 李彥宏說開源模型會越來越落后,為什么很多人不認同?
李彥宏說開源模型會越來越落后,為什么很多人不認同?

上周,百度董事長兼CEO李彥宏對于開源大模型的一番言論引發了爭議。
李彥宏在Create 2024百度AI開發者大會上表示:“開源模型會越來越落后。”
李彥宏的解釋是,百度基礎模型文心4.0可根據不同需求,在效果、響應速度和推理成本等方面靈活剪裁,生成適應各種場景的精簡模型,并支持精調和post pretrain。相較于直接使用開源模型,文心4.0剪裁出的模型在同等尺寸下表現更佳,而在同等效果下成本更低,因此他預測開源模型將會越來越落后。
但很多AI從業者都不太認同這一結論。比如獵豹移動董事長兼CEO、獵戶星空董事長傅盛很快發視頻反駁,說“開源社區將最終戰勝閉源”。
開源模型到底能否超越閉源模型?這個問題從去年開始就備受爭議。
去年5月,外媒曾報道谷歌流出一份文件,主題是“我們沒有護城河,OpenAI也沒有。當我們還在爭吵時,開源已經悄悄地搶了我們的飯碗”。
去年Meta發布開源大模型Llama 2后,Meta副總裁、人工智能部門負責人楊立昆(Yann LeCun)表示,Llama 2將改變大語言模型的市場格局。
人們對于Llama系列模型所引領的開源社區備受期待。但直到今天,最新發布的Llama 3仍然沒有追上最先進的閉源模型GPT-4,盡管兩者的差距已經很小了。
「甲子光年」采訪了多位AI從業者,一個普遍的反饋是,討論開源好還是閉源好,本身是由立場決定的,也不簡簡單單是一個二元對立的問題。
開源與閉源并非一個技術問題,更多是一個商業模式的問題。然而,大模型當前的發展現狀是,不論是開源還是閉源,都還沒有找到切實可行的商業模式。
所以,未來到底會如何發展呢?
1.差距沒有拉大,而是在縮小
開源模型與閉源模型到底誰更強?不妨先看一下客觀的數據排名情況。
大模型領域最權威的榜單是大模型競技場(LLM Arena),采用了國際象棋一直采用了ELO積分體系。它的基本規則是,讓用戶向兩個匿名模型(例如 ChatGPT、Claude、Llama)提出任何問題,并投票給回答更好的一個。回答更好的模型將獲得積分,最終的排名由累計積分的高低來確定。Arean ELO收集了50萬人的投票數據。 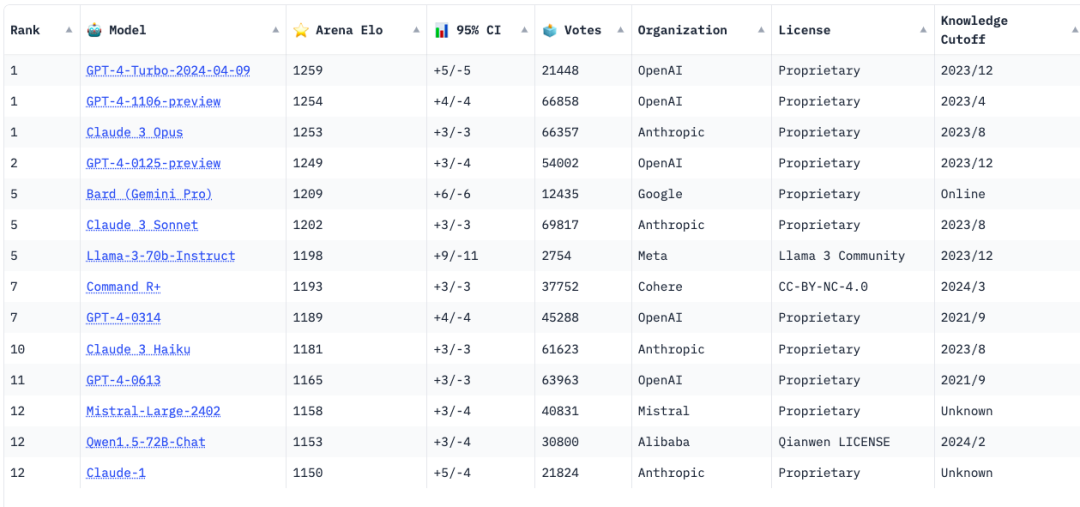
大模型排行榜,圖片來自LLM Arena截圖
在LLM Arena榜單上,OpenAI的GPT-4長期霸榜第一。Anthropic最新發布的Claude 3曾短期取代GPT-4取得第一名的桂冠,但OpenAI很快發布最新版本的GPT-4 Turbo,重新奪回第一的寶座。
LLM Arena排名前十的模型基本上被閉源模型壟。能夠擠進前十名榜單的開源模型只有兩個:一是Meta上周剛剛發布的LLama 3 70B,排名第五,也是表現最好的開源模型;二是“Transformer八子”之一的Aidan Gomez創立的Cohere近期發布的Command R+,排名第七。值得一提的是,阿里發布的開源模型Qwen1.5-72B-Chat,排名第十二,是國內表現最好的開源模型。
從絕對排名上看,閉源模型仍然遙遙領先開源模型。但若從兩者的差距來看,并非李彥宏所說的越來越大,而是越來越小。 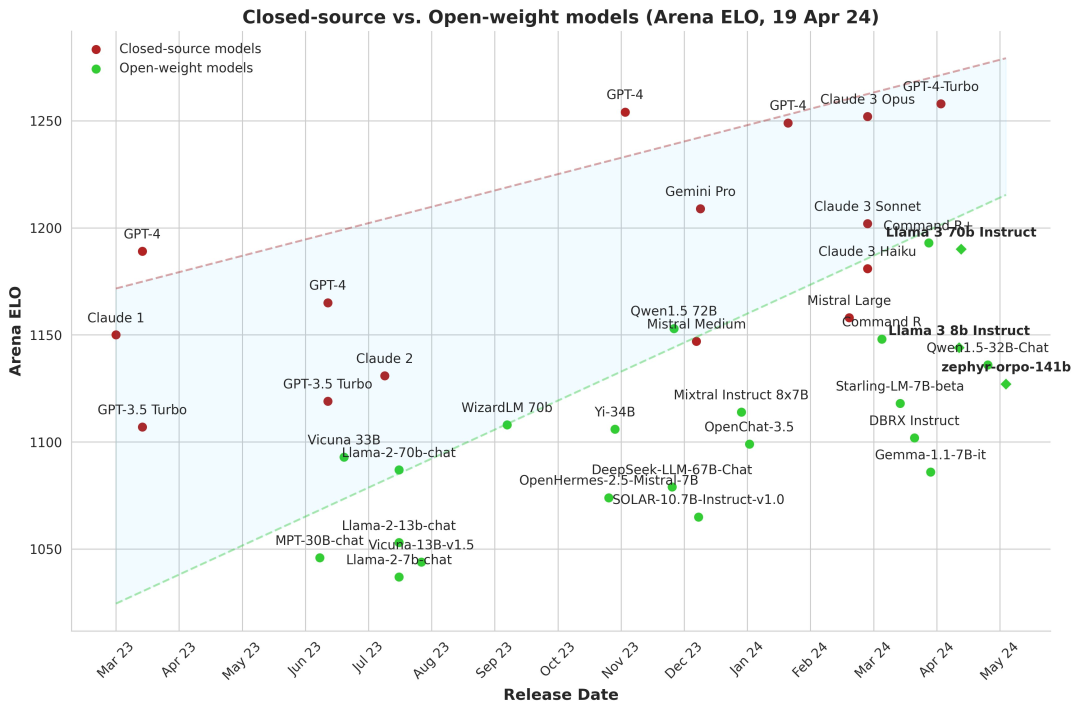
閉源模型與開源模型的差距,圖片來自X
昆侖萬維董事長兼CEO方漢此前曾對「甲子光年」表示,開源模型與閉源模型的差距已經從落后2年追到僅落后4~6個月了。
什么因素會影響開源和閉源模型的能力差異?
微博新技術研發負責人張俊林認為,模型能力增長曲線的平滑或陡峭程度比較重要。如果模型能力增長曲線越陡峭(單位時間內,模型各方面能力的增長數量,越快就類似物體運動的“加速度”越大),則意味著短時間內需要投入越大的計算資源,這種情況下閉源模型相對開源模型是有優勢的,主要是資源優勢導致的模型效果優勢。
反過來,如果模型能力增長曲線越平緩,則意味著開源和閉源模型的差異會越小,追趕速度也越快。這種由模型能力增長曲線陡峭程度決定的開源閉源模型的能力差異,可以稱之為模型能力的“加速度差”。
張俊林認為,往后多看幾年,開源與閉源的能力是縮小還是增大,取決于在“合成數據”方面的技術進展。如果“合成數據”技術在未來兩年能獲得突破,則兩者差距是有可能拉大的;如果不能突破,則開源和閉源模型能力會相當。
所以,“合成數據”是未來兩年大語言模型最關鍵的決定性的技術,很可能沒有之一。
2.開源模型的“真假開源”
人們對于開源模型的期待,很大程度上就在于“開源”兩個字。
開源是軟件行業蓬勃發展的決定性力量。正如360集團創始人周鴻祎近期在哈佛大學演講中提到的那樣:“沒有開源就沒有Linux,沒有PHP,沒有MySQL,甚至沒有互聯網。包括在人工智能的發展上,如果沒有當初谷歌開源Transformer,就不會有OpenAI和GPT。我們都是受益于開源成長起來的個人和公司。”
但是,這一次的開源模型可能要讓很多開源信徒失望了。
去年Llama 2發布后不久,就有批評聲音稱,Meta其實是在“假開源”。
比如,開源友好型風險投資公司RedPoint的董事總經理Erica Brescia表示:“誰能向我解釋一下,如果Llama 2實際上沒有使用OSI(開放源碼計劃)批準的許可證,也不符合OSD(開放源碼定義),Meta公司和微軟公司又如何稱Llama 2為開放源碼?他們是在故意挑戰OSS(開放源碼軟件)的定義嗎?”?
的確,Llama 2并沒有遵循上述協議,而是自定義了一套“開源規則”,包括禁止使用Llama 2去訓練其它語言模型,如果該模型用于每月用戶超過7億的應用程序和服務,則需要獲得Meta的特殊許可證。
Llama 2雖然自稱為開源模型,但僅僅開放了模型權重——也就是訓練之后的參數,但訓練數據、訓練代碼等關鍵信息都未開放。
零一萬物開源負責人林旅強告訴「甲子光年」,現在說的開源模型,對比開源軟件來說,是一種介于閉源與開源的中間狀態,開發者可以在其基礎上做微調、做RAG,但又無法像開源軟件那樣對模型本身做修改,更無法得到其訓練源數據。
在“真開源”的開源軟件領域,一個顯著的特點是軟件源代碼共享,開源社區的開發者不僅可以反饋Bug,而且可以直接貢獻代碼。 比如,國產開源數據庫TiDB就分享過一組數據,在每年更新的40%的代碼中,有40%是由外部貢獻者貢獻的。
但由于大模型的算法黑盒,僅僅開放模型權重的“半開源”,導致了一個結果:用Llama 2的開發者再多,也不會幫助Meta提升任何Llama 3的能力和Know-how,Meta也無法靠Llama 2獲取任何的數據飛輪。
Meta想要訓練更強的Llama 3,還是只能靠自己團隊內部的人才、數據、GPU資源來做,還是需要做實驗(比如Scailing Law)、收集更多的優質數據、建立更大的計算集群。這本質上與OpenAI訓練閉源的GPT-4無異。
正如李彥宏在百度內部信中所言,開源模型并不能像開源軟件那樣做到“眾人拾柴火焰高”。
今天,很多開源模型都注意到了這個問題。比如谷歌在發布開源模型Gemma的時候,谷歌特意將其命名為“開放模型(Open Model)”而非“開源模型(Open Source Model)”。谷歌表示:開放模型具有模型權重的免費訪問權限,但使用條款、再分發和變體所有權根據模型的具體使用條款而變化,這些條款可能不基于開源許可證。
昆侖萬維AI Infra負責人成誠在知乎上對于開源模型做了以下分級:
僅模型開源(技術報告只列舉了 Evaluation)。主要利好做應用的公司(繼續訓練和微調)和普通用戶(直接部署) ?
技術報告開源訓練過程。比較詳盡的描述了模型訓練的關鍵細節。利好算法研究。
訓練代碼開源/技術報告開源全部細節。包含了數據配比的核心關鍵信息。這些信息價值連城,是原本需要耗費很多GPU資源才能得到的Know-how。
全量訓練數據開源。其他有算力資源的團隊可以基于訓練數據和代碼完全復現該模型。訓練數據可以說是大模型團隊最核心的資產。
數據清洗框架和流程開源。從源頭的原始數據(比如CC網頁、PDF電子書等)到 可訓練的數據的清洗過程也開源, 其他團隊不僅可以基于此清洗框架復現數據預處理過程,還可以通過搜集更多的源(比如基于搜索引擎抓取的全量網頁)來擴展自己的數據規模,得到比原始模型更強的基座模型。
他表示,實際上大部分的模型開源諸如LLama2、Mistral、Qwen等,只做到Level-1, 像DeepSeek可以做到Level-2。 而Level-4及以上的開源一個都沒有。至今沒有一家公司開源自己的全部訓練數據和數據清洗代碼,以至于開源模型無法被第三方完整復現。
這樣做的結果是: 掌握著模型進步的核心機密(數據、配比)被大模型公司牢牢掌握在自己手里,除了大模型公司自己的團隊,沒有任何其他來自開源社區的力量可以幫助其提升下一次訓練模型的能力。
因此,這就回到一個關鍵問題:如果開源不能借助外部力量幫助提升模型性能,為什么還要開源?
3.模型開源的意義是什么?
開源還是閉源,本身并不決定模型性能的高低。閉源模型并非因為閉源而領先,開源模型也并非因為開源而落后。甚至恰恰相反,模型是因為領先才選擇閉源,因為不夠領先不得不選擇開源。
因此,如果一家公司做出了性能很強的模型,它就有可能不再開源了。
比如法國的明星創業公司Mistral,其開源的最強7B模型Mistral-7B和首個開源MoE模型8x7B(MMLU 70)是開源社區聲量最大的模型之一。 但是,Mistral后續訓練的Mistral-Medium(MMLU-75)、Mistral-Large(MMLU-81) 均是閉源模型。
目前性能最好的閉源模型與性能最好的開源模型都是由大公司所主導,而大公司里又屬Meta的開源決心最大。如果OpenAI不開源是從商業回報的角度來考慮,那么Meta選擇開源讓用戶免費試用的目的又是什么呢?
在上一季度的財報會上,扎克伯格對這件事的回應是,Meta開源其AI技術是出于推動技術創新、提升模型質量、建立行業標準、吸引人才、增加透明度和支持長期戰略的考慮。
具體來說,開源帶來了諸多戰略好處。
首先,開源軟件通常會更安全,更可靠,而且會由于社區提供的持續反饋和審查而變得更高效。這點非常重要,因為安全正是AI領域的最關鍵議題之一。
其次,開源軟件會時常成為行業標準。而當其他企業基于Meta的技術棧建立標準時,新創新就會更容易融入Meta的產品中。這種微妙的優勢,就是巨大的競爭優勢。
再次,開源在開發者中非常受歡迎。因為科技工作者們渴望參與到廣泛采納的開放系統中,這就會讓Meta吸引更多頂尖人才,從而在新興技術領域保持領先地位。同時,由于Meta具有獨特的數據和產品集成,開源Llama基礎設施并不會削弱Meta的核心競爭力。
Meta是大公司中開源決心最大的公司,也是收益最大的公司。盡管訓練大模型需要耗費幾千億美元,但自從2023年把業務重心聚焦在開源大模型上以來,Meta的股價已經上漲了大約272%。Meta不僅從開源中收獲了名聲,也收獲了巨大的財務回報。
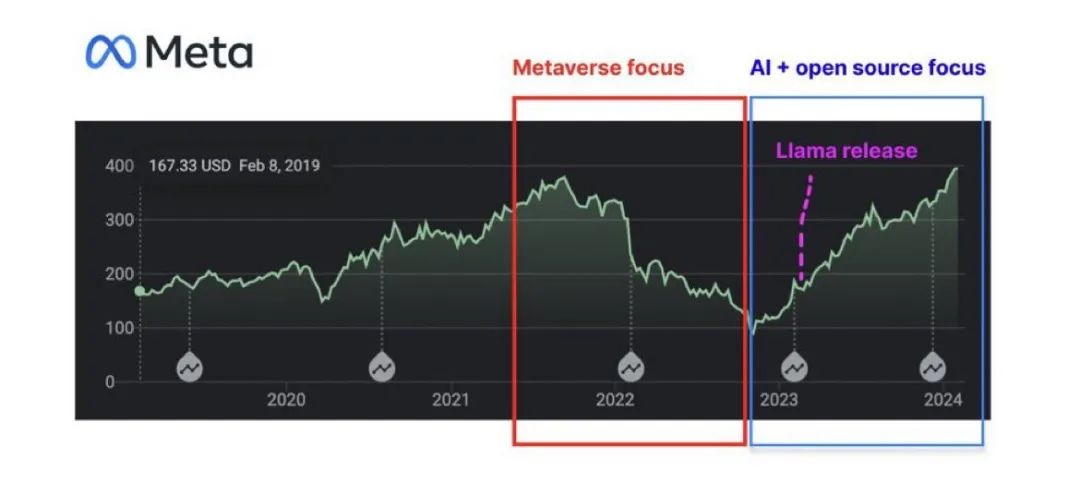
Meta股價走勢圖,圖片來自X
Meta最新發布的Llama 3也是開源模型。除了8B與70B兩個較小參數的模型,正在訓練中的Llama 3 400B大概率也會是開源模型,而且有望成為第一個超越GPT-4的開源模型。
4.閉源to C,開源to B
不論開源模型還是閉源模型,都需要找到合適的商業模式。
今天大模型行業逐漸形成的一個趨勢是,閉源模型更傾向做to C,開源模型更傾向于做to B。
月之暗面創始人楊植麟曾表示,要想做to C領域的Super App,就必須用自研(閉源)模型,因為“只有自研模型才能在用戶體驗上產生差異化”。
楊植麟認為,開源模型本質上是一種to B的獲客工具,或者是在Super App之外的長尾應用,才可能基于開源模型去發揮數據的優勢或場景的優勢。
但開源模型無法構建產品壁壘。比如,在海外有幾百個基于開源擴散模型Stable Diffusion的應用出現,但最后其實沒有任何一個跑出來。
其次,無法在開源技術的基礎上通過數據的虹吸效應讓模型持續地優化,因為開源模型本身是分布式部署,沒有一個集中的地方接收數據。
相比之下,開源模型更加適合在to B領域落地。
零一萬物開源負責人林旅強告訴「甲子光年」,toB是一單一單直接從客戶身上賺錢,提供的不是產品,而是服務和解決方案,而且是一個定制化的服務。做服務是用開源還是閉源?To B的客戶肯定首選開源模型,因為不僅能省下授權費用,還有更高的定制空間。
開源模型往往被當成一種最便宜的獲得銷售線索的手段。廠商可通過幾十B或以下規模的開源模型擴大用戶群體,以獲取銷售線索、證明技術實力。如果客戶有更多定制化需求,模型廠商也可以提供更多的服務。
同時,開源與閉源并非一個單選題,很多公司都采用了開源與閉源雙輪驅動的戰略,比如智譜AI、百川智能、零一萬物等等。
王小川就認為,從to B角度,開源閉源其實都需要。未來80%的企業會用到開源的大模型,因為閉源沒有辦法對產品做更好的適配,或者成本特別高,閉源可以給剩下的20%提供服務。二者不是競爭關系,而是在不同產品中互補的關系。”
不論開源還是閉源,大模型商業化面臨的根本問題是,如何降低推理成本。只有降低了推理成本,大模型才有可能真正大規模落地。
今天,開源與閉源陣營分別有自己的支持者。但如果參考iOS與安卓操作系統的發展軌跡來看,彼此之間的良性競爭大大促進了產品的迭代與用戶體驗的升級。這才是開閉源之爭最終的價值。
-
人工智能
+關注
關注
1817文章
50095瀏覽量
265311 -
李彥宏
+關注
關注
2文章
97瀏覽量
15310 -
GPT
+關注
關注
0文章
368瀏覽量
16871 -
大模型
+關注
關注
2文章
3650瀏覽量
5179
原文標題:李彥宏說開源模型會越來越落后,為什么很多人不認同?|甲子光年
文章出處:【微信號:jazzyear,微信公眾號:甲子光年】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
為什么原廠越來越需要一套自己的 Studio
為什么原廠越來越需要一套自己的 Studio
為什么機器人控制器越來越偏愛 RK3588?
百度李彥宏人民日報撰文 內化AI能力,加快形成新質生產力
LVGL近期很多人問,那它和Qt哪個好?
FPGA技術為什么越來越牛,這是有原因的

香港特區政府會見百度創始人李彥宏一行
PCB為啥現在行業越來越流行“淺背鉆”了?
LED芯片越亮,發熱量越大,還是芯片越暗,發熱量越大?

后摩爾時代:芯片不是越來越涼,而是越來越燙





 工商網監
工商網監
評論