") Hold住千億參數(shù)大模型,Gaudi?2 有何優(yōu)勢
Hold住千億參數(shù)大模型,Gaudi?2 有何優(yōu)勢

近日在北京舉行的2023年中國國際服務(wù)貿(mào)易交易會(huì)(下文簡稱:服貿(mào)會(huì))上,作為英特爾人工智能產(chǎn)品組合的重要成員,Habana Gaudi2實(shí)力亮相,它在海內(nèi)外諸多大語言模型(Large Language Model,下文簡稱:LLM)的加速上,已展現(xiàn)了出眾實(shí)力,成為業(yè)界焦點(diǎn)。
AI技術(shù)飛速發(fā)展,LLM風(fēng)起云涌,但由于AI模型尤其是LLM的訓(xùn)練與推理需要消耗大量資源和成本,在生產(chǎn)環(huán)境部署和使用這些模型變得極具挑戰(zhàn)。如何提升性能降低開銷,使AI技術(shù)更快普及,是行業(yè)內(nèi)共同關(guān)注的話題。

專為加速LLM的訓(xùn)練和推理設(shè)計(jì)
Habana Gaudi2 正是專為高性能、高效率大規(guī)模深度學(xué)習(xí)任務(wù)而設(shè)計(jì)的AI加速器,具備24個(gè)可編程Tensor處理器核心(TPCs)、21個(gè)100Gbps(RoCEv2)以太網(wǎng)接口、96GB HBM2E內(nèi)存容量、2.4TB/秒的總內(nèi)存帶寬、48MB片上SRAM,并集成多媒體處理引擎。該加速器能夠通過性能更高的計(jì)算架構(gòu)、更先進(jìn)的內(nèi)存技術(shù)和集成RDMA實(shí)現(xiàn)縱向擴(kuò)展,為中國用戶提供更高的深度學(xué)習(xí)效率與更優(yōu)性價(jià)比。Gaudi2 的計(jì)算速度十分出色,它的架構(gòu)能讓加速器并行執(zhí)行通用矩陣乘法 (GeMM) 和其他運(yùn)算,從而加快深度學(xué)習(xí)工作流。這些特性使 Gaudi2 成為 LLM 訓(xùn)練和推理的理想選擇,亦將成為大規(guī)模部署AI的更優(yōu)解。

在服貿(mào)會(huì)上,英特爾展示了Habana Gaudi2 對ChatGLM2-6B的加速能力。ChatGLM2-6B是開源中英雙語對話模型ChatGLM-6B的第二代版本,加強(qiáng)了初代模型對話流暢等優(yōu)質(zhì)特性。得益于專為深度學(xué)習(xí)設(shè)計(jì)的架構(gòu),Habana Gaudi2 可以靈活地滿足單節(jié)點(diǎn)、多節(jié)點(diǎn)的大規(guī)模分布式大語言模型訓(xùn)練,在ChatGLM2-6B上,能夠支持更長的上下文,并帶來極速對話體驗(yàn)。
在千億參數(shù)大模型上大顯身手
實(shí)際上,Habana Gaudi2 的卓越性能早已嶄露頭角。在今年6月公布的MLCommonsMLPerf基準(zhǔn)測試中,Gaudi2在GPT-3模型、計(jì)算機(jī)視覺模型ResNet-50(使用8個(gè)加速器)、Unet3D(使用8個(gè)加速器),以及自然語言處理模型BERT(使用8個(gè)和64個(gè)加速器)上均取得了優(yōu)異結(jié)果。近日,MLCommons又繼續(xù)公布了針對60億參數(shù)大語言模型及計(jì)算機(jī)視覺與自然語言處理模型GPT-J的MLPerf推理v3.1性能基準(zhǔn)測試結(jié)果,其中包括基于Habana Gaudi2加速器、第四代英特爾至強(qiáng)可擴(kuò)展處理器,以及英特爾至強(qiáng)CPU Max系列的測試結(jié)果。
數(shù)據(jù)顯示,Habana Gaudi2在GPT-J-99 和GPT-J-99.9 上的服務(wù)器查詢和離線樣本的推理性能分別為78.58 次/秒和84.08 次/秒。該測試采用 FP8數(shù)據(jù)類型,并在這種新數(shù)據(jù)類型上達(dá)到了 99.9% 的準(zhǔn)確率,這無疑再一次印證了Gaudi2的出色性能。此外,基于第四代英特爾至強(qiáng)可擴(kuò)展處理器的7個(gè)推理基準(zhǔn)測試也顯示出其對于通用AI工作負(fù)載的出色性能。截至目前,英特爾仍是唯一一家使用行業(yè)標(biāo)準(zhǔn)的深度學(xué)習(xí)生態(tài)系統(tǒng)軟件提交公開CPU結(jié)果的廠商。
另一個(gè)讓Habana Gaudi2 大顯身手的模型是BLOOMZ。BLOOM是一個(gè)擁有 1760 億參數(shù)的自回歸模型,訓(xùn)練后可用于生成文本序列,它可以處理 46 種語言和 13 種編程語言,而BLOOMZ是與BLOOM架構(gòu)完全相同的模型,它是BLOOM基于多個(gè)任務(wù)的調(diào)優(yōu)版本。Habana與著名AI平臺Hugging Face合作進(jìn)行了 Gaudi2 在BLOOMZ模型上的基準(zhǔn)測試1。如圖1所示,對于參數(shù)量達(dá)1760億的模型 BLOOMZ(BLOOMZ-176B),Gaudi2性能表現(xiàn)出色,時(shí)延僅為約3.7 秒;對于參數(shù)量為 70 億的較小模型 BLOOMZ-7B,Gaudi2 的時(shí)延優(yōu)勢更加顯著,單設(shè)備約為第一代 Gaudi 的37.21%,而當(dāng)設(shè)備數(shù)量都增加為8后,這一百分比進(jìn)一步下降至約24.33%。
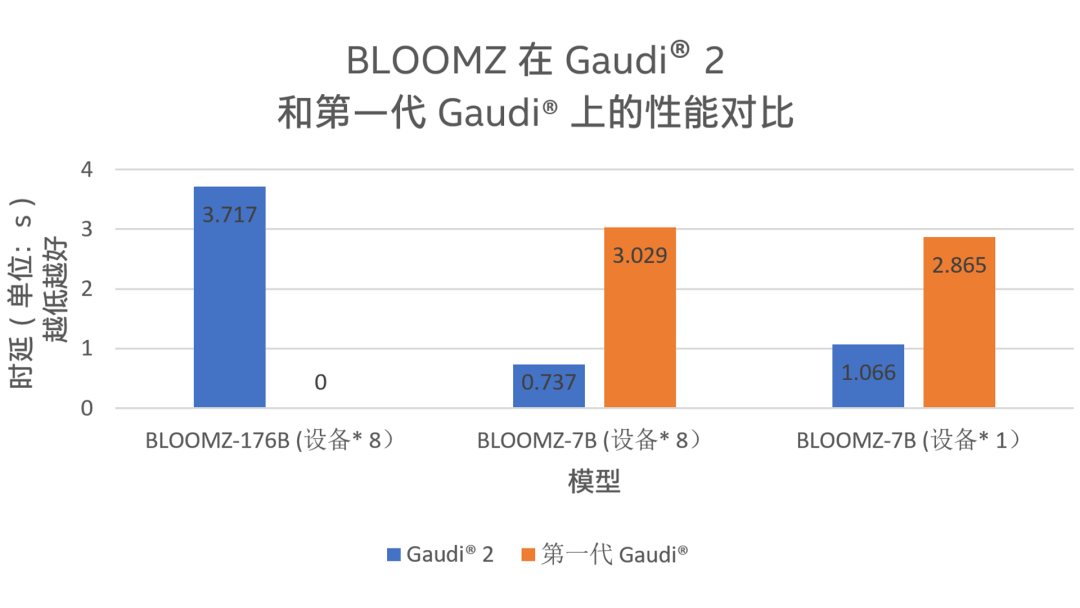
圖 1. BLOOMZ 在 Gaudi2 和第一代 Gaudi 上的推理時(shí)延測試結(jié)果
此外,在Meta發(fā)布的開源大模型Llama 2上,Gaudi2的表現(xiàn)依然出眾。圖2顯示了70億參數(shù)和130億參數(shù)兩種Llama 2模型的推理性能。模型分別在一臺Habana Gaudi2設(shè)備上運(yùn)行,batch size=1,輸出token長度256,輸入token長度不定,使用BF16精度。報(bào)告的性能指標(biāo)為每個(gè)token的延遲(不含第一個(gè))。對于128至2000輸入token,在70億參數(shù)模型上Gaudi2的推理延遲范圍為每token 9.0-12.2毫秒,而對于130億參數(shù)模型,范圍為每token 15.5-20.4毫秒2。
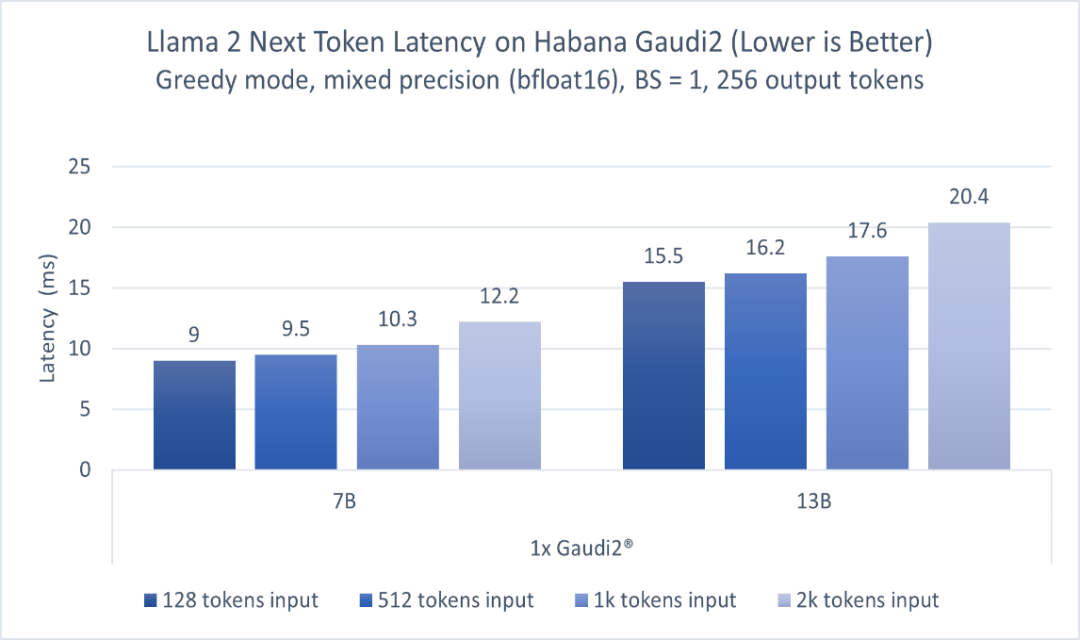
圖 2.基于HabanaGaudi2,70億和130億參數(shù)Llama 2模型的推理性能
值得一提的是,Habana 的SynapseAI 軟件套件在模型部署和優(yōu)化的過程中起到了至關(guān)重要的作用。SynapseAI 軟件套件不僅支持使用 PyTorch 和 DeepSpeed 來加速LLM的訓(xùn)練和推理,還支持 HPU Graph和DeepSpeed-inference,這兩者都非常適合時(shí)延敏感型應(yīng)用。因此,在Habana Gaudi2上部署模型非常簡單,尤其是對LLM等數(shù)十億以上參數(shù)的模型推理具有較優(yōu)的速度優(yōu)勢,且無需編寫復(fù)雜的腳本。
LLM的成功堪稱史無前例。有人說,LLM讓AI技術(shù)朝著通用人工智能(AGI)的方向邁進(jìn)了一大步,而因此面臨的算力挑戰(zhàn)也催生了更多技術(shù)的創(chuàng)新。Habana Gaudi2 正是在這一背景下應(yīng)運(yùn)而生,以其強(qiáng)大的性能和性價(jià)比優(yōu)勢加速深度學(xué)習(xí)工作負(fù)載。Habana Gaudi2的出色表現(xiàn)更進(jìn)一步顯示了英特爾AI產(chǎn)品組合的競爭優(yōu)勢,以及英特爾對加速從云到網(wǎng)絡(luò)到邊緣再到端的工作負(fù)載中大規(guī)模部署AI的承諾。英特爾將持續(xù)引領(lǐng)產(chǎn)品技術(shù)創(chuàng)新,豐富和優(yōu)化包括英特爾 至強(qiáng) 可擴(kuò)展處理器、英特爾 數(shù)據(jù)中心GPU等在內(nèi)的AI產(chǎn)品組合,助力中國本地AI市場發(fā)展。
參考資料:
1.https://huggingface.co/blog/zh/habana-gaudi-2-bloom
2.Habana Gaudi2深度學(xué)習(xí)加速器:所有測量使用了一臺HLS2 Gaudi2服務(wù)器上的Habana SynapseAI 1.10版和optimum-habana 1.6版,該服務(wù)器具有八個(gè)Habana Gaudi2 HL-225H Mezzanine卡和兩個(gè)英特爾 至強(qiáng) 白金8380 CPU@2.30GHz以及1TB系統(tǒng)內(nèi)存。2023年7月進(jìn)行測量。
-
英特爾
+關(guān)注
關(guān)注
61文章
10301瀏覽量
180452 -
cpu
+關(guān)注
關(guān)注
68文章
11279瀏覽量
224993
原文標(biāo)題:Hold住千億參數(shù)大模型,Gaudi?2 有何優(yōu)勢
文章出處:【微信號:英特爾中國,微信公眾號:英特爾中國】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相比MCU同行產(chǎn)品,芯源的MCU產(chǎn)品有何優(yōu)勢和劣勢呢?
國產(chǎn)AI芯片真能扛住“算力內(nèi)卷”?海思昇騰的這波操作藏了多少細(xì)節(jié)?
淺談SPICE模型參數(shù)自動(dòng)化提取
基于神經(jīng)網(wǎng)絡(luò)的數(shù)字預(yù)失真模型解決方案
英特爾Gaudi 2E AI加速器為DeepSeek-V3.1提供加速支持

醫(yī)院專用數(shù)據(jù)記錄儀產(chǎn)品有哪些?有何推薦?
TC377配置SMU FSP時(shí),如何配置頻率參數(shù);三種模式有何區(qū)別,配置上有何區(qū)別?
?Groq LPU 如何讓萬億參數(shù)模型「飛」起來?揭秘 Kimi K2 40 倍提速背后的黑科技
請問InDTU IHDMP協(xié)議使用的CRC校驗(yàn)使用的什么參數(shù)模型?
萬億參數(shù)!元腦企智一體機(jī)率先支持Kimi K2大模型
【VisionFive 2單板計(jì)算機(jī)試用體驗(yàn)】3、開源大語言模型部署
ON Semiconductor MC14013BDTR2G 雙D型觸發(fā)器參數(shù)特性 EDA模型 數(shù)據(jù)手冊
IBIS模型中的Corner參數(shù)處理



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論