 32k上下文可商用!羊駝進化成長頸鹿,“開源大模型之最”
32k上下文可商用!羊駝進化成長頸鹿,“開源大模型之最”

號稱“世界首個上下文長度達32k的開源可商用大模型”來了。
名字“簡單粗暴”,就叫“長頸鹿”(Giraffe),基于130億規模的Llama-2打造。

如作者所言,原始的Llama-2和Llama-1都只有4k上下文,很難真正在企業領域被商用。
而現在這個是其8倍的“Giraffe”,直接改變這一局面:
能夠一次處理更大文檔、維持更長時間對話、執行更復雜檢索且結果出錯更少……在開源大模型界中,可謂真正的商業/企業友好。
網友紛紛表示:“太有用了”、“馬上就要試試”。
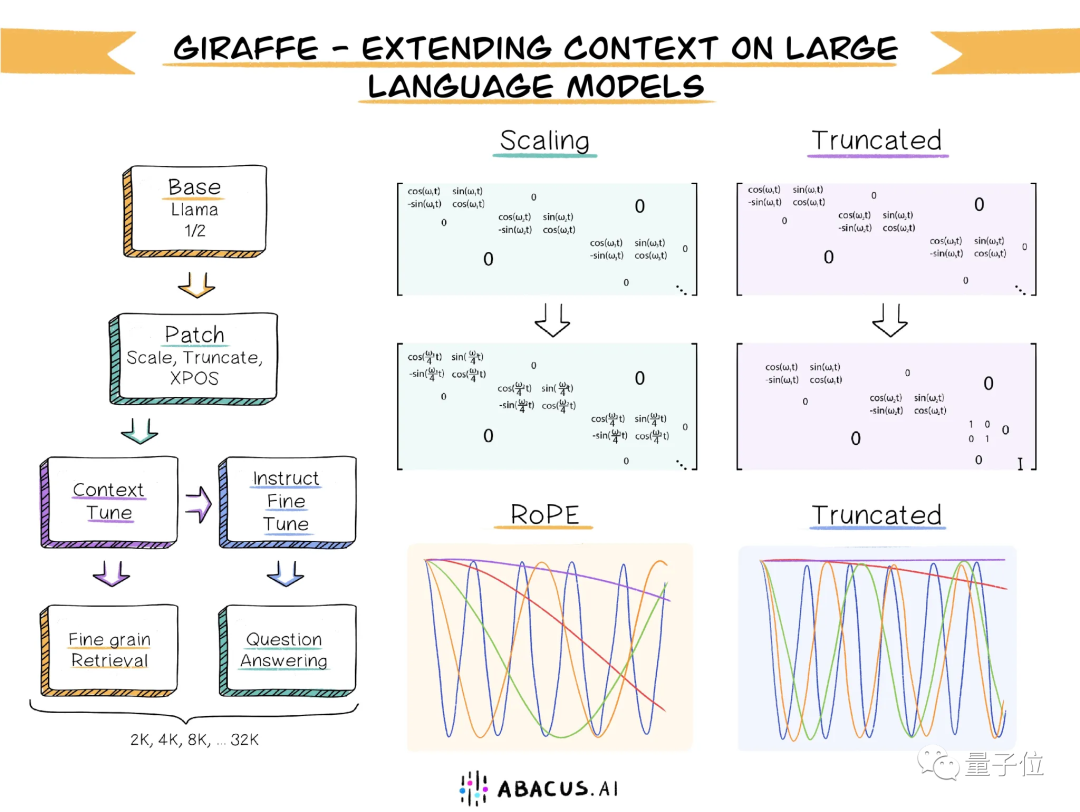
所以,長頸鹿是如何從羊駝“進化”而來的?
擴充上下文長度的探索
這是一家搞AI數據科學平臺的初創企業,成立于2019年,已完成5000萬元C輪融資。
為了擴展開源模型的上下文長度,他們將目前最突出的已有方法整理在一起,并進行徹底測試確定出最有效的方法。
在此之上,他們也提出了一些新思路,其中一種稱為“截斷(truncation)”,它表現出了不小的潛力。
具體來看:
首先團隊發現,目前已有的長下文外推方法普遍都是通過修改注意力機制中使用的位置編碼系統,指示token和activation在輸入序列中的位置而完成。
包括線性縮放/位置插值、xPos、隨機化位置編碼等等。
在此,他們提出了兩種新方法。
一個叫Power Scaling,主要是對原始的RoPE編碼進行了如下變換:
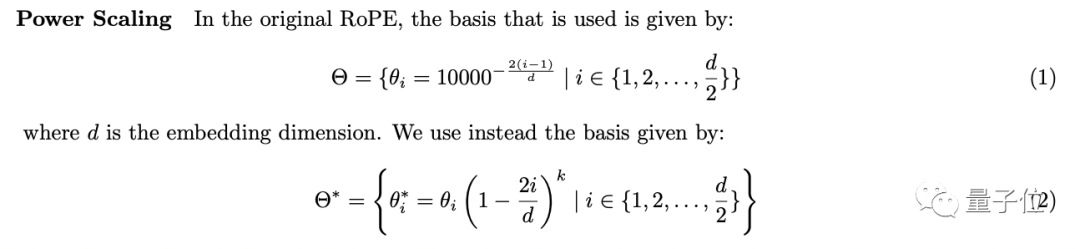
這使得基礎的高頻(短距離)元素比低頻(長距離)元素受到的影響更小,讓模型不得不對低頻元素進行不那么復雜的外推,從而讓整體得到提升。
另一個方法叫Truncated Basis(也就是上面所說的“截斷”),主要是對原始RoPE編碼進行了如下變換:
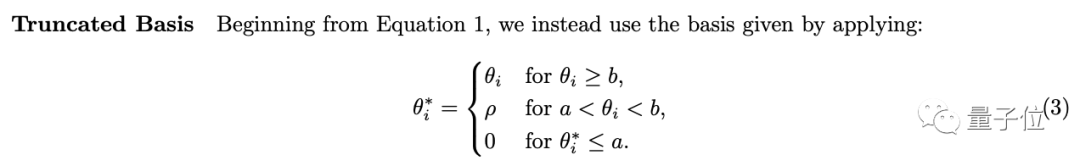
其中ρ是一個相對較小的固定值,a和b是選定的截止值。
作者在這里的想法是,保留basis的高頻分量,但將低頻分量設置為恒定值(比如0)。
而通過明智地選擇截止值a,模型就可以在微調期間(由于正弦函數和正弦函數的周期性)經歷上下文長度中的所有basis值,從而更好地外推到更大的上下文長度。
接下來,便是對以上這些方法進行徹底測試。
在此,作者認為,很多人只用困惑度來衡量模型的長下文能力是遠遠不夠的,因為它的細粒度不夠。
為此,除了困惑度,他們還加了三個新的評估任務(都已公開發布到HuggingFace之上):
FreeFormQA、AlteredNumericQA和LongChat Lines,其中前兩個是一類,為問答任務,第三個為關鍵值檢索任務。
通過使用這兩種類型的任務,我們能夠強制要求模型更加關注完整的上下文,從而獲得高精度的測試結果。
那么結果如何?
直接上結論:
首先,線性插值是最好的上下文長度外推方法。
其次,所有上下文長度外推方法都隨著長度的增加,在任務準確性上出現了下降。
第三,通過在評估階段使用比微調時更高的比例因子,可以進一步增加上下文長度,但比例因子似乎最多只能提高2倍。
以下是這些方法在三個評估數據集上的具體表現(精度為1.0表示性能完美,0.0表示每次評估都是錯誤的):
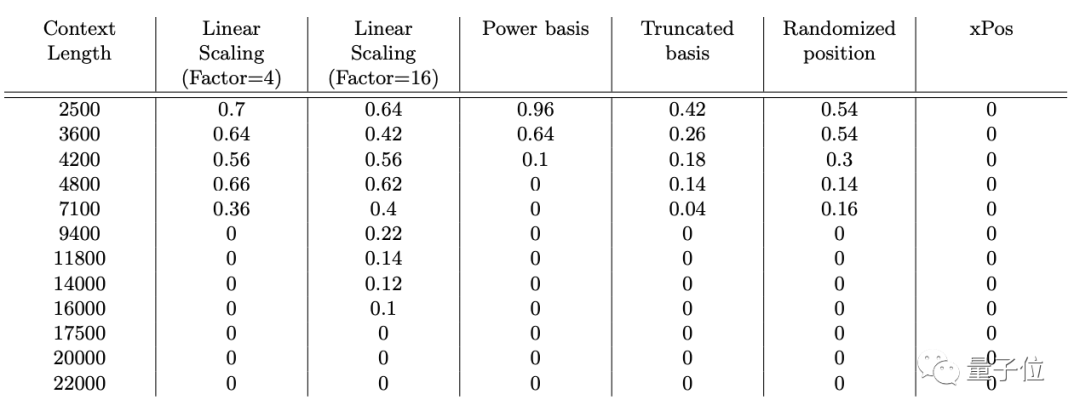
△ LongChat Lines
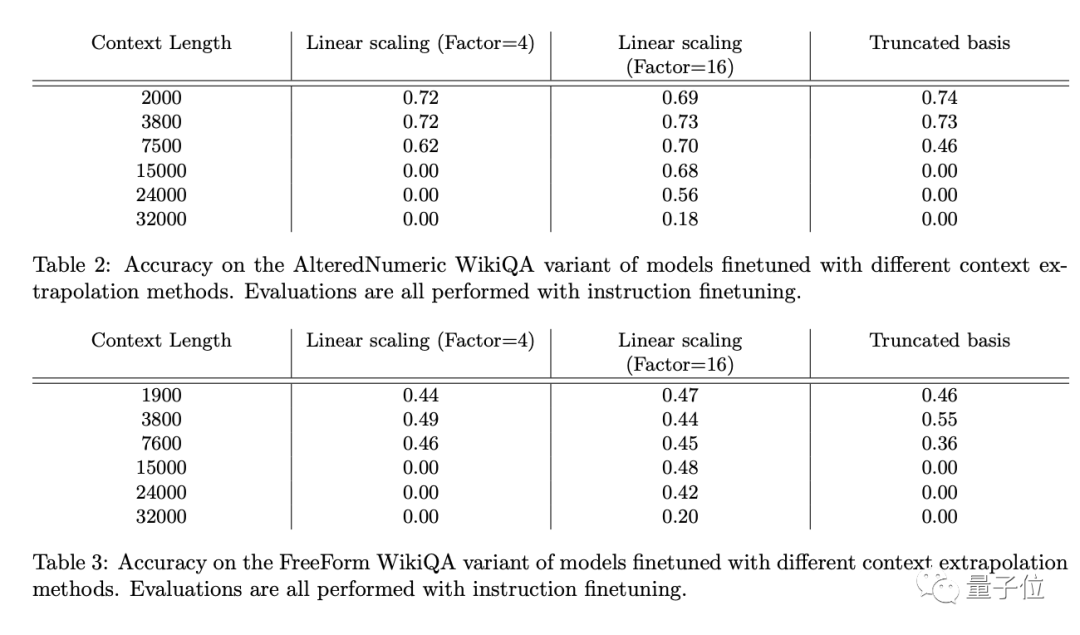
△ AlteredNumericQA和FreeFormQA
可以看到,除了佐證上面的結論,作者們新提出的Truncated Basis方法表現確實不錯,有一定的前景。
而基于以上研究,團隊也在LLaMA2-13B基礎模型上發布了長頸鹿大模型,當然,用的是性能最優的線性插值法。
根據上下文長度不同,長勁鹿家族最終一共有三個版本:4k、16k和32k,感興趣的朋友就可以去HuggingFace上下載了。
其實是并列第一
雖然Abacus.AI號稱長頸鹿是世界首個上下文可達32k的開源LLM,但Together.AI其實更為搶先一步:
他們已在本月初發布了32k的Llama-2-7B大模型(已有近1萬7千次下載),以及在上周五發布了llama-2-7b-32k-instruct。
大家的上下文長度一樣,唯一的大區別是Together.AI的參數規模要小些。
現在,大伙也好奇能不能出一個對比,看看究竟誰更勝一籌。

-
編碼
+關注
關注
6文章
1039瀏覽量
56974 -
開源
+關注
關注
3文章
4207瀏覽量
46140 -
大模型
+關注
關注
2文章
3650瀏覽量
5183
原文標題:32k上下文可商用!羊駝進化成長頸鹿,“開源大模型之最”
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是大模型,智能體...?大模型100問,快速全面了解!

NVIDIA BlueField-4為推理上下文記憶存儲平臺提供強大支持

深入解析NVIDIA Nemotron 3系列開放模型
大語言模型如何處理上下文窗口中的輸入

【CIE全國RISC-V創新應用大賽】基于 K1 AI CPU 的大模型部署落地
請問riscv中斷還需要軟件保存上下文和恢復嗎?
米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
HarmonyOSAI編程智能問答
HarmonyOSAI編程編輯區代碼續寫
三張圖深入分析京東開源Genie的8大亮點
HarmonyOS AI輔助編程工具(CodeGenie)代碼續寫
鴻蒙中Stage模型與FA模型詳解
鴻蒙NEXT-API19獲取上下文,在class中和ability中獲取上下文,API遷移示例-解決無法在EntryAbility中無法使用最新版

Transformer架構中編碼器的工作流程




 工商網監
工商網監
評論