") 國(guó)產(chǎn)GPU可替代!摩爾線程千卡集群點(diǎn)亮新成就
國(guó)產(chǎn)GPU可替代!摩爾線程千卡集群點(diǎn)亮新成就

摩爾線程、無(wú)問(wèn)芯穹聯(lián)合宣布,雙方已經(jīng)正式完成MT-infini-3B 3B(30億參數(shù))規(guī)模大模型的實(shí)訓(xùn),基于摩爾線程國(guó)產(chǎn)全功能GPU MTT S4000組成的千卡集群,以及無(wú)問(wèn)芯穹的AIStudio PaaS平臺(tái)。
本次實(shí)訓(xùn)充分驗(yàn)證了夸娥千卡智算集群在大模型訓(xùn)練場(chǎng)景下的可靠性,同時(shí)也在行業(yè)內(nèi)率先開(kāi)啟了國(guó)產(chǎn)大語(yǔ)言模型與國(guó)產(chǎn)GPU千卡智算集群深度合作的新范式。
據(jù)悉,這次的MT-infini-3B模型訓(xùn)練總共用時(shí)13.2天,全程穩(wěn)定無(wú)中斷,集群訓(xùn)練穩(wěn)定性達(dá)到100%,千卡訓(xùn)練和單機(jī)相比擴(kuò)展效率超過(guò)90%。
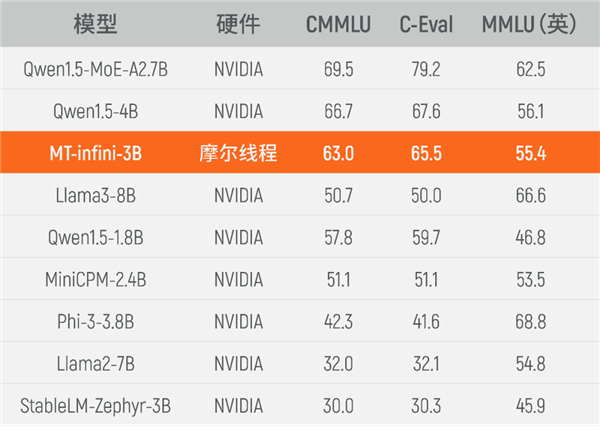
目前,實(shí)訓(xùn)出來(lái)的MT-infini-3B性能在同規(guī)模模型中躋身前列,相比在國(guó)際主流硬件上(尤其是NVIDIA)訓(xùn)練而成的其他模型,在C-Eval、MMLU、CMMLU等3個(gè)測(cè)試集上均實(shí)現(xiàn)性能領(lǐng)先。
無(wú)問(wèn)芯穹正在打造“M種模型”和“N種芯片”之間的“M x N”中間層產(chǎn)品,實(shí)現(xiàn)多種大模型算法在多元芯片上的高效、統(tǒng)一部署,已與摩爾線程達(dá)成深度戰(zhàn)略合作。
摩爾線程是第一家接入無(wú)問(wèn)芯穹并進(jìn)行千卡級(jí)別大模型訓(xùn)練的國(guó)產(chǎn)GPU公司,夸娥千卡集群已與無(wú)穹Infini-AI順利完成系統(tǒng)級(jí)融合適配,完成LLama2 700億參數(shù)大模型的訓(xùn)練測(cè)試。
T-infini-3B的訓(xùn)練,則是行業(yè)內(nèi)首次實(shí)現(xiàn)基于國(guó)產(chǎn)GPU芯片從0到1的端到端大模型實(shí)訓(xùn)案例。
就在日前,基于摩爾線程的夸娥千卡集群,憨猴集團(tuán)也成功完成了7B、34B、70B不同參數(shù)量級(jí)的大模型分布式訓(xùn)練,雙方還達(dá)成戰(zhàn)略合作。
經(jīng)雙方共同嚴(yán)苛測(cè)試,兼容適配程度高,訓(xùn)練效率達(dá)到預(yù)期,精度符合要求,整個(gè)訓(xùn)練過(guò)程持續(xù)穩(wěn)定。
-
GPU芯片
+關(guān)注
關(guān)注
1文章
307瀏覽量
6516 -
摩爾線程
+關(guān)注
關(guān)注
2文章
279瀏覽量
6450 -
大模型
+關(guān)注
關(guān)注
2文章
3650瀏覽量
5181
原文標(biāo)題:國(guó)產(chǎn)GPU可替代!摩爾線程千卡集群點(diǎn)亮新成就
文章出處:【微信號(hào):hdworld16,微信公眾號(hào):硬件世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
摩爾線程正式開(kāi)源TileLang-MUSA項(xiàng)目
全棧國(guó)產(chǎn)AI Coding上線:摩爾線程+硅基流動(dòng)+智譜,強(qiáng)強(qiáng)聯(lián)合!

國(guó)產(chǎn)算力首證具身大腦模型訓(xùn)練實(shí)力:摩爾線程聯(lián)合智源研究院完成RoboBrain 2.5全流程訓(xùn)練

墨芯人工智能千卡集群正式簽約入駐新疆算力中心
算力即國(guó)力!摩爾線程架構(gòu)/芯片/超節(jié)點(diǎn)/萬(wàn)卡集群四連發(fā),助力打造AI國(guó)之重器

摩爾線程新一代GPU架構(gòu)即將揭曉
摩爾線程高開(kāi)468% 中一簽賺27萬(wàn) 國(guó)產(chǎn)GPU第一股摩爾線程高開(kāi)468%

摩爾線程副總裁王華:AI工廠全棧技術(shù)重構(gòu)算力基建,開(kāi)啟國(guó)產(chǎn) GPU 黃金時(shí)代

摩爾線程吳慶詳解 MUSA 軟件棧:以技術(shù)創(chuàng)新釋放 KUAE 集群潛能,引領(lǐng) GPU 計(jì)算新高度?

摩爾線程與AI算力平臺(tái)AutoDL達(dá)成深度合作
摩爾線程與當(dāng)虹科技達(dá)成深度合作
摩爾線程發(fā)布云電腦驅(qū)動(dòng)MT vGPU 2.7.0
摩爾線程GPU原生FP8計(jì)算助力AI訓(xùn)練

千卡算力破局:科通技術(shù)以"AI大模型+AI芯片"重構(gòu)智算底座
摩爾線程支持阿里云通義千問(wèn)QwQ-32B開(kāi)源模型




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論