") LLM和傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
LLM和傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別

在人工智能領(lǐng)域,LLM(Large Language Models,大型語言模型)和傳統(tǒng)機(jī)器學(xué)習(xí)是兩種不同的技術(shù)路徑,它們在處理數(shù)據(jù)、模型結(jié)構(gòu)、應(yīng)用場景等方面有著顯著的差異。
1. 模型結(jié)構(gòu)和訓(xùn)練方法
LLM:
- 預(yù)訓(xùn)練和微調(diào): LLM通常采用預(yù)訓(xùn)練(Pre-training)和微調(diào)(Fine-tuning)的方法。預(yù)訓(xùn)練階段,模型在大規(guī)模的文本數(shù)據(jù)上學(xué)習(xí)語言的通用特征,微調(diào)階段則針對特定任務(wù)進(jìn)行調(diào)整。
- Transformer架構(gòu): LLM多基于Transformer架構(gòu),這種架構(gòu)特別適合處理序列數(shù)據(jù),能夠有效捕捉長距離依賴關(guān)系。
- 自注意力機(jī)制: Transformer架構(gòu)中的自注意力機(jī)制使得模型能夠同時關(guān)注輸入序列中的所有位置,這對于理解上下文信息至關(guān)重要。
傳統(tǒng)機(jī)器學(xué)習(xí):
- 特征工程: 傳統(tǒng)機(jī)器學(xué)習(xí)模型通常需要人工進(jìn)行特征提取和特征選擇,這是一個耗時且需要專業(yè)知識的過程。
- 模型多樣性: 傳統(tǒng)機(jī)器學(xué)習(xí)包括多種模型,如決策樹、支持向量機(jī)、隨機(jī)森林等,每種模型都有其特定的應(yīng)用場景和優(yōu)勢。
- 監(jiān)督學(xué)習(xí): 許多傳統(tǒng)機(jī)器學(xué)習(xí)模型依賴于監(jiān)督學(xué)習(xí),需要大量的標(biāo)注數(shù)據(jù)來訓(xùn)練。
2. 數(shù)據(jù)依賴性
LLM:
- 數(shù)據(jù)驅(qū)動: LLM極度依賴于大量的數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,這些數(shù)據(jù)通常是未標(biāo)注的,模型通過自監(jiān)督學(xué)習(xí)來理解語言結(jié)構(gòu)和語義。
- 多模態(tài)數(shù)據(jù): 一些LLM也開始嘗試整合多模態(tài)數(shù)據(jù)(如圖像、聲音)來增強(qiáng)模型的理解和生成能力。
傳統(tǒng)機(jī)器學(xué)習(xí):
- 標(biāo)注數(shù)據(jù)依賴: 傳統(tǒng)機(jī)器學(xué)習(xí)模型,尤其是監(jiān)督學(xué)習(xí)模型,嚴(yán)重依賴于高質(zhì)量的標(biāo)注數(shù)據(jù)。
- 數(shù)據(jù)量要求: 傳統(tǒng)機(jī)器學(xué)習(xí)模型對數(shù)據(jù)量的要求不如LLM那么高,但數(shù)據(jù)的質(zhì)量和多樣性對模型性能有直接影響。
3. 應(yīng)用場景
LLM:
- 自然語言處理: LLM在自然語言處理(NLP)領(lǐng)域表現(xiàn)出色,包括文本生成、翻譯、問答系統(tǒng)等。
- 對話系統(tǒng): LLM能夠構(gòu)建更加自然和流暢的對話系統(tǒng),理解用戶的意圖并生成合適的回應(yīng)。
- 內(nèi)容創(chuàng)作: LLM可以用于自動生成文章、故事、詩歌等內(nèi)容,展現(xiàn)出強(qiáng)大的創(chuàng)造性。
傳統(tǒng)機(jī)器學(xué)習(xí):
- 預(yù)測和分類: 傳統(tǒng)機(jī)器學(xué)習(xí)模型廣泛應(yīng)用于預(yù)測和分類任務(wù),如股票價格預(yù)測、圖像識別等。
- 推薦系統(tǒng): 在推薦系統(tǒng)中,傳統(tǒng)機(jī)器學(xué)習(xí)模型能夠根據(jù)用戶的歷史行為推薦個性化內(nèi)容。
- 異常檢測: 傳統(tǒng)機(jī)器學(xué)習(xí)在異常檢測領(lǐng)域也有廣泛應(yīng)用,如信用卡欺詐檢測、網(wǎng)絡(luò)安全等。
4. 可解釋性和透明度
LLM:
- 黑箱問題: LLM通常被認(rèn)為是“黑箱”,因為它們的決策過程不透明,難以解釋模型是如何做出特定預(yù)測的。
- 可解釋性研究: 盡管存在挑戰(zhàn),但研究者正在探索各種方法來提高LLM的可解釋性,如注意力可視化、模型解釋等。
傳統(tǒng)機(jī)器學(xué)習(xí):
- 模型可解釋性: 傳統(tǒng)機(jī)器學(xué)習(xí)模型,尤其是決策樹和線性模型,通常具有較好的可解釋性。
- 特征重要性: 一些模型(如隨機(jī)森林)能夠提供特征重要性評分,幫助理解模型的決策依據(jù)。
5. 計算資源需求
LLM:
- 高計算需求: LLM需要大量的計算資源進(jìn)行訓(xùn)練和推理,這通常涉及到高性能的GPU和TPU。
- 能源消耗: LLM的訓(xùn)練和運行對能源消耗巨大,這也引發(fā)了對環(huán)境影響的擔(dān)憂。
傳統(tǒng)機(jī)器學(xué)習(xí):
- 資源需求較低: 相比LLM,傳統(tǒng)機(jī)器學(xué)習(xí)模型通常需要較少的計算資源,尤其是在模型訓(xùn)練階段。
- 可擴(kuò)展性: 傳統(tǒng)機(jī)器學(xué)習(xí)模型更容易在不同的硬件和平臺上部署,具有較好的可擴(kuò)展性。
6. 倫理和社會影響
LLM:
- 偏見和歧視: LLM可能會從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)并放大偏見和歧視,這需要通過數(shù)據(jù)清洗和模型調(diào)整來緩解。
- 隱私問題: LLM可能會無意中泄露訓(xùn)練數(shù)據(jù)中的敏感信息,需要采取隱私保護(hù)措施。
傳統(tǒng)機(jī)器學(xué)習(xí):
- 數(shù)據(jù)隱私: 傳統(tǒng)機(jī)器學(xué)習(xí)模型同樣面臨數(shù)據(jù)隱私問題,尤其是在處理個人數(shù)據(jù)時。
- 模型濫用: 任何強(qiáng)大的技術(shù)都可能被濫用,傳統(tǒng)機(jī)器學(xué)習(xí)模型也不例外,需要制定相應(yīng)的倫理準(zhǔn)則和監(jiān)管措施。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
人工智能
+關(guān)注
關(guān)注
1817文章
50094瀏覽量
265261 -
模型
+關(guān)注
關(guān)注
1文章
3751瀏覽量
52097 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136928 -
LLM
+關(guān)注
關(guān)注
1文章
346瀏覽量
1329
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
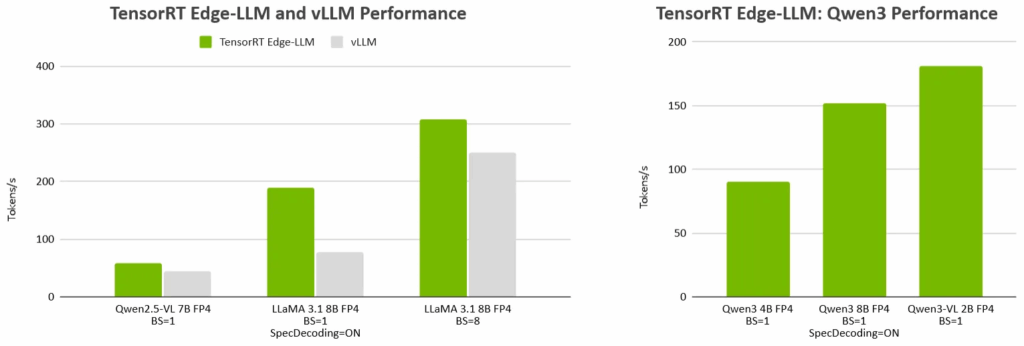
NVIDIA TensorRT Edge-LLM在汽車與機(jī)器人行業(yè)的落地應(yīng)用
大語言模型(LLM)與多模態(tài)推理系統(tǒng)正迅速突破數(shù)據(jù)中心的局限。越來越多的汽車與機(jī)器人領(lǐng)域的開發(fā)者希望將對話式 AI 智能體、多模態(tài)感知系統(tǒng)和高級規(guī)劃功能直接部署在端側(cè),因為在這些場景中,低延遲、高可靠性以及離線運行能力至關(guān)重要。
【CIE全國RISC-V創(chuàng)新應(yīng)用大賽】+ 一種基于LLM的可通過圖像語音控制的元件庫管理工具
一種基于LLM的可通過圖像語音控制的元件庫管理工具
項目概述
? 庫存管理在我們的生活中幾乎無處不在,在許多小型的庫存當(dāng)中,比如實驗室中的庫存管理,往往沒有人去專職維護(hù),這就會導(dǎo)致在日積月累中逐漸
發(fā)表于 11-12 19:32
NVIDIA TensorRT LLM 1.0推理框架正式上線
TensorRT LLM 作為 NVIDIA 為大規(guī)模 LLM 推理打造的推理框架,核心目標(biāo)是突破 NVIDIA 平臺上的推理性能瓶頸。為實現(xiàn)這一目標(biāo),其構(gòu)建了多維度的核心實現(xiàn)路徑:一方面,針對需
TensorRT-LLM的大規(guī)模專家并行架構(gòu)設(shè)計
之前文章已介紹引入大規(guī)模 EP 的初衷,本篇將繼續(xù)深入介紹 TensorRT-LLM 的大規(guī)模專家并行架構(gòu)設(shè)計與創(chuàng)新實現(xiàn)。

量子機(jī)器學(xué)習(xí)入門:三種數(shù)據(jù)編碼方法對比與應(yīng)用
在傳統(tǒng)機(jī)器學(xué)習(xí)中數(shù)據(jù)編碼確實相對直觀:獨熱編碼處理類別變量,標(biāo)準(zhǔn)化調(diào)整數(shù)值范圍,然后直接輸入模型訓(xùn)練。整個過程更像是數(shù)據(jù)清洗,而非核心算法組件。量子機(jī)器

FPGA在機(jī)器學(xué)習(xí)中的具體應(yīng)用
隨著機(jī)器學(xué)習(xí)和人工智能技術(shù)的迅猛發(fā)展,傳統(tǒng)的中央處理單元(CPU)和圖形處理單元(GPU)已經(jīng)無法滿足高效處理大規(guī)模數(shù)據(jù)和復(fù)雜模型的需求。FPGA(現(xiàn)場可編程門陣列)作為一種靈活且高效的硬件加速平臺
如何在魔搭社區(qū)使用TensorRT-LLM加速優(yōu)化Qwen3系列模型推理部署
TensorRT-LLM 作為 NVIDIA 專為 LLM 推理部署加速優(yōu)化的開源庫,可幫助開發(fā)者快速利用最新 LLM 完成應(yīng)用原型驗證與產(chǎn)品部署。
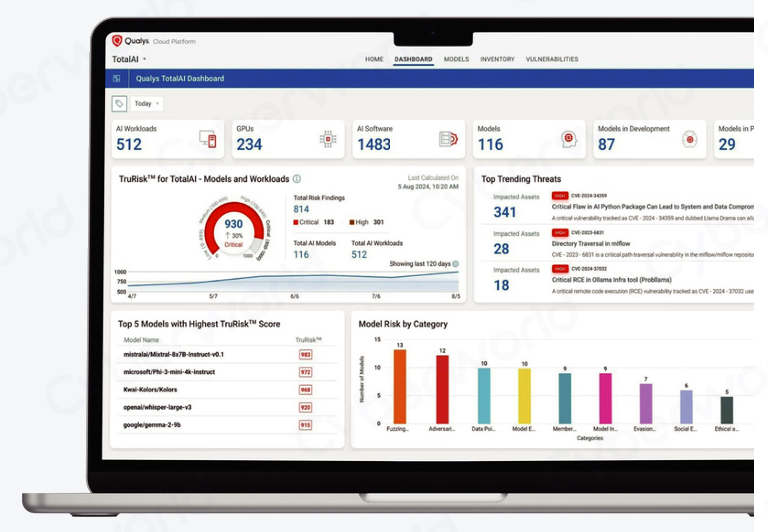
Qualys TotalAI 降低 Gen AI 和 LLM 工作負(fù)載的風(fēng)險
,為陳舊系統(tǒng)構(gòu)建的傳統(tǒng)安全方法根本無法應(yīng)對。 如今,企業(yè)面臨著知識產(chǎn)權(quán)被盜、數(shù)據(jù)泄露、違反隱私法規(guī)等風(fēng)險。在這種情況下,就更需要了解 LLM 的所在位置、漏洞以及暴露程度。這正是 Qualys TotalAI 發(fā)揮作用的地方。 Qualys TotalAI 為企業(yè)提供針對
使用 llm-agent-rag-llamaindex 筆記本時收到的 NPU 錯誤怎么解決?
使用 conda create -n ov-nb-demos python=3.11 創(chuàng)建運行 llm-agent-rag-llamaindex notebook 的環(huán)境。
執(zhí)行“創(chuàng)建
發(fā)表于 06-23 06:26
使用NVIDIA Triton和TensorRT-LLM部署TTS應(yīng)用的最佳實踐
針對基于 Diffusion 和 LLM 類別的 TTS 模型,NVIDIA Triton 和 TensorRT-LLM 方案能顯著提升推理速度。在單張 NVIDIA Ada Lovelace

LM Studio使用NVIDIA技術(shù)加速LLM性能
隨著 AI 使用場景不斷擴(kuò)展(從文檔摘要到定制化軟件代理),開發(fā)者和技術(shù)愛好者正在尋求以更 快、更靈活的方式來運行大語言模型(LLM)。
小白學(xué)大模型:從零實現(xiàn) LLM語言模型
在當(dāng)今人工智能領(lǐng)域,大型語言模型(LLM)的開發(fā)已經(jīng)成為一個熱門話題。這些模型通過學(xué)習(xí)大量的文本數(shù)據(jù),能夠生成自然語言文本,完成各種復(fù)雜的任務(wù),如寫作、翻譯、問答等。https
詳解 LLM 推理模型的現(xiàn)狀
2025年,如何提升大型語言模型(LLM)的推理能力成了最熱門的話題之一,大量優(yōu)化推理能力的新策略開始出現(xiàn),包括擴(kuò)展推理時間計算、運用強(qiáng)化學(xué)習(xí)、開展監(jiān)督微調(diào)和進(jìn)行提煉等。本文將深入探討LLM推理優(yōu)化
物聯(lián)網(wǎng)卡與傳統(tǒng) SIM 卡的區(qū)別,看完你就懂了
在移動通信領(lǐng)域,物聯(lián)網(wǎng)卡和傳統(tǒng) SIM 卡看似相似,實則有著本質(zhì)區(qū)別。這種區(qū)別不僅體現(xiàn)在物理形態(tài)上,更反映在技術(shù)特性和應(yīng)用場景上。理解這些差異,對于正確選擇和使用通信解決方案至關(guān)重要。
無法在OVMS上運行來自Meta的大型語言模型 (LLM),為什么?
無法在 OVMS 上運行來自 Meta 的大型語言模型 (LLM),例如 LLaMa2。
從 OVMS GitHub* 存儲庫運行 llama_chat Python* Demo 時遇到錯誤。
發(fā)表于 03-05 08:07



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論