 英特爾助力百度智能云千帆大模型平臺加速LLM推理
英特爾助力百度智能云千帆大模型平臺加速LLM推理

“大模型在各行業的廣泛應用驅動了新一輪產業革命,也凸顯了在AI算力方面的瓶頸。通過攜手英特爾釋放英特爾 至強 可擴展處理器的算力潛力,我們為用戶提供了高性能、靈活、經濟的算力基礎設施方案,結合千帆大模型平臺在大模型工具鏈、豐富的預置模型等方面的升級,我們將進一步推動大模型技術在各行各業的廣泛應用,為企業智能化提供更多可能性。”
—— 謝廣軍
百度副總裁
“百花齊放的大模型時代呼喚著更加經濟、可及的AI算力資源,通過百度智能云千帆大模型平臺,用戶能夠快捷、高效地部署基于CPU的LLM推理服務,并發揮英特爾 至強 可擴展處理器在AI推理方面的巨大價值。我們將進一步加速大模型的生態建設與軟硬件創新,助力更多的用戶利用大模型推動業務創新。”
—— 陳葆立
中國區總經理
概 述
以文心大模型、Llama、GPT和ChatGLM為代表的大語言模型(LLM)展示了人工智能(AI)的驚人潛力,其在藝術創作、辦公、娛樂、生產方面的廣泛應用激發了新一輪的產業革命。雖然LLM在各種自然語言處理任務中表現優越,但也帶來了巨量的算力資源消耗。目前機器學習開源框架如PyTorch等雖然支持基于CPU平臺執行計算,但CPU上的算力并沒有被充分挖掘,通用框架軟件基于CPU硬件的優化程度欠佳,其推理性能并不能滿足真實業務的吞吐和時延需求。
百度智能云千帆大模型平臺是一個面向開發者和企業的人工智能服務平臺。它為開發者提供了豐富的人工智能模型和算法,尤其是豐富的LLM支持,能夠幫助用戶構建各種智能應用。為了提升基于CPU的LLM推理性能,百度智能云利用英特爾 至強 可擴展處理器搭載的英特爾 高級矩陣擴展(英特爾 AMX)等高級硬件能力,助力千帆大模型平臺在CPU端的推理加速。
挑戰:LLM推理帶來算力、資源利用率等挑戰
目前開源的LLM網絡結構主要以Transformer子結構為基礎模塊,其推理解碼的過程是一個自回歸的過程,當前詞的生成計算依賴于所有前文的計算結果。LLM推理過程中涉及大量的、多維度的矩陣乘法計算,在不同參數量級模型、不同并發、不同數據分布等場景下,模型推理的性能瓶頸可能在于計算或者帶寬,為了保證模型生成的吞吐和時延,對硬件平臺的算力和訪存帶寬都會提出較高的要求。
目前,行業還存在大量離線的LLM應用需求,如生成文章總結、摘要、數據分析等,與在線場景相比,離線場景通常會利用平臺的閑時算力資源,對于推理的時延要求不高,而對于推理的成本較為敏感,因此用戶更加傾向采用低成本、易獲得的CPU來進行推理。百度智能云等云平臺中部署著大量基于CPU的云服務器,釋放這些CPU的AI算力潛力將有助于提升資源利用率,滿足用戶快速部署LLM模型的需求。
此外,對于30B等規模的LLM,需要采用高規格的GPU來進行推理,普通GPU無法支持。但是,高規格的GPU的成本較高、供貨緊缺,對于離線場景的用戶來說不是一個理想的選擇。而針對該場景,CPU不僅可以很好地支持30B及以下規模的模型,而且在性價比上更具優勢。
解決方案:千帆大模型采用英特爾至強可擴展處理器加速LLM推理
百度智能云千帆大模型平臺為企業提供大模型全生命周期工具鏈和整套環境,用戶可以在百度智能云千帆上開發、訓練、部署和調用自己的大模型服務。其提供智能計算基礎設施、豐富的大模型、數據集和精選應用范式,以及包含數據管理、模型訓練、評估和優化、推理服務部署、Prompt工程等大模型全生命周期工具鏈,能夠顯著提升模型精調效果和應用集成效率。
?覆蓋大模型全生命周期:提供數據標注,模型訓練與評估,推理服務與應用集成的全面功能服務;
?推理能力大幅提升:可充分釋放CPU、GPU等硬件的推理性能潛力,算力利用率大幅提升,滿足不同規模模型的推理所需;
?快速應用編排與插件集成:預置百度文心大模型與國內外主流大模型,支持插件與應用靈活編排,助力大模型多場景落地應用。
百度智能云千帆大模型平臺可以利用百度智能云平臺中豐富的英特爾 至強 可擴展處理器資源,加速LLM模型的推理,滿足LLM模型實際部署的需求。
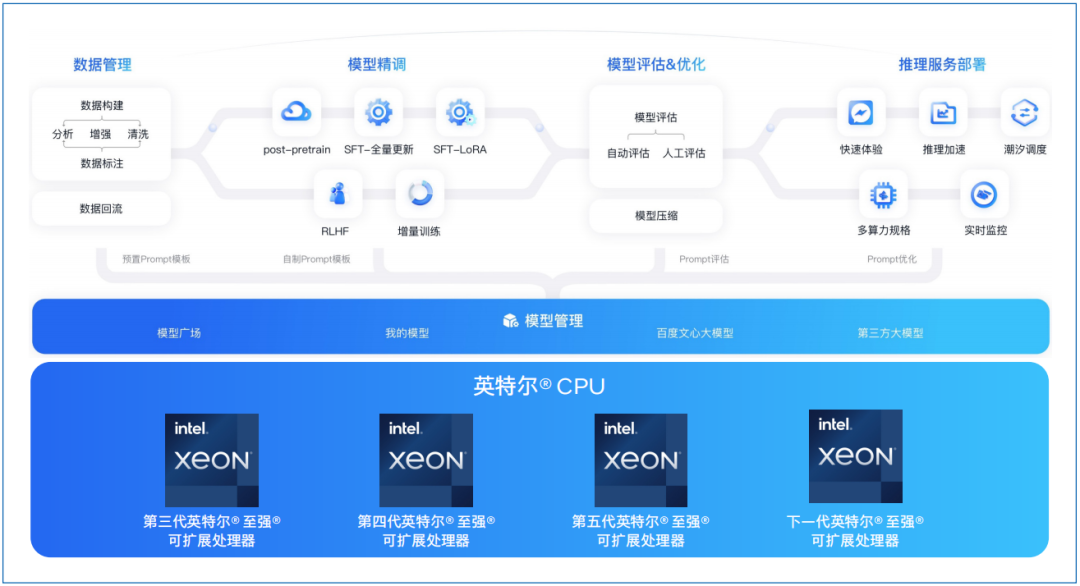
圖1. 百度智能云千帆大模型平臺支持的英特爾 CPU
新一代英特爾 至強 可擴展處理器通過創新架構增加了每個時鐘周期的指令,有效提升了內存帶寬與速度,并通過PCIe 5.0實現了更高的PCIe帶寬提升。英特爾 至強 可擴展處理器提供了出色性能和安全性,可根據用戶的業務需求進行擴展。借助內置的加速器,用戶可以在AI、分析、云和微服務、網絡、數據庫、存儲等類型的工作負載中獲得優化的性能。通過與強大的生態系統相結合,英特爾 至強 可擴展處理器能夠幫助用戶構建更加高效、安全的基礎設施。
第四代和第五代英特爾 至強 可擴展處理器中內置了英特爾 AMX加速器,可優化深度學習(DL)訓練和推理工作負載。英特爾 AMX架構由兩部分組件構成:第一部分為TILE,由8個1KB大小的2D寄存器組成,可存儲大數據塊。
第二部分為平鋪矩陣乘法(TMUL),它是與TILE連接的加速引擎,可執行用于AI的矩陣乘法計算。英特爾 AMX支持INT8和BF16兩種數據類型以滿足不同精度的加速需求。AMX讓英特爾 至強 可擴展處理器實現了大幅代際性能提升,與內置英特爾 高級矢量擴展512矢量神經網絡指令(Intel Advanced Vector Extensions 512 Vector Neural Network Instructions,英特爾 AVX-512 VNNI)的第三代英特爾 至強 可擴展處理器 相比,內置英特爾 AMX的第四代英特爾 至強 可擴展處理器將單位計算周期內執行INT8運算的次數從256次提高至2048次,是AVX512_VNNI同樣數據類型的8倍。
英特爾 至強 可擴展處理器可支持High Bandwidth Memory(HBM)內存,高帶寬內存HBM和DDR5相比,具有更多的訪存通道和更長的讀取位寬,理論帶寬可達DDR5的4倍。雖然HBM的容量相對較小(每個CPU Socket 64 GB),每個物理核心僅可以平均獲得超過1GB的高帶寬內存容量,但對于包括大模型推理任務在內的絕大多數計算任務,HBM可以容納全部的權重數據,顯著提升訪存限制型的計算任務。經實測,在真實的大模型推理任務上可以實現明顯的端到端加速。
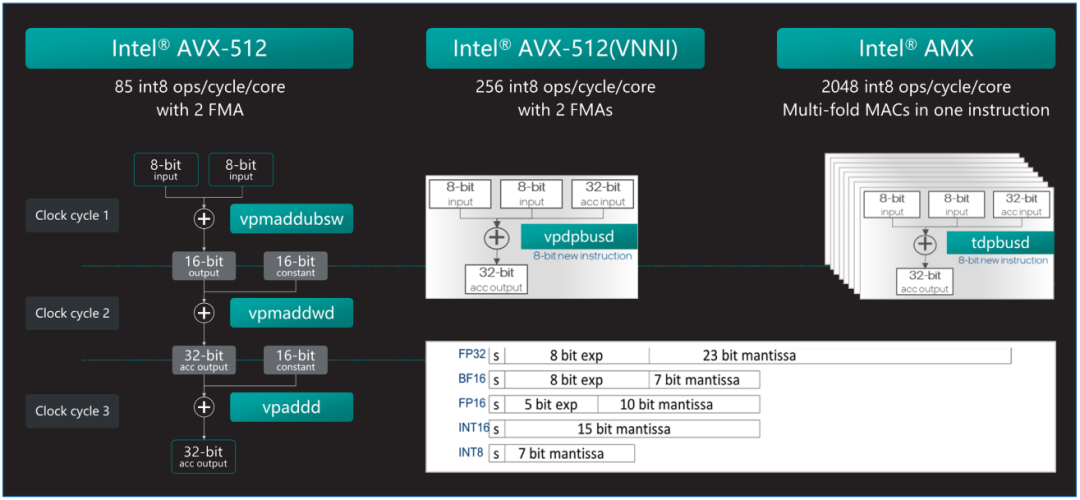
圖2. 英特爾 AMX可以更高效的實現AI加速
百度智能云千帆大模型平臺采用基于AMX加速器和HBM硬件特性極致優化的大模型推理軟件解決方案xFasterTransformer(xFT),進一步加速英特爾 至強 可擴展處理器的LLM推理速度。軟件架構的詳細信息如圖3所示,其具備如下優勢:
?通過模型轉換工具,xFT實現了對HuggingFace上開源模型格式的全面支持。
?軟件的核心高性能計算庫包括oneDNN、MKL以及針對LLM特別優化的計算實現,這些高性能計算庫把對AMX/AVX512等加速部件的相關實現進行隱藏,上層的LLM基礎算子實現以及網絡層的實現都建立在此基礎之上,形成了軟件和硬件特性的解耦。
?最上層提供C++以及Python接口方便測試,且由于全部的核心代碼均基于C++實現,因此集成進現有的框架非常便捷。
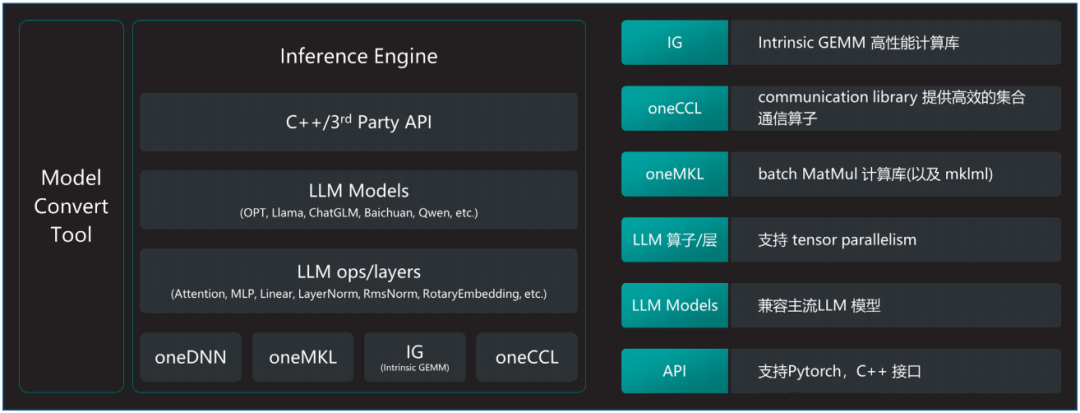
圖3. 英特爾 至強 可擴展處理器LLM推理軟件解決方案
具體的優化策略如下:

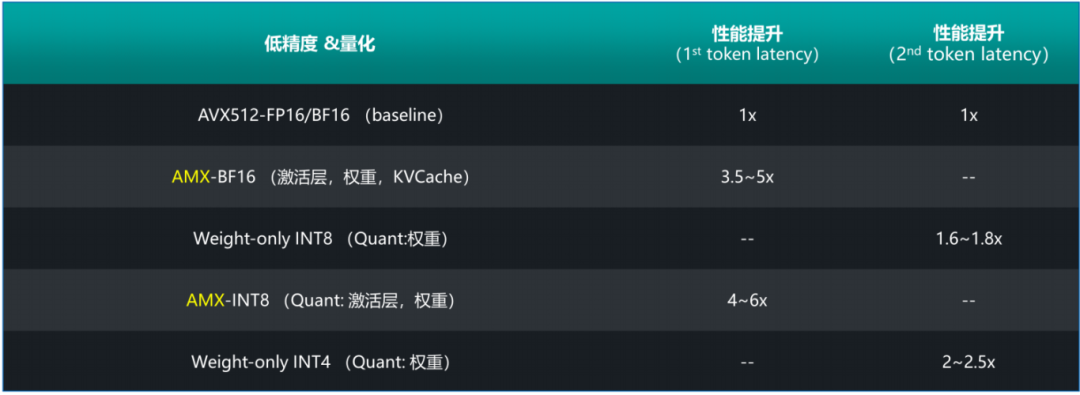
圖4. 將模型轉化為低精度數據格式可帶來性能提升
在千帆大模型平臺上實現CPU推理加速
當前千帆大模型平臺已經引入了針對英特爾 至強 可擴展平臺深度優化的LLM推理軟件解決方案xFT,并將其作為后端推理引擎,助力用戶在千帆大模型平臺上實現基于CPU的LLM推理加速。目前,使用該方案針對超長上下文和長輸出進行了優化,已經支持Llama-2-7B/13B,ChatGLM2-6B等模型部署在線服務(參見表1)。
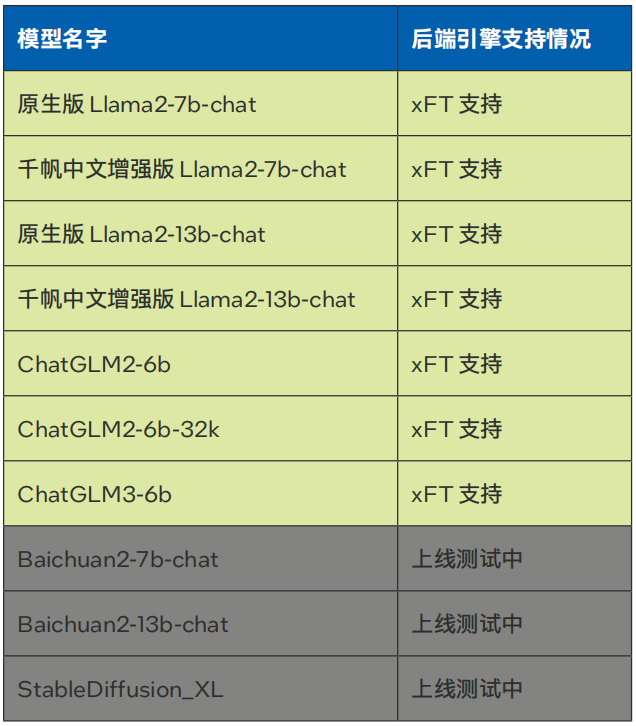
表1. 百度智能云千帆大模型平臺xFasterTransformer后端支持模型種類
Llama-2-7b模型測試數據如圖5和圖6所示,第四代英特爾 至強 可擴展處理器上輸出Token吞吐可達100TPS以上,相比第三代英特爾 至強 可擴展處理器提升了60%。在低延遲的場景,同等并發下,第四代英特爾 至強 可擴展處理器的首Token時延比第三代英特爾 至強 可擴展處理器可降低50%以上。在將處理器升級為第五代英特爾 至強 可擴展處理器之后,吞吐可提升45%左右,首Token時延下降50%左右1 。
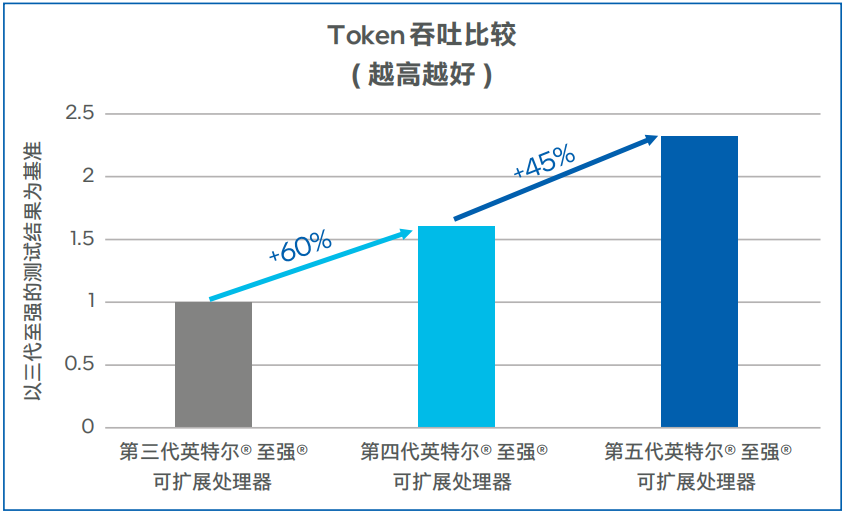
圖5. Llama-2-7b模型輸出Token吞吐
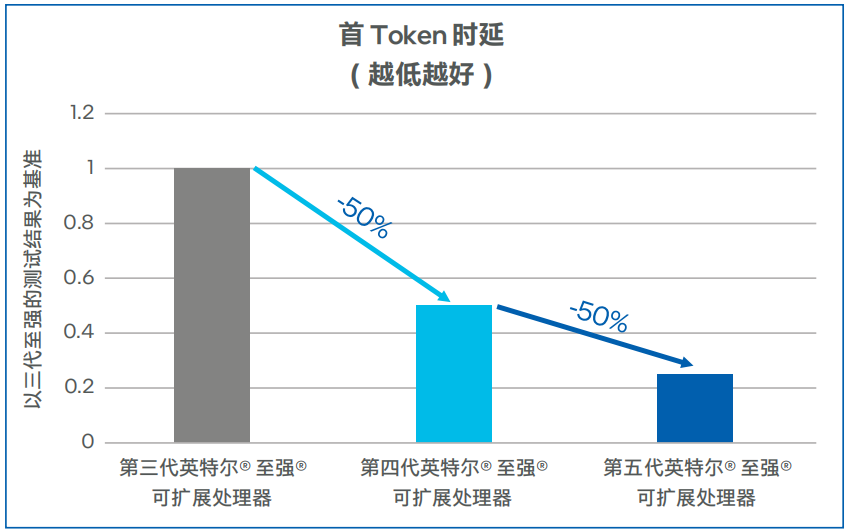
圖6. Llama-2-7b模型首Token時延
方案效果
通過在千帆大模型平臺中采用英特爾 至強 可擴展處理器進行LLM模型推理,方案效果如下:
?通過千帆大模型平臺提供的全生命周期工具鏈,快速在英特爾 至強 可擴展平臺中部署LLM模型推理服務;
?高效釋放英特爾 至強 可擴展處理器的AI推理性能,降低LLM生成時延,提供更佳的服務體驗;
?針對30B以下規模的LLM模型,皆可采用英特爾 至強 可擴展處理器結合xFT推理解決方案,獲得良好性能體驗;
?利用充足的CPU資源,降低對于AI加速卡的需求,從而降低LLM推理服務的總體擁有成本(TCO),特別是在離線的LLM推理場景中表現出色。
展 望
通過xFasterTransformer等軟件方案,百度智能云千帆大模型平臺充分利用了英特爾 至強 可擴展處理器的計算能力以及新一代AI內置加速引擎英特爾 AMX,成功解決了大模型推理中的計算密集型和訪存受限型算子挑戰,實現了基于CPU的LLM推理加速,助力用戶更加高效地利用CPU資源。
未來,英特爾與百度將繼續深化合作,推動大模型平臺的發展,計劃進一步優化LLM推理算法和實現,提升推理性能和計算資源效率,使得更多類型和規模的大模型能夠在CPU平臺上得到支持和加速。同時,雙方將不斷完善軟硬件配套解決方案,提供更加全面和靈活的技術支持,滿足用戶在自然語言處理領域的不斷增長的需求。
-
處理器
+關注
關注
68文章
20255瀏覽量
252280 -
英特爾
+關注
關注
61文章
10301瀏覽量
180452 -
大模型
+關注
關注
2文章
3650瀏覽量
5183
原文標題:看至強? 可擴展處理器如何為千帆大模型平臺推理加速
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
有方科技攜手百度智能云重塑AI賦能新生態
光庭信息成為百度智能云大模型行業合伙人
昆侖芯科技亮相2025百度云智大會
英特爾Gaudi 2E AI加速器為DeepSeek-V3.1提供加速支持

硬件與應用同頻共振,英特爾Day 0適配騰訊開源混元大模型
百度智能云亮相第二十二屆ChinaJoy
如何在魔搭社區使用TensorRT-LLM加速優化Qwen3系列模型推理部署
65%央企大模型落地首選百度智能云

百度文心大模型X1 Turbo獲得信通院當前大模型最高評級證書

格靈深瞳與百度智能云達成戰略合作,共筑AI算力新基建
詳解 LLM 推理模型的現狀




 工商網監
工商網監
評論