") 介紹一款基于昆侖芯AI加速卡的高效模型推理部署框架
介紹一款基于昆侖芯AI加速卡的高效模型推理部署框架

引言
昆侖芯科技公眾號全新欄目“用芯指南”重磅推出!面向AI行業(yè)技術從業(yè)者,系列好文將提供手把手的昆侖芯產(chǎn)品使用指南。第一期圍繞昆侖芯自研效能工具——昆侖芯Anyinfer展開,這是一款基于昆侖芯AI加速卡的高效模型推理部署框架。種種行業(yè)痛點,昆侖芯Anyinfer輕松搞定。
當下,AI技術蓬勃發(fā)展,AI算法應用需求井噴。行業(yè)技術從業(yè)者在項目的不同階段面臨種種現(xiàn)實問題,這些問題無疑也增加了項目的復雜性和不確定性:
算法選型:
技術從業(yè)者極有可能遇到不同框架格式的算法模型;即便是同一個開源算法的實現(xiàn),也可能是經(jīng)過不同訓練框架導出,因此模型的保存格式也會有所不同。
算法驗證:
想在AI加速卡上評估算法的推理效果,就要針對不同推理框架的接口構(gòu)造上百行代碼的推理程序;如果效果不達預期,可能還需要更換其他框架的模型,這就需要重新構(gòu)造一份不同的推理程序......
真正到了算法部署階段,則將迎來更加嚴峻的挑戰(zhàn)。
以上種種業(yè)內(nèi)痛點,是否也在困擾您?看完這篇,基于昆侖芯AI加速卡的高效模型推理部署框架——昆侖芯Anyinfer,幫您一鍵全搞定!
1昆侖芯Anyinfer
1.昆侖芯Anyinfer架構(gòu)圖
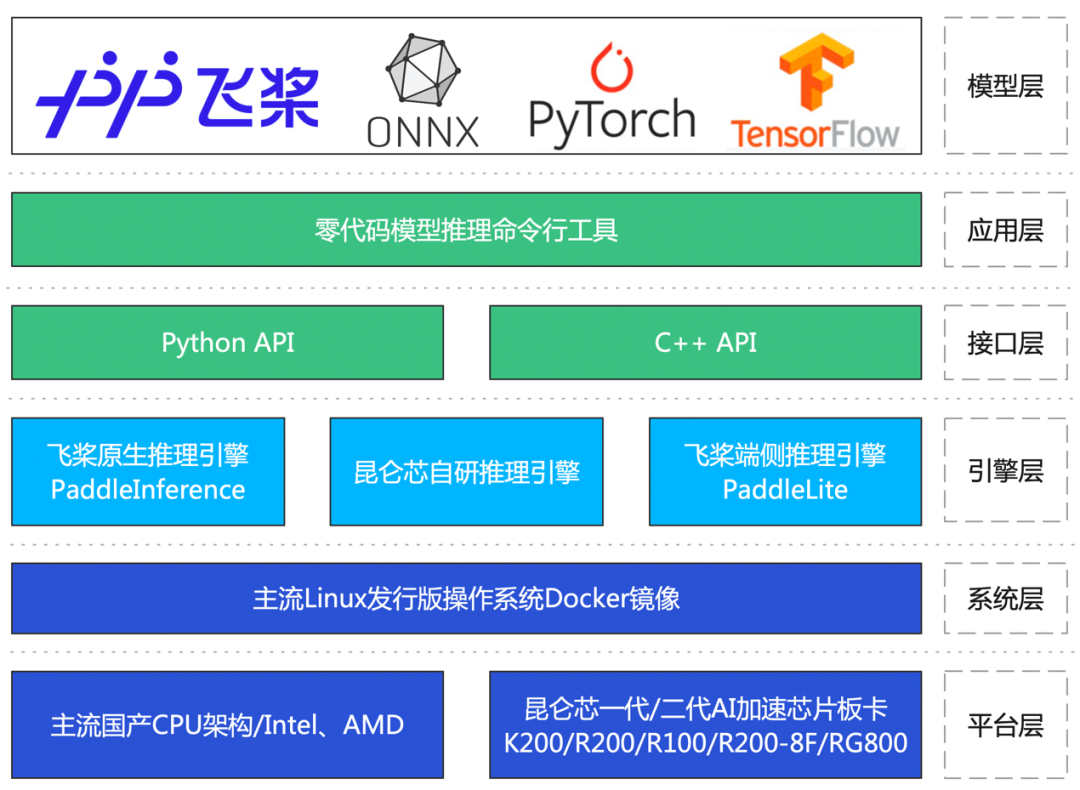
2.昆侖芯Anyinfer核心優(yōu)勢
A強兼容性
在多個平臺上支持零代碼推理PaddlePaddle、PyTorch、ONNX、TensorFlow等多個主流框架格式的眾多領域模型。
B高人效
內(nèi)置多款推理引擎,針對不同領域,用戶無需學習特定框架編程接口,更不用編寫多份推理程序,零代碼驗證模型在不同框架中的效果。
C零代碼
只需一行命令,即可完成模型驗證評估,無需依據(jù)模型構(gòu)建輸入數(shù)據(jù),也無需撰寫模型轉(zhuǎn)換、前后處理及推理腳本代碼。
D部署友好
支持C++與Python兩套接口邏輯統(tǒng)一的API,用戶在生產(chǎn)環(huán)境中部署模型更方便。
2運行演示
1. 快速完成算法模型驗證評估
一行命令,即可輕松驗證模型精度、一鍵評估模型的推理性能等關鍵指標。
AONNX、PyTorch和TensorFlow模型在昆侖芯AI加速卡和CPU上的計算精度對比
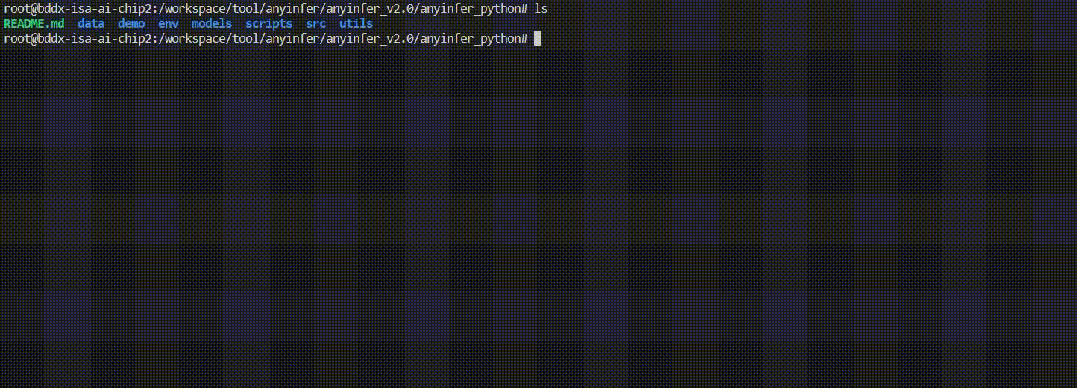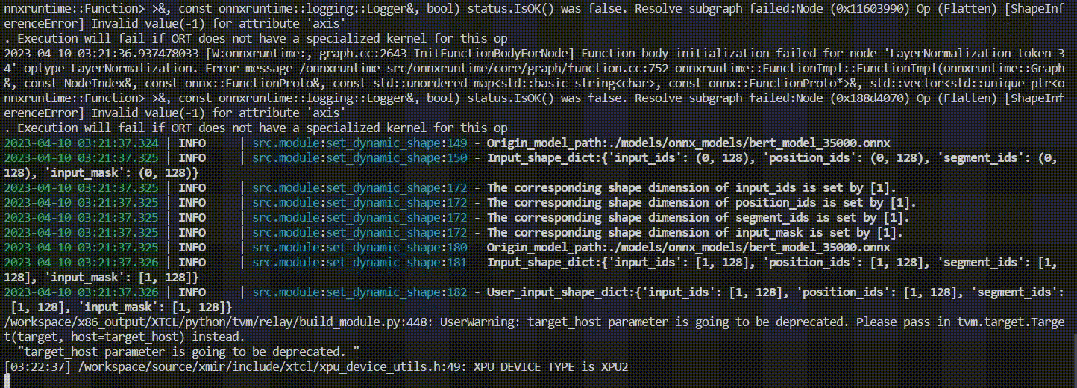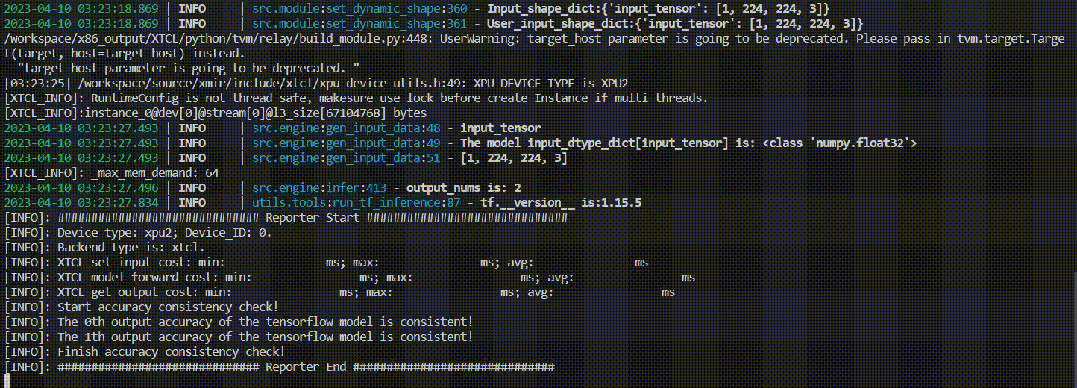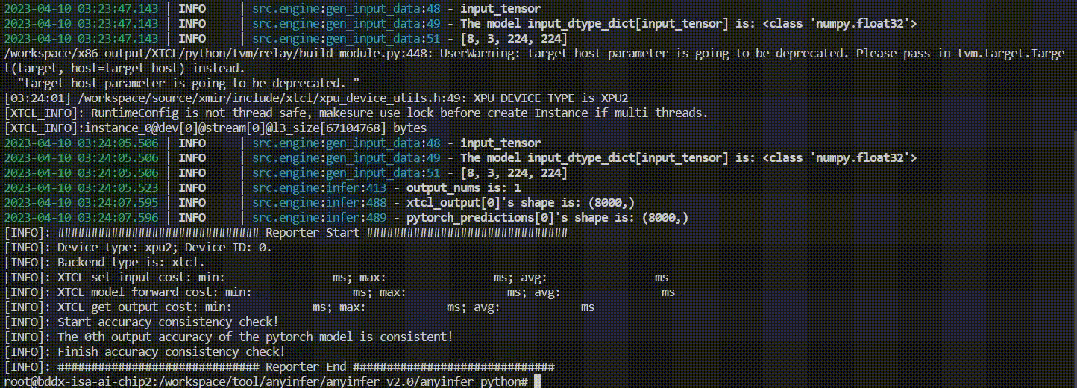
BPaddlePaddle模型在昆侖芯AI加速卡上的推理性能統(tǒng)計

2.獲取模型性能分析報告,為下一步模型優(yōu)化做足準備
在初步完成算法模型的驗證評估后,可利用昆侖芯Anyinfer深入研究模型中各個層面的性能,包括推理框架層面和算子執(zhí)行層面等,助力進一步調(diào)優(yōu)模型的推理性能。

一鍵開啟昆侖芯自研推理引擎的性能分析模式,統(tǒng)計框架層和算子層面的計算耗時

一鍵開啟Paddle inference的性能分析模式,統(tǒng)計框架層和算子層面的耗時
3. 模型的基礎性能調(diào)優(yōu)
完成對模型的性能評估后,可以使用基礎的調(diào)優(yōu)方法來提高模型的推理性能。昆侖芯Anyinfer提供了一項非常便捷的功能:最佳QPS搜索。此功能將以往需要修改多個參數(shù)并多次執(zhí)行的操作化繁為簡,快速確定最適合項目需求的配置,提高用戶體驗。

搜索最佳QPS
4. 模型的高性能部署
完成算法模型的驗證后,最關鍵的一步來了!昆侖芯Anyinfer可輕松應對生產(chǎn)環(huán)境部署這一挑戰(zhàn)。僅需三個統(tǒng)一的C++接口,即可順利將驗證后的模型部署至生產(chǎn)環(huán)境中。
此外,昆侖芯Anyinfer還提供了方便的調(diào)試功能,例如算子的自動精度對比、模型轉(zhuǎn)換等。同時,也提供了豐富的使用示例,包括多輸入、多線程、多進程、多流推理等。種種行業(yè)痛點,昆侖芯Anyinfer輕松搞定。簡潔而強大的解決方案,幫您把模型推理部署變得簡單、高效。
目前,昆侖芯Anyinfer已在多個行業(yè)客戶中投入使用,切實降低了行業(yè)客戶人力成本,提高了項目交付效率,助力客戶在行業(yè)競爭中取得領先優(yōu)勢。
審核編輯:湯梓紅
-
算法
+關注
關注
23文章
4784瀏覽量
98038 -
AI
+關注
關注
91文章
39755瀏覽量
301356 -
模型
+關注
關注
1文章
3751瀏覽量
52099 -
昆侖芯科技
+關注
關注
0文章
40瀏覽量
1093
原文標題:一鍵搞定!昆侖芯Anyinfer助您零代碼實現(xiàn)昆侖芯AI加速卡模型推理
文章出處:【微信號:昆侖芯科技,微信公眾號:昆侖芯科技】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
算力密度翻倍!江原D20加速卡發(fā)布,一卡雙芯重構(gòu)AI推理標桿

MLU220-M.2邊緣端智能加速卡支持相關資料介紹
LCD轉(zhuǎn)VGA視頻加速卡
昆侖芯2代AI芯片為開發(fā)者提供靈活便捷的部署方案
昆侖芯科技產(chǎn)業(yè)級AI模型部署全攻略

昆侖芯新品R100正式發(fā)布,強大算力賦能邊緣推理場景
昆侖芯完成OpenCloudOS社區(qū)首個兼容性認證,軟硬協(xié)同加速AI技術落地
HPC領域的一款大殺器-HBX-G500大帶寬加速卡

瞬變對AI加速卡供電的影響
首發(fā) | 昆侖芯 | 國產(chǎn)AI卡Deepseek訓練推理全版本適配、性能卓越,一鍵部署等您來(附文檔下載方式)

邊緣AI新突破:MemryX AI加速卡與RK3588打造高效多路物體檢測方案

此芯科技發(fā)布“合一”AI加速計劃,賦能邊緣與端側(cè)AI創(chuàng)新

專為邊緣而生:深度解析昆侖芯K100 AI加速卡,釋放128 TOPS極致能效

邁向云端算力巔峰:昆侖芯K200 AI加速卡全面解讀

昆侖芯R200 AI加速卡技術規(guī)格解析




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論