 PPTAgent: 大模型驅動的PPT自動生成
PPTAgent: 大模型驅動的PPT自動生成

論文題目
PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides
論文鏈接
https://arxiv.org/abs/2501.03936
項目倉庫
https://github.com/icip-cas/PPTAgent
演示視頻
在數字化時代,演示文稿(PPT)作為信息傳遞的重要媒介,其自動化生成需求愈發迫切。然而,一份優秀的演示文稿不僅需要引人入勝的故事線,還需要抓人眼球的視覺效果和內容的有效組織,這對創作者提出了極高的要求。針對這一挑戰,中國科學院軟件研究所中文信息處理實驗室提出了一種突破性的演示文稿自動生成框架 PPTAgent。
不同于傳統的端到端生成方法,PPTAgent 借鑒了人類創作 PPT 的過程,采用基于編輯的工作流程。正如經驗豐富的演講者往往會參考優秀的演示文稿來優化自己的作品,PPTAgent 也通過分析和編輯參考演示文稿來生成新的內容。
PPTAgent 設計的框架包含兩個關鍵階段:首先是“演示文稿分析”階段,系統會深入分析作為參考的演示文稿,提取每張幻燈片的語義信息。隨后在“演示文稿生成”階段,系統首先會基于文檔內容生成詳細的演示大綱,并為每張幻燈片分配合適的參考模板及相關文檔段落。對于待生成的每張幻燈片,PPTAgent 能夠根據輸入內容自動調整幻燈片參考模板中的文本和視覺元素,通過生成的代碼指令來完成元素的創建、編輯和刪除等操作。通過這種方式,PPTAgent 不僅確保了生成內容的連貫性,還保持了視覺設計的美觀度。
同時,我們還提出了首個全面的演示文稿評估框架 PPTEval,從內容、設計和結構連貫性三個維度評估演示文稿的質量,為自動化生成技術的改進提供了細粒度的反饋。實驗結果表明,PPTAgent 能夠生成高質量的演示文稿,在 PPTEval 的評估中取得了 3.67 的平均得分,并在來自不同領域的實驗數據上展現出了 97.8%的任務成功率。
PPTAgent
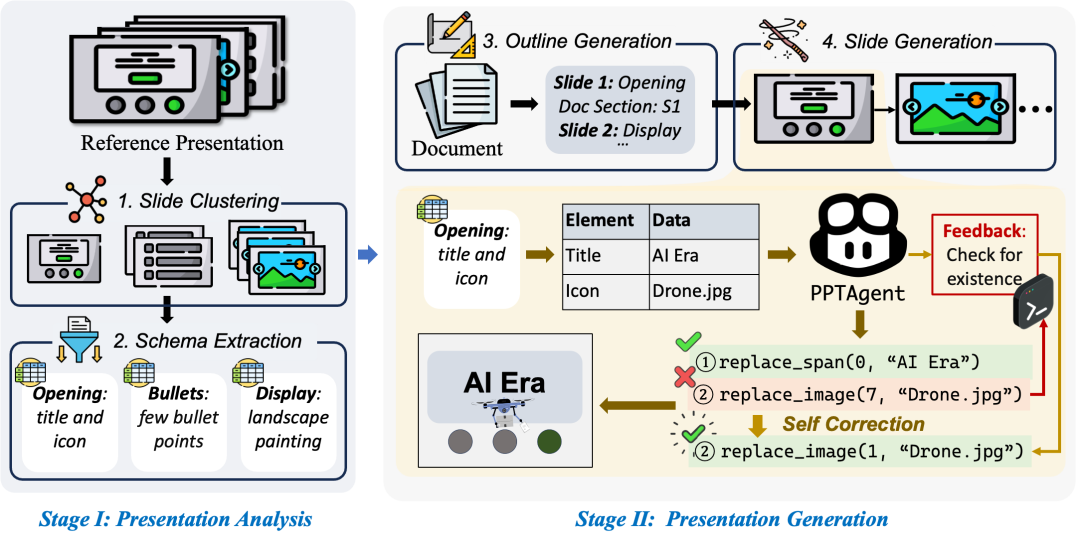
階段一:演示文稿分析 在這個階段,PPTAgent 首先對參考演示文稿進行全面分析以提取其中包含的語義信息。具體來說:
根據功能將幻燈片分為兩大類:支持演示結構的幻燈片(如開場頁)和傳遞具體內容的幻燈片(如要點頁)。針對不同類型,PPTAgent 采用基于圖片相似度或大語言模型的方法對參考演示文稿中的幻燈片進行聚類,并利用大語言模型的上下文感知能力對該頁的功能進行描述。
考慮到現實世界中幻燈片內容的復雜性和碎片性,我們利用大語言模型進一步地提取幻燈片的內容模式(schema),包括幻燈片元素的類別、形式和具體內容。這些信息為后續的編輯過程提供了重要指導。
階段二:演示文稿生成
在生成階段,我們采用了基于編輯的生成范式,具體流程包括:
首先根據上一階段分析得到的幻燈片語義信息和輸入文檔生成結構化大綱,為新演示文稿中的每張幻燈片指定參考模板和輸入文檔中的相關內容。
基于我們設計的 API 接口,生成可執行的代碼指令來對幻燈片中的元素進行編輯修改。此外,我們還引入了實時的錯誤反饋機制,系統能夠根據執行過程中的錯誤反饋進行自我糾正,顯著提高了生成的穩定性。
PPTEval:基于 LLM-as-a-Judge 范式的幻燈片質量評估
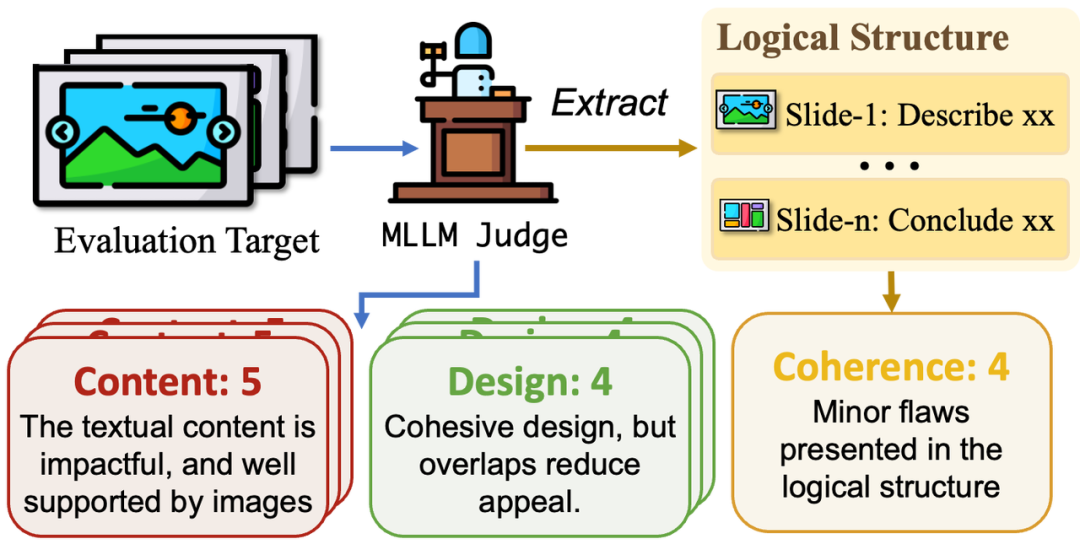
此外,為了能夠有效和全面地評估生成幻燈片的質量,我們還開發了 PPTEval 評估框架,利用大語言模型來從三個維度對演示文稿進行全面評估:
內容(Content):評估幻燈片中文本和圖像的相關度、文本內容信息量和質量,確保傳達的信息簡潔、準確且具備實用性。
設計(Design):關注幻燈片的色彩搭配、視覺元素的使用和整體設計的專業性,確保視覺呈現和內容相輔相成。
連貫性(Coherence):評估幻燈片的邏輯結構和上下文信息的完整性,確保內容流暢且符合邏輯,觀眾易于理解。
實驗
數據集
為了全面評估 PPTAgent 的性能,我們首先構建了一個包含 10,448 份多領域演示文稿的數據集 Zenodo10K,這也是目前已知最大的幻燈片數據集。在此基礎上,我們在三個常用的大語言模型:GPT-4o、Qwen2.5-72B(Qwen2.5)和 Qwen2-VL-72B(Qwen2-VL)上進行了實驗。
實驗結果
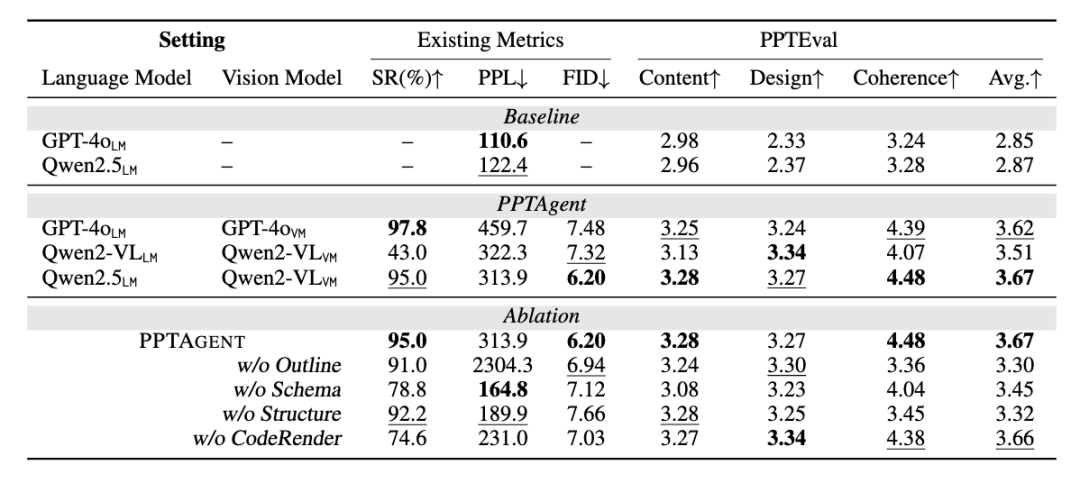
超高的生成成功率:PPTAgent 展現出卓越的魯棒性,使用 GPT-4o 或 Qwen2.5+Qwen2-VL 組合時,均實現了超過 95%的生成成功率。這一成績遠超此前模板編輯任務僅有 10%的成功率。
全方位的質量提升:與基線方法相比,PPTAgent 在幻燈片的各個維度都取得了顯著進步:
設計維度得分提升 40%(3.24 vs 2.33)
連貫性維度提升 34%(4.39 vs 3.28)
內容質量提升 9%(3.25 vs 2.98)
開源模型的出色表現:值得一提的是,Qwen2.5 與 Qwen2-VL 的組合有效地克服了 Qwen2-VL 在語言處理方面的局限性,其整體表現也達到了與 GPT-4o 相當的水平,展現了開源大模型在專業領域的應用潛力。
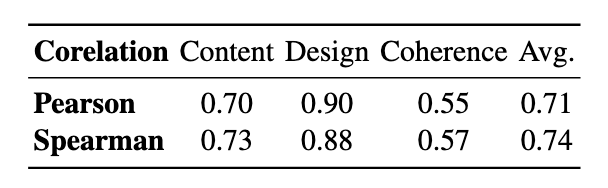
評估結果的可靠性驗證:為確保評估結果的可靠性,我們將 PPTEval 的評估結果與人工評估進行了一致性分析。分析結果表明,PPTEval 在三個維度上的平均皮爾遜相關系數為 0.71,顯示其能夠有效地代替人類評估幻燈片的質量。
總結
通過這項研究,我們將演示文稿的自動生成重新定義為一個基于編輯的兩階段任務。PPTAgent 充分利用了大語言模型對代碼的理解和生成能力,通過分析參考演示文稿的文本特征和布局模式,有效地組織和生成新的演示文稿。在多個領域的實驗驗證中,PPTAgent 都能夠魯棒地生成高質量幻燈片。同時,我們提出的 PPTEval 評估框架為演示文稿生成任務提供了可靠的評估手段,為該領域的未來發展奠定了重要基礎。 這項技術有望開創一種全新的無監督演示文稿生成范式,為未來研究提供了新的思路。通過這項技術,我們期待能夠幫助更多人高效地創作專業的演示文稿,讓信息傳遞變得更加便捷。最后,通過開源的 PPTAgent、PPTEval 和大規模幻燈片數據集 Zenodo10K,我們希望能夠推動整個領域的發展,激發更多創新性的研究成果。
-
ppt
+關注
關注
1文章
48瀏覽量
18226 -
大模型
+關注
關注
2文章
3650瀏覽量
5179
原文標題:PPTAgent: 大模型驅動的PPT自動生成,解放打工人
文章出處:【微信號:gh_e5b9d8c5c1d4,微信公眾號:中科院軟件所中文信息處理實驗室】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何構建適合自動駕駛的世界模型?

生成式AI浪潮如何驅動車載通信模組升級
大模型支撐后勤保障方案生成系統軟件平臺
大模型支撐后勤保障方案生成系統:功能特點與平臺架構解析
五大大模型支撐后勤保障方案生成系統軟件的應用與未來發展
世界模型是讓自動駕駛汽車理解世界還是預測未來?

pdf轉換ppt怎么轉換
不只有AI協作編程(Vibe Coding):生成式系統級芯片(GenSoC)將如何把生成式設計推向硬件層面
VLA和世界模型,誰才是自動駕駛的最優解?
真正免費的AI生成PPT工具盤點:告別收費陷阱
如何讓大模型生成你想要的測試用例?

小紅書:通過商品標簽API自動生成內容標簽,優化社區推薦算法

生成式 AI 重塑自動駕駛仿真:4D 場景生成技術的突破與實踐




 工商網監
工商網監
評論