 Hot Chips 2017——人工智能近期的發展及其對計算機系統設計的影響(附PPT資料下載)
Hot Chips 2017——人工智能近期的發展及其對計算機系統設計的影響(附PPT資料下載)

在演講中,Jeff Dean 首先介紹了深度學習的崛起(及其原因),谷歌在自動駕駛、醫療健康等領域取得的最新進展。
Jeff Dean 表示,隨著深度學習的發展,我們需要更多的計算能力,而深度學習也正在改變我們設計計算機的能力。
我們知道,谷歌設計了 TPU 專門進行神經網絡推斷。Jeff Dean 表示,TPU 在谷歌產品中的應用已經超過了 30 個月,用于搜索、神經機器翻譯、DeepMind 的 AlphaGo 系統等。
但部署人工智能不只是推斷,還有訓練階段。TPU 能夠助力推斷,我們又該如何加速訓練?訓練的加速非常的重要:無論是對產品化還是對解決大量的難題。
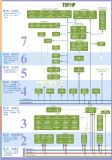
為了同時加速神經網絡的推斷與訓練,谷歌設計了 TPU 二代。TPU 二代芯片的性能如下圖所示:
除了上圖所述意外,TPU 二代的特點還有:
-
每秒的浮點運算是 180 teraflops,64 GB 的 HBM 存儲,2400 GB/S 的存儲帶寬
-
設計上,TPU 二代可以組合連接成大型配置
下圖是 TPU 組成的大型配置:由 64 塊 TPU 二代組成,每秒 11.5 千萬億次浮點運算,4 太字節的 HBM 存儲。
在擁有強大的硬件之后,我們需要更強大的深度學習框架來支持這些硬件和編程語言,因為快速增長的機器學習和深度學習需要硬件和軟件都能具備強大的擴展能力。因此,Jeff Dean 還詳細介紹了最開始由谷歌開發的深度學習框架 TensorFlow。
深度學習框架 TensorFlow
TensorFlow 是一種采用數據流圖(data flow graphs),用于數值計算的開源軟件庫。其中 Tensor 代表傳遞的數據為張量(多維數組),Flow 代表使用計算圖進行運算。數據流圖用「節點」(nodes)和「邊」(edges)組成的有向圖來描述數學運算。
TensorFlow 的目標是建立一個可以表達和分享機器學習觀點與系統的公共平臺。該平臺是開源的,所以它不僅是谷歌的平臺,同時是所有機器學習開發者和研究人員的平臺,谷歌和所有機器學習開源社區的研究者都在努力使 TensorFlow 成為研究和產品上最好的機器學習平臺。
下面是 TensorFlow 項目近年來在 Github 上的關注度,我們可以看到 TensorFlow 是所有同類深度學習框架中關注度最大的項目。

TensorFlow:一個充滿活力的開源社區
TensorFlow 發展迅速,有很多谷歌外部的開發人員
-
超過 800 多位 TensorFlow 開發人員(非谷歌人員)。
-
21 個月內 Github 上有超過 21000 多條貢獻和修改。
-
許多社區編寫了 TensorFlow 的教程、模型、翻譯和項目
-
超過 16000 個 Github 項目在項目名中包含了「TensorFlow」字段
社區與 TensorFlow 團隊之間的直接聯合
-
5000+已回答的 Stack Overflow 問題
-
80+ 每周解答的社區提交的 GitHub 問題

通過 TensorFlow 編程
在 TensorFlow 中,一個模型可能只需要一點點修改就能在 CPU、GPU 或 TPU 上運行。前面我們已經看到 TPU 的強大之處,Jeff Dean 表明,對于從事開放性機器學習研究的科學家,谷歌可以免費提供 1000 塊云 TPU 來支持他們的研究。Jeff Dean 說:「我們很高興研究者能在更強勁的計算力下進行更杰出的研究」
TensorFlow Research Cloud 申請地址:https://services.google.com/fb/forms/tpusignup/
機器學習需要在各種環境中運行,我們可以在下面看到 TensorFlow 所支持的各種平臺和編程語言。
除此之外,TensorFlow 還支持各種編程語言,如 Python、C++、Java、C#、R、Go 等。
TensorFlow 非常重要的一點就是計算圖,我們一般需要先定義整個模型需要的計算圖,然后再執行計算圖進行運算。在計算圖中,「節點」一般用來表示施加的數學操作,但也可以表示數據輸入的起點和輸出的終點,或者是讀取/寫入持久變量(persistent variable)的終點。邊表示節點之間的輸入/輸出關系。這些數據邊可以傳送維度可動態調整的多維數據數組,即張量(tensor)。
如下是使用 TensorFlow 和 Python 代碼定義一個計算圖:

在 Tensorflow 中,所有不同的變量和運算都儲存在計算圖。所以在我們構建完模型所需要的圖之后,還需要打開一個會話(Session)來運行整個計算圖。在會話中,我們可以將所有計算分配到可用的 CPU 和 GPU 資源中。
如下所示代碼,我們聲明兩個常量 a 和 b,并且定義一個加法運算。但它并不會輸出計算結果,因為我們只是定義了一張圖,而沒有運行它:
a=tf.constant([1,2],name="a")
b=tf.constant([2,4],name="b")
result = a+b
print(result)
#輸出:Tensor("add:0", shape=(2,), dtype=int32)
下面的代碼才會輸出計算結果,因為我們需要創建一個會話才能管理 TensorFlow 運行時的所有資源。但計算完畢后需要關閉會話來幫助系統回收資源,不然就會出現資源泄漏的問題。下面提供了使用會話的兩種方式:
a=tf.constant([1,2,3,4])
b=tf.constant([1,2,3,4])
result=a+b
sess=tf.Session()
print(sess.run(result))
sess.close
#輸出 [2 4 6 8]
with tf.Session() as sess:
a=tf.constant([1,2,3,4])
b=tf.constant([1,2,3,4])
result=a+b
print(sess.run(result))
#輸出 [2 4 6 8]
TensorFlow + XLA 編譯器
XLA(Accelerated Linear Algebra)是一種特定領域的編譯器,它極好地支持線性代數,所以能很大程度地優化 TensorFlow 的計算。使用 XLA 編譯器,TensorFlow 的運算將在速度、內存使用和概率計算上得到大幅度提升。
-
XLA 編譯器詳細介紹: https://www.tensorflow.org/performance/xla/
-
XLA 編譯器開源代碼: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/compiler
TensorFlow 的優勢
高性能機器學習模型
對于大型模型來說,模型并行化處理是極其重要的,因為單個模型的訓練時間太長以至于我們很難對這些模型進行反復的修改。因此,在多個計算設備中處理模型并取得優秀的性能就十分重要了。如下所示,我們可以將模型分割為四部分,運行在四個 GPU 上。

高性能強化學習模型
通過強化學習訓練的 Placement 模型將圖(graph)作為輸入,并且將一組設備、輸出設備作為圖中的節點。在 Runtime 中,給定強化學習的獎勵信號而度量每一步的時間,然后再更新 Placement。

通過強化學習優化設備部署(Device Placement Optimization with Reinforcement Learning,ICML 2017)
-
論文地址:https://arxiv.org/abs/1706.04972

通過強化學習優化設備部署
降低推斷成本
開發人員最怕的就是「我們有十分優秀的模型,但它卻需要太多的計算資源而不能部署到邊緣設備中!」
Geoffrey Hinton 和 Jeff Dean 等人曾發表過論文 Distilling the Knowledge in a Neural Network。在該篇論文中,他們詳細探討了將知識壓縮到一個集成的單一模型中,因此能使用不同的壓縮方法將復雜模型部署到低計算能力的設備中。他們表示這種方法顯著地提升了商業聲學模型部署的性能。
-
論文地址:https://arxiv.org/abs/1503.02531
這種集成方法實現成一個從輸入到輸出的映射函數。我們會忽略集成中的模型和參數化的方式而只關注于這個函數。以下是 Jeff Dean 介紹這種集成。

訓練模型的幾個趨勢
1. 大型、稀疏激活式模型
之所以想要訓練這種模型是想要面向大型數據集的大型模型容量,但同時也想要單個樣本只激活大型模型的一小部分。

逐個樣本路徑選擇圖
這里,可參考谷歌 Google Brain ICLR 2017 論文《OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER》。
2. 自動機器學習
Jeff Dean 介紹說,目前的解決方式是:機器學習專家+數據+計算。這種解決方案人力的介入非常大。我們能不能把解決方案變成:數據+100 倍的計算。
有多個信號讓我們看到,這種方式是可行的:
-
基于強化學習的架構搜索
-
學習如何優化
如 Google Brain ICLR 2017 論文《Neural Architecture Search with Reinforcement Learning》,其思路是通過強化學習訓練的模型能夠生成模型。
在此論文中,作者們生成了 10 個模型,對它們進行訓練(數個小時),使用生成模型的損失函數作為強化學習的信號。

在 CIFAR-10 圖像識別任務上,神經架構搜索的表現與其他頂級成果的表現對比如上圖所示。

上圖是正常的 LSTM 單元與架構搜索所發現的單元圖。
此外,學習優化更新規則也是自動機器學習趨勢中的一個信號。通常我們使用的都是手動設計的優化器,如下圖所示。

而 Google Brain 在 ICML 2017 的論文《Neural Optimizer Search with Reinforcement Learning》中,就講到了一種學習優化更新規則的技術。神經優化器搜索如下圖所示:

總結
最后,Jeff Dean 總結說,未來人工智能的發展可能需要結合以上介紹的所有思路:需要大型、但稀疏激活的模型;需要解決多種任務的單個模型;大型模型的動態學習和成長路徑;面向機器學習超級計算的特定硬件,以及高效匹配這種硬件的機器學習方法。

當然,目前在機器學習與系統/計算機架構的交叉領域還存在一些開放問題,例如:
-
極為不同的數值是否合理(例如,1-2 位的激勵值/參數)?
-
我們如何高效的處理非常動態的模型(每個輸入樣本都有不同的圖)?特別是在特大型機器上。
-
有沒有方法能夠幫助我們解決當 batch size 更大時,回報變小的難題?
-
接下來 3-4 年中,重要的機器學習算法、方法是什么?
如今,神經網絡與其他方法隨數據、模型大小變化的準確率對比圖如下:

未來,可能又是一番境況。

演講PPT地址:http://pan.baidu.com/s/1kVyxeB1
-
FPGA
+關注
關注
1660文章
22415瀏覽量
636491 -
微處理器
+關注
關注
11文章
2431瀏覽量
85873 -
AI
+關注
關注
91文章
39805瀏覽量
301479 -
人工智能
+關注
關注
1817文章
50100瀏覽量
265495
原文標題:Jeff Dean「Hot Chips 2017」演講:AI對計算機系統設計的影響
文章出處:【微信號:almosthuman2014,微信公眾號:機器之心】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
淺談人工智能(2)

樂高?教育宣布推出專注于計算機科學與人工智能的動手實踐式學習解決方案

光合組織2025人工智能創新大會,高能計算機展現工業智能新圖景

Neousys宸曜發布適用于狹小空間的經濟型邊緣人工智能計算機

上海市計算機行業協會攜手深蘭科技推動人工智能高質量發展
龍架構計算機系統能力核心課程教學研討會圓滿舉行
2025中國高校計算機大賽人工智能創意賽圓滿落幕
挖到寶了!人工智能綜合實驗箱,高校新工科的寶藏神器
人工智能技術的現狀與未來發展趨勢
AI芯片:加速人工智能計算的專用硬件引擎
利用邊緣計算和工業計算機實現智能視頻分析

一文帶你了解工業計算機尺寸

計算機網絡入門指南
2025全國大學生計算機系統能力大賽啟幕,RT-Thread助力高校人才培養




 工商網監
工商網監
評論