") 谷歌發(fā)布語言模型PaLM2,突破3.6萬億個令牌的訓(xùn)練數(shù)量
谷歌發(fā)布語言模型PaLM2,突破3.6萬億個令牌的訓(xùn)練數(shù)量

人工智能和AI技術(shù)的應(yīng)用,是目前很大領(lǐng)域比較重視的部分,而至這個領(lǐng)域的谷歌也擁有不小的實力,就在近日,谷歌最新發(fā)布的語言模型PaLM2就具備很強的競爭力。
據(jù)悉,令牌是指訓(xùn)練大語言模型所使用的單詞串,它們對于教導(dǎo)模型如何預(yù)測字符串中可能出現(xiàn)的下一個單詞至關(guān)重要。
而在去年發(fā)布的上一代模型PaLM僅使用了7800億個令牌,而PaLM2則提升到了3.6萬億個令牌。同時PaLM2在編程、數(shù)學(xué)和創(chuàng)意寫作方面表現(xiàn)更為優(yōu)秀,得益于其龐大的訓(xùn)練數(shù)據(jù)。而這些也將有效提升用戶的工作效率,減輕工作量。
另據(jù)報道,PaLM2是基于3400億個參數(shù)進行訓(xùn)練的,而初始版本的PaLM則基于5400億個參數(shù),而這也造就PaLM2比現(xiàn)有的任何模型都更加強大。
該模型采用了一種名為“計算機優(yōu)化擴張”的新技術(shù),使得大語言模型具備更高的效率和整體性能,包括加快推理速度、減少參數(shù)調(diào)用和降低服務(wù)成本。
相信隨著社會科技的進步,Ai技術(shù)的應(yīng)用也將給我們的生活帶來諸多的變化。
以上源自互聯(lián)網(wǎng),版權(quán)歸原作所有
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
谷歌
+關(guān)注
關(guān)注
27文章
6254瀏覽量
111377 -
人工智能
+關(guān)注
關(guān)注
1817文章
50096瀏覽量
265313
發(fā)布評論請先 登錄
相關(guān)推薦
熱點推薦
從訓(xùn)練到推理:大模型算力需求的新拐點已至
在大模型產(chǎn)業(yè)發(fā)展的早期階段,行業(yè)焦點主要集中在大模型訓(xùn)練所需的算力投入。一個萬億參數(shù)大模型的

什么是大模型,智能體...?大模型100問,快速全面了解!
一、概念篇1.什么是大模型?大模型是指參數(shù)規(guī)模巨大(通常達到數(shù)十億甚至萬億級別)、使用海量數(shù)據(jù)訓(xùn)練而成的人工智能模型。
谷歌正式發(fā)布Gemma Scope 2模型
大語言模型 (LLM) 具備令人驚嘆的推理能力,但其內(nèi)部決策過程在很大程度上仍然不透明。如果系統(tǒng)未按預(yù)期運行,對其內(nèi)部運作機制缺乏可見性將難以準(zhǔn)確定位問題根源。過去,我們通過發(fā)布 Gemma
摩爾線程新一代大語言模型對齊框架URPO入選AAAI 2026
近日,摩爾線程在人工智能前沿領(lǐng)域取得重要突破,其提出的新一代大語言模型對齊框架——URPO統(tǒng)一獎勵與策略優(yōu)化,相關(guān)研究論文已被人工智能領(lǐng)域的國際頂級學(xué)術(shù)會議AAAI 2026收錄。這一成果標(biāo)志著摩爾線程在大
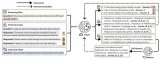
谷歌與耶魯大學(xué)合作發(fā)布最新C2S-Scale 27B模型
我們很榮幸發(fā)布與耶魯大學(xué)合作研究的 Cell2Sentence-Scale 27B (C2S-Scale),這是一個新的 270 億參數(shù)基礎(chǔ)模型
在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗
本帖欲分享在Ubuntu20.04系統(tǒng)中訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型的一些經(jīng)驗。我們采用jupyter notebook作為開發(fā)IDE,以TensorFlow2為訓(xùn)練框架,目標(biāo)是
發(fā)表于 10-22 07:03
借助NVIDIA Megatron-Core大模型訓(xùn)練框架提高顯存使用效率
隨著模型規(guī)模邁入百億、千億甚至萬億參數(shù)級別,如何在有限顯存中“塞下”訓(xùn)練任務(wù),對研發(fā)和運維團隊都是巨大挑戰(zhàn)。NVIDIA Megatron-Core 作為流行的大模型

摩爾線程發(fā)布大模型訓(xùn)練仿真工具SimuMax v1.0
近日,摩爾線程正式發(fā)布并開源大模型分布式訓(xùn)練仿真工具SimuMax 1.0版本。該版本在顯存和性能仿真精度上實現(xiàn)突破性提升,同時引入多項關(guān)鍵功能,進一步增強了

Vicor電源模塊突破數(shù)據(jù)中心AI電力困境
盡管底層硅芯片的性能有了巨大的飛躍,但人工智能 (AI) 訓(xùn)練仍在推動數(shù)據(jù)中心電力的突破。斯坦福大學(xué)最新的 AI 指數(shù)報告顯示,最先進的 AI 模型越來越大,現(xiàn)已達到高達 1 萬億
萬億參數(shù)!元腦企智一體機率先支持Kimi K2大模型
應(yīng)用大模型提供高處理性能和完善的軟件工具平臺支持。 ? Kimi K2是月之暗面推出的開源萬億參數(shù)大模型,創(chuàng)新使用了MuonClip優(yōu)化器進行訓(xùn)練
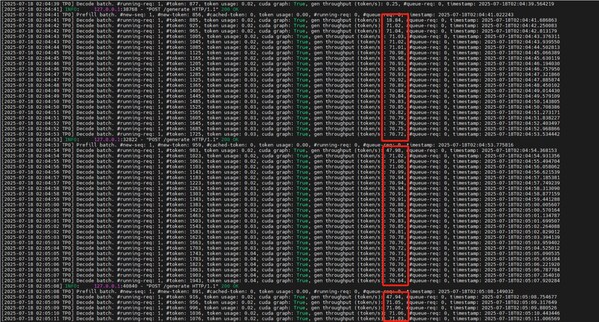
NVIDIA GTC巴黎亮點:全新Cosmos Predict-2世界基礎(chǔ)模型與CARLA集成加速智能汽車訓(xùn)練
。這種向使用大模型的過渡大大增加了對用于訓(xùn)練、測試和驗證的高質(zhì)量、基于物理學(xué)傳感器數(shù)據(jù)的需求。 為加速下一代輔助駕駛架構(gòu)的開發(fā),NVIDIA 發(fā)布了?NVIDIA Cosmos Predict-
RAKsmart智能算力架構(gòu):異構(gòu)計算+低時延網(wǎng)絡(luò)驅(qū)動企業(yè)AI訓(xùn)練范式升級
在AI大模型參數(shù)量突破萬億、多模態(tài)應(yīng)用爆發(fā)的今天,企業(yè)AI訓(xùn)練正面臨算力效率與成本的雙重挑戰(zhàn)。RAKsmart推出的智能算力架構(gòu),以異構(gòu)計算
用PaddleNLP為GPT-2模型制作FineWeb二進制預(yù)訓(xùn)練數(shù)據(jù)集
作者:算力魔方創(chuàng)始人/英特爾創(chuàng)新大使劉力 《用PaddleNLP在4060單卡上實踐大模型預(yù)訓(xùn)練技術(shù)》發(fā)布后收到讀者熱烈反響,很多讀者要求進一步講解更多的技術(shù)細節(jié)。本文主要針對大語言

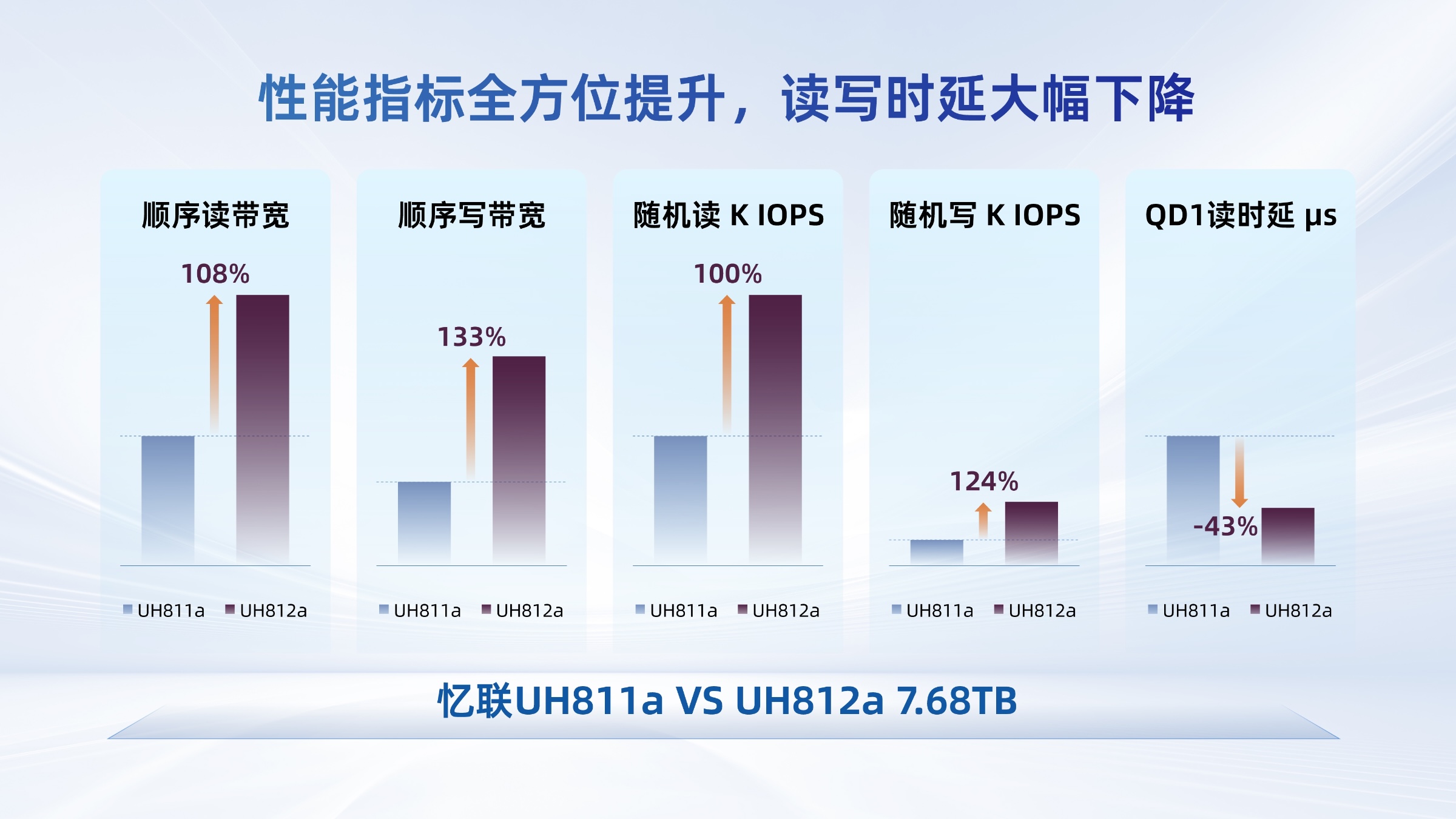
憶聯(lián)PCIe 5.0 SSD支撐大模型全流程訓(xùn)練
當(dāng)前,大模型全流程訓(xùn)練對數(shù)據(jù)存儲系統(tǒng)的要求已突破傳統(tǒng)邊界。企業(yè)級SSD作為AI算力基礎(chǔ)設(shè)施的核心組件,其高可靠性、高性能及智能化管理能力,正成為支撐大模型
訓(xùn)練好的ai模型導(dǎo)入cubemx不成功怎么處理?
訓(xùn)練好的ai模型導(dǎo)入cubemx不成功咋辦,試了好幾個模型壓縮了也不行,ram占用過大,有無解決方案?
發(fā)表于 03-11 07:18



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論