 Cerebras推出WSE-3 AI芯片,比NVIDIA H100大56倍
Cerebras推出WSE-3 AI芯片,比NVIDIA H100大56倍

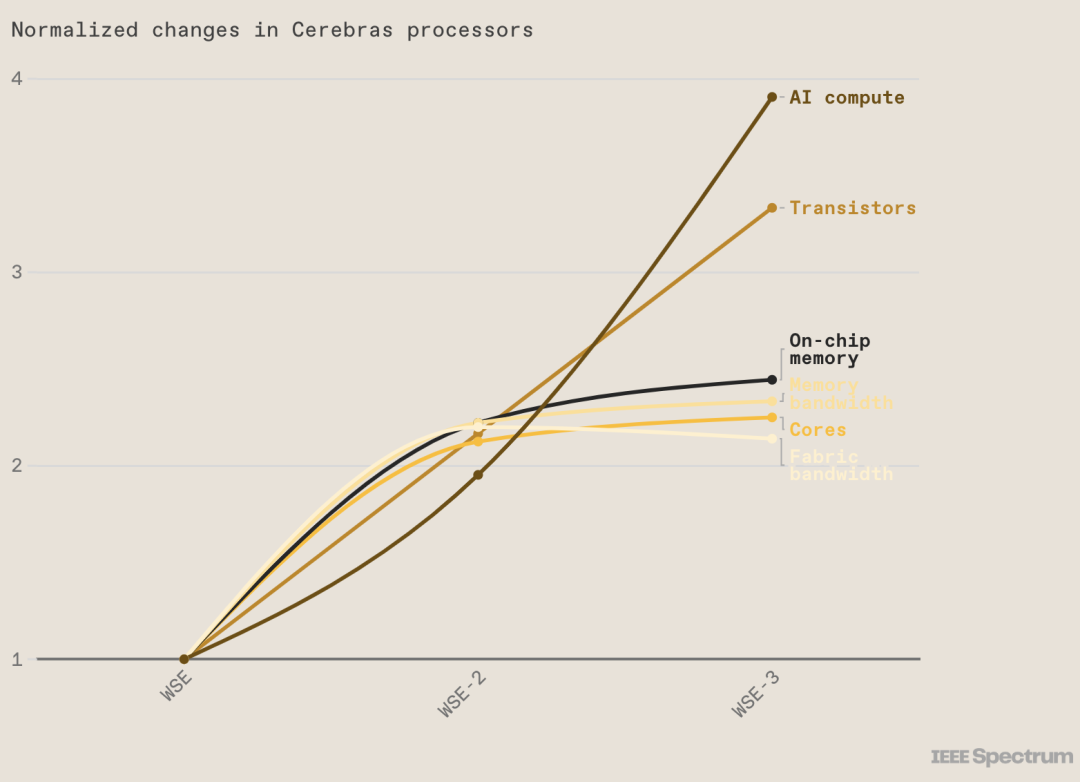
Cerebras 是一家位于美國加利福尼亞州的初創公司,2019 年進入硬件市場,其首款超大人工智能芯片名為 Wafer Scale Engine (WSE) ,尺寸為 8 英寸 x 8 英寸,比最大的 GPU 大 56 倍,擁有 1.2 萬億個晶體管和 40 萬個計算核心,是當時最快、最大的 AI 芯片。隨后在 2021 年,Cerebras 推出了 WSE-2,這是一款 7 納米芯片,其性能是原來的兩倍,擁有 2.6 萬億個晶體管和 85 萬個核心。
近日,Cerebras 宣布推出了第三代WSE-3,性能再次提高了近一倍。
01
Cerebras 推出 WSE-3 AI 芯片,比 NVIDIA H100 大 56 倍 WSE-3采用臺積電5nm工藝,擁有超過4萬億個晶體管和90 萬個核心,可提供 125 petaflops 的性能。這款芯片是臺積電可以制造的最大的方形芯片。WSE-3擁有44GB 片上 SRAM,而不是片外 HBM3E 或 DDR5。內存與核心一起分布,目的是使數據和計算盡可能接近。
自推出以來,Cerebras 就將自己定位為英偉達GPU 驅動的人工智能系統的替代品。這家初創公司的宣傳是:他們可以使用更少的芯片在 Cerebras 硬件上進行 AI訓練,而不是使用數千個 GPU。據稱,一臺Cerebras服務器可以完成與 10 個 GPU 機架相同的工作。
下圖是Cerebras WSE-3和英偉達 H100的對比。 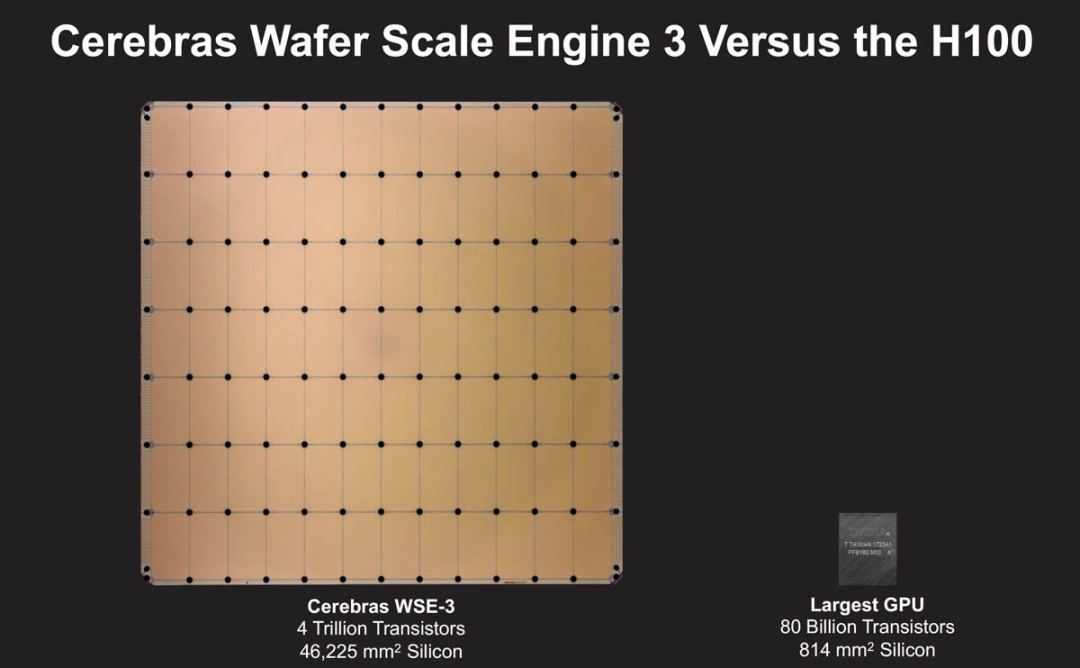
Cerebras 的獨特優勢是將整個硅片直接轉化為單一巨大的處理器,從而大幅提升計算性能和效率。英偉達、AMD、英特爾等公司往往會把一塊大晶圓切成多個小的部分來制造芯片,在充斥著 Infiniband、以太網、PCIe 和 NVLink 交換機的英偉達GPU 集群中,大量的功率和成本花費在重新鏈接芯片上,Cerebras的方法極大地減少了芯片之間的數據傳輸延遲,提高了能效比,并且在AI和ML任務中實現了前所未有的計算速度。
02
Cerebras CS-3 系統
Cerebras CS-3 是第三代 Wafer Scale 系統。其頂部具有 MTP/MPO 光纖連接,以及用于冷卻的電源、風扇和冗余泵。該系統及其新芯片在相同的功耗和價格下實現了大約 2 倍的性能飛躍。 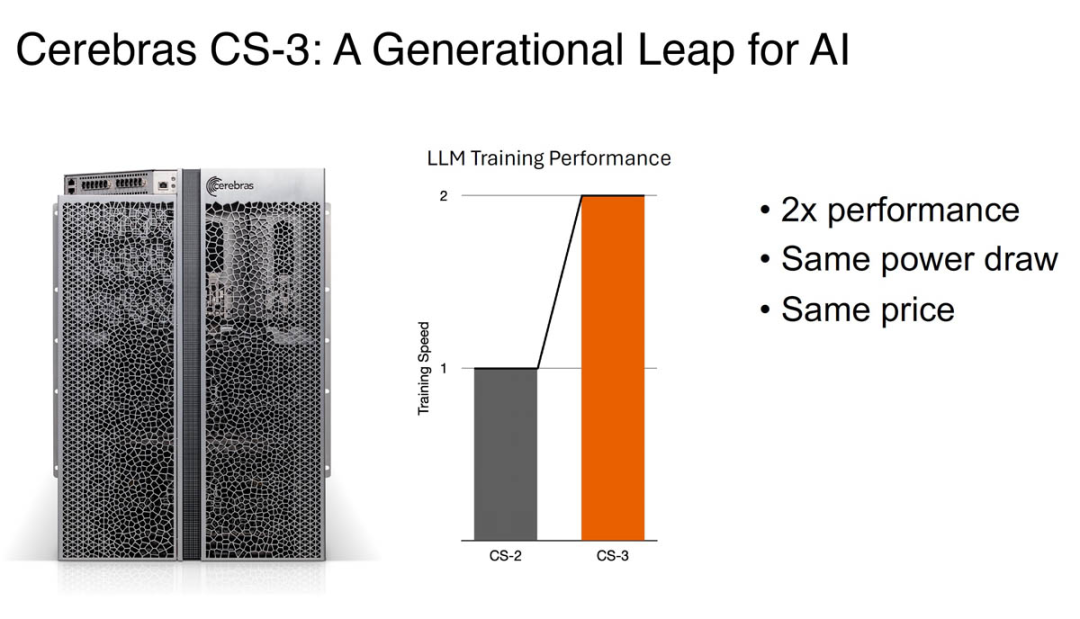
Cerebras WSE-3 的核心數量是英偉達的 H100 Tensor Core 的 52 倍。與 Nvidia DGX H100 系統相比,由 WSE-3 芯片驅動的 Cerebras CS-3 系統的訓練速度提高了 8 倍,內存增加了 1,900 倍,并且可以訓練多達 24 萬億個參數的 AI 模型,這是其 600 倍。Cerebras 高管表示,CS-3的能力比 DGX H100 的能力還要大。在 GPU 上訓練需要 30 天的 Llama 700 億參數模型,使用CS-3 集群進行訓練只需要一天。 
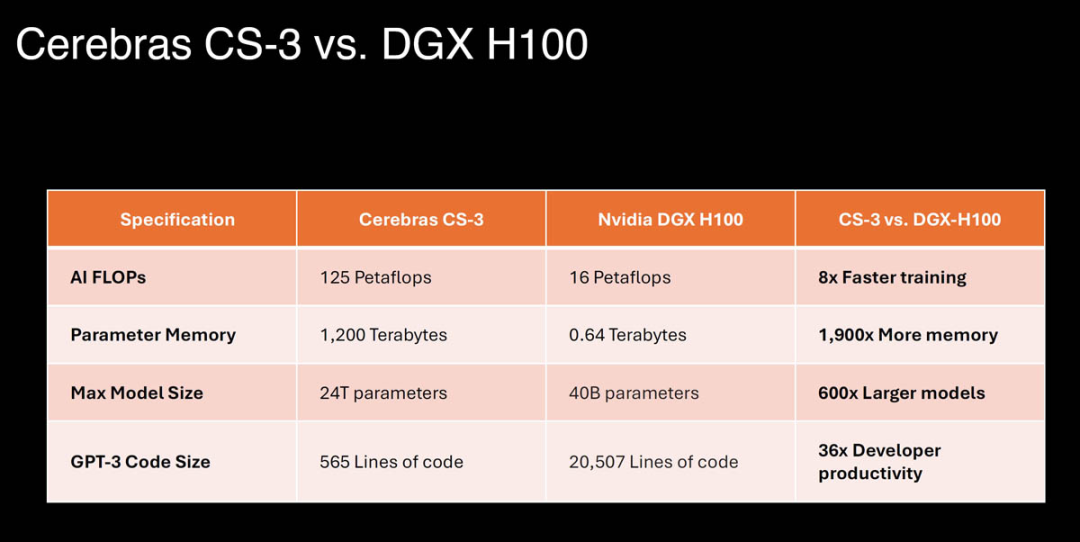
CS-3可以配置為多達2048個系統的集群,可實現高達 256 exaFLOPs 的 AI 計算,專為快速訓練 GPT-5 規模的模型而設計。 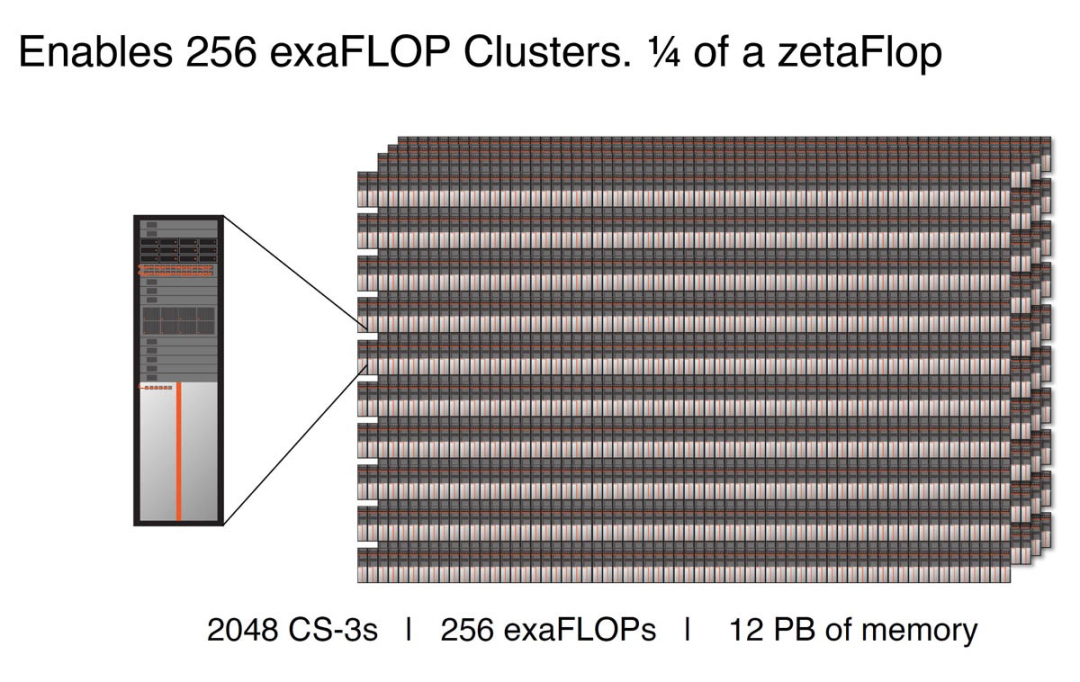
Cerebras CS-3 適用于 2048 節點 256EF 集群 
適用于 GPT 5 規模的 Cerebras CS-3 集群
03
Cerebras AI編程
Cerebras 聲稱其平臺比英偉達的平臺更易于使用,原因在于 Cerebras 存儲權重和激活的方式,Cerebras 不必擴展到系統中的多個 GPU,然后擴展到集群中的多個 GPU 服務器。 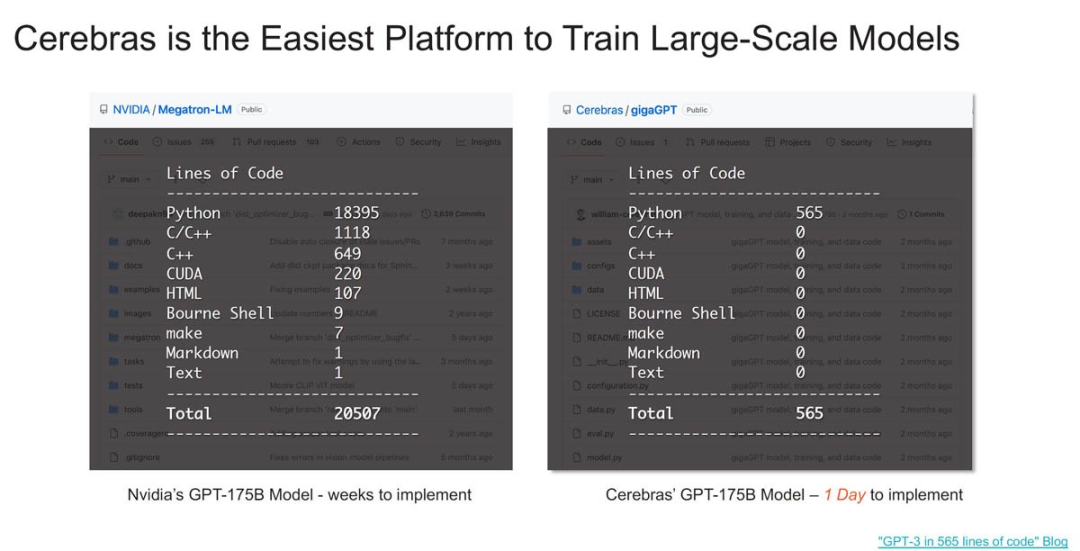 ?
?
除了代碼更改很容易之外,Cerebras 表示它的訓練速度比 Meta GPU 集群更快。當然,這只是理論上數據,當前還沒有任何 2048 個 CS-3 集群已經投入運行,而 Meta 已經有了 AI GPU 集群。 
Llama 70B Meta VS Cerebras CS-3 集群
04
Cerebras 與高通合作開發人工智能推理
Cerebras 和高通建立了合作伙伴關系,目標是將推理成本降低 10 倍。Cerebras 表示,他們的解決方案將涉及應用神經網絡技術,例如權重數據壓縮等。該公司表示,經過 Cerebras 訓練的網絡將在高通公司的新型推理芯片AI 100 Ultra上高效運行。
這項工作使用了四種主要技術來定制 Cerebras 訓練的模型:
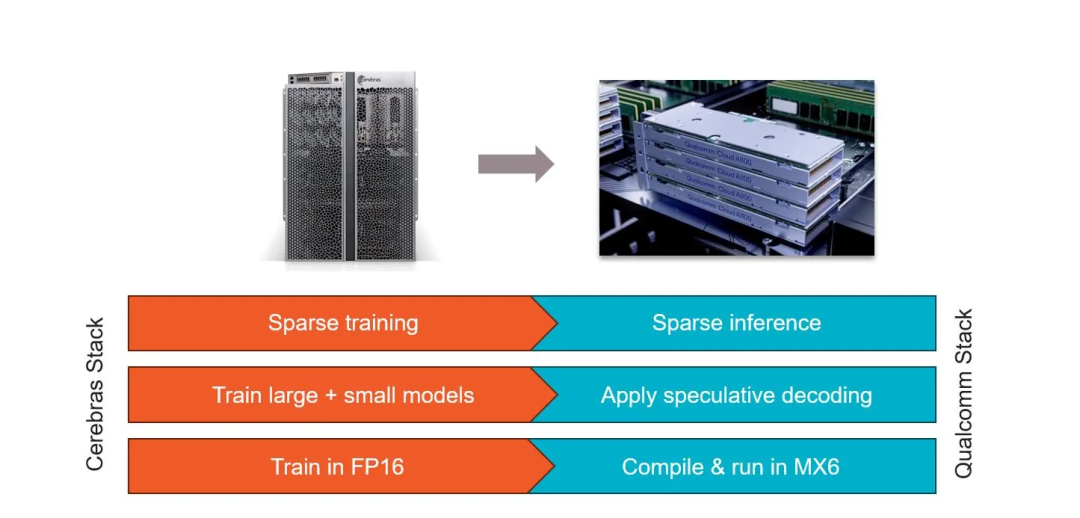
稀疏性是 Cerebras 的秘密武器之一,Cerebras 能夠在訓練過程中利用動態、非結構化的稀疏性。高通的 Cloud AI100 具有對非結構化稀疏性的硬件支持,這種稀疏協同可以使性能提高2.5倍。
推測解碼是一種前景廣闊但迄今為止難以有效實施的行業技術,也被用來加快速度。這種技術使用一個大型LLM和一個小型LLM的組合來完成一個大型LLM的工作。小模型不太精確,但效率較高。大模型用于檢查小模型的合理性。總體而言,組合效率更高,由于該技術總體上使用的計算量較少,因此速度可以提高 1.8 倍。
權重壓縮為 MxFP6,這是一種行業 6 位微指數格式,與 FP16 相比,可節省 39% 的 DRAM 空間。高通的編譯器將權重從 FP32 或 FP16 壓縮為 MxFP6,Cloud AI100 的矢量引擎在軟件中執行即時解壓縮到 FP16。該技術可以將推理速度提高 2.2 倍。
神經架構搜索(NAS)是一種推理優化技術。該技術在訓練期間考慮了目標硬件(Qualcomm Cloud AI 100)的優點和缺點,以支持在該硬件上高效運行的層類型、操作和激活函數。Cerebras 和 Qualcomm 在 NAS 方面的工作使推理速度提高了一倍。
審核編輯:劉清
-
NVIDIA
+關注
關注
14文章
5594瀏覽量
109737 -
晶體管
+關注
關注
78文章
10396瀏覽量
147760 -
AI芯片
+關注
關注
17文章
2128瀏覽量
36779 -
人工智能芯片
+關注
關注
1文章
124瀏覽量
31024 -
DDR5
+關注
關注
1文章
474瀏覽量
25735
原文標題:初創公司Cerebras 推出 WSE-3 AI 芯片,聲稱“吊打”英偉達 H100
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
廣立微QuanTest-YAD良率感知大數據診斷分析平臺獲得行業高度認可

馬斯克:AI5芯片設計進展順利,特斯拉AI戰略邁入新階段
NVIDIA 推出 Nemotron 3 系列開放模型

亞馬遜發布新一代AI芯片Trainium3,性能提升4倍

NVIDIA推出面向語言、機器人和生物學的全新開源AI技術
BPI-AIM7 RK3588 AI與 Nvidia Jetson Nano 生態系統兼容的低功耗 AI 模塊
【「AI芯片:科技探索與AGI愿景」閱讀體驗】+AI芯片的需求和挑戰
英偉達 H100 GPU 掉卡?做好這五點,讓算力穩如泰山!

NVIDIA 將恢復H20芯片在中國的銷售 NVIDIA CEO 黃仁勛在美國和中國加大推廣AI
GPU 維修干貨 | 英偉達 GPU H100 常見故障有哪些?
大算力芯片的生態突圍與算力革命
Oracle 與 NVIDIA 合作助力企業加速代理式 AI 推理

NVIDIA 與行業領先的存儲企業共同推出面向 AI 時代的新型企業基礎設施

NVIDIA 宣布推出 DGX Spark 個人 AI 計算機

NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺




 工商網監
工商網監
評論