 理解LLM中的模型量化
理解LLM中的模型量化

作者:Shaoni Mukherjee
編譯:ronghuaiyang,來源:AI公園
導讀
在本文中,我們將探討一種廣泛采用的技術,用于減小大型語言模型(LLM)的大小和計算需求,以便將這些模型部署到邊緣設備上。這項技術稱為模型量化。它使得人工智能模型能夠在資源受限的設備上高效部署。
在當今世界,人工智能和機器學習的應用已成為解決實際問題不可或缺的一部分。大型語言模型或視覺模型因其卓越的表現和實用性而備受關注。如果這些模型運行在云端或大型設備上,并不會造成太大問題。然而,它們的大小和計算需求在將這些模型部署到邊緣設備或用于實時應用時構成了重大挑戰。
邊緣設備,如我們所說的智能手表或Fitbits,擁有有限的資源,而量化是一個將大型模型轉換為可以輕松部署到小型設備上的過程。隨著人工智能技術的進步,模型復雜度呈指數增長。將這些復雜的模型容納在智能手機、物聯網設備和邊緣服務器等小型設備上是一項重大挑戰。然而,量化是一種減少機器學習模型大小和計算需求的技術,同時不會顯著犧牲其性能。量化已被證明在提高大型語言模型的內存和計算效率方面非常有用,從而使這些強大的模型更加實用和易于日常使用。
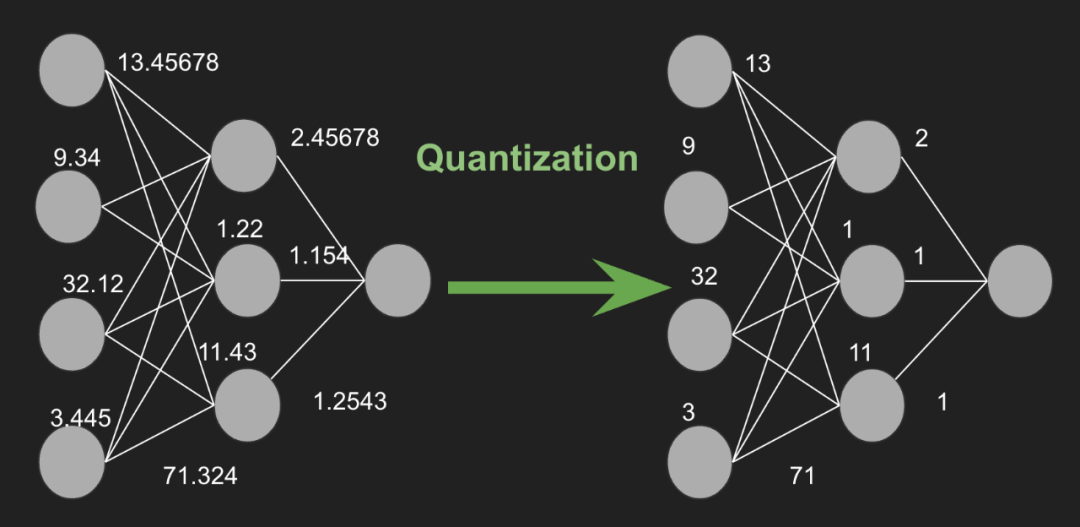
模型量化涉及將神經網絡的參數(如權重和激活)從高精度(例如32位浮點數)表示轉換為較低精度(例如8位整數)格式。這種精度的降低可以帶來顯著的好處,包括減少內存使用、加快推理時間和降低能耗。
什么是模型量化?模型量化的益處
模型量化是一種減少模型參數精度的技術,從而降低了存儲每個參數所需的位數。例如,考慮一個32位精度的參數值7.892345678,它可以被近似為8位精度下的整數8。這一過程顯著減小了模型的大小,使得模型能夠在內存有限的設備上更快地執行。
除了減少內存使用和提高計算效率外,量化還可以降低能耗,這對于電池供電的設備尤為重要。通過降低模型參數的精度,量化還能加快推理速度,因為它減少了存儲和訪問這些參數所需的內存。
模型量化有多種類型,包括均勻量化和非均勻量化,以及訓練后的量化和量化感知訓練。每種方法都有其自身的模型大小、速度和準確性之間的權衡,這使得量化成為在廣泛的硬件平臺上部署高效AI模型的一個靈活且必不可少的工具。
不同的模型量化技術
模型量化涉及各種技術來減少模型參數的大小,同時保持性能。
以下是幾種常見的技術:
1. 訓練后的量化
訓練后的量化(PTQ)是在模型完全訓練之后應用的。PTQ可能會降低模型的準確性,因為在模型被壓縮時,原始浮點值中的一些詳細信息可能會丟失。
- 準確性損失:當PTQ壓縮模型時,可能會丟失一些重要的細節,這會降低模型的準確性。
- 平衡:為了在使模型更小和保持高準確性之間找到合適的平衡,需要仔細調優和評估。這對于那些準確性至關重要的應用尤其重要。
簡而言之,PTQ可以使模型變得更小,但也可能降低其準確性,因此需要謹慎校準以維持性能。
這是一種簡單且廣泛使用的方法,包括幾種子方法:
- 靜態量化:將模型的權重和激活轉換為較低精度。使用校準數據來確定激活值的范圍,這有助于適當地縮放它們。
- 動態量化:僅量化權重,而在推理期間激活保持較高精度。根據推理時觀察到的范圍動態量化激活。
2. 量化感知訓練
量化感知訓練(QAT)將量化集成到訓練過程中。模型在前向傳播中模擬量化,使模型能夠學會適應降低的精度。這通常比訓練后的量化產生更高的準確性,因為模型能夠更好地補償量化誤差。QAT在訓練過程中增加了額外的步驟來模擬模型被壓縮后的表現。這意味著調整模型以準確處理這種模擬。這些額外步驟和調整使訓練過程更具計算要求。它需要更多的時間和計算資源。訓練后,模型需要經過徹底的測試和微調,以確保不會失去準確性。這為整個訓練過程增加了更多的復雜性。
3. 均勻量化
在均勻量化中,值范圍被劃分為等間距的間隔。這是最簡單的量化形式,通常應用于權重和激活。
4. 非均勻量化
非均勻量化為不同的區間分配不同的大小,通常使用諸如對數或k均值聚類等方法來確定區間。這種方法對于參數具有非均勻分布的情況更為有效,可能在關鍵范圍內保留更多信息。
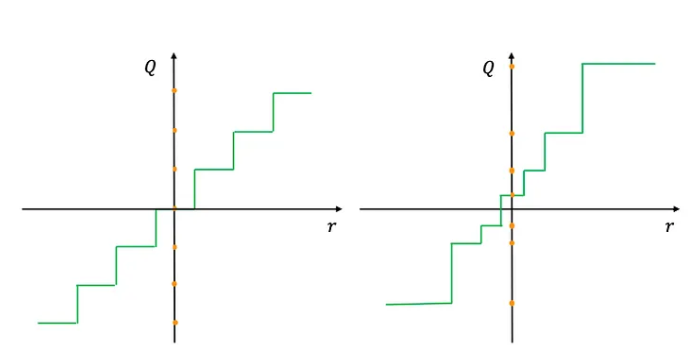
均勻量化和非均勻量化
5. 權重共享
權重共享涉及將相似的權重聚類,并在它們之間共享相同的量化值。這種技術減少了唯一權重的數量,從而實現了進一步的壓縮。權重共享量化是一種通過限制大型神經網絡中唯一權重的數量來節省能量的技術。
益處:
- 抗噪性:該方法更好地處理噪聲。
- 可壓縮性:可以在不犧牲準確性的情況下縮小網絡的規模。
6. 混合量化
混合量化在同一模型中結合了不同的量化技術。例如,權重可以被量化到8位精度,而激活則保持較高的精度,或者不同的層可以根據它們對量化的敏感性使用不同級別的精度。這種技術通過將量化應用于模型的權重(模型的參數)和激活(中間輸出)來減小神經網絡的大小并加快速度。
- 量化兩個部分:它同時壓縮模型的權重和計算的數據激活。這意味著兩者都使用較少的位數存儲和處理,從而節省了內存并加快了計算速度。
- 內存和速度提升:通過減少模型需要處理的數據量,混合量化使得模型更小、更快。
- 復雜性:因為它同時影響權重和激活,所以實施起來可能比僅僅量化其中一個更復雜。它需要精心調優以確保模型在保持高效的同時仍然保持準確性。
7. 僅整數量化
在僅整數量化中,權重和激活都被轉換為整數格式,并且所有計算都使用整數算術完成。這種技術對于優化整數操作的硬件加速器特別有用。
8. 按張量和按通道量化
按張量量化:在整個張量(例如,一層中的所有權重)上應用相同的量化尺度。
按通道量化:在一個張量的不同通道上使用不同的尺度。這種方法可以通過允許卷積神經網絡中的量化更細粒度,從而提供更好的準確性。
9. 自適應量化
自適應量化方法根據輸入數據分布動態調整量化參數。這些方法通過針對數據的具體特征定制量化,有可能達到更高的準確性。
每種技術都有其在模型大小、速度和準確性之間的權衡。選擇適當的量化方法取決于部署環境的具體要求和約束。
模型量化面臨的挑戰與考慮因素
在AI中實施模型量化涉及到應對幾個挑戰和考慮因素。主要的問題之一是準確性權衡,因為減少模型數值數據的精度可能會降低其性能,特別是對于需要高精度的任務。為了管理這一點,采用的技術包括量化感知訓練、混合方法(結合不同精度級別)以及量化參數的迭代優化,以保持準確性。此外,不同硬件和軟件平臺之間的兼容性可能存在問題,因為并非所有平臺都支持量化。解決這個問題需要廣泛的跨平臺測試,使用標準化框架(如TensorFlow或PyTorch)以獲得更廣泛的兼容性,有時還需要為特定硬件開發定制解決方案以確保最佳性能。
實際應用案例
模型量化在各種實際應用中廣泛使用,其中效率和性能至關重要。
以下是一些示例:
- 移動應用:量化模型用于移動應用中的任務,如圖像識別、語音識別和增強現實。例如,量化神經網絡可以在智能手機上高效運行,以識別照片中的目標或提供實時的語言翻譯,即使在計算資源有限的情況下也是如此。
- 自動駕駛汽車:在自動駕駛汽車中,量化模型幫助實時處理傳感器數據,如識別障礙物、讀取交通標志和做出駕駛決策。量化模型的效率使得這些計算可以快速完成,并且功耗較低,這對于自動駕駛汽車的安全性和可靠性至關重要。
- 邊緣設備:量化對于將AI模型部署到無人機、物聯網設備和智能攝像頭等邊緣設備至關重要。這些設備通常具有有限的處理能力和內存,因此量化模型使它們能夠高效地執行復雜的任務,如監控、異常檢測和環境監測。
- 醫療保健:在醫學影像和診斷中,量化模型用于分析醫學掃描和檢測異常,如腫瘤或骨折。這有助于在硬件計算能力有限的情況下提供更快、更準確的診斷,例如便攜式醫療設備。
- 語音助手:數字語音助手如Siri、Alexa和Google Assistant使用量化模型處理語音命令、理解自然語言并提供響應。量化使這些模型能夠在家庭設備上快速高效地運行,確保順暢且響應迅速的用戶體驗。
- 推薦系統:在線平臺如Netflix、Amazon和YouTube使用量化模型提供實時推薦。這些模型處理大量用戶數據以建議電影、產品或視頻,量化有助于管理計算負載,同時及時提供個性化推薦。
量化提高了AI模型的效率,使它們能夠在資源受限的環境中部署,而不顯著犧牲性能,從而改善了廣泛應用中的用戶體驗。
總結思考
量化是人工智能和機器學習領域的一項關鍵技術,解決了將大型模型部署到邊緣設備的挑戰。量化顯著減少了神經網絡的內存占用和計算需求,使它們能夠在資源受限的設備和實時應用中部署。正如本文討論的,量化的一些好處包括減少內存使用、加快推理時間和降低功耗。技術如均勻量化和非均勻量化,以及創新方法如權重共享和混合量化。盡管量化具有優勢,但也帶來了挑戰,特別是在保持模型準確性方面。然而,隨著近期的研究和量化方法的發展,研究人員繼續致力于解決這些問題,推動低精度計算的可能性邊界。隨著深度學習社區不斷創新發展,量化將在部署強大且高效的AI模型中扮演關鍵角色,使先進的AI功能能夠廣泛應用于更多的應用場景和設備。總之,量化不僅僅是技術優化那么簡單——它在AI進步中扮演著至關重要的角色。
-
人工智能
+關注
關注
1819文章
50219瀏覽量
266526 -
語言模型
+關注
關注
0文章
572瀏覽量
11336 -
LLM
+關注
關注
1文章
349瀏覽量
1381
發布評論請先 登錄
后量化模型在 iMX93 NPU 上運行,但輸出不正確怎么解決
Google正式發布LLM評測基準Android Bench

AWQ/GPTQ量化模型加載與顯存優化實戰
【CIE全國RISC-V創新應用大賽】+ 一種基于LLM的可通過圖像語音控制的元件庫管理工具
NVIDIA TensorRT LLM 1.0推理框架正式上線
廣和通發布端側情感對話大模型FiboEmo-LLM
米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
3萬字長文!深度解析大語言模型LLM原理

DeepSeek R1 MTP在TensorRT-LLM中的實現與優化

基于米爾瑞芯微RK3576開發板的Qwen2-VL-3B模型NPU多模態部署評測
如何在魔搭社區使用TensorRT-LLM加速優化Qwen3系列模型推理部署
使用NVIDIA Triton和TensorRT-LLM部署TTS應用的最佳實踐

使用瑞薩MPU芯片RZ/V2H部署DeepSeek-R1模型

小白學大模型:從零實現 LLM語言模型



 工商網監
工商網監
評論