AtomicInteger readCount = new AtomicInteger();
@CanIgnoreReturnValue
V get(K key, int hash, CacheLoader loader) throws ExecutionException {
checkNotNull(key);
checkNotNull(loader);
try {
if (count != 0) {
ReferenceEntry e = getEntry(key, hash);
// 獲取到對(duì)應(yīng)元素
if (e != null) {
long now = map.ticker.read();
// 獲取到對(duì)應(yīng)的 value
V value = getLiveValue(e, now);
// value 不為空
if (value != null) {
// 記錄讀操作,會(huì)將元素添加到最近訪問(wèn)隊(duì)列 recencyQueue 的尾節(jié)點(diǎn)
recordRead(e, now);
// 命中計(jì)數(shù) +1
statsCounter.recordHits(1);
// 如果配置了元素刷新則執(zhí)行相關(guān)刷新邏輯
return scheduleRefresh(e, key, hash, value, now, loader);
}
// value 為空
ValueReference valueReference = e.getValueReference();
// 如果 value 正在 loading 則等待
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
}
// 如果元素?cái)?shù)量為 0,則執(zhí)行該方法
return lockedGetOrLoad(key, hash, loader);
} catch (ExecutionException ee) {
Throwable cause = ee.getCause();
if (cause instanceof Error) {
throw new ExecutionError((Error) cause);
} else if (cause instanceof RuntimeException) {
throw new UncheckedExecutionException(cause);
}
throw ee;
} finally {
postReadCleanup();
}
}
@CheckForNull
ReferenceEntry getEntry(Object key, int hash) {
// 獲取到 table 數(shù)組中對(duì)應(yīng)桶的頭節(jié)點(diǎn)
for (ReferenceEntry e = getFirst(hash); e != null; e = e.getNext()) {
// 元素 hash 值不相等繼續(xù)遍歷尋找
if (e.getHash() != hash) {
continue;
}
// 找到對(duì)應(yīng)的元素后,如果 key 為空,則處理引用隊(duì)列
K entryKey = e.getKey();
if (entryKey == null) {
tryDrainReferenceQueues();
continue;
}
// 如果 key 值相等,則返回該元素
if (map.keyEquivalence.equivalent(key, entryKey)) {
return e;
}
}
// 否則返回 null
return null;
}
V getLiveValue(ReferenceEntry entry, long now) {
// key 和 value 為空的情況,處理引用隊(duì)列
if (entry.getKey() == null) {
tryDrainReferenceQueues();
return null;
}
V value = entry.getValueReference().get();
if (value == null) {
tryDrainReferenceQueues();
return null;
}
// 如果元素過(guò)期了
if (map.isExpired(entry, now)) {
// 嘗試加鎖執(zhí)行元素過(guò)期驅(qū)逐操作
tryExpireEntries(now);
return null;
}
return value;
}
void recordRead(ReferenceEntry entry, long now) {
// 如果配置了訪問(wèn)后過(guò)期,則更新元素訪問(wèn)時(shí)間
if (map.recordsAccess()) {
entry.setAccessTime(now);
}
// 將元素添加到最近訪問(wèn)隊(duì)列中
recencyQueue.add(entry);
}
V waitForLoadingValue(ReferenceEntry e, K key, ValueReference valueReference) throws ExecutionException {
if (!valueReference.isLoading()) {
throw new AssertionError();
}
checkState(!Thread.holdsLock(e), "Recursive load of: %s", key);
try {
// 等待元素加載完成
V value = valueReference.waitForValue();
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
// 執(zhí)行記錄讀操作
long now = map.ticker.read();
recordRead(e, now);
return value;
} finally {
// 未命中統(tǒng)計(jì)數(shù)+1
statsCounter.recordMisses(1);
}
}
// 通常在寫入過(guò)程中進(jìn)行清理。如果在足夠數(shù)量的讀取后沒(méi)有觀察到清理,請(qǐng)嘗試從讀取線程進(jìn)行清理。
void postReadCleanup() {
// readCount 自增,如果達(dá)到閾值則執(zhí)行清理操作,清理操作與寫入操作中的邏輯一致
if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0) {
cleanUp();
}
}
void cleanUp() {
long now = map.ticker.read();
runLockedCleanup(now);
runUnlockedCleanup();
}
}
lockedGetOrLoad
lockedGetOrLoad 是 LoadingCache 的核心邏輯,在某個(gè) key 在緩存中不存在且配置了 loader 函數(shù)時(shí)會(huì)被執(zhí)行,本質(zhì)上這也是觸發(fā)了一次寫操作,將不存在的元素通過(guò) loader 方法獲取到具體值并加載到緩存中,所以在這里也會(huì)觸發(fā)到元素生命周期管理的方法,如 preWriteCleanup,不過(guò)該方法總體上的實(shí)現(xiàn)與 put 方法類似,并沒(méi)有特別復(fù)雜的地方。
static class Segment extends ReentrantLock {
volatile int count;
@Weak final LocalCache map;
@CheckForNull volatile AtomicReferenceArray> table;
@GuardedBy("this")
final Queue> writeQueue;
@GuardedBy("this")
final Queue> accessQueue;
final StatsCounter statsCounter;
int modCount;
// 加鎖讀或加載元素值
V lockedGetOrLoad(K key, int hash, CacheLoader loader) throws ExecutionException {
ReferenceEntry e;
ValueReference valueReference = null;
LoadingValueReference loadingValueReference = null;
boolean createNewEntry = true;
// 加鎖
lock();
try {
long now = map.ticker.read();
// 寫前整理操作,已經(jīng)在上文中介紹過(guò)
preWriteCleanup(now);
int newCount = this.count - 1;
// 找到該元素對(duì)應(yīng)桶的頭節(jié)點(diǎn)
AtomicReferenceArray> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry first = table.get(index);
// 遍歷尋找該元素
for (e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
// 如果找到了與該元素 key 值相等的元素
if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) {
valueReference = e.getValueReference();
// 判斷元素是否在加載中
if (valueReference.isLoading()) {
// 如果在加載中則不創(chuàng)建新的元素
createNewEntry = false;
} else {
// 否則執(zhí)行元素的加載
V value = valueReference.get();
if (value == null) {
// 如果獲取到的值為空,說(shuō)明元素已經(jīng)被回收了,則將該事件通知放到隊(duì)列中
enqueueNotification(entryKey, hash, value, valueReference.getWeight(), RemovalCause.COLLECTED);
} else if (map.isExpired(e, now)) {
// 如果元素過(guò)期了,則將該事件通知放到隊(duì)列中
enqueueNotification(entryKey, hash, value, valueReference.getWeight(), RemovalCause.EXPIRED);
} else {
// 否則,獲取到了 value 值,執(zhí)行記錄讀操作
recordLockedRead(e, now);
// 命中統(tǒng)計(jì)數(shù)+1
statsCounter.recordHits(1);
return value;
}
// value 無(wú)效的情況都需要將元素在寫隊(duì)列和訪問(wèn)隊(duì)列中移除
writeQueue.remove(e);
accessQueue.remove(e);
// 可見性寫操作
this.count = newCount;
}
break;
}
}
// 沒(méi)有找到該元素,則需要?jiǎng)?chuàng)建新元素
if (createNewEntry) {
// value 的類型為 LoadingValueReference
loadingValueReference = new LoadingValueReference();
if (e == null) {
e = newEntry(key, hash, first);
e.setValueReference(loadingValueReference);
table.set(index, e);
} else {
e.setValueReference(loadingValueReference);
}
}
} finally {
// 解鎖和寫后通知操作
unlock();
postWriteCleanup();
}
if (createNewEntry) {
try {
// 同步執(zhí)行元素的加載
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
// 元素未命中統(tǒng)計(jì)數(shù)+1
statsCounter.recordMisses(1);
}
} else {
// 元素已經(jīng)存在,等在加載
return waitForLoadingValue(e, key, valueReference);
}
}
V loadSync(K key, int hash, LoadingValueReference loadingValueReference, CacheLoader loader) throws ExecutionException {
ListenableFuture loadingFuture = loadingValueReference.loadFuture(key, loader);
return getAndRecordStats(key, hash, loadingValueReference, loadingFuture);
}
@CanIgnoreReturnValue
V getAndRecordStats(K key, int hash, LoadingValueReference loadingValueReference, ListenableFuture newValue) throws ExecutionException {
V value = null;
try {
// 阻塞執(zhí)行 loader 函數(shù)(不允許中斷)
value = getUninterruptibly(newValue);
if (value == null) {
throw new InvalidCacheLoadException("CacheLoader returned null for key " + key + ".");
}
// 標(biāo)記元素加載完成
statsCounter.recordLoadSuccess(loadingValueReference.elapsedNanos());
// 保存加載的元素
storeLoadedValue(key, hash, loadingValueReference, value);
return value;
} finally {
if (value == null) {
statsCounter.recordLoadException(loadingValueReference.elapsedNanos());
removeLoadingValue(key, hash, loadingValueReference);
}
}
}
// 邏輯與 put 方法類似
@CanIgnoreReturnValue
boolean storeLoadedValue(K key, int hash, LoadingValueReference oldValueReference, V newValue) {
// 加鎖
lock();
try {
long now = map.ticker.read();
preWriteCleanup(now);
int newCount = this.count + 1;
if (newCount > this.threshold) {
expand();
newCount = this.count + 1;
}
// 找到該元素對(duì)應(yīng)的桶的頭節(jié)點(diǎn)
AtomicReferenceArray> table = this.table;
int index = hash & (table.length() - 1);
ReferenceEntry first = table.get(index);
for (ReferenceEntry e = first; e != null; e = e.getNext()) {
K entryKey = e.getKey();
if (e.getHash() == hash && entryKey != null && map.keyEquivalence.equivalent(key, entryKey)) {
ValueReference valueReference = e.getValueReference();
V entryValue = valueReference.get();
// 如果元素已經(jīng)存在,則替換舊的 LoadingValueReference
if (oldValueReference == valueReference || (entryValue == null && valueReference != UNSET)) {
++modCount;
if (oldValueReference.isActive()) {
RemovalCause cause = (entryValue == null) ? RemovalCause.COLLECTED : RemovalCause.REPLACED;
enqueueNotification(key, hash, entryValue, oldValueReference.getWeight(), cause);
newCount--;
}
setValue(e, key, newValue, now);
this.count = newCount;
evictEntries(e);
return true;
}
enqueueNotification(key, hash, newValue, 0, RemovalCause.REPLACED);
return false;
}
}
++modCount;
// 沒(méi)有找到該 key 對(duì)應(yīng)的元素則創(chuàng)建新的元素,此處邏輯與 put 元素的操作一致
ReferenceEntry newEntry = newEntry(key, hash, first);
setValue(newEntry, key, newValue, now);
table.set(index, newEntry);
this.count = newCount;
evictEntries(newEntry);
return true;
} finally {
unlock();
postWriteCleanup();
}
}
}
與 Caffeine 的對(duì)比
Guava Cache 的源碼要比 Caffeine 簡(jiǎn)單得多,但是 Caffeine 的實(shí)現(xiàn)更加優(yōu)雅,可讀性也更高(詳細(xì)參閱萬(wàn)文詳解 Caffeine 實(shí)現(xiàn)原理)。
Guava Cache 采用的是分段鎖的思想,這種思想在 JDK 1.7 的 ConcurrentHashMap 也有實(shí)現(xiàn),但由于性能相對(duì)較差,在 JDK 1.8 及之后被棄用,取而代之的是使用 CAS 操作、少量 synchronized 關(guān)鍵字同步操作、及合適的 自旋重試 和 volatile 關(guān)鍵字的方案,而在 Caffeine 中,底層實(shí)現(xiàn)采用的便是 ConcurrentHashMap,它是在 ConcurrentHashMap 之上添加了緩存相關(guān)的管理功能,如緩存過(guò)期、緩存淘汰等(相比于 Guava Cache 功能也更豐富),在這一點(diǎn)上 Caffeine 就已經(jīng)占盡了優(yōu)勢(shì),能夠高效支持更大規(guī)模的并發(fā)訪問(wèn),而且還能隨著 JDK 升級(jí)過(guò)程中對(duì) ConcurrentHashMap 的優(yōu)化而持續(xù)享受優(yōu)化后帶來(lái)的并發(fā)效率的提升。
在 Guava Cache 中針對(duì)緩存的驅(qū)逐采用了 LRU 算法,實(shí)際上這種驅(qū)逐策略并不精準(zhǔn),在 Caffeine 中提供了基于 TinyLFU 算法 的驅(qū)逐策略,這種算法在對(duì)緩存驅(qū)逐的準(zhǔn)確性上更高,能更好的提供緩存命中率和保證緩存的性能。
除此之外,Caffeine 提供了更復(fù)雜的緩存過(guò)期管理機(jī)制:TimeWheel,這一點(diǎn)在 Guava Cache 中是沒(méi)有的(本地緩存 Caffeine 中的時(shí)間輪(TimeWheel)是什么?)。另外,在對(duì)內(nèi)存性能的優(yōu)化上,Caffeine 針對(duì)常訪問(wèn)的字段避免了緩存?zhèn)喂蚕韱?wèn)題(高性能緩存設(shè)計(jì):如何解決緩存?zhèn)喂蚕韱?wèn)題),這些在 Guava Cache 中也是沒(méi)有任何體現(xiàn)的。
總而言之,Caffeine 是更加現(xiàn)代化的本地緩存,可以說(shuō)它全面優(yōu)于 Guava Cache,在技術(shù)選型上,可以優(yōu)先考慮。不過(guò),Guava Cache 也并不是一無(wú)是處,在對(duì)性能要求不高的場(chǎng)景下且不想引入額外的依賴(Caffeine),Guava Cache 也是一個(gè)不錯(cuò)的選擇,因?yàn)?Guava 作為常用的 Java 庫(kù),通常都會(huì)在依賴中存在。
巨人的肩膀
Github - Guava
審核編輯 黃宇
-
Cache
+關(guān)注
關(guān)注
0文章
130瀏覽量
29707 -
源碼
+關(guān)注
關(guān)注
8文章
685瀏覽量
31317
發(fā)布評(píng)論請(qǐng)先 登錄
請(qǐng)問(wèn)在哪里可以找到 VisionFive 2 上的 VPU?
大家好! 疊層工藝相比傳統(tǒng)工藝,在響應(yīng)速度上具體快在哪里?
常用的百兆網(wǎng)絡(luò)變壓器與RJ45網(wǎng)口的參考連接電路有哪些,主要注意事項(xiàng)在哪里呢?
實(shí)現(xiàn)環(huán)境計(jì)算真正的瓶頸究竟在哪里
緩存之美:萬(wàn)文詳解 Caffeine 實(shí)現(xiàn)原理(上)
本地緩存 Caffeine 中的時(shí)間輪(TimeWheel)是什么?

請(qǐng)問(wèn)USB2CAN驅(qū)動(dòng)程序在哪里?
harmony-utils之LRUCacheUtil,LRUCache緩存工具類
高性能緩存設(shè)計(jì):如何解決緩存偽共享問(wèn)題



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論