 本地緩存 Caffeine 中的時間輪(TimeWheel)是什么?
本地緩存 Caffeine 中的時間輪(TimeWheel)是什么?

我們詳細介紹了 Caffeine 緩存添加元素和讀取元素的流程,并詳細解析了配置固定元素數量驅逐策略的實現原理。在本文中我們將主要介紹 配置元素過期時間策略的實現原理,補全 Caffeine 對元素管理的機制。在創建有過期時間策略的 Caffeine 緩存時,它提供了三種不同的方法,分別為 expireAfterAccess, expireAfterWrite 和 expireAfter,前兩者的元素過期機制非常簡單:通過遍歷隊列中的元素(expireAfterAccess 遍歷的是窗口區、試用區和保護區隊列,expireAfterWrite 有專用的寫順序隊列 WriteOrderDeque),并用當前時間減去元素的最后訪問時間(或寫入時間)的結果值和配置的時間作對比,如果超過配置的時間,則認為元素過期。而 expireAfter 為自定義過期策略,使用到了時間輪 TimeWheel。它的實現相對復雜,在源碼中相關的方法都會包含 Variable 命名(變量;可變的),如 expiresVariable。本文以如下源碼創建自定義過期策略的緩存來了解 Caffeine 中的 TimeWheel 機制,它創建的緩存類型為 SSA,表示 Key 和 Value 均為強引用且配置了自定義過期策略:
public class TestReadSourceCode { @Test public void doReadTimeWheel() { Cache cache2 = Caffeine.newBuilder() // .expireAfterAccess(5, TimeUnit.SECONDS) // .expireAfterWrite(5, TimeUnit.SECONDS) .expireAfter(new Expiry() { @Override public long expireAfterCreate(Object key, Object value, long currentTime) { // 指定過期時間為 Long.MAX_VALUE 則不會過期 if ("key0".equals(key)) { return Long.MAX_VALUE; } // 設置條目在創建后 5 秒過期 return TimeUnit.SECONDS.toNanos(5); } // 以下兩個過期時間指定為默認 duration 不過期 @Override public long expireAfterUpdate(Object key, Object value, long currentTime, @NonNegative long currentDuration) { return currentDuration; } @Override public long expireAfterRead(Object key, Object value, long currentTime, @NonNegative long currentDuration) { return currentDuration; } }) .build(); cache2.put("key2", "value2"); System.out.println(cache2.getIfPresent("key2")); try { Thread.sleep(6000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(cache2.getIfPresent("key2")); } }
在前文中我們提到過,Caffeine 中 maintenance 方法負責緩存的維護,包括執行緩存的驅逐,所以我們便以這個方法作為起點去探究時間過期策略的執行:
abstract class BoundedLocalCache extends BLCHeader.DrainStatusRef
implements LocalCache {
@GuardedBy("evictionLock")
void maintenance(@Nullable Runnable task) {
setDrainStatusRelease(PROCESSING_TO_IDLE);
try {
drainReadBuffer();
drainWriteBuffer();
if (task != null) {
task.run();
}
drainKeyReferences();
drainValueReferences();
// 元素過期策略執行
expireEntries();
evictEntries();
climb();
} finally {
if ((drainStatusOpaque() != PROCESSING_TO_IDLE)
|| !casDrainStatus(PROCESSING_TO_IDLE, IDLE)) {
setDrainStatusOpaque(REQUIRED);
}
}
}
}
在其中我們能發現 expireEntries 元素過期策略的執行方法,該方法的源碼如下所示:
abstract class BoundedLocalCache extends BLCHeader.DrainStatusRef
implements LocalCache {
@GuardedBy("evictionLock")
void expireEntries() {
// 獲取當前時間
long now = expirationTicker().read();
// 基于訪問和寫后的過期策略
expireAfterAccessEntries(now);
expireAfterWriteEntries(now);
// *主要關注*:執行自定義過期策略
expireVariableEntries(now);
// Pacer 用于調度和執行定時任務,創建 Caffeine 緩存時可通過 scheduler 方法來配置
// 默認為 null
Pacer pacer = pacer();
if (pacer != null) {
long delay = getExpirationDelay(now);
if (delay == Long.MAX_VALUE) {
pacer.cancel();
} else {
pacer.schedule(executor, drainBuffersTask, now, delay);
}
}
}
}
在自定義的過期策略中,我們便能夠發現 TimeWheel 的身影,并調用了它的 TimeWheel#advance 方法:
abstract class BoundedLocalCache extends BLCHeader.DrainStatusRef
implements LocalCache {
@GuardedBy("evictionLock")
void expireVariableEntries(long now) {
if (expiresVariable()) {
timerWheel().advance(this, now);
}
}
}
在深入 TimeWheel 的源碼前,我們先通過源碼注釋了解下它的作用。TimeWheel 是 Caffeine 緩存中定義的類,它的類注釋如下寫道:
一個 分層的 時間輪,能夠以O(1)的時間復雜度添加、刪除和觸發過期事件。過期事件的執行被推遲到 maintenance 維護方法中的 TimeWheel#advance 邏輯中。
A hierarchical timer wheel to add, remove, and fire expiration events in amortized O(1) time. The expiration events are deferred until the timer is advanced, which is performed as part of the cache's maintenance cycle.
可見上文中我們看見的 TimeWheel#advance 方法是用來執行元素過期事件的。在這段注釋中提到了 分層(hierarchical) 的概念,注釋中還有一段內容對這個特性進行了描述:
時間輪將計時器事件存儲在循環緩沖區的桶中。Bucket 表示粗略的時間跨度,例如一分鐘,并使用一個雙向鏈表來記錄事件。時間輪按層次結構(秒、分鐘、小時、天)構建,這樣當時間輪旋轉時,在遙遠的未來安排的事件會級聯到較低的桶中。它允許在O(1)的時間復雜度下添加、刪除和過期事件,在整個 Bucket 中的元素都會發生過期,同時有大部分元素過期的特殊情況由時間輪的輪換分攤。
A timer wheel stores timer events in buckets on a circular buffer. A bucket represents a coarse time span, e.g. one minute, and holds a doubly-linked list of events. The wheels are structured in a hierarchy (seconds, minutes, hours, days) so that events scheduled in the distant future are cascaded to lower buckets when the wheels rotate. This allows for events to be added, removed, and expired in O(1) time, where expiration occurs for the entire bucket, and the penalty of cascading is amortized by the rotations.
大概能夠推測,它的“分層”概念指的是根據事件的過期時間將這些事件放在不同的“層”去管理,秒級別的在一層,分鐘級別的在一層等等。那么接下來我們根據它的注釋內容,詳細探究一下 TimeWheel 是如何實現這種機制的。
constructor
我們先來看它的構造方法:
final class TimerWheel implements Iterable> {
// 定義了 5 個桶,每個桶的容量分別為 64、64、32、4、1
static final int[] BUCKETS = {64, 64, 32, 4, 1};
final Node[][] wheel;
TimerWheel() {
wheel = new Node[BUCKETS.length][];
for (int i = 0; i < wheel.length; i++) {
wheel[i] = new Node[BUCKETS[i]];
for (int j = 0; j < wheel[i].length; j++) {
wheel[i][j] = new Sentinel();
}
}
}
// 定義 Sentinel 內部類,創建對象表示雙向鏈表的哨兵節點
static final class Sentinel extends Node {
Node prev;
Node next;
Sentinel() {
prev = next = this;
}
}
}
它會創建如下所示的二維數組,每行都作為一個桶(Bucket),根據 BUCKETS 數組中定義的容量,每行桶的容量分別為 64、64、32、4、1,每個桶中的初始元素是創建 Sentinel 為節點的雙向鏈表,如下所示(其中...表示圖中省略了31個桶):

它為什么會創建一個內部類 Sentinel 并將其作為桶中的初始元素呢?在《算法導論》中講解鏈表的章節提到過這個方法:雙向鏈表中沒有元素時也不為 null,而是創建一個哨兵節點(Sentinel),它不存儲任何數據,只是為了方便鏈表的操作,減少代碼中的判空邏輯,而在此處將其命名為 Sentinel,表示采用這個方法,又同時提高了代碼的可讀性。
schedule
現在它的數據結構我們已經有了基本的了解,那么究竟什么時候會向其中添加元素呢?在前文中我們提到過,向 Caffeine 緩存中 put 元素時會注冊 AddTask 任務,任務中有一段邏輯會調用 TimeWheel#schedule 方法向其中添加元素:
final class AddTask implements Runnable {
@Override
@GuardedBy("evictionLock")
@SuppressWarnings("FutureReturnValueIgnored")
public void run() {
// ...
if (isAlive) {
// ...
// 如果自定義時間策略,則執行 schedule 方法
if (expiresVariable()) {
// node 為添加的節點
timerWheel().schedule(node);
}
}
// ...
}
}
我們來看看 schedule 方法,根據的它的入參可以發現上文注釋中提到的“過期事件”便是 Node 節點本身:
final class TimerWheel implements Iterable> {
static final long[] SPANS = {
// 1073741824L 2^30 1.07s
ceilingPowerOfTwo(TimeUnit.SECONDS.toNanos(1)),
// 68719476736L 2^36 1.14m
ceilingPowerOfTwo(TimeUnit.MINUTES.toNanos(1)),
// 36028797018963968L 2^45 1.22h
ceilingPowerOfTwo(TimeUnit.HOURS.toNanos(1)),
// 864691128455135232L 2^50 1.63d
ceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)),
// 5629499534213120000L 2^52 6.5d
BUCKETS[3] * ceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)),
BUCKETS[3] * ceilingPowerOfTwo(TimeUnit.DAYS.toNanos(1)),
};
// Long.numberOfTrailingZeros 表示尾隨 0 的數量
static final long[] SHIFT = {
// 30
Long.numberOfTrailingZeros(SPANS[0]),
// 36
Long.numberOfTrailingZeros(SPANS[1]),
// 45
Long.numberOfTrailingZeros(SPANS[2]),
// 50
Long.numberOfTrailingZeros(SPANS[3]),
// 52
Long.numberOfTrailingZeros(SPANS[4]),
};
final Node[][] wheel;
long nanos;
public void schedule(Node node) {
// 在 wheel 中找到對應的桶,node.getVariableTime() 獲取的是元素的“過期時間”
Node sentinel = findBucket(node.getVariableTime());
// 將該節點添加到桶中
link(sentinel, node);
}
// 初次添加時,time 為元素的“過期時間”
Node findBucket(long time) {
// 計算 duration 持續時間(有效期)
long duration = time - nanos;
// length 為 4
int length = wheel.length - 1;
for (int i = 0; i < length; i++) {
// 注意這里它是將持續時間和 SPANS[i + 1] 作比較,如果小于則認為該節點在這個“層級”中
if (duration < SPANS[i + 1]) {
// tick 指鐘表的滴答聲,用于表示它所在層級的偏移量,舉個例子:
// 如果 duration < SPANS[1] 表示秒級別的時間跨度,則右移 SHIFT[0] 30 位,SPANS[0] 為 2^30 對應 1.07s,右移 30 位足以將 time 表示為秒級別的時間跨度
long ticks = (time >>> SHIFT[i]);
// 2進制數-1 的位與運算計算出節點在該層級的實際索引位置
int index = (int) (ticks & (wheel[i].length - 1));
return wheel[i][index];
}
}
// 如果遍歷完所有層級都沒有合適的,那么將其放在最后一層
return wheel[length][0];
}
// 雙向鏈表的尾插法添加元素,有了 Sentinel 哨兵節點避免了代碼中的判空邏輯
void link(Node sentinel, Node node) {
node.setPreviousInVariableOrder(sentinel.getPreviousInVariableOrder());
node.setNextInVariableOrder(sentinel);
sentinel.getPreviousInVariableOrder().setNextInVariableOrder(node);
sentinel.setPreviousInVariableOrder(node);
}
}
其中 node.getVariableTime() 為元素的過期時間,那么這個過期時間是何時計算的呢?在 put 方法中有如下邏輯:
abstract class BoundedLocalCache extends BLCHeader.DrainStatusRef
implements LocalCache {
@Nullable
V put(K key, V value, Expiry expiry, boolean onlyIfAbsent) {
requireNonNull(key);
requireNonNull(value);
Node node = null;
long now = expirationTicker().read();
int newWeight = weigher.weigh(key, value);
Object lookupKey = nodeFactory.newLookupKey(key);
for (int attempts = 1; ; attempts++) {
Node prior = data.get(lookupKey);
if (prior == null) {
if (node == null) {
node = nodeFactory.newNode(key, keyReferenceQueue(),
value, valueReferenceQueue(), newWeight, now);
// 計算過期時間并為 variableTime 賦值
setVariableTime(node, expireAfterCreate(key, value, expiry, now));
}
}
// ...
}
// ...
}
long expireAfterCreate(@Nullable K key, @Nullable V value,
Expiry expiry, long now) {
if (expiresVariable() && (key != null) && (value != null)) {
// 此處的 expireAfterCreate 便為自定義的有效期
long duration = expiry.expireAfterCreate(key, value, now);
// 將定義的有效期在當前操作時間上進行累加得出過期時間
return isAsync ? (now + duration) : (now + Math.min(duration, MAXIMUM_EXPIRY));
}
return 0L;
}
}
可以發現在元素被添加時它的過期時間已經被計算好了。接著回到 findBucket 方法,其中有邏輯 duration < SPANS[i + 1] 確定節點所在時間輪的層級。SPANS 數組中存儲的是層級的“時間跨度邊界”,如注釋中標記的,SPANS[0] 表示第一層級的時間為 1.07s,SPANS[1] 表示第二層級的時間為 1.14m,for 循環開始時便以 SPANS[1] 作為比較,如果 duration 小于 SPANS[1],那么將該節點放在第一層級,那么第一層級的時間范圍為 t < 1.14 min,為秒級的時間跨度;第二層級的時間范圍為 1.14 min <= t < 1.22 h,為分鐘級的時間跨度,接下來的時間跨度以此類推。在這里也明白了為什么 final Node[][] wheel 數據結構會將第一行、第二行元素大小設定為 64,因為第一行為秒級別的時間跨度,60s 即為 1min,那么在這個秒級別的跨度下 64 的容量足以,同理,第二行為分鐘級別的時間跨度,60min 即為 1h,那么在這個分鐘級別的跨度下 64 的容量也足夠了。
現在我們已經了解了向 TimeWheel 中添加元素的邏輯,那么現在我們可以回到文章開頭提到的 maintenance 方法中調用的 TimeWheel#advance 方法了。
advance
advance 有推進、前進的意思,我認為在 TimeWheel 中,advance 用來表示“某個層級的時間有沒有流動”會更合適,以下是它的源碼:
final class TimerWheel implements Iterable> {
static final long[] SHIFT = {
Long.numberOfTrailingZeros(SPANS[0]),
Long.numberOfTrailingZeros(SPANS[1]),
Long.numberOfTrailingZeros(SPANS[2]),
Long.numberOfTrailingZeros(SPANS[3]),
Long.numberOfTrailingZeros(SPANS[4]),
};
long nanos;
public void advance(BoundedLocalCache cache, long currentTimeNanos) {
// nanos 總是記錄 advance 方法被調用時的時間
long previousTimeNanos = nanos;
nanos = currentTimeNanos;
// 校正時間戳的溢出
if ((previousTimeNanos < 0) && (currentTimeNanos > 0)) {
previousTimeNanos += Long.MAX_VALUE;
currentTimeNanos += Long.MAX_VALUE;
}
try {
// 遍歷所有層級,如果當前層級的時間沒有流動,則結束循環
// 因為所有的層級是按照時間遞增的順序排列的,如果低層級的時間都沒有流動,那么證明更高的層級時間更沒有流動了,比如秒級別時間沒變,那么分鐘級別的時間更不可能變
for (int i = 0; i < SHIFT.length; i++) {
long previousTicks = (previousTimeNanos >>> SHIFT[i]);
long currentTicks = (currentTimeNanos >>> SHIFT[i]);
// 計算出某層級下時間的流動范圍
long delta = (currentTicks - previousTicks);
if (delta <= 0L) {
break;
}
// 如果當前層級的時間有流動,則調用 expire 方法
expire(cache, i, previousTicks, delta);
}
} catch (Throwable t) {
nanos = previousTimeNanos;
throw t;
}
}
}
我們接著看 expire 方法:
final class TimerWheel implements Iterable> {
final Node[][] wheel;
long nanos;
void expire(BoundedLocalCache cache, int index, long previousTicks, long delta) {
Node[] timerWheel = wheel[index];
int mask = timerWheel.length - 1;
// 計算要遍歷處理的槽位數量,假設 delta 不會出現負值(只有時間范圍超過 2^61 nanoseconds (73 years) 才會溢出)
int steps = Math.min(1 + (int) delta, timerWheel.length);
// 上一次 advance 的操作時間即為起始索引
int start = (int) (previousTicks & mask);
// 計算結果索引
int end = start + steps;
for (int i = start; i < end; i++) {
// 拿到桶中的哨兵節點,獲取到尾節點和頭節點
Node sentinel = timerWheel[i & mask];
Node prev = sentinel.getPreviousInVariableOrder();
Node node = sentinel.getNextInVariableOrder();
// 重置哨兵節點,意味著這個桶中的元素都需要被處理,該層級的時間有流逝,處理但不意味著有元素過期
sentinel.setPreviousInVariableOrder(sentinel);
sentinel.setNextInVariableOrder(sentinel);
// node != sentinel 表示 node 并不是哨兵節點,證明其中有元素需要被處理
while (node != sentinel) {
// 標記 next 節點的引用
Node next = node.getNextInVariableOrder();
// 將當前節點從雙向鏈表中斷開
node.setPreviousInVariableOrder(null);
node.setNextInVariableOrder(null);
try {
// 先拿元素的過期時間與當前操作時間比較,判斷有沒有過期,如果過期則會執行 evictEntry 方法,驅逐元素
if (((node.getVariableTime() - nanos) > 0)
|| !cache.evictEntry(node, RemovalCause.EXPIRED, nanos)) {
// 如果沒有過期則重新 schedule 節點,因為隨著時間的流逝,該節點可能會被重新分配到更低的時間層級中,以便被更好的管理過期時間
schedule(node);
}
node = next;
} catch (Throwable t) {
// 處理時發生異常,將節點重新加入到鏈表中
node.setPreviousInVariableOrder(sentinel.getPreviousInVariableOrder());
node.setNextInVariableOrder(next);
sentinel.getPreviousInVariableOrder().setNextInVariableOrder(node);
sentinel.setPreviousInVariableOrder(prev);
throw t;
}
}
}
}
}
expire 方法并不復雜,本質上是將未過期的節點重新執行 TimeWheel#schedule 方法,將其劃分到更精準的時間分層;將過期的節點驅逐,evictEntry 方法在 緩存之美:萬文詳解 Caffeine 實現原理 中已經介紹過了,這里就不再贅述了。
總結一下 TimeWheel 的流程:只有指定了 expireAfter 時間過期策略的緩存才會使用到時間輪。當元素被添加時,它的過期時間已經被計算好并賦值到 variableTime 字段中,根據當前元素的剩余有效期(variableTime - nanos)劃分它在具體的時間輪層級(wheel),隨著時間的流逝(advance),它所在的時間輪層級可能會不斷變化,可能由小時級別被轉移(schedule)到分鐘級,當然它也可能過期直接被驅逐(evictEntry)。這樣操作按照元素剩余有效期將其劃分到更精準的時間層級中,可以更精準的控制元素的過期時間,比如秒級時間沒有流逝的話,那么便無需檢查分鐘級或更高時間跨度級別的元素是否過期。Caffeine 緩存完整的原理圖如下:
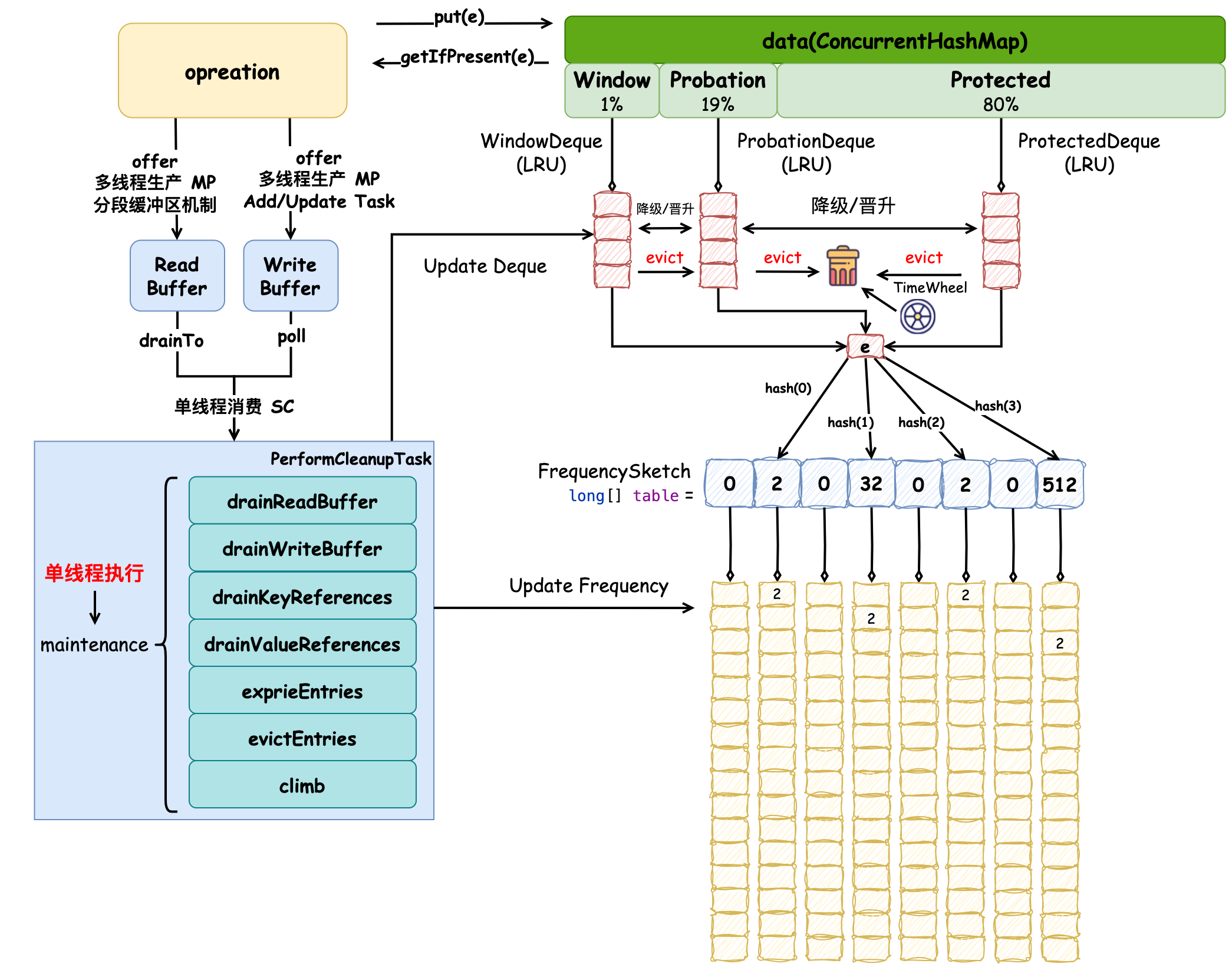
詳細了解需要結合 緩存之美:萬文詳解 Caffeine 實現原理。
審核編輯 黃宇
-
源碼
+關注
關注
8文章
685瀏覽量
31348 -
PUT
+關注
關注
0文章
6瀏覽量
6442
發布評論請先 登錄
KeepAlive:組件緩存實現深度解析
C語言的緩沖區(緩存)詳解
ESP32 編譯過程中 bootloader 配置階段的 CMake 緩存沖突錯誤,記錄
DES輪密鑰產生模塊結構設計
緩存之美:萬文詳解 Caffeine 實現原理(上)
高性能緩存設計:如何解決緩存偽共享問題
輪邊驅動電機專利技術發展
輪邊電機驅動汽車性能仿真與控制方法的研究
請問如何增大usb3.0從設備fifo接口固件中的寫dma緩存大小?
MCU緩存設計
Nginx緩存配置詳解
高速SSD存儲系統中數據緩存控制器整體頂層設計



 工商網監
工商網監
評論