 Qwen2強勢來襲,AIBOX支持本地化部署
Qwen2強勢來襲,AIBOX支持本地化部署

Qwen2 是阿里通義推出的新一代多語言預訓練模型,經過更深入的預訓練和指令調整,在多個基準評測結果中表現出色,尤其在代碼和數學方面有顯著提升,同時拓展了上下文長度支持,最高可達128K。目前 AIBOX-1684X 已適配 Qwen2 系列模型,并已集成在 FireflyChat 對話應用中,開機即可體驗。
模型基礎更新
預訓練和指令微調模型
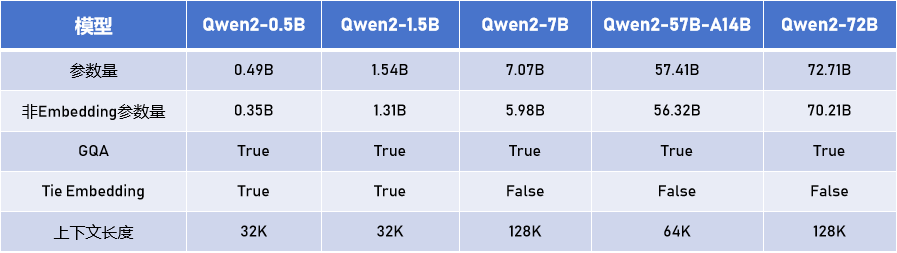
Qwen2系列包含5個尺寸的預訓練和指令微調模型,所有尺寸模型都使用了 GQA(分組查詢注意力)機制,方便用戶體驗到推理加速和顯存占用降低的優勢。
加強27種語言的訓練數據
Qwen團隊通過擴展多語言預訓練和指令微調數據的規模,針對除中英文以外的27種語言進行加強,提升模型的多語言能力。

模型多方面測評

基準測評結果
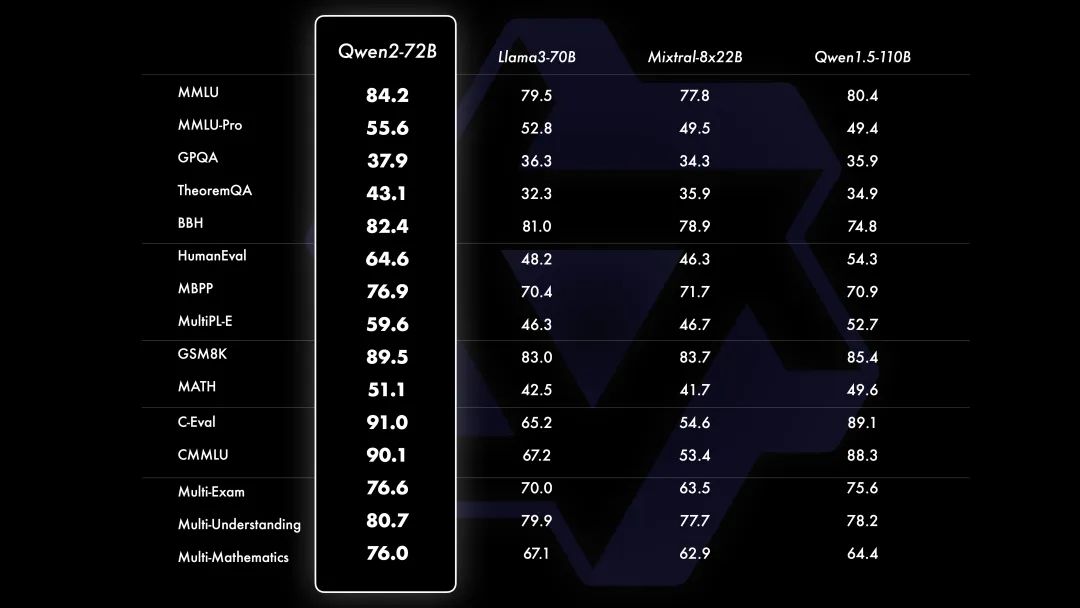
相比 Qwen1.5,得益于預訓練數據及訓練方法的優化,Qwen2 在大模型實現大幅度的效果提升。在針對預訓練語言模型的評估中,Qwen2-72B 在包括自然語言理解、知識、代碼、數學及多語言等多項能力上均表現卓越。
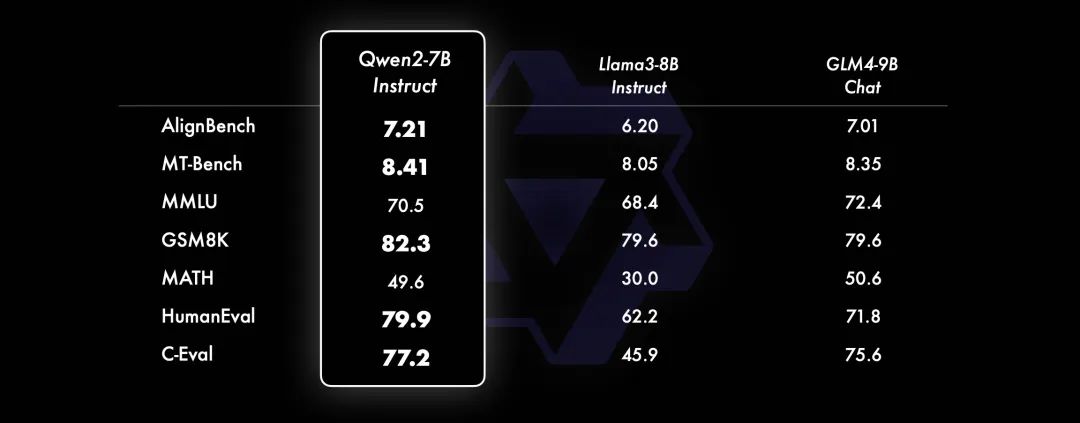
小模型方面,相比近期推出的領先模型,Qwen2-7B-Instruct 依然能在多個評測上取得顯著的優勢,尤其是代碼及中文理解。
代碼和數學能力顯著提升
代碼方面,沿用 Qwen1.5 的代碼能力,實現 Qwen2 在多種編程語言上的效果提升;數學方面,投入了大規模且高質量的訓練數據提升 Qwen2-72B-Instruct 的數學解題能力。

長文本處理
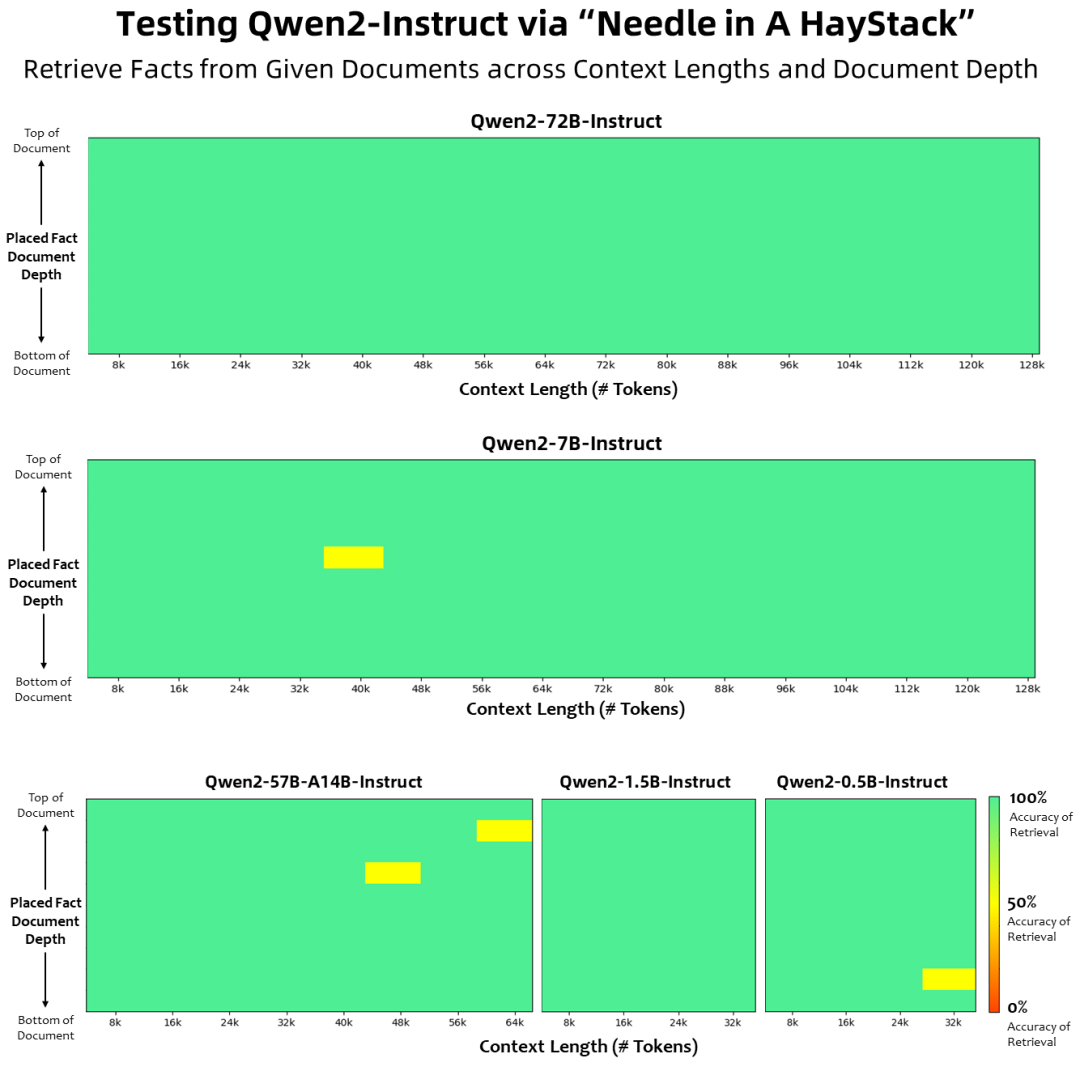
Qwen2 系列模型中較為關注的功能是它能夠理解和處理擴展的上下文序列,對于冗長文檔的應用程序,Qwen2 可以提供更準確、全面的響應,實現長文本自然語言高效處理。在Needle in a Haystack的測試集上顯示:Qwen2-7B-Instruct 幾乎完美地處理長達128k的上下文。
Qwen2-7B本地化部署
-
人工智能
+關注
關注
1817文章
50094瀏覽量
265273 -
模型
+關注
關注
1文章
3751瀏覽量
52099 -
語言模型
+關注
關注
0文章
571瀏覽量
11310
發布評論請先 登錄
美格智能高算力AI模組+Qwen3.5,打造端側最強AI智能體

涂鴉網關本地化進階能力來襲!周期/區間/批量聯動全掌控,解鎖高階場景應用

NVIDIA ACE現已支持開源Qwen3-8B小語言模型
發布元服務配置本地化基礎信息(應用名稱、圖標)
廣和通成功部署DeepSeek-R1-0528-Qwen3-8B模型
破解非洲數字鴻溝:傳音控股以本地化創新與教育合作助力可持續發展

基于米爾瑞芯微RK3576開發板的Qwen2-VL-3B模型NPU多模態部署評測
能源監測管理平臺是本地化部署好還是云端部署好?

傳音控股本地化戰略的跨區域成功:驅動東南亞、南亞數字化浪潮 ?

AI+能源數字化破局者故事5:斯倫貝謝 x IBM 咨詢之 “全球化經營與本地化適配”
施耐德電氣與奇安信共建技術本地化創新中心

AIBOX 產品矩陣:支持主流大模型的私有化部署,滿足個性化 AI 應用需求

AIBOX 新成員,搭載 RK3588S 芯片全新上線



 工商網監
工商網監
評論