 進迭時空同構融合技術加速大模型AI應用創新
進迭時空同構融合技術加速大模型AI應用創新

同構融合技術
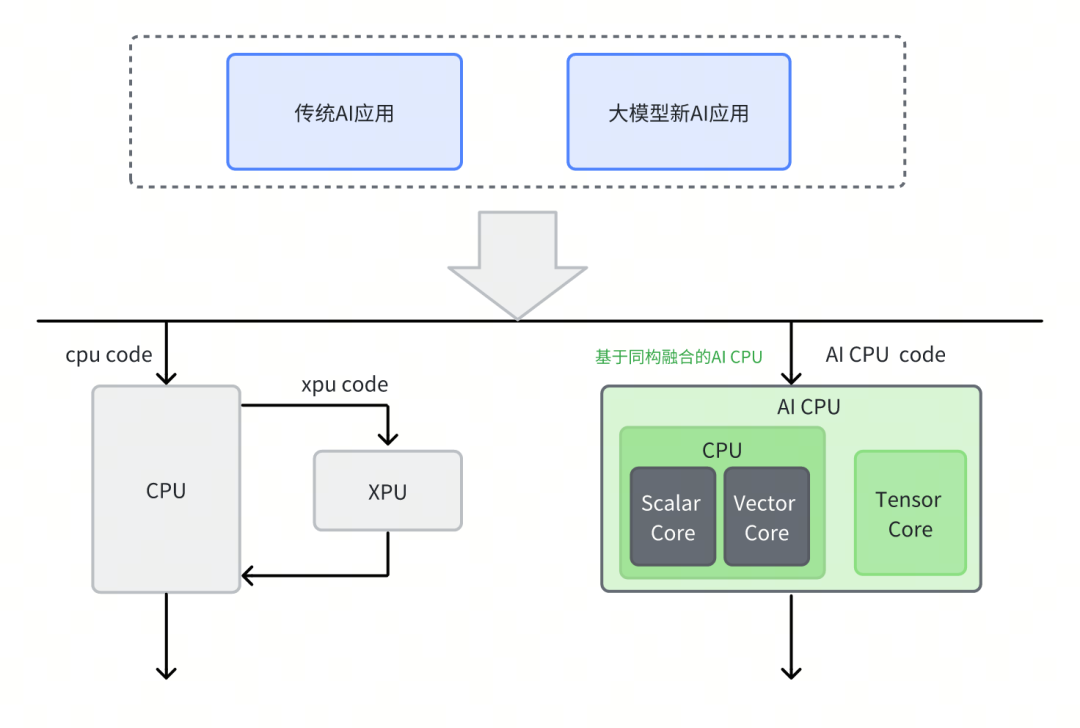
為了加速AI計算,芯片企業設計了多種專用處理器架構,如GPGPU、NPU、TPU等。這些專用處理器架構在執行調度代碼及應用層代碼時,需要主控CPU的配合,如下圖所示。因此,通常需要構建復雜的異構調度系統來協調CPU和XPU的額外數據交互和同步。
進迭時空踐行的同構融合技術,創新性地在CPU內集成TensorCore,以RISC-V指令集為統一的軟硬件接口,驅動Scalar標量算力、Vector向量算力和 Matrix AI算力,支持軟件和AI模型同時在RISC-V AI核上運行,并通過程序正常跳轉實現軟件和AI模型之間的事件和數據交互,進而完成整個AI應用執行。我們將這種使用同構融合技術,得到具有AI算力的CPU稱為AI CPU。
同構融合技術以更輕的軟件基礎設施構建接近Nvidia的軟件層級
雖然市面上已有多種不同架構且硬件做的非常出色的AI加速器,但是除了AIOT細分場景之外,Nvidia占據了AI計算絕大多數市場份額,成為AI計算主流架構,并深刻影響工業界學術界AI計算的發展。Nvidia通過CUDA將異構開發的門檻降至最低,并基于多層級的軟件棧構建了護城河。基于這些軟件棧,全球開發者都在壯大Nvidia生態。很多企業的GPGPU發展策略是硬件上學習Nvidia,軟件上兼容CUDA生態。由于很難跟上Nvidia的快速迭代,這條路徑并不容易實現。
同構融合有望成為新的發展路徑。相比于異構加速器和CPU的組合,同構融合技術在硬件層面上對AI算力和通用CPU進行了更高層次的封裝,用戶不需要關心主控CPU和異構加速器之間的數據同步,并且保留了通用CPU的調試和開發方式。廠商不需要開發復雜的異構調度系統,也不需要開發額外的驅動管理就可以讓開發者便捷的使用AI算力。另外,同構融合技術中CPU的通用性和RISC-V架構良好的開源生態基礎,進一步降低了需要自建軟件棧的復雜度。
綜上,進迭時空基于開源軟件生態,以更輕的基礎軟件設施,構建了接近Nvidia的軟件層級,如下圖所示。我們的目標是,基于這些軟件層級,達到接近Nvidia的AI通用性。
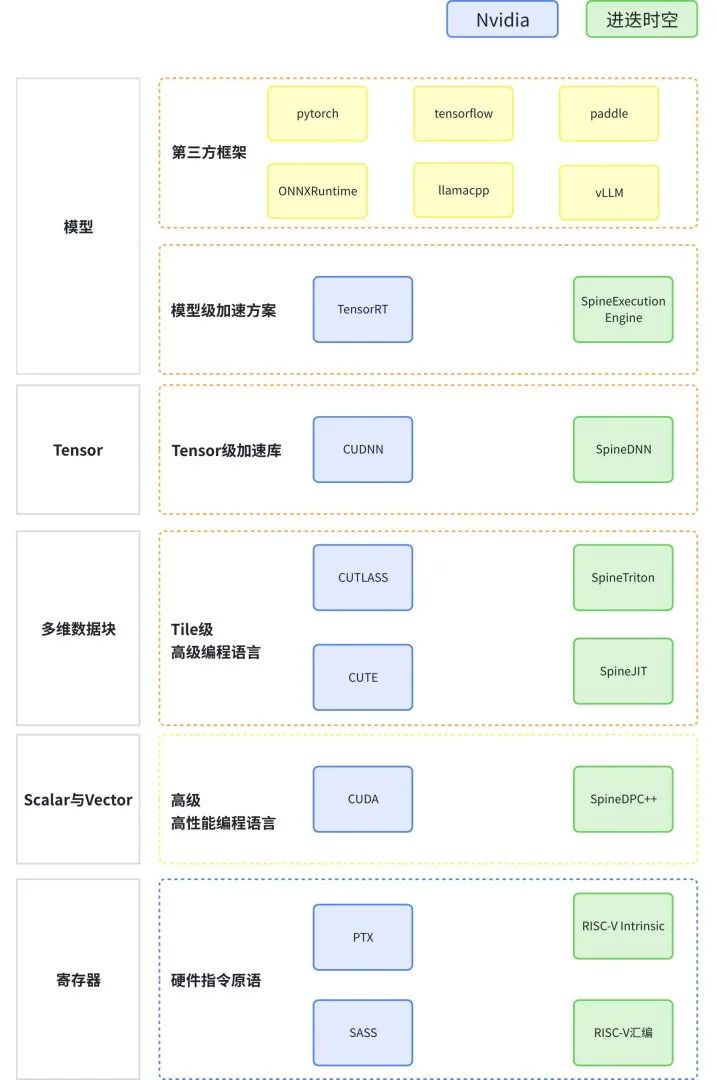
1 | 在模型加速層面,與Nvidia一樣,進迭時空的推理引擎可以非常便捷的接入各主流第三方框架 |
2 | 在Tensor及多維數據塊層面,SpineDNN、SpineTriton及SpineJit分別對標CUDNN、CUTLASS及CUTE |
3 | 在Scalar及Vector層面,SpineDPC++可以對標CUDA |
4 | 最底層的寄存器層面,標準的Intrinsic接口則對標Nvidia的PTX接口 |
進迭時空同構融合技術實踐
進迭時空基于同構融合技術完成兩代通用RISC-V AI核的研發。
第一代RISC-V AI核A60實現2Tops算力,支持INT8等數據格式。A60核已經應用于RISC-V AI CPU芯片K1,實踐表明,同構融合AI算力可以無縫運行所有AI算法,更安全地加速從TEE到REE所有AI應用。RISC-V AI CPU芯片K1也是第一個完整提供Scalar、Vector和Matrix三個維度關鍵算力的RISC-V芯片。在運行常見的AI算法時,K1的實際性能是傳統芯片的3-5倍,某些AI應用幀率提升可達10倍以上。
尤其是在運行大模型算法時,Matrix算力可以從容應對prefill階段的算力需求,CPU出色的訪存系統可以解決decode階段的帶寬需求,無需構建復雜的異構計算調度系統。此外,由于CPU的通用性,可以支持幾乎所有低bit量化方式,將帶寬需求降至最低。
更重要的是,將整個AI應用涉及的計算步驟全部遷移至AI CPU上,還可以為客戶提供更加簡單高效的開發方式。不僅能夠避免在多個硬件設備上開發和調試,而且在一個編程模型覆蓋AI開發全過程,能夠讓部署和調試變得輕松,讓算法快速實現價值。例如,K1芯片在客戶場景下,可以把在傳統NPU上適配新算法所需的3-6個月時間壓縮到1周以內,K1芯片已支持多個客戶在語音和機器視覺領域快速開發了基于最新AI大模型的產品。
第二代RISC-V AI核A100已經研發完畢,預期無論在大模型運行效率方面,還是運行傳統AI效率方面都能達到業界先進水平。
此外在算力堆疊方面,同構融合技術路線通過采用Core-to-Core coherence和Cluster-to-Cluster coherence,能以與GPU相同的技術實現多芯片級聯和算力堆疊。與總線的Die2Die一致性技術結合后,通往多芯片算力堆疊的規模有望接近現有最先進GPU集群。
同構融合技術適合運行MoE大模型
MOE模型(Mixture of Experts,混合專家模型)是一種基于分而治之策略的神經網絡架構,它將復雜的問題分解為多個子問題,每個子問題由一個獨立的模型(稱為專家)進行處理。MOE模型在單請求推理場景,每個token只需要使用部分專家參與計算。這些專家共同組成了MOE模型的激活參數。以DeepSeek-R1模型為例,671B的模型,只有37B的激活參數。對于FP8的模型,相當于需要將近700GB的容量來存放模型所有的權重,但是在進行單請求推理時,每個token只需要使用將近40GB的權重。相比于Dense模型,MOE模型是一個大容量,弱帶寬的推理需求。相較于GDDR和HBM,內存容量更容易擴展;再加上專家的選擇是動態的,其計算和訪存模式是CPU極其擅長的。
GPU與NPU適合密集的重復計算模式,而CPU適合復雜調度場景下的計算模式,AI CPU介于兩者之間。MoE的興起,代表了一個兼具大容量與復雜邏輯的大模型發展趨勢,而這正是AI CPU的發力場景。
-
AI
+關注
關注
91文章
40448瀏覽量
302068 -
大模型
+關注
關注
2文章
3705瀏覽量
5227 -
進迭時空
+關注
關注
0文章
63瀏覽量
604
發布評論請先 登錄
進迭時空發布新一代RISC-V AI CPU芯片,滿足端側大模型算力需求
進迭時空2025年度十大開發者揭曉

聚勢前行,攜手共進|進迭時空亮相 ICCAD-Expo 2025

進迭時空雙周報(20251022-1121)

取之于開源,貢獻于開源:進迭時空AI計算生態開源貢獻
十萬元獎金池!首屆全國RISC-V高水平創新及應用大賽火熱進行中

進迭時空與青少年共赴RISC-V AI科技未來!
芯活力,搏未來——2025進迭時空應屆生入職培訓
迎接泛機器人時代:進迭時空如何以RISC-V架構數智未來
高校賽事 | 進迭時空攜手藍橋杯,誠邀全國高校學子共啟RISC-V人工智能應用創新賽道
大象機器人攜手進迭時空推出 RISC-V 全棧開源六軸機械臂產品
大象機器人×進迭時空聯合發布全球首款RISC-V全棧開源小六軸機械臂




 工商網監
工商網監
評論