 座艙SoC天花板是SA8295P?
座艙SoC天花板是SA8295P?

座艙SoC天花板是SA8295P?當然不是,AMD的一系列嵌入式處理器都可以碾壓SA8295P,高通自己的座艙SoC如SA8255P也可以在AI領域超越SA8295P,主要原因是SA8295P是2021年初的產品,其設計范圍在2020年就已確定了,卻沒想到座艙領域被中國車企卷得不成樣子,遂在定位低于SA8295P的產品上也持續加大算力。
2023年9月19日,極越01首發高通驍龍8295智艙芯片。驍龍8295是最強的車機芯片,采用5nm制程工藝、8倍于8155的算力。在安兔兔車機性能榜單中,其跑分近70萬,幾乎是驍龍8155的2倍。就在同一天下午,高合在展翼日正式發布自研高算力智能座艙平臺。該平臺將首搭高通QCS8550芯片,實現行業首發,根據官方數據對比顯示,全面優于SA8295。不出意外的話,比亞迪下一代也會用QCS8550。
兩者最大性能差別就是AI算力。
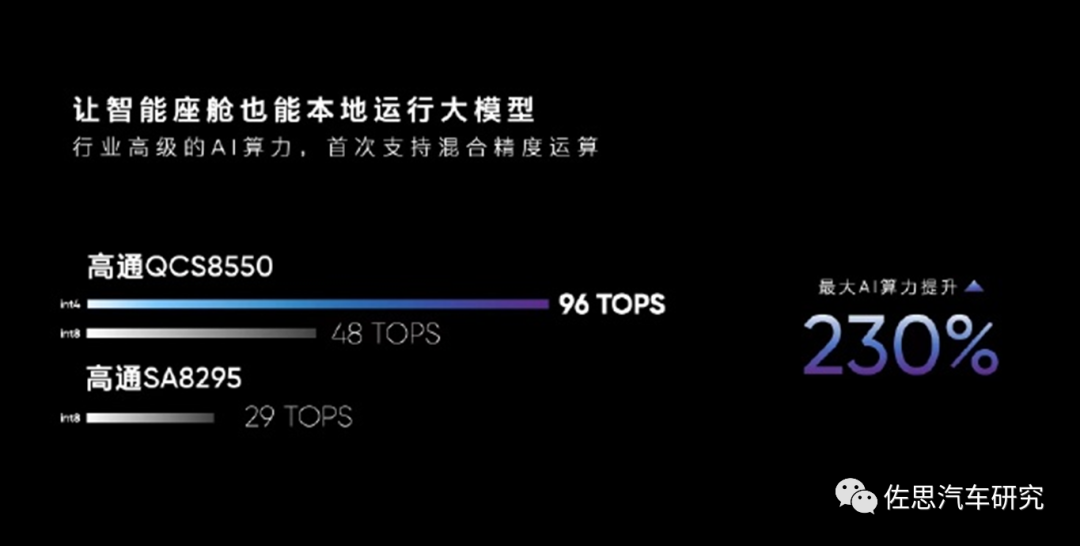
圖片來源:高通
這張圖有混淆視聽之嫌,需要解釋清楚,這個96TOPS是INT4精度下的算力,而SA8295P是不支持INT4精度的。不過即便比INT8精度,QCS8550也有48TOPS,也是遙遙領先。
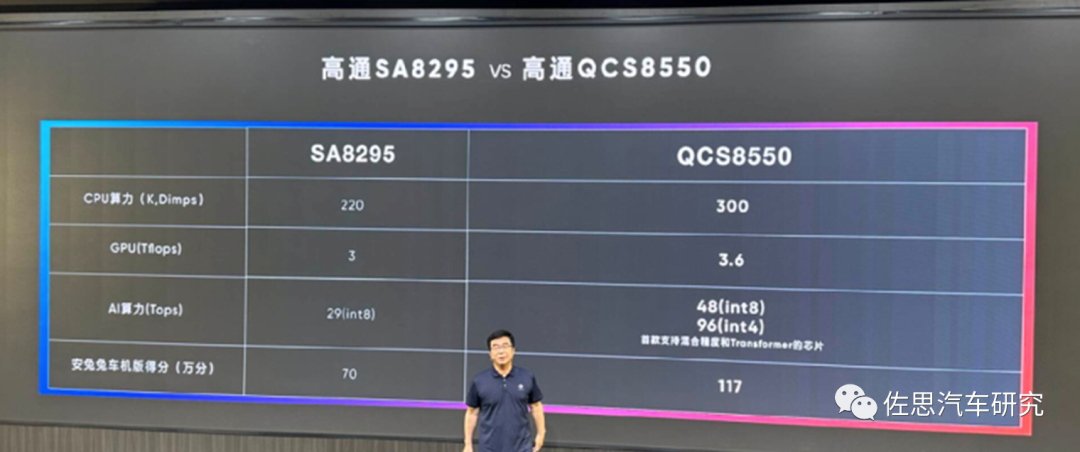
圖片來源:高通
CPU也碾壓SA8295P,高達300kDMIPS,GPU是Adreno 740,算力達3.6TFLOPS,同樣比SA8295P要高。就制造工藝而言,QCS8550是4納米,SA8295P還是5納米。
QCS8550是何方神圣?
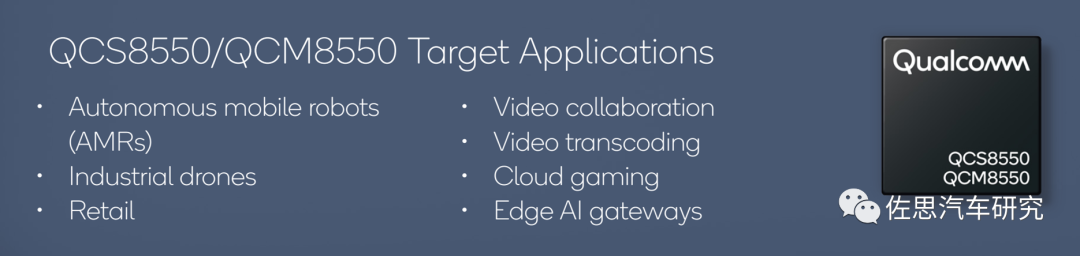
圖片來源:高通
上圖是高通對QCS8550/QCM8550的定位,顯然它不是車規級芯片,不過這無所謂,特斯拉Model S那顆AMD顯卡芯片連工業級都沒做到,也沒人指責過,這個至少是工業級,不是消費級的。而現在的Model 3/Y上用的AMD Ryzen V1000系列產品,是工業級產品,也不是車規級的,也沒人敢指責特斯拉。再有就是國內頂級新能源大廠一直都是用高通非車規級模組做座艙,用非車規級做座艙的至少有30%以上。
高通QCS8550/QCM8550的參數

圖片來源:高通
QCM就是帶modem。看一眼這個CPU配置,略有經驗的人便能看出,這就是手機領域驍龍8gen2的修改版,實際單看型號也能看出,8Gen2的型號就是SM8550。
驍龍8Gen3和8Gen2對比
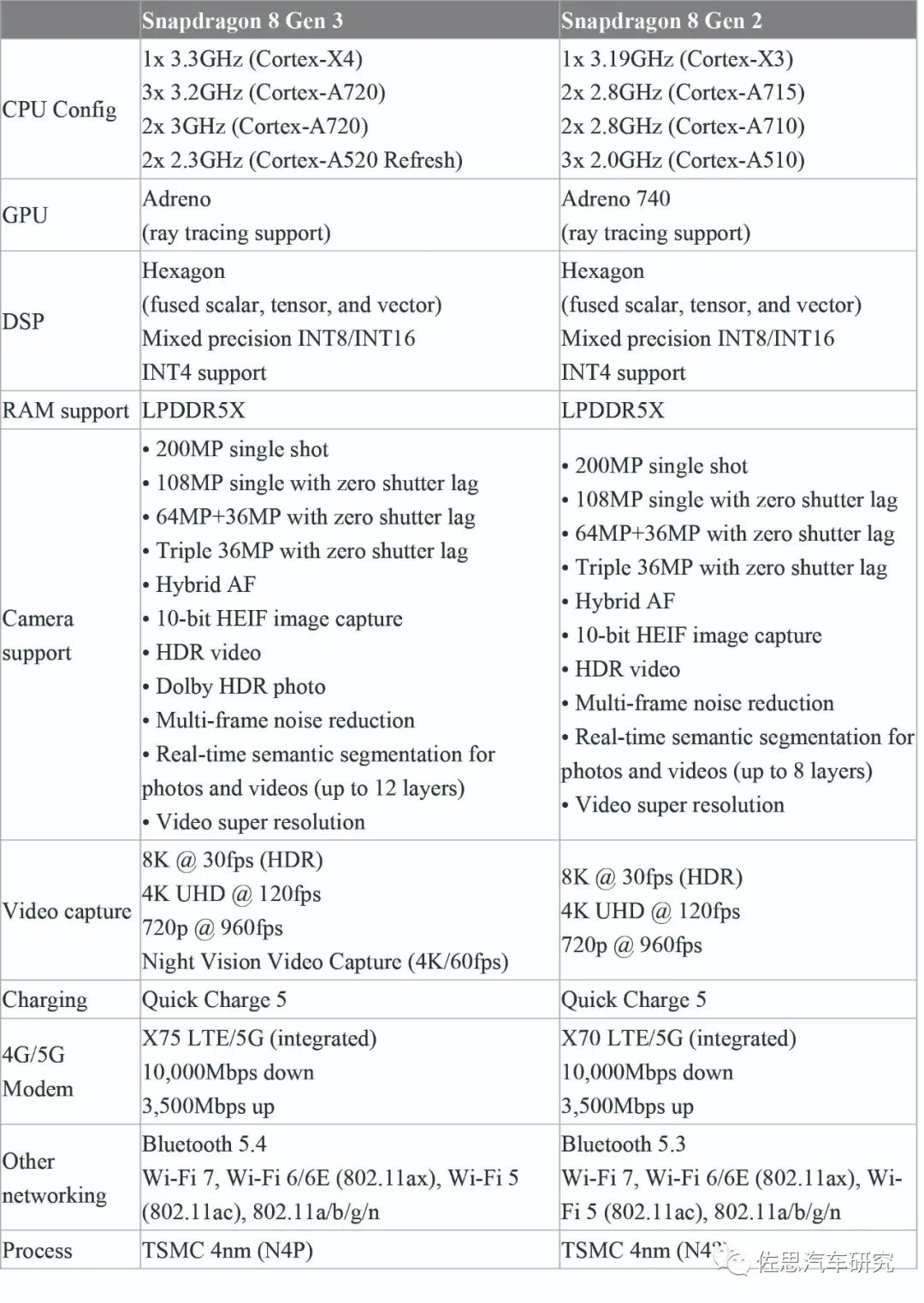
上表對比后不難發現,QCS8550就是8Gen2,兩者完全一致。
強大的AI算力不難做到,難以做到的是低成本下的高AI算力,而高通最擅長的就是低成本下的AI算力。對芯片來說硬件成本基本等同于die size面積大小,高通SoC 的die size一般都很小,一般都低于120平方毫米,而英偉達Orin和華為MDC 610要400平方毫米以上。座艙SoC中,高通的AI算力異乎尋常地強,這個48TOPS真能運行大模型么?當然不能運行ChatGPT3這種大模型,就算單張H100也不能,流暢運行ChatGPT3至少需要8張H100和兩片6千美元的CPU芯片。
高通的AI算力這么強主要源自其獨特的DSP架構和VLIW指令集,其淵源是ATI,早在2004年高通與ATI達成合作計劃,決定把ATI公司的3D圖形技術集成到高通下一代移動處理器之中,看中的就是ATI Imageon。后來ATI被AMD收購,ATI Imageon也更名為AMD Imageon。2009年,高通以6500萬美元收購了AMD的移動設備資產,取得了AMD的矢量繪圖與3D繪圖技術相關知識產權,不用再向AMD繳納技術授權費用。后來高通獨立發展出了一種全新的GPU品牌體系——Adreno。Adreno GPU此后不斷開花結果,歷經多年演化,占據了移動GPU市場的主導地位。
實際ATI的技術不止供養了日后的Adreno,ATI也開發了VLIW技術。以ATI Radeon HD 5800為例,GPU由20個SIMD計算引擎組成,每個SIMD計算引擎由16個線程處理器單元(Thread Processor - TP)組成。而每個TP則是一個5-way的VLIW Processor。雖然后來VLIW退出GPU領域,但在DSP領域大放異彩,在AI時代更是大展神威,助力高通成為移動霸主。
VLIW就是超長指令集。
幾種指令集的對比

圖片來源:網絡
VLIW類似于多條RISC指令的集合,VLIW的思路是硬件盡量簡單化,硬件只負責取指令和執行指令,其余一概不管,把困難推給編譯器,讓編譯器來做指令調度。首先我們還得知道編譯器是什么,比如C語言、C++、Java這樣的程序,當我們一行一行寫下代碼后,需要經過編譯器的“翻譯”才能變成可執行程序才可以執行,才可以實現代碼到程序的轉變。電腦(其實主要就是CPU)只認識0或1這兩個數字。所有寫的一切代碼,都需要編譯器幫我們編譯也就是翻譯成大量的01代碼(實際中間還有一步就是生成匯編代碼),才是CPU的“母語”,CPU才會熟練的幫我們飛速般去執行。
VLIW把多條獨立的指令打包為一個指令集并交給編譯器,編譯器根據指令的不同形式判斷指令的運行周期,將運行周期比較一致的指令安排在一起發射并執行。VLIW最大好處是實現了并行計算,比如VLIW的數據總線長如果是1024比特,那么對4比特數據,一次可以取256個,取到數據進行并行計算(前提是你得有256套ALU加寄存器之類的硬件系統),一個指令就可以完成256個周期運算,如同256個內核。缺點很明顯,如果這256個計算中有一個卡殼了,那么其余255個必須停下來等待這個計算完成,這就是鎖步,大家的步伐必須完全一致,而傳統的超標量CPU不會,它可以亂序執行。還有一個缺點就是即使只有10個指令,其余那246個也必須空轉,這意味著功耗很高。這與近期的SIMD可變矢量長度非常近似,但SIMD只是一次性取了256個4比特數據,VLIW完全依靠軟件就實現了并行計算。1994年英特爾和惠普簽訂協議,宣布共同開發面向高性能計算(HPC)的處理器,也就是后來的Itanium,安騰。他們以VLIW指令作為基礎,提出了顯式并行指令集運算EPIC( Explicitly parallel instruction computing)。不過這對開放式軟件系統挑戰太大,2000年以后就消失了,但VLIW+DSP慢慢崛起了。
VLIW處理器示意圖
圖片來源:網絡
DSP與傳統CPU或GPU最大不同是其采用哈佛架構,將存儲器空間劃分成兩個,分別存儲程序和數據。它們有兩組總線連接到處理器核,允許同時對它們進行訪問,每個存儲器獨立編址,獨立訪問。這種安排將處理器的數據吞吐率加倍,更重要的是同時為處理器核提供數據與指令。DSP芯片廣泛采用2-6級流水線以減少指令執行時間,從而增強了處理器的處理能力。這可使指令執行能完全重疊,每個指令周期內,不同的指令都處于激活狀態。更像是脈動處理器,數據一次導入,流轉周期很長,效率極高。DSP最強之處還有它可實現零開銷循環,而AI引擎通常就是零開銷循環結構,不會發生任何用于比較和分支的分支控制開銷。
但DSP本質還是近似CPU的設計,不適合做并行計算,它最適合的是圖像壓縮算法或快速傅里葉變換(FFT)這種算法,即串行數據流形式的計算,而VLIW是天生并行指令集,二者結合后就非常適合AI運算,AI運算即是并行矩陣運算,也是數據流形式。
高通的AI表現與編譯器關系非常密切,但大家都知道編譯器是靜態的,無法實現動態調整,因此某些模型可能在高通芯片表現很差,很多搞座艙的都沒使用過高通的DSP運算能力,智能駕駛領域用DSP的人也很少,因為太難用了。而高通唯一一款通用AI計算器AI100上,高通沒有使用其最擅長的DSP架構,而是傳統的MAC陣列架構,主要也是為了盡可能擴大應用面。
大模型是可以跑,但誰都不會公布延遲是多少毫秒,AI算力這游戲還是蠻有趣的。
審核編輯:劉清
-
soc
+關注
關注
40文章
4576瀏覽量
229105 -
嵌入式處理器
+關注
關注
0文章
259瀏覽量
31720
原文標題:碾壓SA8295P的高通SoC來了,高合首發
文章出處:【微信號:zuosiqiche,微信公眾號:佐思汽車研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
車企激戰高壓平臺!比亞迪要把“超充戰”打到天花板

AD8295:精密儀表放大器的卓越之選
【工程師必看】三星電容在車載智能座艙/中控系統中的選型與案例分析

MediaTek發布天璣座艙P1 Ultra芯片
車規級WiFi模塊在智能座艙無線投屏互聯中的應用

博泰車聯網助力東風奕派eπ007+正式上市
破解“散熱天花板”:金剛石銅復合材料的百億征程(附分析報告)

中科創達旗下暢行智駕推出基于高通SA6155P系列芯片的SIP模組產品
解密高通域控制器一級電源設計 電源設計和計算

突破無風扇工控機技術天花板,聚徽廠家這些方案你知道嗎?

閃迪天花板級PCIe5.0 SSD上市,性能與能效均位于行業前沿

主流汽車電子SoC芯片對比分析




 工商網監
工商網監
評論