 CVPR 2023 | 完全無監督的視頻物體分割 RCF
CVPR 2023 | 完全無監督的視頻物體分割 RCF


TLDR:視頻分割一直是重標注的一個 task,這篇 CVPR 2023 文章研究了完全不需要標注的視頻物體分割。僅使用 ResNet,RCF模型在 DAVIS16/STv2/FBMS59 上提升了 7/9/5%。文章里還提出了不需要標注的調參方法。代碼已公開可用。
 ?
?
?論文標題:Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
?
?
?論文標題:Bootstrapping Objectness from Videos by Relaxed Common Fate and Visual Grouping
論文鏈接:
https://arxiv.org/abs/2304.08025
作者機構:
UC Berkeley, MSRA, UMich
分割效果視頻:
https://people.eecs.berkeley.edu/~longlian/RCF_video.html
項目主頁:
https://rcf-video.github.io/
代碼鏈接:
https://github.com/TonyLianLong/RCF-UnsupVideoSeg

視頻物體分割真的可以不需要人類監督嗎?
視頻分割一直是重標注的一個 task,可是要標出每一幀上的物體是非常耗時費力的。然而人類可以輕松地分割移動的物體,而不需要知道它們是什么類別。為什么呢?
Gestalt 定律嘗試解釋人類是怎么分割一個場景的,其中有一條定律叫做 Common Fate,即移動速度相同的物體屬于同一類別。比如一個箱子從左邊被拖到右邊,箱子上的點是均勻運動的,人就會把這個部分給分割出來理解。然而人并不需要理解這是個箱子來做這個事情,而且就算是嬰兒之前沒有見過箱子也能知道這是一個物體。
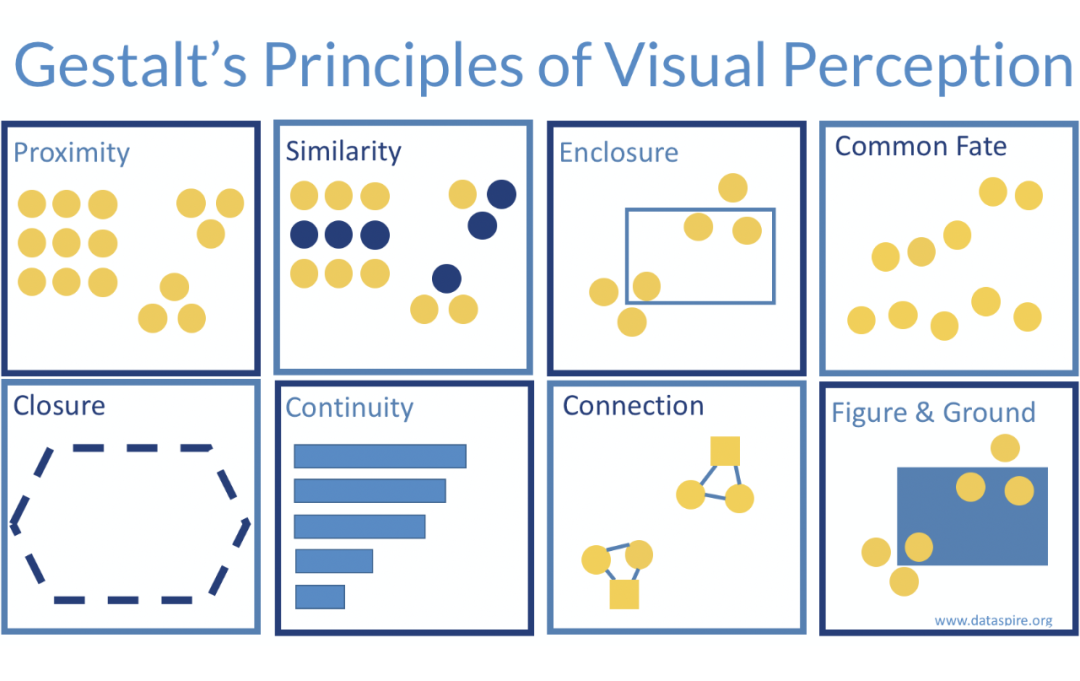

運用Common Fate來分割視頻
這個定律啟發了基于運動的無監督分割。然而,Common Fate 并不是物體性質的可靠指標:關節可動(articulated)/可變形物體(deformable objects)的一些 part 可能不以相同速度移動,而物體的陰影/反射(shadows/reflections)始終隨物體移動,但并非其組成部分。
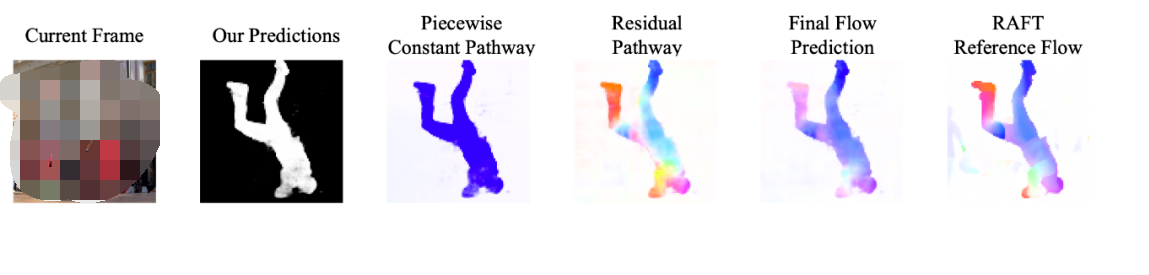
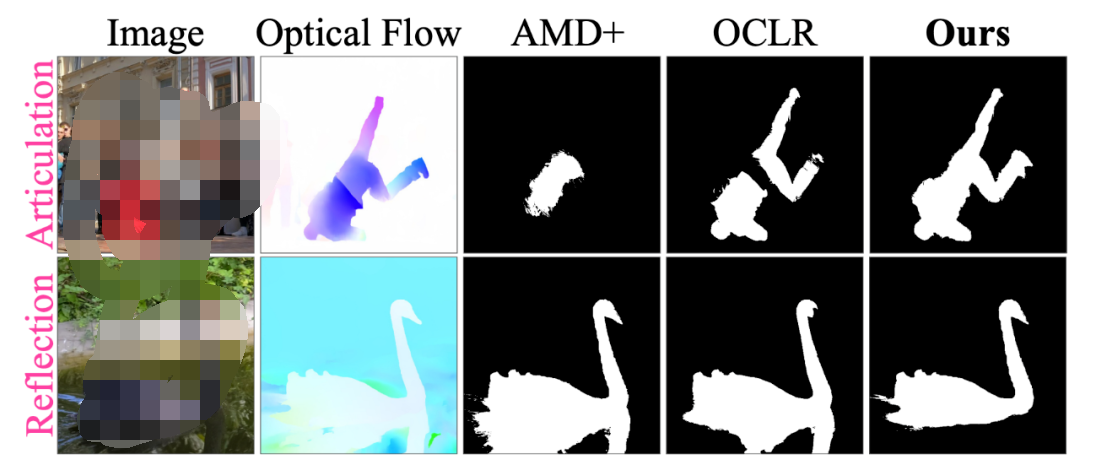
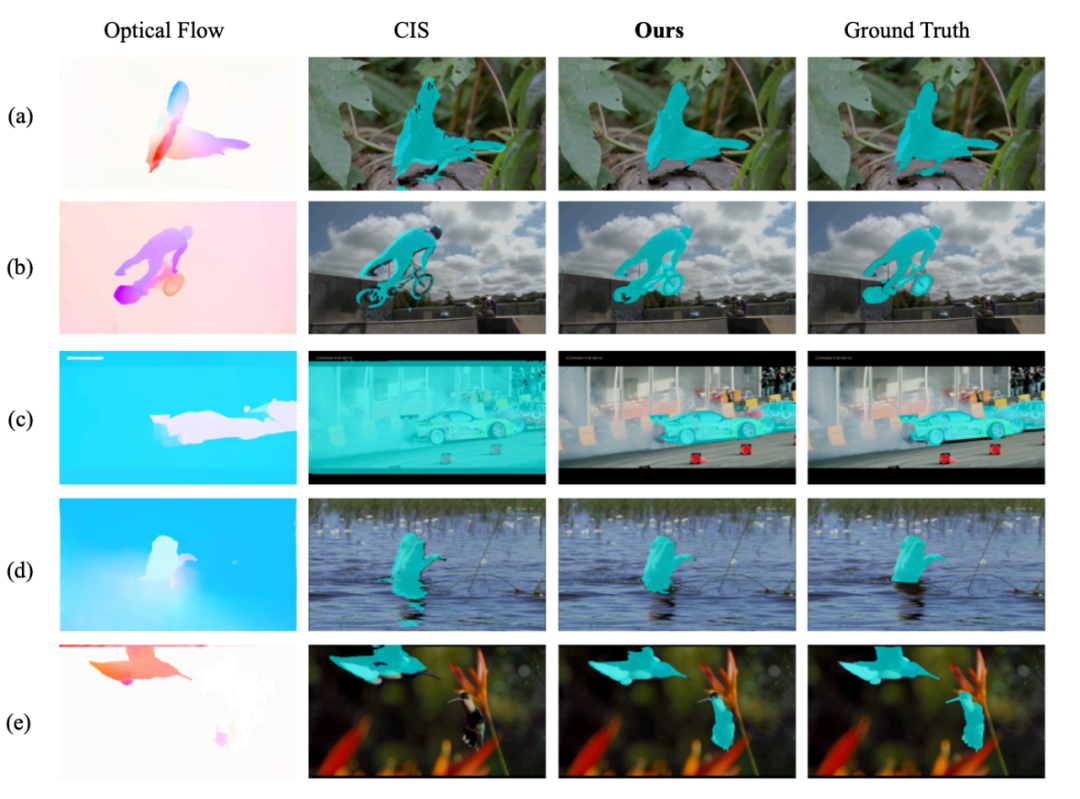
舉個例子,下面這個人的腿和身子的運動是不同的(Optical Flow 可視化出來顏色不同)。這很常見,畢竟人有關節嘛(articulated),要是這個處理不了的話,很多視頻都不能分割了。然而很多 baseline 是處理不了這點的(例如 AMD+ 和 OCLR),他們把人分割成了幾個部分。

還有就是影子和反射,比如上面這只天鵝,它的倒影跟它的運動是一致的(Optical Flow 可視化顏色一樣),所以之前的方法認為天鵝跟倒影是一個物體。很多視頻里是有這類現象的(畢竟大太陽下物體都有個影子嘛),如果這個處理不了的話,很多視頻也不能分割了。

那怎么解決?放松。Relax.
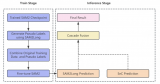
長話短說,那我們的方法是怎么解決這個問題的呢?無監督學習的一個特性是利用神經網絡自己內部的泛化和擬合能力進行學習。既然 Common Fate 有自己的問題,那么我們沒有必要強制神經網絡去擬合 Common Fate。于是我們提出了 Relaxed Common Fate,通過一個比較弱的學習方式讓神經網絡真正學到物體的特性而不是 noise。
具體來說,我們的方法認為物體運動由兩部分組成:物體總體的 piecewise-constant motion (也就是 Common Fate)和物體內部的 segment motion。比如你看下圖這個舞者,他全身的運動就可以被理解成 piecewise-constant motion 來建模,手部腿部這些運動就可以作為 residual motion 進行擬合,最后合并成一個完整的 flow,跟 RAFT 生成的 flow 進行比較來算 loss。我們用的 RAFT 是用合成數據(FlyingChairs 和 FlyingThings)進行訓練的,不需要人工標注。

Relaxed Common Fate
首先我們使用一個 backbone 來進行特征提取,然后通過一個簡單的 full-convolutional network 獲得 Predicted Masks (下圖里的下半部分),和一般的分割框架是一樣的,也可以切換成別的框架。 那我們怎么優化這些 Masks 呢?我們先提取、合并兩幀的特征,放入一個 residual flow prediction head 來獲得 Residual Flow (下圖里的上半部分)。 然后我們對 RAFT 獲得的 Flow 用 Predicted Masks 進行 Guided Pooling,獲得一個 piecewise-constant flow,再加上預測的 residual flow,就是我們的 flow prediction 了。最后把 flow prediction 和 RAFT 獲得的 Flow 的差算一個 L1 norm Loss 進行優化,以此來學習 segmentation。 在測試的時候,只有 Predicted Masks 是有用的,其他部分是不用的。
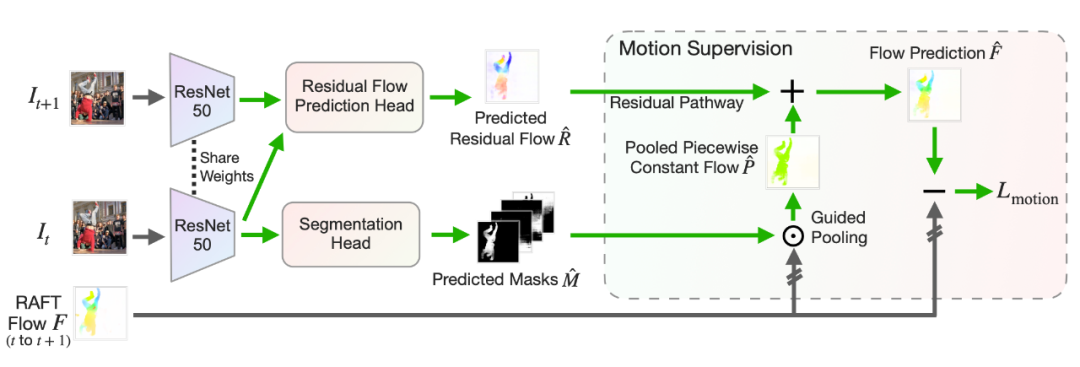 ?
?這里的 Residual Flow 會盡量初始化得小一些,來鼓勵先學 piecewise-constant 的部分(有點類似 ControlNet),再慢慢學習 residual 部分。

引入Appearance信息來幫助無監督視頻分割
光是 Relaxed Common Fate 就能在 DAVIS 上相對 baseline 提 5%了,但這還不夠。前面說 Relaxed Common Fate 的只用了 motion 而沒有使用 appearance 信息。
讓我們再次回到上面這個例子。這個舞者的手和身子是一個顏色,然而 AMD+ 直接把舞者的手忽略了。下面這只天鵝和倒影明明在 appearance 上差別這么大,卻在 motion 上沒什么差別。如果整合 appearance 和 motion,是不是能提升分割質量呢?
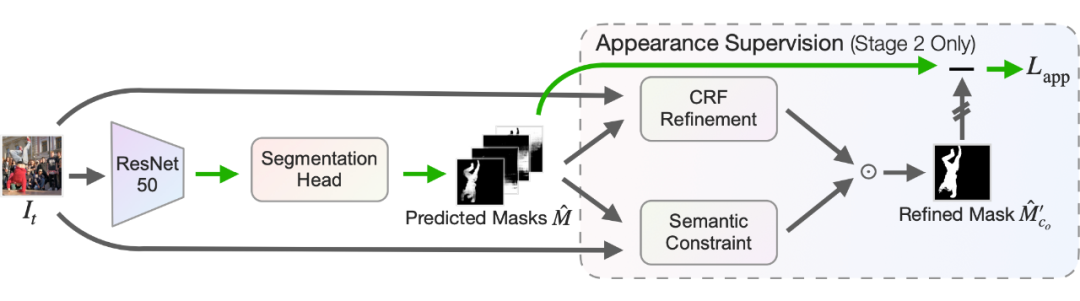
因此我們引入了 Appearance 來進行進一步的監督。在學習完 motion 信息之后,我們直接把取得的 Mask 進行兩步優化:一個是 low-level 的 CRF refinement,強調顏色等細節一致的地方應該屬于同一個 mask(或背景),一個是 semantic constraint,強調 Unsupervised Feature 一直的地方應該屬于同一個 mask。
把優化完的 mask 再和原 mask 進行比較,計算 L2 Loss,再更新神經網絡。這樣訓練的模型的無監督分割能力可以進一步提升。具體細節歡迎閱讀原文。

無監督調參
很多無監督方法都需要使用有標注的數據集來調參,而我們的方法提出可以利用前面說的 motion 和 appearance 的一致性來進行調參。簡單地說,motion 學習出的 mask 在 appearance 上不一致代表這個參數可能不是最優的。具體方法是在 Unsupervised Feature 上計算 Normalized Cuts (但是不用算出最優值),Normalized Cuts 越小越代表分割效果好。原文里面對此有詳細描述。

方法效果
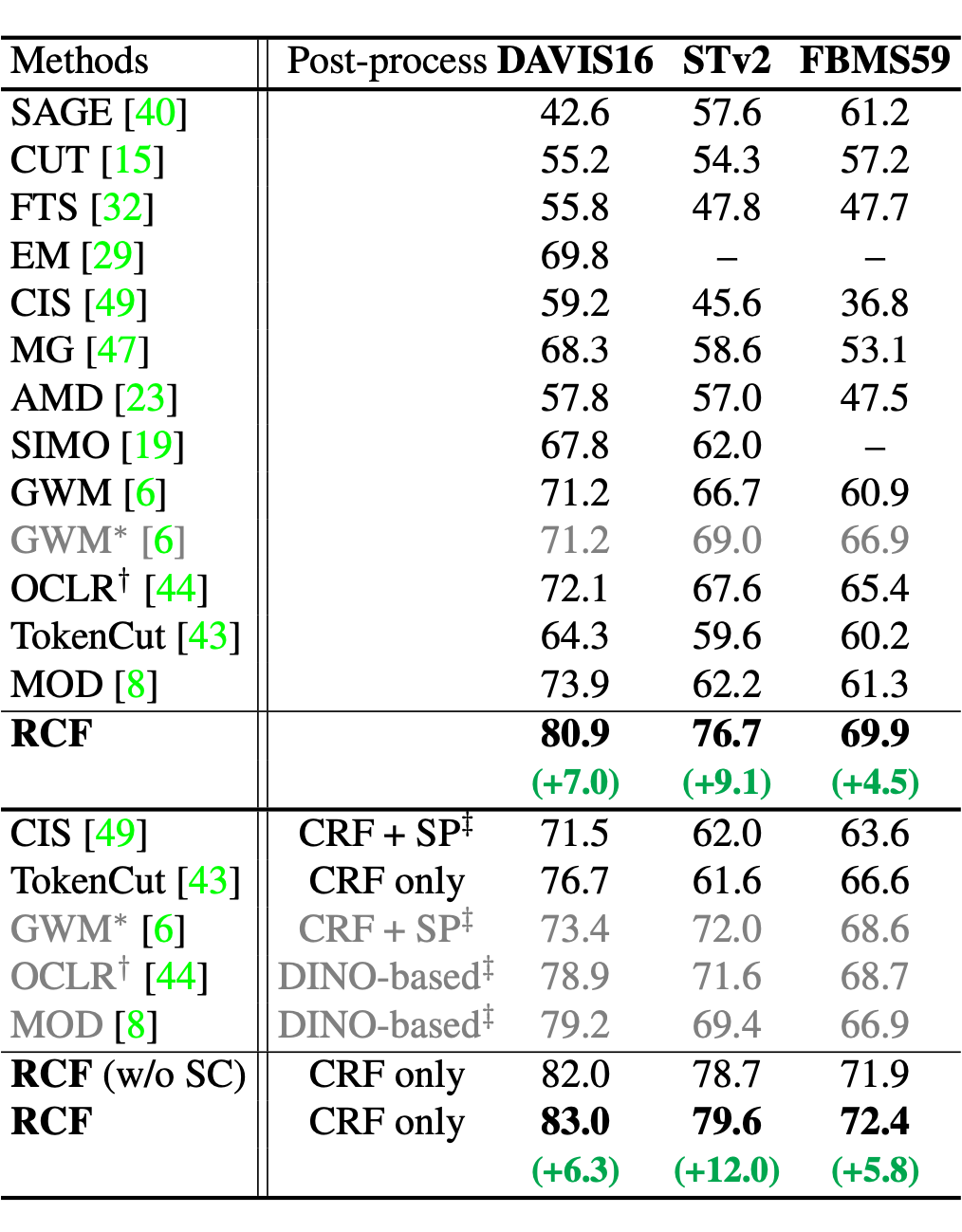
無論是否有 Post-processing,我們的方法在三個視頻分割數據集上都有很大提升,在 STv2 上更是提升了 12%。
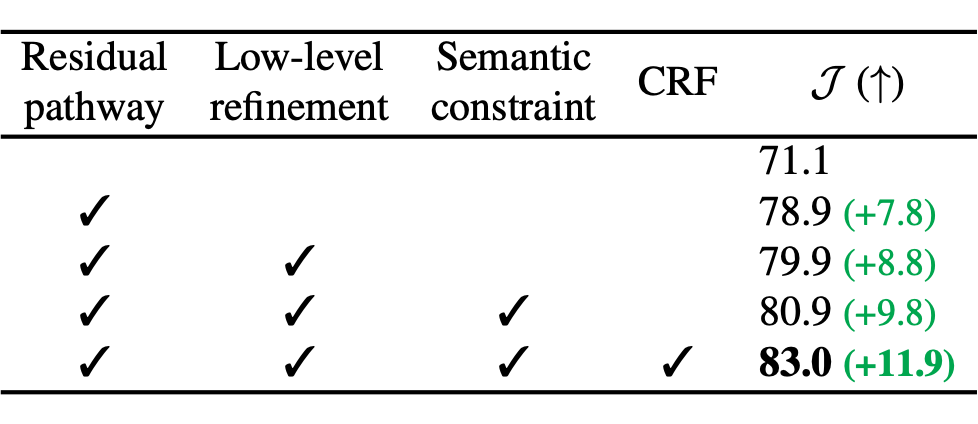
Ablation 可以看出 Residual pathway (Relaxed Common Fate)的貢獻是最大的,其他部分總計貢獻了 11.9% 的增長。
Visualizations




總結
這篇 CVPR 2023 文章研究了完全不需要標注的視頻物體分割。通過 Relaxed Common Fate 來利用 motion 信息,再通過改進和利用 appearance 信息來進一步優化,RCF 模型在 DAVIS16/STv2/FBMS59 上提升了 7/9/5%。文章里還提出了不需要標注的調參方法。代碼和模型已公開可用。
原文標題:CVPR 2023 | 完全無監督的視頻物體分割 RCF
文章出處:【微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
-
物聯網
+關注
關注
2945文章
47820瀏覽量
414886
原文標題:CVPR 2023 | 完全無監督的視頻物體分割 RCF
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Nullmax研發團隊靜態元素檢測和拓撲推理新成果入選CVPR 2026
從CVPR 2019看事件相機步態識別:技術突破與產品應用

百度蘿卜快跑攜手AutoGo啟動阿布扎比全無人駕駛商業化運營
百度蘿卜快跑獲得迪拜全無人駕駛測試許可
百度蘿卜快跑獲得阿布扎比全無人商業化運營許可
傳音TEX AI團隊斬獲ICCV 2025大型視頻目標分割挑戰賽雙料亞軍
手機板 layout 走線跨分割問題
易控智駕榮獲計算機視覺頂會CVPR 2025認可
基于黃金分割搜索法的IPMSM最大轉矩電流比控制
EL非監督分割白皮書丨5張OK圖、1分鐘建模、半小時落地的異常檢測工具!

傳音多媒體團隊攬獲CVPR NTIRE 2025兩項挑戰賽冠亞軍

【正點原子STM32MP257開發板試用】基于 DeepLab 模型的圖像分割
NVIDIA榮獲CVPR 2025輔助駕駛國際挑戰賽冠軍
使用MATLAB進行無監督學習

挑戰具身機器人協同操作新高度!地瓜機器人邀你共戰CVPR 2025雙臂協作機器人競賽




 工商網監
工商網監
評論