") 為什么GPU獲得了如此多的緩存?
為什么GPU獲得了如此多的緩存?

不久之前,如果您想要一個內置大量緩存的處理器,那么 CPU 是顯而易見的選擇。現(xiàn)在,即使是預算級 GPU 也比幾年前的高端 CPU 配備了更多的內存。
那么,什么改變了呢?為什么圖形芯片突然需要比通用中央處理器更多的緩存?兩者之間的專用內存是否不同?我們將來會看到 GPU 擁有千兆字節(jié)的緩存嗎?
為了回答這些問題,我們需要深入了解最新芯片的內部結構,觀察這些年來的變化。
TL;DR:為什么 GPU 獲得了如此多的緩存?
由于 GPU 現(xiàn)在不僅用于圖形,還用于各種應用程序,因此低級數(shù)據(jù)緩存的大小不斷增大。為了提高通用計算能力,圖形芯片需要更大的緩存。這確保沒有數(shù)學核心閑置等待數(shù)據(jù)。
末級緩存已大幅擴展,以抵消 DRAM 性能未能跟上處理器性能進步的事實。大量的 L2 或 L3 高速緩存可減少高速緩存未命中。這還可以防止內核閑置,并最大限度地減少對非常寬的內存總線的需求。
此外,渲染技術(尤其是光線追蹤)的進步對 GPU 的緩存層次結構提出了巨大的要求。大型末級緩存對于確保使用這些技術時的游戲性能保持可玩性至關重要。
緩存課程 101
要全面討論緩存這個話題,我們首先必須了解緩存是什么以及它的意義。所有處理器都需要內存來存儲它們處理的數(shù)字和計算結果。他們還需要有關任務的具體說明,例如要執(zhí)行哪些計算。這些指令以數(shù)字方式存儲和傳送。
這種存儲器通常稱為 RAM(隨機存取存儲器)。每個帶有處理器的電子設備都配備有 RAM。幾十年來,PC 一直采用DRAM(“D”代表動態(tài))作為數(shù)據(jù)的臨時存儲,而磁盤驅動器作為長期存儲。
自發(fā)明以來,DRAM 已經(jīng)取得了巨大的進步,隨著時間的推移,速度呈指數(shù)級增長。數(shù)據(jù)存儲也是如此,曾經(jīng)占據(jù)主導地位但速度緩慢的硬盤正在被快速的固態(tài)存儲 (SSD)所取代。然而,盡管取得了這些進步,與基本處理器執(zhí)行單個計算的速度相比,這兩種類型的內存仍然慢得要命。
即使是一組 DDR5-8200 也不夠快
雖然芯片可以在幾納秒內將兩個數(shù)字相加,但檢索這些值或存儲結果可能需要數(shù)百到數(shù)千納秒——即使使用最快的可用 RAM。如果沒有辦法解決這個問題,那么 PC 也不會比 20 世紀 70 年代的 PC 好多少,盡管它們的時鐘速度要高得多。
值得慶幸的是,SRAM(靜態(tài) RAM)可以彌補這一差距。SRAM 由與執(zhí)行計算的處理器中的晶體管相同的晶體管制成。這意味著 SRAM 可以直接集成到芯片中并以芯片的速度運行。它靠近邏輯單元,將數(shù)據(jù)檢索或存儲時間縮短至數(shù)十納秒。
這樣做的缺點是,即使單個存儲位所需的晶體管的布置以及其他必要的電路也會占用相當大的空間。使用當前的制造技術,64 MB SRAM 的大小大致相當于 2 GB DRAM。
AMD Zen 4 小芯片的大部分是緩存(紅色 + 黃色框)。
這就是為什么現(xiàn)代處理器整合了各種 SRAM 塊——有些很小,僅包含幾個位,而另一些則包含幾個 MB。這些較大的塊繞過了 DRAM 的緩慢問題,顯著提高了芯片性能。
這些內存類型根據(jù)其用途有不同的名稱,但最流行的稱為“緩存”。這就是討論變得有點復雜的地方。
為等級制度歡呼
處理器核心內的邏輯單元通常處理小數(shù)據(jù)。它們接收的指令和處理的數(shù)字很少大于 64 位。因此,存儲這些值的最小 SRAM 塊的大小相似,稱為“寄存器”。
為了確保這些單元不會停止等待下一組命令或數(shù)據(jù),芯片通常會預取這些信息并保留頻繁發(fā)出的信息。該數(shù)據(jù)存儲在兩個不同的 SRAM 組中,通常稱為 1 級指令緩存和 1 級數(shù)據(jù)緩存。顧名思義,每個都有其保存的特定類型的數(shù)據(jù)。盡管它們很重要,但它們的范圍并不廣泛。例如,AMD 最近的桌面處理器為每個處理器分配 32 kB。
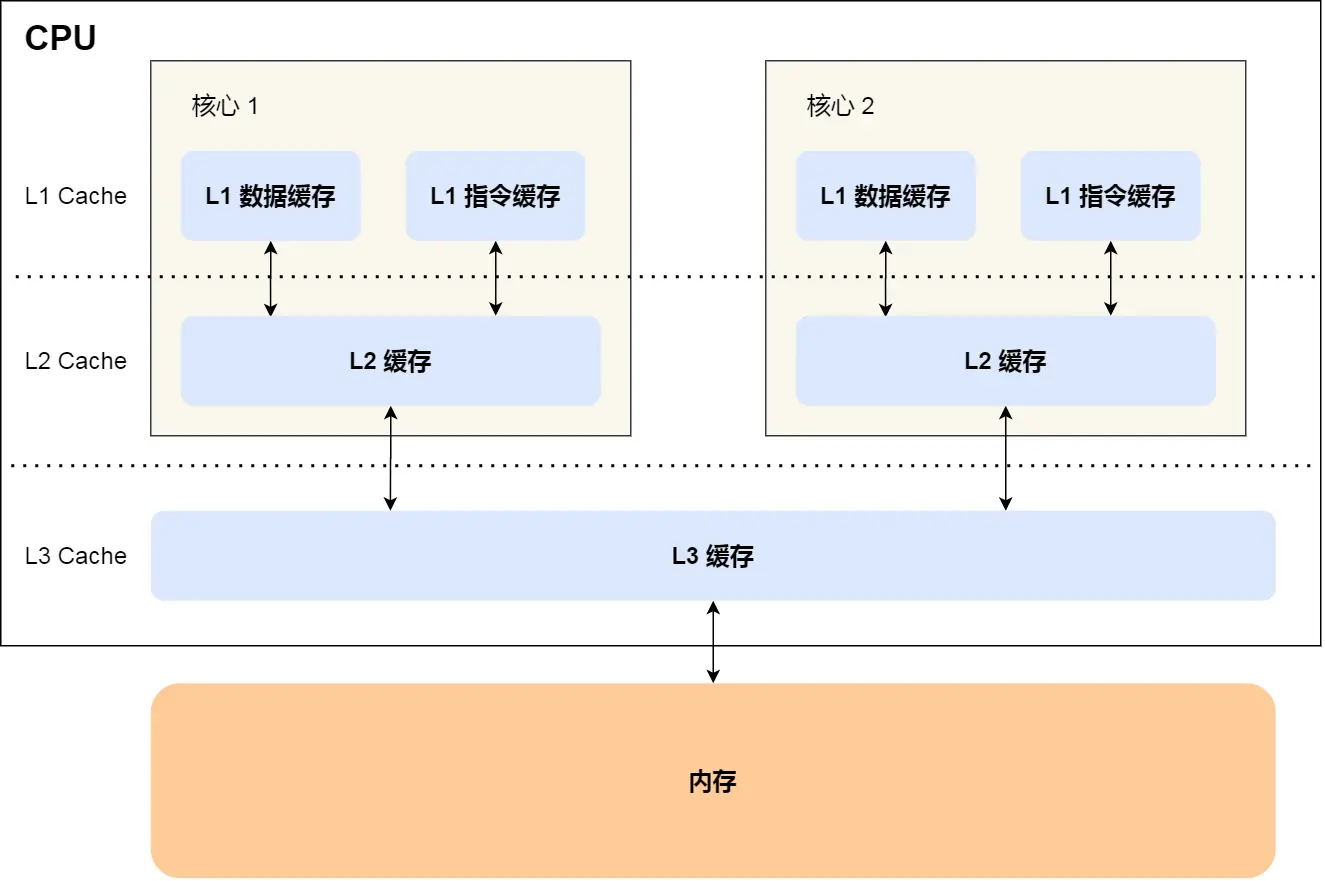
雖然不是很大,但這些緩存足以容納大量命令和數(shù)據(jù),確保內核不會閑置。然而,為了維持這種數(shù)據(jù)流,必須持續(xù)提供緩存。當核心需要 1 級緩存 (L1) 中不存在的特定值時,L2 緩存就變得至關重要。
L2 緩存是一個更大的塊,存儲各種數(shù)據(jù)。請記住,單個內核具有多個邏輯單元線。如果沒有 L2,L1 緩存很快就會被淹沒。現(xiàn)代處理器具有多個內核,因此需要引入另一個為所有內核提供服務的緩存層:三級 (L3) 緩存。它的范圍甚至更廣,跨越了幾個 MB。從歷史上看,某些 CPU 甚至具有第四級。
英特爾 Raptor Lake CPU 之一的單個 P 核的圖像。淡藍色的各種網(wǎng)格點綴在結構周圍,是寄存器和各種緩存的混合體。您可以在此網(wǎng)站上查看每個部分的更詳細細分。然而,本質上,L1 緩存位于核心的中央,而 L2 則占據(jù)右側部分。
處理器中的最后一級緩存通常充當來自系統(tǒng) DRAM 的任何數(shù)據(jù)在繼續(xù)傳輸之前的第一個調用端口,但情況并非總是如此。這是關于緩存的部分,往往會變得非常復雜,但這對于理解為什么 CPU 和 GPU 具有截然不同的緩存安排也至關重要。
SRAM 塊的整個系統(tǒng)的使用方式被稱為芯片的緩存層次結構,它的變化很大,具體取決于架構的年齡和芯片的目標扇區(qū)等因素。但對于CPU來說,有一些方面總是相同的,其中之一就是層次結構的連貫性。
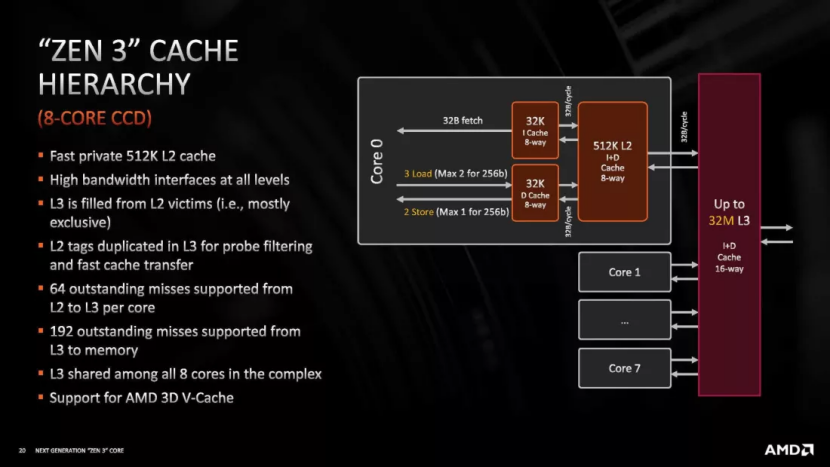
高速緩存中的數(shù)據(jù)可以從系統(tǒng)的 DRAM 復制。如果某個核心對其進行修改,則必須同時更新 DRAM 版本。因此,CPU緩存結構具有確保數(shù)據(jù)準確性和及時更新的機制。這種復雜的設計增加了復雜性,在處理器領域,復雜性轉化為晶體管,進而轉化為空間。
這就是為什么前幾級緩存不是很大的原因 — 不僅因為 SRAM 非常寬敞,還因為需要所有其他系統(tǒng)來保持其一致性。然而,并不是每個處理器都需要這個,并且有一種非常特定的類型通常完全避開它。
GPU 的方式:核心優(yōu)先于緩存
今天的圖形芯片,從內部結構和功能來看,形成于2007年。當時Nvidia和ATI都發(fā)布了統(tǒng)一著色器GPU,但對于后者來說,真正的變化發(fā)生在5年后。
2012 年,AMD(當時已收購ATI)推出了下一代圖形核心(GCN) 架構。這種設計至今仍在使用,盡管它已經(jīng)經(jīng)歷了重大修改并演變成RDNA和 CDNA 等形式。我們將參考 GCN 來闡明 CPU 和 GPU 之間的緩存差異,因為它提供了一個清晰的示例。
跳到 2017 年,讓我們將 AMD 的Ryzen 7 1800X CPU(上圖)與 Radeon RX Vega 64 GPU進行對比。前者有8個核心,每個核心包含8條管道。其中四個管道處理標準數(shù)學運算,兩個專門用于廣泛的浮點計算,最后兩個負責數(shù)據(jù)管理。其緩存層次結構如下:64 kB L1 指令、32 kB L1 數(shù)據(jù)、512 kB L2 和 16 MB L3。
Vega 64 GPU 具有 4 個處理塊。每個塊都包含 64 個管道,通常稱為計算單元 (CU)。此外,每個CU可容納四組16個邏輯單元。每個 CU 都擁有 16 kB 的 L1 數(shù)據(jù)緩存和 64 kB 的暫存存儲器,本質上充當沒有一致性機制的緩存(AMD 將其標記為本地數(shù)據(jù)共享)。
此外,還有兩個高速緩存(16 kB L1 指令和 32 kB L1 數(shù)據(jù))可滿足四個 CU 組的需要。Vega GPU 還擁有 4 MB 二級緩存,位于兩個帶中,一個位于底部,另一個位于下圖頂部附近。
該特定圖形處理器的芯片面積是 Ryzen 芯片尺寸的兩倍。然而,它的緩存占用的空間比CPU中的要小得多。與 CPU 相比,為什么該 GPU 保持最小的緩存,特別是在 L2 段方面?
鑒于其“核心”數(shù)量明顯高于 Ryzen 芯片,人們可能會預計,總共有 4096 個數(shù)學單元,因此需要大量緩存來維持穩(wěn)定的數(shù)據(jù)供應。然而,CPU 和 GPU 工作負載有根本的不同。
雖然 Ryzen 芯片可以同時管理多達 16 個線程并處理 16 個不同的命令,但 Vega 處理器可能會處理更多數(shù)量的線程,但其 CU 通常執(zhí)行相同的指令。
此外,每個 CU 內的數(shù)學單元在一個周期內同步執(zhí)行相同的計算。這種一致性將它們歸類為 SIMT(單指令、多線程)設備。GPU 按順序運行,很少偏離其他處理路線。
相比之下,CPU 處理各種指令,同時確保數(shù)據(jù)一致性。相反,GPU 重復執(zhí)行類似的任務,消除了數(shù)據(jù)一致性的需要并不斷重新啟動其操作。
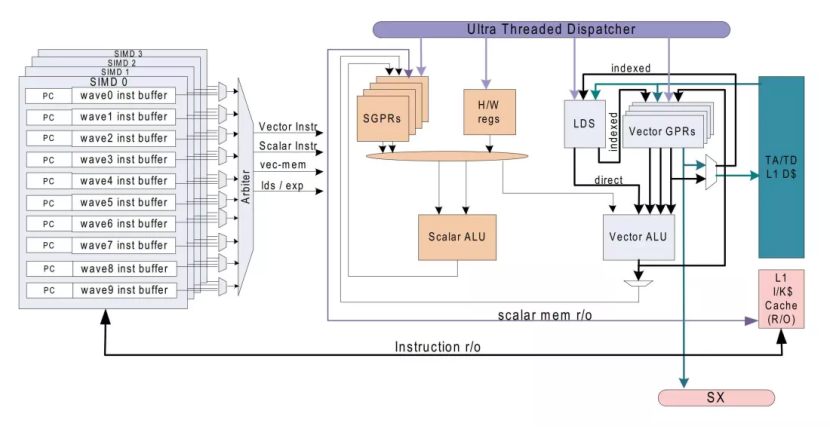
GCN計算單元的內部結構。很簡單,是嗎?
由于渲染 3D 圖形的任務主要由重復的數(shù)學運算組成,因此 GPU 不需要像 CPU 那樣復雜。相反,GPU 被設計為大規(guī)模并行,可同時處理數(shù)千個數(shù)據(jù)點。這就是為什么與中央處理器相比,它們的緩存較小,但內核數(shù)量卻多得多。
然而,如果是這樣的話,為什么 AMD 和 Nvidia 的最新顯卡擁有大量緩存,甚至是廉價型號?Radeon RX 7600只有 2 MB 的 L2,但也有 32 MB 的 L3;Nvidia 的GeForce RTX 4060沒有 L3,但它配備了 24 MB L2。
當談到他們的光環(huán)產(chǎn)品時,數(shù)字是巨大的——GeForce RTX 4090擁有 72 MB 的 L2,而Radeon RX 6800 / 6900卡中的 AMD Navi 21 芯片則擁有 128 MB 的 L3!
這里有很多東西需要解開——例如,為什么 AMD 在這么長時間內保持如此小的緩存,然后突然增加它們的大小并投入大量的 L3 以達到良好的效果?
為什么 Nvidia 將 L1 大小增加這么多,但將 L2 保持相對較小,只是為了復制 AMD 并讓 L2 緩存瘋狂?
GPU 中的 G不再只是圖形
這種轉變的原因有很多,但對于 Nvidia 來說,這種轉變是由 GPU 使用方式的變化推動的。盡管它們被稱為圖形處理單元,但這些芯片的用途不僅僅是在屏幕上顯示令人印象深刻的圖像。
雖然絕大多數(shù) GPU 都擅長此功能,但這些芯片已經(jīng)超越了渲染的范圍。他們現(xiàn)在處理多個學科的數(shù)據(jù)處理和科學算法中的數(shù)學負載,包括工程、物理、化學、生物學、醫(yī)學、經(jīng)濟學和地理學。原因?因為他們非常擅長同時對數(shù)千個數(shù)據(jù)點進行相同的計算。
盡管 CPU 也可以執(zhí)行此功能,但對于某些任務,單個 GPU 的效率可以與多個中央處理器一樣高效。隨著 Nvidia 的 GPU 向通用化發(fā)展,芯片內邏輯單元的數(shù)量及其運行速度都呈指數(shù)級增長。
Nvidia 第一個用于嚴肅通用計算的“顯卡”——2007 年的 Tesla C870
Nvidia 在 2007 年首次涉足嚴肅的通用計算領域,以 Tesla C870 為標志。該卡的架構在其緩存層次結構中只有兩級(技術上可以爭論為 2.5,但讓我們回避這一爭論),確保了 L1 緩存足夠廣泛,可以持續(xù)向所有單位提供數(shù)據(jù)。更快的 VRAM 支持了這一點。二級緩存的大小也有所增加,盡管與我們現(xiàn)在看到的情況完全不同。
Nvidia 的第一批統(tǒng)一著色器 GPU只需要 16 kB 的 L1 數(shù)據(jù)(以及少量的指令和其他值),但在幾年內就躍升至 64 kB。對于過去的兩種架構,GeForce 芯片具有 128 kB L1,其服務器級處理器甚至更多。
第一批芯片中的 L1 緩存只需服務 10 個邏輯單元(8 個通用 + 2 個特殊功能)。當Pascal 架構出現(xiàn)時(與 AMD 的 RX Vega 64 大致同一時代),緩存已增長至 96 kB,可容納 150 多個邏輯單元。
當然,該緩存從 L2 獲取數(shù)據(jù),并且隨著這些單元的簇數(shù)量隨著每一代的增加而增加,L2 緩存的數(shù)量也隨之增加。然而,自 2012 年以來,每個邏輯集群(更廣為人知的流式多處理器,SM)的 L2 數(shù)量一直保持相對不變,約為 70 到 130 MB。當然,最新的 Ada Lovelace 架構是個例外,我們稍后會回到這個架構。
多年來,AMD 的重點主要集中在 CPU 上,而圖形部門在人員配置和預算方面相對較小。不過,作為基本設計,GCN 運行得非常好,在 PC、游戲機、筆記本電腦、工作站和服務器中找到了應用。
雖然AMD的圖形處理器可能并不總是人們能買到的最快的,但它已經(jīng)足夠好了,而且這些芯片的緩存結構似乎不需要認真更新。但是,盡管 CPU 和 GPU 飛速發(fā)展,但事實證明,還有另一個難題很難改進。
DRAM進展緩慢
GCN 的后繼者是 2019 年的 RDNA 架構,AMD 重新調整了一切,以便他們的新 GPU 使用三級緩存,同時仍然保持相對較小的規(guī)模。然后,在其后續(xù)RDNA 2 設計中,AMD 利用其在 CPU 緩存工程方面的專業(yè)知識將第四級緩存硬塞到芯片中,該緩存比之前 GPU 中看到的任何緩存都要大得多。
但為什么要做出這樣的改變,特別是當這些芯片主要用于游戲并且 GCN 緩存多年來只進行了最小的修改時?
原因很簡單:
芯片尺寸和復雜性:
雖然合并更多緩存級別確實使芯片設計復雜化,但它可以防止芯片變得過大。更小的芯片意味著可以從單個硅晶圓中提取更多的單元,從而使生產(chǎn)更具成本效益。
內存速度與處理器速度
多年來,處理器速度一直在持續(xù)增長,但 DRAM 卻未能跟上這一步伐。例如,在 Radeon RX Vega 64 中,AMD 利用高帶寬內存 (HBM) 來提高 VRAM 和 GPU 之間的數(shù)據(jù)傳輸速率。這些模塊顯示在主 GPU 芯片左側上方,本質上是堆疊在一起的多個 DRAM 芯片,有助于每個周期讀取或寫入更多數(shù)據(jù)。然而,HBM 非常昂貴。理想情況下,顯卡應具有充足的內存、大量的總線,并且全部都以高速運行。但由于 DRAM 的結構,其性能無法提升到與 CPU 或 GPU 相匹配。
當計算所需的數(shù)據(jù)不存在于緩存中時(通常稱為“緩存未命中”),必須從 VRAM 中獲取數(shù)據(jù)。由于此過程比從緩存中檢索速度慢,因此等待 DRAM 中存儲的數(shù)據(jù)只會導致需要數(shù)據(jù)的線程停滯。即使使用現(xiàn)代圖形芯片,這種情況也經(jīng)常發(fā)生。
這種情況實際上一直在發(fā)生,即使使用最新的圖形芯片,但隨著它們變得越來越強大,緩存未命中正在成為高分辨率下的一個重要性能限制。
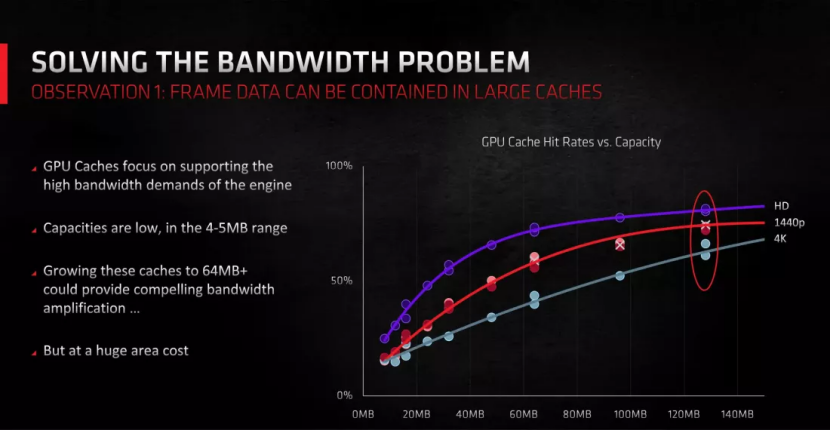
在 GPU 中,最后一級緩存的結構使得每個 VRAM 模塊的接口都有其專用的 SRAM 片。其余處理器利用交叉連接系統(tǒng)來訪問任何模塊。通過 GCN 和首次 RDNA 設計,AMD 通常采用 256 或 512 kB L3 切片。但在 RDNA 2 中,每片的大小激增至 16 至 32 MB,令人印象深刻。
這一調整不僅大幅減少了 DRAM 讀取引起的線程延遲,還減少了對超寬內存總線的需求。更寬的總線需要更廣闊的 GPU 芯片周長來容納所有內存接口。
雖然由于固有的長延遲,大量緩存可能會很麻煩且緩慢,但 AMD 的設計卻恰恰相反——龐大的 L3 緩存使 RDNA 2 芯片的性能與擁有更寬內存總線的性能相當,同時將芯片尺寸保持在低于控制。
Nvidia 緊隨其后,推出了最新一代的 Ada Lovelace,出于同樣的原因,之前的 Ampere 設計在其最大的消費級 GPU 中的最大二級緩存大小為 6 MB,但在新設計中顯著增加。完整的 AD102 芯片(RTX 4090 中使用的是其精簡版本)包含 96 MB 的二級緩存。
至于為什么他們不只是采用另一級緩存并將其做得非常大,可能是因為在這一領域沒有與 AMD 相同水平的專業(yè)知識,或者可能不想看起來像是直接復制該公司。當人們查看芯片時,如上所示,無論如何,所有二級緩存實際上并沒有占用芯片上的太多空間。
除了通用GPU計算的興起外,還有一個原因導致末級緩存現(xiàn)在這么大,這與渲染領域的最新熱門話題:光線追蹤有關。
大圖形需要大數(shù)據(jù)
無需過多介紹該過程的細節(jié),最新游戲中使用的光線追蹤行為涉及執(zhí)行看似相當簡單的算法 - 從 3D 世界中相機的位置畫一條線,通過幀的一個像素,并追蹤其在空間中的路徑。當它與一個對象交互時,檢查它是什么以及它是否可見,然后從那里計算出像素的顏色。
事情遠不止這些,但這是基本過程。光線追蹤要求如此高的原因之一是對象檢查。計算出光線所到達的物體的所有細節(jié)是一項艱巨的任務,因此為了幫助加快例程,使用了一種稱為包圍體層次結構(簡稱 BVH)的東西。
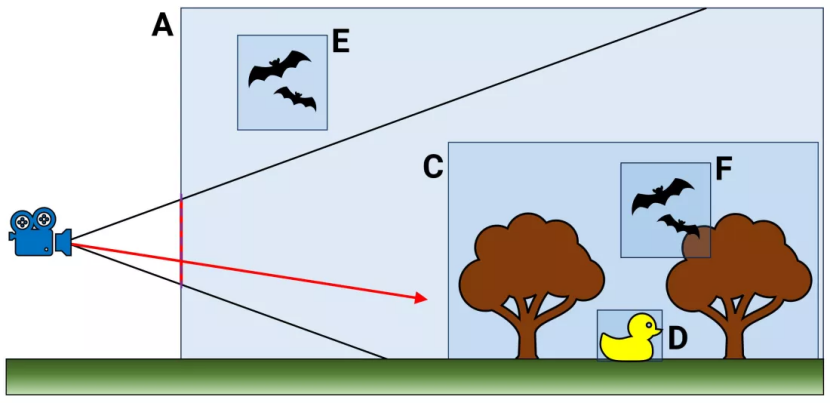
可以將其視為 3D 場景中使用的所有對象的大型數(shù)據(jù)庫 - 每個條目不僅提供有關結構是什么的信息,還提供有關其與其他對象的關系的信息。以上面(極其簡單化)的例子為例。
層次結構的頂部從體積 A 開始。其他所有內容都包含在其中,但請注意,體積 E 位于體積 C 之外,后者本身包含 D 和 F。當光線投射到此場景中時(紅色箭頭),遍歷層次結構時會發(fā)生一個過程,檢查光線路徑經(jīng)過的體積。
然而,BVH像樹一樣排列,遍歷只需沿著檢查結果命中的分支進行。因此,體積 E 可以立即被拒絕,因為它不是射線顯然會穿過的 C 的一部分。當然,現(xiàn)代游戲中 BVH 的實際情況要復雜得多。
我們拍攝了《賽博朋克 2077》的快照,暫停了游戲的渲染中幀,向您展示如何通過增加三角形層來構建任何一個給定場景。
現(xiàn)在,嘗試想象從您的眼睛開始追蹤一條線,穿過監(jiān)視器中的一個像素,然后嘗試準確確定哪個三角形將與光線相交。這就是為什么 BVH 的使用如此重要,并且它大大加快了整個過程。
在這個特定的游戲中,與許多采用光線追蹤來照亮整個場景的游戲一樣,BVH 包含兩種類型的多個數(shù)據(jù)庫:頂級加速結構 (TLAS) 和底層加速結構 (BLAS)。
前者本質上是對整個世界的大概覽,而不僅僅是我們所看到的很小的一部分。在使用 Nvidia 顯卡的 PC 上,它看起來像這樣:
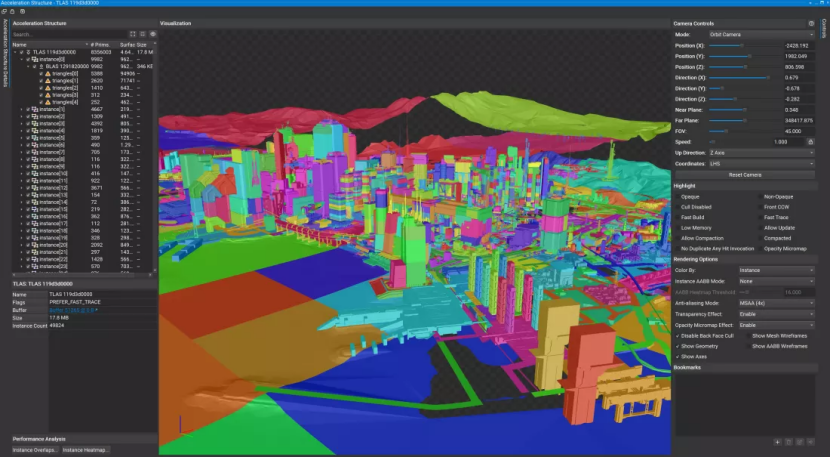
我們稍微放大了一些,以便向您展示其中包含的一些細節(jié),但正如您所看到的,它非常大 — 大小幾乎為 18 MB。請注意該列表是實例之一,并且每個實例都包含至少一個 BLAS。游戲只使用了兩個 TLAS 結構(第二個要小得多),但總共有數(shù)千個 BLAS。
下面的衣服是世界上看到的角色可能穿著的一件衣服。擁有這么多可能看起來很荒謬,但這種層次結構意味著如果這個特定的 BLAS 不在光線路徑中的更大父結構中,則它永遠不會在渲染的著色階段被檢查或使用。

對于我們的《賽博朋克 2077》快照,總共使用了 11,360 個 BLAS,占用的內存比 TLAS 多得多。然而,由于 GPU 現(xiàn)在擁有大量緩存,因此有足夠的空間將后者存儲在該 SRAM 中,并從 VRAM 傳輸許多相關的 BLAS,從而使光線追蹤過程變得更快。
所謂的渲染圣杯實際上仍然只有那些擁有最好顯卡的人才能獲得,即便如此,也需要采用額外的技術(例如圖像升級和幀生成)來將整體性能帶入可玩的領域。
BVH、數(shù)千個核心和 GPU 中的專用光線追蹤單元使這一切成為可能,但巨大的緩存為這一切提供了急需的推動力。
皇冠的競爭者
一旦幾代 GPU 架構過去,擁有大量 L2 或 L3 緩存的圖形芯片將成為常態(tài),而不是新設計的獨特賣點。GPU將繼續(xù)在廣泛的通用場景中使用,光線追蹤將在游戲中變得越來越普遍,而DRAM仍將落后于處理器技術的發(fā)展。
話雖如此,當涉及到 SRAM 中時,GPU 并不會完全滿足要求。事實上,現(xiàn)在有一些例外。
我們不是在談論 AMD 的 X3D 系列 Ryzen CPU,盡管Ryzen 9 7950X3D配備了驚人的 128 MB L3 緩存(英特爾最大的消費級 CPU Core i9-13900K僅 36 MB)。不過,它仍然是 AMD 產(chǎn)品,特別是 EPYC 9000 系列服務器處理器中的最新產(chǎn)品。
售價 14,756 美元的 EPYC 9684X由 13 個小芯片組成,其中 12 個小芯片容納處理器的核心和緩存。每個芯片都包含 8 個核心和一個 64 MB 的 AMD 3D V 緩存片,位于小芯片的內置 32 MB L3 緩存之上。總而言之,末級緩存總計達到 1152 MB,令人難以置信!即使是 16 核版本(9174F)也擁有 256 MB 內存,盡管它仍然不是你所說的便宜,價格為 3,840 美元。
當然,此類處理器并不是為普通人及其游戲電腦而設計的,而且其物理尺寸、價格標簽和功耗數(shù)據(jù)都非常大,我們不會在普通處理器中看到類似的處理器。臺式電腦使用多年。
部分原因是,與用于邏輯單元的半導體電路不同,隨著每個新工藝節(jié)點(芯片的制造方法)縮小 SRAM 變得越來越困難。AMD 的 EPYC 處理器擁有如此多的緩存,僅僅是因為散熱器下方有很多芯片。
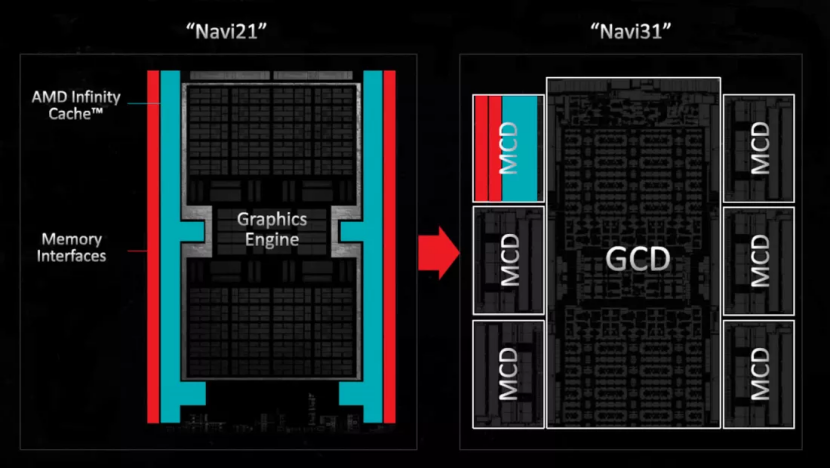
所有 GPU 在未來的某個時候可能都會走類似的路線,AMD 的高端 Radeon 9000 型號已經(jīng)這樣做了,內存接口和相關的 L3 緩存片被安置在與主處理芯片不同的小芯片中。
不過,使用更大的緩存會帶來收益遞減,因此不要指望 GPU 到處都有千兆字節(jié)的緩存。但即便如此,最近的變化還是相當引人注目的。
二十年前,圖形芯片中的緩存非常少,只有幾 kB 的 SRAM。現(xiàn)在,您可以花不到 400 美元購買一張具有如此大緩存的顯卡,您可以將整個原始 Doom 放入其中 - 兩倍!
GPU 確實是緩存之王。
審核編輯:劉清
-
處理器
+關注
關注
68文章
20250瀏覽量
252195 -
DRAM
+關注
關注
41文章
2392瀏覽量
189131 -
晶體管
+關注
關注
78文章
10395瀏覽量
147723 -
SSD
+關注
關注
21文章
3109瀏覽量
122221 -
隨機存取存儲器
+關注
關注
0文章
48瀏覽量
9345
原文標題:為什么GPU是新的緩存之王?
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
是否可以將 Vision Five 2 配置為 SuperSpeed 上的 USB 3.0 mass_storage小工具?
盤點芯科科技在2025年獲得的企業(yè)及產(chǎn)品類獎項

如何在多顯卡環(huán)境下配置OLLAMA實現(xiàn)GPU負載均衡
高性能緩存設計:如何解決緩存偽共享問題
為什么無法在GPU上使用INT8 和 INT4量化模型獲得輸出?
如果使用CYPD72721-68LQXQ是否需要外部MCU?
SPI數(shù)據(jù)傳輸緩慢問題求解
MCU緩存設計
Nginx緩存配置詳解



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論