 Ambarella展示了在其CV3-AD芯片上運行LLM的能力
Ambarella展示了在其CV3-AD芯片上運行LLM的能力

Ambarella前不久展示了在其CV3-AD芯片上運行LLM的能力。這款芯片是CV3系列中最強大的,專為自動駕駛設計。
CV3-AD一年前開始出樣,使用Ambarella現有的AI軟件堆棧,運行Llama2-13B模型時,可以實現每秒推理25個token。
Ambarella的CEO Fermi Wang表示:“當transformer在今年早些時候變得流行時,我們開始問自己,我們擁有一個強大的推理引擎,我們能做到嗎?我們進行了一些快速研究,發現我們確實可以。我們估計我們的性能可能接近Nvidia A100。”
Ambarella工程師正在展示Llama2-13B在CV3-AD上的實時演示,CV3-AD是一款50W的自動駕駛芯片。
Ambarella芯片上的CVFlow引擎包括其NVP(Neural Vector Processor)和一個GVP(General Vector Processor),演示中的LLM正在NVP上運行。NVP采用數據流架構,Ambarella已將諸如卷積之類的高級運算符指令組合成圖表,描述數據如何通過處理器進行該運算符的處理。所有這些運算符之間的通信都使用片上內存完成。CV3系列使用LPDDR5(而非HBM),功耗約為50W。
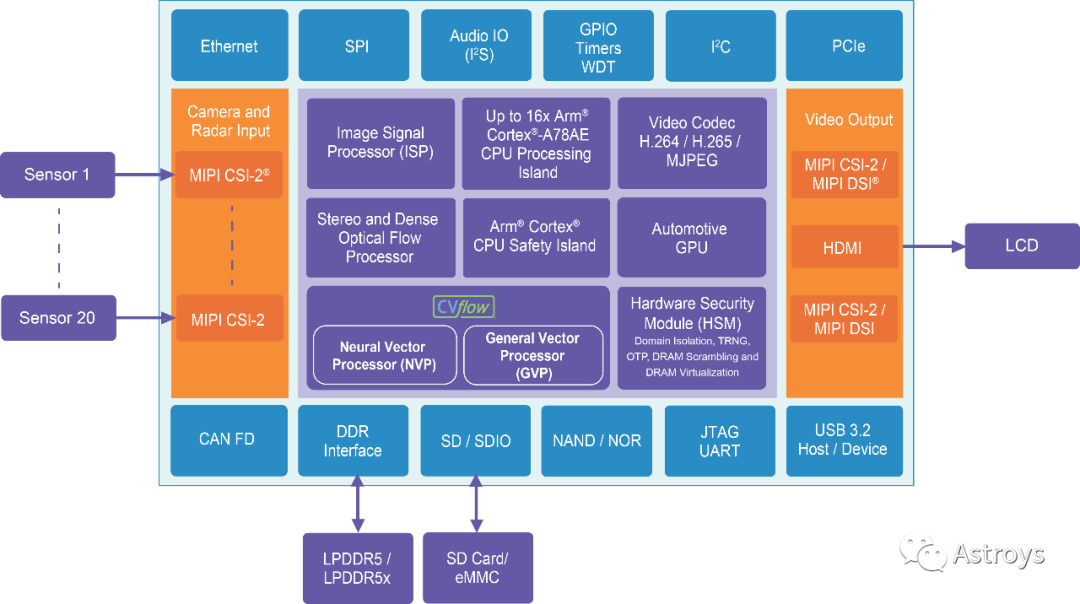
Ambarella的CTO Les Kohn表示,LLM演示確實需要一些新軟件。實現transformer架構核心操作的構建模塊,目前這些操作針對的是像Llama2這樣的模型。
他說:“隨著時間的推移,我們將擴展這些功能以覆蓋其它模型,但Llama2正在成為開源世界的事實標準。這絕對是一項不小的投資,但與從頭開始開發軟件相比,還差得遠。”
Edge LLM發展路線圖?????
Wang表示:“現在我們知道我們擁有這項技術,我們可以解決一些實際問題。如果你與LLM的研發人員交談,問他們最頭疼的是什么,一個顯然是價格,另一個是功耗。”
CV3-AD設計用于50W的功率范圍(包括整個芯片的功率,不僅僅是AI加速器)。因此,Wang希望Ambarella能夠以大約四分之一的功耗,為LLM提供與A100相似的性能。
他說:“這意味著對于固定的數據中心功率,我可以增加四倍的AI性能。這是巨大的價值。盡管這種想法很簡單,但我們相信我們可以為渴望使用LLM的任何人提供價值。在過去的六個月里,渴望使用LLM的人數迅速增加。”
雖然超大規模計算中心可能是首批跟進LLM趨勢的,但Ambarella在安防攝像頭和汽車領域的現有客戶開始考慮如何在他們的邊緣系統中實施LLM,以及LLM將如何實施他們的發展路線圖。
Wang說:“我們相信LLM將成為我們需要在路線圖中為當前客戶提供的重要技術。當前的CV3可以運行LLM,而無需Ambarella進行太多額外的工程投資,所以這對我們來說并非分心之事。我們當前的市場在他們的路線圖中已經有了LLM。” 多模態AI???? Kohn指出,在邊緣計算中,具有生成文本和圖像能力的大型多模態生成型AI潛力日益增大。
他說:“對于像機器人這樣的應用,transformer網絡已經可以用于計算機視覺處理,這比任何傳統計算機視覺模型都要強大,因為這種模型可以處理零樣本學習,這是小模型無法做到的。”
零樣本學習指的是模型能夠推斷出在其訓練數據中未出現的對象類別的信息。這意味著模型可以以更強大的方式預測和處理邊緣情況,這在自動系統中尤其重要。
他補充說:“自動駕駛本質上是一種機器人應用:如果你看看L4/L5系統需要什么,很明顯你需要更強大、更通用的AI模型,這些模型能以更類似于人類的方式理解世界,超越我們今天的水平。我們將這看作是為各種邊緣應用獲取更強大的AI處理能力的一種方式。”
LLM發展路線圖??
問及Ambarella是否會制造專門針對LLM的邊緣芯片時,Wang表示:“這可能是我們需要考慮的事情。我們需要一個具有更多AI性能的LLM路線圖。LLM本身需要大量的DRAM帶寬,這幾乎使得在芯片上集成其他功能變得不可能(因為其他功能也需要DRAM帶寬)。”
Wang說,盡管在某些人看來,一個大型信息娛樂芯片應該能夠同時處理其他工作負載和LLM,但目前這是不可能的。LLM所需的性能和帶寬或多或少地需要一個單獨的加速器。
Kohn補充說:“這取決于模型的大小。我們可能會看到目前使用的模型比較小的版本應用于像機器人學這樣的領域,因為它們不需要處理大型模型所做的所有通用事務。但與此同時,人們希望有更強大的性能。所以,我認為最終我們將看到未來更優化的解決方案,它們將被應用于不同的價格/性能點。”
在邊緣計算之外,CV3系列也有可能在數據中心中使用。Kohn說,CV3系列有多個PCIe接口,這在多芯片系統中可能很有用。他還補充說,該公司已經有一個可以利用的PCIe卡。
Wang表示:“對我們來說,真正的問題是,‘我們能否將當前產品和未來產品銷售到超大規模計算中心或基于云的解決方案中?’這是一個我們還沒有回答的問題,但我們已經確認了技術的可行性,并且我們有一些差異化。我們知道我們可以將這種產品銷售到邊緣設備和邊緣服務器。我們正在制定一個計劃,希望如果我們想要進入基于云的解決方案,我們可以證明進一步投資是合理的。”
審核編輯:劉清
-
處理器
+關注
關注
68文章
20170瀏覽量
247988 -
機器人
+關注
關注
213文章
30665瀏覽量
220033 -
LPDDR5
+關注
關注
2文章
92瀏覽量
13194 -
自動駕駛芯片
+關注
關注
3文章
48瀏覽量
5405 -
LLM
+關注
關注
1文章
341瀏覽量
1272
原文標題:Ambarella展示在自動駕駛芯片上的LLM推理能力
文章出處:【微信號:Astroys,微信公眾號:Astroys】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
客戶案例 | Imagination GPU助力安霸 CV3-AD655 環視系統

【CIE全國RISC-V創新應用大賽】+ 一種基于LLM的可通過圖像語音控制的元件庫管理工具
NVIDIA TensorRT LLM 1.0推理框架正式上線
米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
如何在魔搭社區使用TensorRT-LLM加速優化Qwen3系列模型推理部署
使用 llm-agent-rag-llamaindex 筆記本時收到的 NPU 錯誤怎么解決?
LM Studio使用NVIDIA技術加速LLM性能
詳解 LLM 推理模型的現狀
無法在OVMS上運行來自Meta的大型語言模型 (LLM),為什么?
新品| LLM630 Compute Kit,AI 大語言模型推理開發平臺

海力士展示AI專用計算內存解決方案AiMX-xPU

小白學大模型:構建LLM的關鍵步驟





 工商網監
工商網監
評論