 NeurIPS 2023 | 全新的自監督視覺預訓練代理任務:DropPos
NeurIPS 2023 | 全新的自監督視覺預訓練代理任務:DropPos


論文標題:
DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions
論文鏈接:https://arxiv.org/pdf/2309.03576
代碼鏈接:https://github.com/Haochen-Wang409/DropPos
今天介紹我們在自監督視覺預訓練領域的一篇原創工作,目前 DropPos 已被 NeurIPS 2023 接收,相關代碼已開源,有任何問題歡迎在 GitHub 提出。

TL;DR
我們提出了一種全新的自監督代理任務 DropPos,首先在 ViT 前向過程中屏蔽掉大量的 position embeddings(PE),然后利用簡單的 cross-entropy loss 訓練模型,讓模型重建那些無 PE token 的位置信息。這個及其簡單的代理任務就能在多種下游任務上取得有競爭力的性能。

Motivation
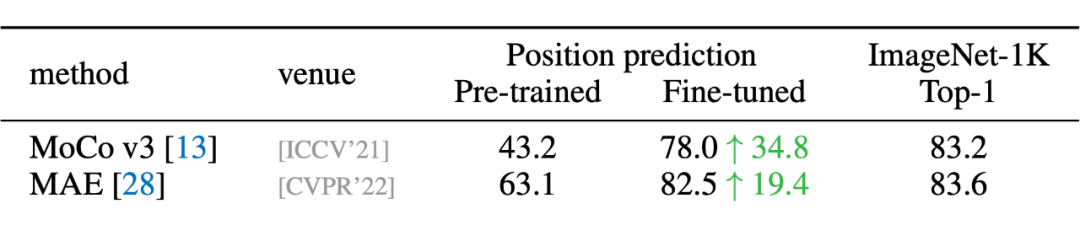
在 MoCo v3 的論文中有一個很有趣的現象:ViT 帶與不帶 position embedding,在 ImageNet 上的分類精度相差無幾。

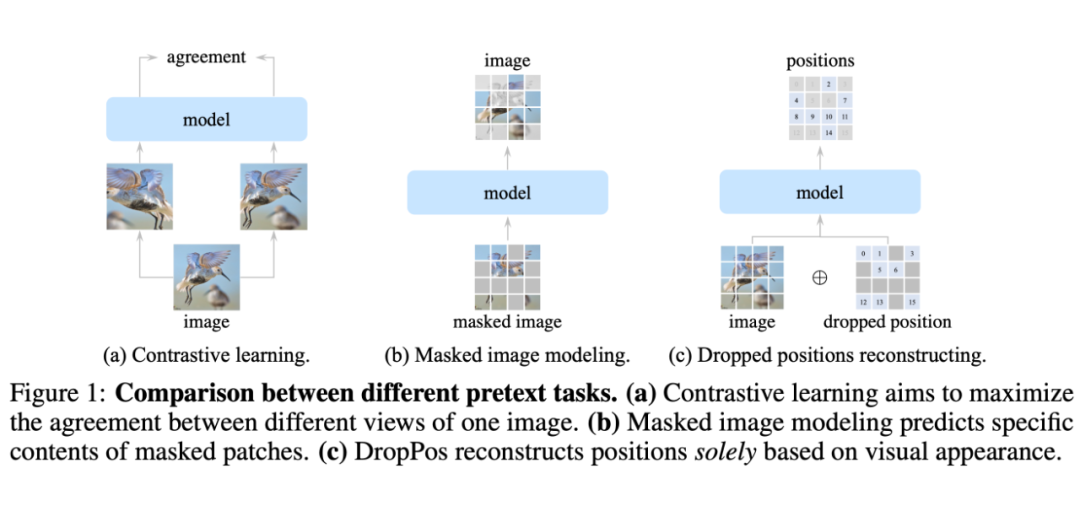
- 對比 CL,DropPos 不需要精心設計的數據增強(例如 multi-crop)。
- 對比 MIM,DropPos 不需要精心設計的掩碼策略和重建目標。

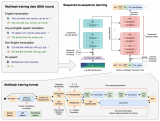
Method

- 如果簡單地把所有 PE 丟棄,讓模型直接重建每個 patch 的位置,會導致上下游的 discrepency。因為下游任務需要 PE,而上游預訓練的模型又完全沒見過 PE。
- ViT 對于 long-range 的建模能力很強,這個簡單的位置重建任務可能沒辦法讓模型學到非常 high-level 的語義特征。
-
看上去相似的不同 patch(例如純色的背景)的位置無需被精準重建,因此決定哪些 patch 的位置需要被重建非常關鍵。
- 針對問題一,我們采用了一個簡單的隨機丟棄策略。每次訓練過程中丟棄 75% 的 PE,保留 25% 的 PE。
- 針對問題二,我們采取了高比例的 patch mask,既能提高代理任務的難度,又能加快訓練的速度。
- 針對問題三,我們提出了 position smoothing 和 attentive reconstruction 的策略。
3.1 DropPos 前向過程

3.2 Objective
我們使用了一個最簡單的 cross-entropy loss 作為預訓練的目標函數:
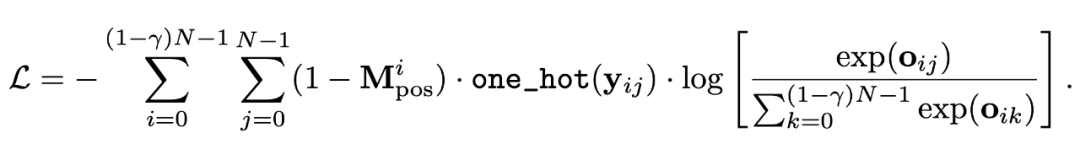
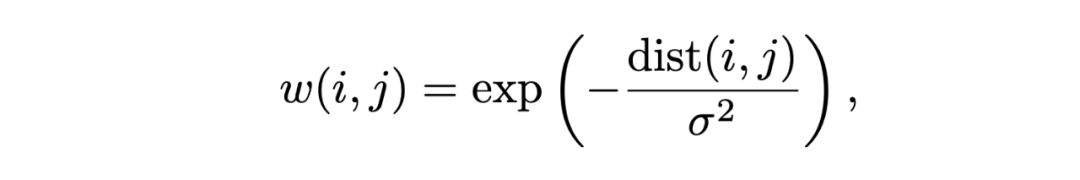
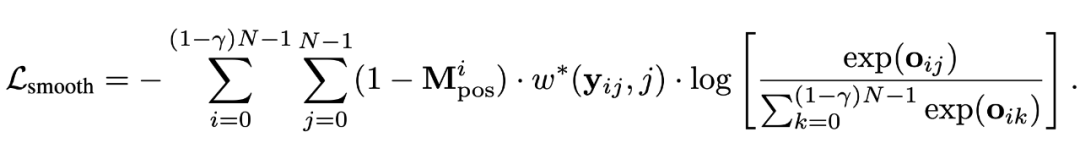 此處,w(i, j) 表示當真實位置為 i,而預測位置為 j 時,平滑后的 position target。
此外,我們還讓 sigma 自大變小,讓模型一開始不要過分關注精確的位置重建,而訓練后期則越來越關注于精準的位置重建。
3.2.2 Attentive Reconstruction
我們采用 [CLS] token 和其他 patch 的相似度作為親和力矩陣,作為目標函數的額外權重。
此處,w(i, j) 表示當真實位置為 i,而預測位置為 j 時,平滑后的 position target。
此外,我們還讓 sigma 自大變小,讓模型一開始不要過分關注精確的位置重建,而訓練后期則越來越關注于精準的位置重建。
3.2.2 Attentive Reconstruction
我們采用 [CLS] token 和其他 patch 的相似度作為親和力矩陣,作為目標函數的額外權重。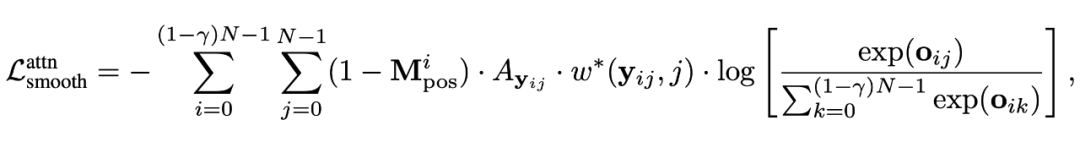
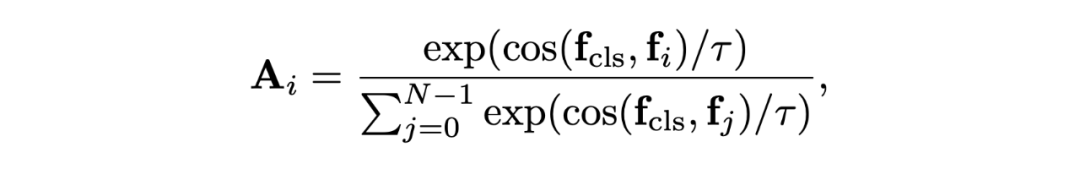 其中 f 為不同 token 的特征,tau 為超參數,控制了 affinity 的平滑程度。
其中 f 為不同 token 的特征,tau 為超參數,控制了 affinity 的平滑程度。

Experiments
4.1 與其他方法的對比

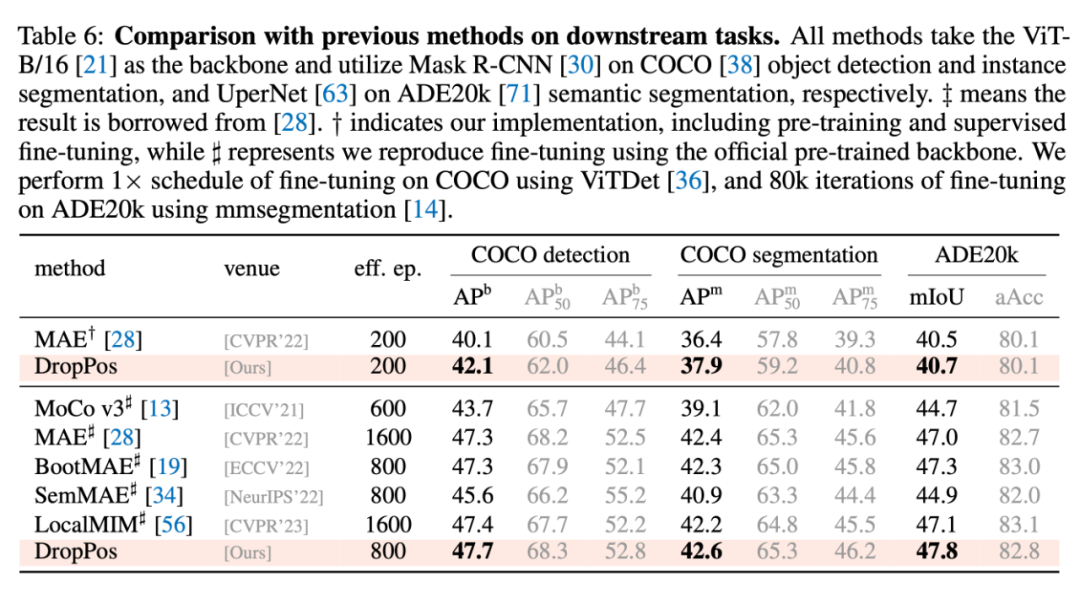
4.2 消融實驗
本文主要有四個超參:patch mask ratio(gamma),position mask ratio(gamma_pos),sigma,和 tau。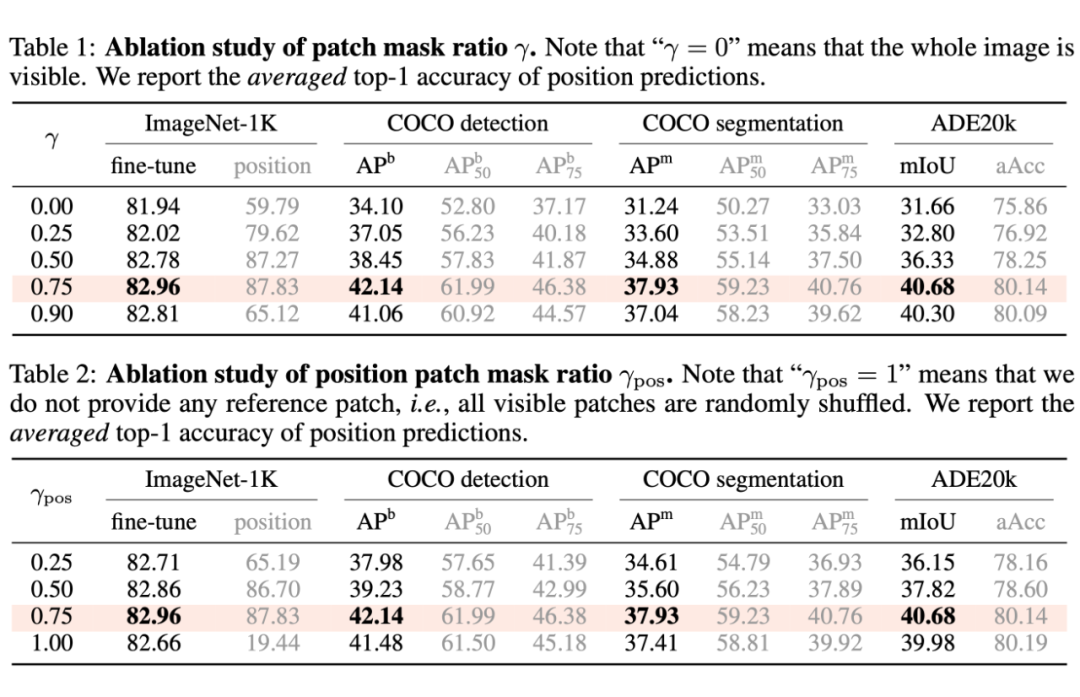
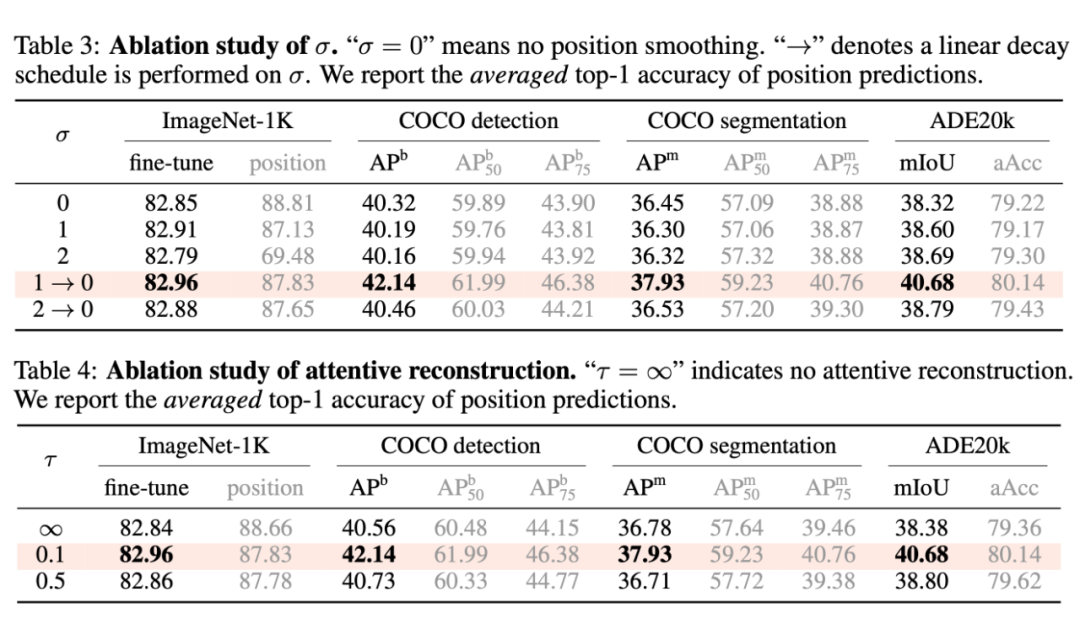 由表,我們可以得出一些比較有趣的結論:
由表,我們可以得出一些比較有趣的結論:
- 一般來說,更高的 position 重建精度會帶來更高的下游任務性能。
- 上述結論存在例外:當 sigma = 0 時,即不做位置平滑時,位置預測精度高,而下游任務表現反而低;當 tau = inf 時,即不做 attentive reconstruction 時,位置預測精度高,而下游表現反而低。
-
因此,過分關注于預測每一個 patch 的精確的位置,會導致局部最優,對于下游任務不利。

原文標題:NeurIPS 2023 | 全新的自監督視覺預訓練代理任務:DropPos
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
物聯網
+關注
關注
2945文章
47818瀏覽量
414838
原文標題:NeurIPS 2023 | 全新的自監督視覺預訓練代理任務:DropPos
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
數據傳輸拖慢訓練?三維一體調度讓AI任務提速40%
、模型三者割裂,資源調度與數據流轉不同步,訓練任務頻繁卡頓;更無奈的是,優化了算法、升級了硬件,卻因底層傳輸與調度低效,始終無法突破訓練效率瓶頸。 在AI模型規模越來越大、數據量呈爆炸式增長的今天,數據傳輸與資源協同效率,早已
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課(11大系列課程,共5000+分鐘)
、GPU加速訓練(可選)
雙軌教學:傳統視覺算法+深度學習方案全覆蓋
輕量化部署:8.6M超輕OCR模型,適合嵌入式設備集成
無監督學習:無需缺陷樣本即可訓練高精度檢測模型
持續更新:
發表于 12-04 09:28
【團購】獨家全套珍藏!龍哥LabVIEW視覺深度學習實戰課程(11大系列課程,共5000+分鐘)
、GPU加速訓練(可選)
雙軌教學:傳統視覺算法+深度學習方案全覆蓋
輕量化部署:8.6M超輕OCR模型,適合嵌入式設備集成
無監督學習:無需缺陷樣本即可訓練高精度檢測模型
持續更新:
發表于 12-03 13:50
思必馳與上海交大聯合實驗室五篇論文入選NeurIPS 2025
近日,機器學習與計算神經科學領域全球頂級學術頂級會議NeurIPS 2025公布論文錄用結果,思必馳-上海交大聯合實驗室共有5篇論文被收錄。NeurIPS(Conference on Neural
基于大規模人類操作數據預訓練的VLA模型H-RDT
近年來,機器人操作領域的VLA模型普遍基于跨本體機器人數據集預訓練,這類方法存在兩大局限:不同機器人本體和動作空間的差異導致統一訓練困難;現有大規模機器人演示數據稀缺且質量參差不齊。得益于近年來VR

信捷視覺平臺全新升級
當機器視覺的精準遇上AI的智能,會碰撞出怎樣的火花?信捷視覺平臺全新升級——XINJE VISION STUDIO 3.7 + Vision AI算法平臺雙劍合璧,覆蓋從規則化檢測到復雜場景分析的全鏈路需求,助力多行業智造升級!
科通技術與RealSense簽署代理協議
近日,科通技術與RealSense, Inc.正式簽署代理協議,成為其中國區代理商。此次合作標志著雙方在3D視覺領域的戰略布局邁入新階段。
EASY EAl Orin Nano(RK3576) whisper語音識別訓練部署教程
1Whisper簡介Whisper是OpenAI開源的,識別語音識別能力已達到人類水準自動語音識別系統。Whisper作為一個通用的語音識別模型,它使用了大量的多語言和多任務的監督數據來訓練,能夠在

EASY EAl Orin Nano(RK3576) whisper語音識別訓練部署教程
Whisper是OpenAI開源的,識別語音識別能力已達到人類水準自動語音識別系統。Whisper作為一個通用的語音識別模型,它使用了大量的多語言和多任務的監督數據來訓練,能夠在英語語音識別上達到接近人類水平的魯棒性和準確性。
CPU密集型任務開發指導
CPU密集型任務是指需要占用系統資源處理大量計算能力的任務,需要長時間運行,這段時間會阻塞線程其它事件的處理,不適宜放在主線程進行。例如圖像處理、視頻編碼、數據分析等。
基于多線程并發機制處理CPU
發表于 06-19 06:05
使用MATLAB進行無監督學習
無監督學習是一種根據未標注數據進行推斷的機器學習方法。無監督學習旨在識別數據中隱藏的模式和關系,無需任何監督或關于結果的先驗知識。

用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集
作者:算力魔方創始人/英特爾創新大使劉力 《用PaddleNLP在4060單卡上實踐大模型預訓練技術》發布后收到讀者熱烈反響,很多讀者要求進一步講解更多的技術細節。本文主要針對大語言模型的預訓

NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺
由 NVIDIA 后訓練的全新 Llama Nemotron 推理模型,為代理式 AI 提供業務就緒型基礎 埃森哲、Amdocs、Atlassian、Box、Cadence、CrowdStrike
發表于 03-19 09:31
?390次閱讀

自動化標注技術推動AI數據訓練革新
標貝自動化數據標注平臺在全棧數據標注場景式中搭載了大模型預標注和自動化標注能力,并應用于3D點云、2D圖像、音頻、文本等數據場景的大規模、復雜任務和常規任務的標注中。在保證高效處理的前提下,確保標注



 工商網監
工商網監
評論