") 高效理解機(jī)器學(xué)習(xí)
高效理解機(jī)器學(xué)習(xí)

來(lái)源:DeepNoMind
對(duì)于初學(xué)者來(lái)說(shuō),機(jī)器學(xué)習(xí)相當(dāng)復(fù)雜,可能很容易迷失在細(xì)節(jié)的海洋里。本文通過(guò)將機(jī)器學(xué)習(xí)算法分為三個(gè)類別,梳理出一條相對(duì)清晰的路線,幫助初學(xué)者理解機(jī)器學(xué)習(xí)算法的基本原理,從而更高效地學(xué)習(xí)機(jī)器學(xué)習(xí)。原文:Machine Learning in Three Steps: How to Efficiently Learn It[1]
當(dāng)有志于成為數(shù)據(jù)科學(xué)家的學(xué)習(xí)者試圖學(xué)習(xí)機(jī)器學(xué)習(xí)算法時(shí),通常會(huì)采用兩種極端方法。第一種方法是學(xué)習(xí)并從頭實(shí)現(xiàn)所有復(fù)雜算法,從而期待真正掌握這些算法。另一種方法假設(shè)計(jì)算機(jī)可以自己"學(xué)習(xí)",因此個(gè)人沒有必要學(xué)習(xí)算法,從而導(dǎo)致一些人只依賴于諸如lazypredict之類的工具軟件包。
在學(xué)習(xí)機(jī)器學(xué)習(xí)算法時(shí),比較現(xiàn)實(shí)的是在這兩個(gè)極端中間采取某種方法。不過(guò)還有問(wèn)題,那就是從哪里開始呢?本文中我將把機(jī)器學(xué)習(xí)算法分為三類,并就從什么開始和可以跳過(guò)什么提供一些拙見。
機(jī)器學(xué)習(xí)算法的復(fù)雜性
由于可用算法眾多,開始學(xué)習(xí)機(jī)器學(xué)習(xí)可能很快就會(huì)被壓垮。線性回歸(linear regression)、支持向量機(jī)(SVM, support vector machine)、梯度下降(gradient descent)、梯度增強(qiáng)(gradient boosting)、決策樹(decision tree)、LASSO(Least Absolute Shrinkage and Selection Operator)、嶺回歸(ridge)、網(wǎng)格搜索(grid search)、等等,都是在提出這個(gè)問(wèn)題時(shí)立馬能夠想到的一些算法。
在監(jiān)督學(xué)習(xí)領(lǐng)域,這些算法有不同的目的和目標(biāo)。本文只討論監(jiān)督學(xué)習(xí)。
為了更好地理解各種技術(shù),根據(jù)其目標(biāo)和復(fù)雜度級(jí)別進(jìn)行分類是有幫助的。通過(guò)將這些算法組織成不同類別和復(fù)雜度,可以簡(jiǎn)化概念,使其更容易理解。這種方法可以極大增強(qiáng)人們對(duì)機(jī)器學(xué)習(xí)的理解,并幫助確定用于特定任務(wù)或目標(biāo)的最合適的技術(shù)。
當(dāng)學(xué)生深入研究機(jī)器學(xué)習(xí)領(lǐng)域時(shí),可能會(huì)因?yàn)槠鋸?fù)雜性而感到氣餒。然而,在付諸實(shí)踐之前,沒有必要學(xué)習(xí)或熟悉所有算法。機(jī)器學(xué)習(xí)領(lǐng)域的不同職位可能需要不同熟練程度,在某些方面缺乏知識(shí)是可以接受的。例如,數(shù)據(jù)科學(xué)家、數(shù)據(jù)分析師、數(shù)據(jù)工程師和機(jī)器學(xué)習(xí)研究人員這些不同的角色有不同的要求。
對(duì)整個(gè)過(guò)程有廣泛的理解可以使機(jī)器學(xué)習(xí)從業(yè)者在時(shí)間緊迫的情況下跳過(guò)某些技術(shù)細(xì)節(jié),同時(shí)仍然理解整個(gè)過(guò)程。
1. 分解機(jī)器學(xué)習(xí)算法
1.1 模型、訓(xùn)練和調(diào)優(yōu)
"機(jī)器學(xué)習(xí)算法"的范圍相當(dāng)廣泛,可以分為三種主要類型的算法:
- 用于接收輸入數(shù)據(jù)并隨后生成預(yù)測(cè)的機(jī)器學(xué)習(xí)模型,如線性回歸、支持向量機(jī)、決策樹、KNN等。
- 用于創(chuàng)建或優(yōu)化模型的**模型訓(xùn)練/擬合算法(model training/fitting algorithms)**,即為特定數(shù)據(jù)集找到模型的參數(shù)。不同的機(jī)器學(xué)習(xí)模型有其特定的訓(xùn)練算法。雖然梯度下降是最著名的訓(xùn)練基于數(shù)學(xué)函數(shù)的模型的方法,但其他機(jī)器學(xué)習(xí)模型可以使用不同的技術(shù)進(jìn)行訓(xùn)練,本文將在后面的部分中更詳細(xì)探討這些技術(shù)。
- **超參數(shù)調(diào)優(yōu)(hyperparameter tuning)**,即尋找機(jī)器學(xué)習(xí)模型的最優(yōu)超參數(shù)。與訓(xùn)練過(guò)程相反,超參數(shù)調(diào)優(yōu)的過(guò)程通常不依賴于機(jī)器學(xué)習(xí)模型。盡管還有其他替代方法,但網(wǎng)格搜索是執(zhí)行此任務(wù)的一種流行且常用的方法,我們將在本文后面深入討論。
1.2 三類ML模型
第一種類型涉及能夠接收數(shù)據(jù)并根據(jù)該數(shù)據(jù)生成預(yù)測(cè)的模型。這些模型可以分為三大類:
- 基于距離(Distance-based)的模型,包括K-近鄰(K-nearest-neighbors)、線性判別分析(Linear Discriminant Analysis)和二次判別分析(Quadratic Discriminant Analysis)。在scikit-learn庫(kù)中,這些也被稱為"估算器(estimators)"。
- 基于決策樹(Decision tree)的模型,例如單個(gè)決策樹(用于分類或回歸)、隨機(jī)森林(Random Forest)和梯度增強(qiáng)決策樹(Gradient-Boosted Decision Trees)。
- 基于數(shù)學(xué)函數(shù)(Mathematical functions)的模型,也被稱為參數(shù)模型,是假設(shè)輸入和輸出之間關(guān)系的特定函數(shù)形式的模型。可以進(jìn)一步分為線性模型(linear model),如OLS回歸、SVM(具有線性核)、Ridge和LASSO,以及非線性模型,如具有非線性核的SVM和神經(jīng)網(wǎng)絡(luò)。
1.3 元模型和集成方法
在機(jī)器學(xué)習(xí)中,元模型(meta-model)是一種將多個(gè)個(gè)體模型的預(yù)測(cè)結(jié)果結(jié)合起來(lái)以獲得更準(zhǔn)確預(yù)測(cè)的模型,也被稱為"堆疊模型(stacked model)"或"超級(jí)學(xué)習(xí)器(super learner)"。構(gòu)成元模型的個(gè)體模型可以是不同類型的或使用不同算法,它們的預(yù)測(cè)結(jié)果可以通過(guò)加權(quán)平均或其他技術(shù)進(jìn)行組合。
元模型的目標(biāo)是通過(guò)減少個(gè)體模型可能存在的方差和偏差來(lái)提高預(yù)測(cè)的總體準(zhǔn)確性和魯棒性,并且通過(guò)捕捉數(shù)據(jù)中更復(fù)雜的模式來(lái)克服個(gè)體模型的局限性。
常見的創(chuàng)建元模型的方法是基于集成的方法,比如打包(bagging)、增強(qiáng)(boosting)或堆疊(stacking)。
- 打包(Bagging)或Bootstrap Aggregating是一種通過(guò)組合基于數(shù)據(jù)集的不同樣本訓(xùn)練多個(gè)模型來(lái)減少模型方差的機(jī)器學(xué)習(xí)技術(shù)。Bagging背后的思想是生成多個(gè)模型,每個(gè)模型都有一個(gè)數(shù)據(jù)子集,然后組合起來(lái)創(chuàng)建一個(gè)更健壯、更不易過(guò)擬合的模型。
- 增強(qiáng)(Boosting)是另一種集成方法,將多個(gè)弱模型組合在一起創(chuàng)建一個(gè)強(qiáng)模型。與Bagging不同的不同之處在于,Bagging是獨(dú)立訓(xùn)練每個(gè)模型,而Boosting是按順序訓(xùn)練模型,每個(gè)新模型都是在之前模型錯(cuò)誤分類的數(shù)據(jù)上進(jìn)行訓(xùn)練,通過(guò)匯總所有模型的預(yù)測(cè)來(lái)完成最終的預(yù)測(cè)。
- 堆疊(Stacking)或堆疊泛化(stacked generalization),是一種元模型集成方法,方法是訓(xùn)練多個(gè)基本模型,并以基本模型的預(yù)測(cè)作為更高級(jí)模型的輸入,高級(jí)模型通過(guò)結(jié)合基本模型的預(yù)測(cè)來(lái)做出最終預(yù)測(cè)。
- 隨機(jī)森林(Random forests)是Bagging的延伸,增加了額外的隨機(jī)性。除了對(duì)數(shù)據(jù)進(jìn)行隨機(jī)抽樣外,隨機(jī)森林還為每個(gè)分割隨機(jī)選擇特征子集,從而有助于減少過(guò)擬合并增加集合中模型的多樣性。
集成方法最常應(yīng)用于決策樹,而非線性回歸等線性模型。這是因?yàn)闆Q策樹比線性模型更容易出現(xiàn)過(guò)擬合,而集成方法通過(guò)組合多個(gè)模型有助于減少過(guò)擬合。
決策樹有高方差和低偏差,意味著容易過(guò)度擬合訓(xùn)練數(shù)據(jù),導(dǎo)致在新的、未見過(guò)的數(shù)據(jù)上表現(xiàn)不佳。集成方法通過(guò)聚合多個(gè)決策樹的預(yù)測(cè)來(lái)解決這個(gè)問(wèn)題,從而產(chǎn)生更健壯和準(zhǔn)確的模型。
另一方面,線性模型(如線性回歸)具有低方差和高偏差,意味著不太容易過(guò)度擬合,但可能造成欠擬合。集成方法對(duì)線性模型不那么有效,因?yàn)槟P鸵呀?jīng)是低方差的,無(wú)法從聚合中獲益。
然而,在某些情況下,集成方法仍然可以應(yīng)用于線性模型。例如,Bagging中使用的自舉聚合技術(shù)可以應(yīng)用于任何類型模型,包括線性回歸。在這種情況下,Bagging算法會(huì)對(duì)訓(xùn)練數(shù)據(jù)進(jìn)行采樣,并在自舉樣本上擬合多個(gè)線性回歸模型,從而使模型更穩(wěn)定、更具有魯棒性。然而,值得注意的是,得到的模型仍然是線性回歸模型,而不是元模型。
總的來(lái)說(shuō),雖然集成方法最常用于決策樹,但在某些情況下,也可以與線性模型一起使用,重要的是要記住每種模型的優(yōu)點(diǎn)和局限性,并為手頭的問(wèn)題選擇合適的方法。
1.4 機(jī)器學(xué)習(xí)算法概述
下圖提供了三類機(jī)器學(xué)習(xí)算法的摘要,本文后續(xù)部分將更深入研究每個(gè)類別。
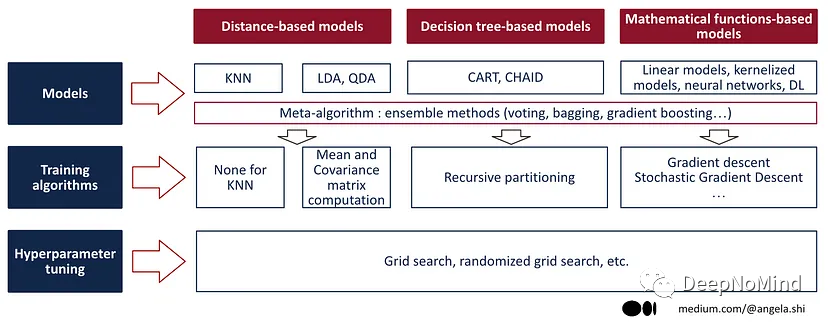
機(jī)器學(xué)習(xí)算法概述
2. 機(jī)器學(xué)習(xí)模型
本節(jié)我們將仔細(xì)研究機(jī)器學(xué)習(xí)模型的三大類別:
(1) 基于距離的模型
基于距離的模型:KNN
貝葉斯分類:LDA, QDA
(2) 決策樹模型
(3) 基于數(shù)學(xué)函數(shù)的模型
- 線性模型
- 核支持向量機(jī)(kernel SVM)或核嶺(kernel ridge)等核化模型(Kernelized models)
- 神經(jīng)網(wǎng)絡(luò)
2.1 基于距離的模型
第一類機(jī)器學(xué)習(xí)模型是基于距離的模型,這些模型利用數(shù)據(jù)點(diǎn)之間的距離進(jìn)行預(yù)測(cè)。
最簡(jiǎn)單、最具代表性的模型是K近鄰模型(KNN, K-Nearest Neighbors),可以計(jì)算新數(shù)據(jù)點(diǎn)與數(shù)據(jù)集中所有現(xiàn)有數(shù)據(jù)點(diǎn)之間的距離,然后選擇K個(gè)最近的鄰居,并將新數(shù)據(jù)點(diǎn)分配給K個(gè)鄰居中最常見的類。
在檢驗(yàn)K近鄰(KNN)算法時(shí),注意到在訓(xùn)練階段沒有建立顯式模型。在KNN中,對(duì)新觀測(cè)值的預(yù)測(cè)是通過(guò)在訓(xùn)練集中找到與該觀測(cè)值最近的K個(gè)鄰居,并取其目標(biāo)值的平均值或多數(shù)投票來(lái)完成的。
與其他算法在訓(xùn)練期間將模型擬合到數(shù)據(jù)不同,KNN存儲(chǔ)整個(gè)訓(xùn)練數(shù)據(jù)集,并簡(jiǎn)單地計(jì)算新觀測(cè)值與現(xiàn)有數(shù)據(jù)集之間的距離來(lái)進(jìn)行預(yù)測(cè)。因此,KNN可以被認(rèn)為是一種"懶學(xué)習(xí)(lazy learning)"算法,在訓(xùn)練階段不主動(dòng)構(gòu)建模型,并將決策過(guò)程推遲到推理時(shí)。
因此,推理/測(cè)試階段可能很慢,可以用更有效的算法(如k-d樹)進(jìn)行優(yōu)化。
2.2 貝葉斯分類
線性判別分析(LDA,Linear Discriminant Analysis)和二次判別分析(QDA,Quadratic Discriminant Analysis)都是基于距離的模型,利用馬氏距離(Mahalanobis distance)進(jìn)行預(yù)測(cè),馬氏距離是點(diǎn)和分布之間距離的度量,因此考慮到了變量之間的相關(guān)性。
LDA假設(shè)不同類別的方差相同,而QDA假設(shè)每個(gè)類別的方差不同。這意味著LDA假設(shè)所有類別的協(xié)方差矩陣是相同的,而QDA允許每個(gè)類別有自己的協(xié)方差矩陣。
2.3 基于決策樹的模型
第二種機(jī)器學(xué)習(xí)模型是基于決策樹的模型,也被稱為基于規(guī)則的模型(rule-based models)。這種模型生成一組規(guī)則,用來(lái)解釋如何做出決策或預(yù)測(cè)。
決策樹的每個(gè)分支代表一個(gè)規(guī)則或條件,用于確定接下來(lái)要遵循的數(shù)據(jù)子集。這些規(guī)則通常采用簡(jiǎn)單的if-then語(yǔ)句的形式,例如"如果變量X的值大于5,則遵循左分支,否則遵循右分支"。
決策樹的最終葉節(jié)點(diǎn)表示的是基于輸入變量值以及相關(guān)規(guī)則所做出的目標(biāo)變量預(yù)測(cè)類/值。
決策樹的優(yōu)點(diǎn)是易于解釋和理解,因?yàn)橐?guī)則可以以清晰直觀的方式可視化和解釋,因此對(duì)于向非技術(shù)相關(guān)方解釋預(yù)測(cè)或決策背后的原因非常有用。
然而,決策樹也容易出現(xiàn)過(guò)擬合,當(dāng)模型變得過(guò)于復(fù)雜,與訓(xùn)練數(shù)據(jù)擬合過(guò)于緊密時(shí),就會(huì)出現(xiàn)過(guò)擬合,從而導(dǎo)致對(duì)新數(shù)據(jù)的泛化能力差。為了解決這個(gè)問(wèn)題,通常將集成方法應(yīng)用于決策樹。
2.4 基于數(shù)學(xué)函數(shù)的模型
第三類機(jī)器學(xué)習(xí)模型是基于數(shù)學(xué)函數(shù)的模型,基于數(shù)學(xué)函數(shù)模擬輸入變量和目標(biāo)變量之間的關(guān)系。線性模型(如普通最小二乘(OLS,Ordinary Least Squares)回歸、具有線性核的支持向量機(jī)(SVM,Support Vector Machines)、Ridge、LASSO)假設(shè)輸入變量與目標(biāo)變量之間的關(guān)系是線性的。非線性模型,如具有非線性核的支持向量機(jī)和神經(jīng)網(wǎng)絡(luò),可以模擬輸入變量和目標(biāo)變量之間更復(fù)雜的關(guān)系。
對(duì)于基于數(shù)學(xué)函數(shù)的模型,如線性回歸或邏輯回歸,必須定義損失函數(shù)。損失函數(shù)衡量模型的預(yù)測(cè)與實(shí)際數(shù)據(jù)的匹配程度,目標(biāo)是通過(guò)調(diào)整模型參數(shù)最小化損失函數(shù)。
相比之下,對(duì)于非數(shù)學(xué)函數(shù)為基礎(chǔ)的模型(如KNN或決策樹),不需要定義損失函數(shù),而是通過(guò)不同的方法進(jìn)行匹配,例如在KNN的情況下找到最近的鄰居,或者在決策樹的情況下根據(jù)特征值遞歸分割數(shù)據(jù)。
在基于數(shù)學(xué)函數(shù)的模型中,定義合適的損失函數(shù)至關(guān)重要,因?yàn)樗鼪Q定了模型要解決的優(yōu)化問(wèn)題。可以根據(jù)手頭問(wèn)題使用不同的損失函數(shù),例如回歸問(wèn)題的均方誤差或二元分類問(wèn)題的交叉熵。
值得注意的是,所有具有線性核的線性模型(如OLS、LASSO、Ridge、SVM等),都可以寫成線性方程y = wX + b的形式。然而,這些模型之間的區(qū)別在于用于估計(jì)模型參數(shù)w和b的最優(yōu)值的代價(jià)函數(shù)。
因此,雖然所有這些模型都可以以相同的數(shù)學(xué)函數(shù)的形式編寫,但重要的是要注意選擇的代價(jià)函數(shù)決定了模型的行為和性能,因此可以將它們視為具有不同代價(jià)函數(shù)的不同模型,而不是具有不同代價(jià)函數(shù)的同一模型。
非線性模型是解決復(fù)雜機(jī)器學(xué)習(xí)問(wèn)題的強(qiáng)大工具,而線性模型無(wú)法充分解決這些問(wèn)題。在實(shí)踐中基本上有兩種方法:核技巧(kernel trick)和神經(jīng)網(wǎng)絡(luò)。
核技巧是一種有效實(shí)現(xiàn)特征映射的方法,無(wú)需顯式計(jì)算轉(zhuǎn)換后的特征。相反,它定義核函數(shù)來(lái)計(jì)算轉(zhuǎn)換后的特征空間中輸入樣本對(duì)之間的相似性。通過(guò)使用核函數(shù),可以隱式地將輸入數(shù)據(jù)映射到高維空間,在高維空間中可以更容易地分離和建模。
從這個(gè)意義上說(shuō),核部分可以看作是特征工程的一種形式,其中模型能夠創(chuàng)建更適合手頭任務(wù)的新特征。這與傳統(tǒng)特征工程不一樣,在傳統(tǒng)特征工程中,人類專家根據(jù)領(lǐng)域知識(shí)和直覺手動(dòng)創(chuàng)建新特征。
另一種創(chuàng)建非線性模型的方法是使用神經(jīng)網(wǎng)絡(luò)。它們由相互連接的節(jié)點(diǎn)或"神經(jīng)元"層組成,每個(gè)節(jié)點(diǎn)對(duì)其輸入執(zhí)行簡(jiǎn)單的數(shù)學(xué)運(yùn)算,并將結(jié)果傳遞給下一層。
神經(jīng)網(wǎng)絡(luò)強(qiáng)大的關(guān)鍵在于能夠?qū)W習(xí)輸入和輸出之間復(fù)雜的非線性關(guān)系。這是通過(guò)在訓(xùn)練期間根據(jù)預(yù)測(cè)輸出和實(shí)際輸出之間的誤差調(diào)整神經(jīng)元之間連接的權(quán)重來(lái)實(shí)現(xiàn)的。
2.5 深度學(xué)習(xí)模型
深度學(xué)習(xí)的重點(diǎn)是通過(guò)多層結(jié)構(gòu)來(lái)學(xué)習(xí)數(shù)據(jù)的表示。近年來(lái),由于其在計(jì)算機(jī)視覺、自然語(yǔ)言處理和語(yǔ)音識(shí)別等應(yīng)用中的廣泛成功,變得越來(lái)越受歡迎。雖然深度學(xué)習(xí)模型有大量參數(shù)和層,實(shí)現(xiàn)相對(duì)復(fù)雜,但其特征工程也是其重要部分之一。
卷積神經(jīng)網(wǎng)絡(luò)(CNN,convolutional neural network)是深度學(xué)習(xí)模型的一個(gè)例子,其核心是對(duì)輸入圖像應(yīng)用一系列濾波器,每個(gè)濾波器尋找特定的特征,如邊緣或角,然后網(wǎng)絡(luò)的下一層使用這些提取的特征對(duì)輸入圖像進(jìn)行分類。
像CNN這樣的深度學(xué)習(xí)模型可以被認(rèn)為是特征工程和可訓(xùn)練模型的結(jié)合。該模型的特征工程涉及設(shè)計(jì)網(wǎng)絡(luò)架構(gòu)以從輸入數(shù)據(jù)中提取有用的特征,而可訓(xùn)練模型涉及優(yōu)化網(wǎng)絡(luò)參數(shù)以擬合數(shù)據(jù)并做出準(zhǔn)確的預(yù)測(cè)。
3. 模型訓(xùn)練/擬合
訓(xùn)練機(jī)器學(xué)習(xí)模型是通過(guò)向模型展示一組標(biāo)記的示例來(lái)教模型做出預(yù)測(cè)或決策的過(guò)程。標(biāo)記的示例,也稱為訓(xùn)練數(shù)據(jù),由成對(duì)的輸入特征和輸出標(biāo)簽組成。
在訓(xùn)練過(guò)程中,機(jī)器學(xué)習(xí)模型學(xué)習(xí)識(shí)別輸入特征及其對(duì)應(yīng)的輸出標(biāo)簽中的模式。該模型使用特定算法從訓(xùn)練數(shù)據(jù)中學(xué)習(xí)并調(diào)整其內(nèi)部參數(shù),以提高對(duì)新數(shù)據(jù)的預(yù)測(cè)或分類能力。
一旦模型在標(biāo)記的例子上進(jìn)行了訓(xùn)練,就可以用來(lái)對(duì)新的、沒見過(guò)的數(shù)據(jù)進(jìn)行預(yù)測(cè)或決策,這個(gè)過(guò)程被稱為推理或測(cè)試。
不同的機(jī)器學(xué)習(xí)模型有不同的訓(xùn)練算法,以下是不同機(jī)器學(xué)習(xí)模型使用的訓(xùn)練算法的一些示例。
3.1 基于距離的模型訓(xùn)練
KNN是一種不需要顯式訓(xùn)練的非參數(shù)算法。它存儲(chǔ)整個(gè)訓(xùn)練數(shù)據(jù)集,并用來(lái)預(yù)測(cè)新實(shí)例的標(biāo)簽,方法是根據(jù)一些距離度量在訓(xùn)練數(shù)據(jù)集中找到K個(gè)最接近的實(shí)例,然后根據(jù)K個(gè)最近鄰居的多數(shù)投票進(jìn)行預(yù)測(cè)。
LDA是一種用于分類任務(wù)的監(jiān)督學(xué)習(xí)算法。LDA對(duì)每個(gè)類的輸入特征的分布進(jìn)行建模,并用該信息找到輸入特征的線性組合,使類之間的分離最大化。得到的線性判別式可以用來(lái)對(duì)新實(shí)例進(jìn)行分類。
LDA的訓(xùn)練過(guò)程包括估計(jì)每個(gè)類別的輸入特征的均值和協(xié)方差矩陣,然后用這些估值來(lái)計(jì)算類內(nèi)和類間散點(diǎn)矩陣,這些散點(diǎn)矩陣用于導(dǎo)出線性判別式,線性判別式的數(shù)量等于類的數(shù)量減一。
3.2 基于決策樹的模型訓(xùn)練
至于決策樹,通常用一種稱為遞歸劃分的方法進(jìn)行訓(xùn)練。
遞歸分區(qū)從整個(gè)數(shù)據(jù)集開始,自上而下根據(jù)一組規(guī)則或條件將其分成子集。在每個(gè)子集上遞歸重復(fù)分割過(guò)程,直到滿足停止條件(通常是當(dāng)子集變得太小或進(jìn)一步分割無(wú)法提高模型性能時(shí))。
分割規(guī)則基于數(shù)據(jù)集特征或?qū)傩裕惴ㄔ诿恳徊街羞x擇對(duì)模型性能改善最顯著的特征。分割過(guò)程產(chǎn)生一個(gè)樹狀結(jié)構(gòu),其中內(nèi)部節(jié)點(diǎn)表示分割條件,葉節(jié)點(diǎn)表示最終預(yù)測(cè)。
在訓(xùn)練過(guò)程中,可以使用各種度量來(lái)評(píng)估決策樹,例如信息增益或基尼雜質(zhì)(Gini impurity),以確定最佳分割標(biāo)準(zhǔn)。一旦訓(xùn)練好決策樹,就可以根據(jù)輸入特征從根節(jié)點(diǎn)找到適當(dāng)?shù)娜~節(jié)點(diǎn)路徑,對(duì)新的、未知的數(shù)據(jù)進(jìn)行預(yù)測(cè)。
3.3 基于數(shù)學(xué)函數(shù)的模型訓(xùn)練
基于數(shù)學(xué)函數(shù)的模型,也稱為參數(shù)模型,是為輸入和輸出之間的關(guān)系假設(shè)特定函數(shù)形式的模型。
用于優(yōu)化基于數(shù)學(xué)函數(shù)的模型參數(shù)的最基本算法是梯度下降(gradient descent)。梯度下降是一種迭代優(yōu)化算法,它首先對(duì)參數(shù)值進(jìn)行初始猜測(cè),然后根據(jù)損失函數(shù)相對(duì)于參數(shù)的梯度對(duì)參數(shù)值進(jìn)行更新,持續(xù)這一過(guò)程直到算法收斂到損失函數(shù)最小為止。
對(duì)于非凸函數(shù)(non-convex functions),通常用隨機(jī)梯度下降(SGD, stochastic gradient descent)來(lái)代替梯度下降,SGD在每次迭代時(shí)隨機(jī)抽取一個(gè)數(shù)據(jù)子集來(lái)計(jì)算梯度,這種方法比梯度下降算法更快、更有效。
在神經(jīng)網(wǎng)絡(luò)中,反向傳播(backpropagation)用于計(jì)算損失函數(shù)相對(duì)于參數(shù)的梯度。反向傳播本質(zhì)上就是將微積分的鏈?zhǔn)椒▌t應(yīng)用于由神經(jīng)網(wǎng)絡(luò)表示的復(fù)合函數(shù),可以有效計(jì)算網(wǎng)絡(luò)每層的梯度,對(duì)于訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)必不可少。
對(duì)于深度學(xué)習(xí)模型,通常使用更高級(jí)的優(yōu)化技術(shù)來(lái)提高性能,包括動(dòng)量(momentum)和自適應(yīng)學(xué)習(xí)率(adaptive learning rate)等技術(shù),動(dòng)量可以幫助算法避免陷入局部最小值,自適應(yīng)學(xué)習(xí)率可以在訓(xùn)練過(guò)程中自動(dòng)調(diào)整學(xué)習(xí)率,以提高收斂速度和穩(wěn)定性。
綜上所述,梯度下降是優(yōu)化函數(shù)模型參數(shù)的基本算法。對(duì)于非凸函數(shù),通常使用隨機(jī)梯度下降法。反向傳播用于計(jì)算神經(jīng)網(wǎng)絡(luò)中的梯度,此外還有其他更高級(jí)的技術(shù)用于深度學(xué)習(xí)模型。
4. 模型優(yōu)化
機(jī)器學(xué)習(xí)的第三個(gè)方面包括通過(guò)使用網(wǎng)格搜索來(lái)優(yōu)化模型的超參數(shù)(hyperparameters)。超參數(shù)是模型的設(shè)置或配置,這些設(shè)置或配置不是在訓(xùn)練過(guò)程中學(xué)習(xí)到的,而必須手動(dòng)指定。
超參數(shù)的例子包括學(xué)習(xí)率、神經(jīng)網(wǎng)絡(luò)中隱藏層的數(shù)量以及正則化強(qiáng)度等,通過(guò)使用網(wǎng)格搜索,評(píng)估多個(gè)超參數(shù)組合,從而可以確定模型的最佳配置。
網(wǎng)格搜索是一種用于優(yōu)化機(jī)器學(xué)習(xí)模型超參數(shù)的常用技術(shù)。然而,這并不是唯一可用的方法,還有其他幾種可用于微調(diào)模型參數(shù)的替代方法,一些最流行的替代方案包括:
- 隨機(jī)網(wǎng)格搜索:與網(wǎng)格搜索相比,隨機(jī)搜索涉及從預(yù)定義范圍內(nèi)隨機(jī)采樣超參數(shù),從而更有效的探索參數(shù)空間。
- 貝葉斯優(yōu)化:貝葉斯優(yōu)化利用概率模型,通過(guò)迭代評(píng)估模型性能,更新超參數(shù)的概率分布,找到超參數(shù)的最優(yōu)集合。
- 遺傳算法:遺傳算法模擬自然選擇過(guò)程,通過(guò)產(chǎn)生一組潛在的解決方案,評(píng)估其性能,并選擇最適合的個(gè)體進(jìn)行繁殖,從而找到最優(yōu)的超參數(shù)集。
- 基于梯度的優(yōu)化:基于梯度的優(yōu)化涉及使用梯度迭代調(diào)整超參數(shù),目的是最大化模型性能。
- 基于集成的優(yōu)化:基于集成的優(yōu)化涉及將具有不同超參數(shù)的多個(gè)模型組合在一起,以創(chuàng)建更具魯棒性和更準(zhǔn)確的最終模型。
每種替代方法都有其優(yōu)缺點(diǎn),需要根據(jù)所處理的特定問(wèn)題、參數(shù)空間大小和可用計(jì)算資源選擇最佳方法。
5. 高效學(xué)習(xí)機(jī)器學(xué)習(xí)的幾個(gè)技巧
現(xiàn)在我們對(duì)機(jī)器學(xué)習(xí)算法的不同類別有了大致了解,接下來(lái)探索一下為了創(chuàng)建有效的預(yù)測(cè)模型,需要學(xué)習(xí)什么。
5.1 算法太難學(xué)?
如果我們從一些乍一看可能很復(fù)雜的算法開始,就會(huì)覺得機(jī)器學(xué)習(xí)是個(gè)具有挑戰(zhàn)性的領(lǐng)域。然而,通過(guò)將該過(guò)程分解為三個(gè)階段(建模、擬合和調(diào)優(yōu)),就能夠獲得更清晰的理解。
例如,學(xué)習(xí)支持向量機(jī)(SVM)對(duì)于數(shù)據(jù)科學(xué)家來(lái)說(shuō)可能令人生畏,因?yàn)橛写罅康募夹g(shù)術(shù)語(yǔ),如最優(yōu)超平面(optimal hyperplane)、無(wú)約束最小化(unconstrained minimization)、對(duì)偶性(原始和對(duì)偶形式)、拉格朗日乘子(Lagrange multipliers)、Karush-Kuhn-Tucker條件、二次規(guī)劃等等。然而,有必要將SVM只是理解為一個(gè)線性模型,和OLS回歸類似,方程為y = wX + b。
雖然上面提到的各種技術(shù)可以被用來(lái)優(yōu)化SVM,但重要的是不要陷入技術(shù)問(wèn)題的泥潭,而是要關(guān)注SVM作為線性模型的基本概念。
5.2 了解模型
我們已經(jīng)討論了三種類型的機(jī)器學(xué)習(xí)算法——模型、擬合算法和調(diào)優(yōu)算法。在我看來(lái),對(duì)于數(shù)據(jù)科學(xué)家來(lái)說(shuō),重要的是將理解模型置于其他兩個(gè)步驟之上。
從這個(gè)角度來(lái)看,將機(jī)器學(xué)習(xí)模型分為三種主要類型,從而有助于理解其功能:
基于距離的模型:在這種類型中,KNN不是一個(gè)合適的模型,因?yàn)樾聰?shù)據(jù)的距離是直接計(jì)算的,而在LDA或QDA中,是基于分布距離計(jì)算。
基于決策樹的模型:決策樹遵循if-else規(guī)則,形成一組可用于決策的規(guī)則。
基于數(shù)學(xué)函數(shù)的模型:可能不太容易理解,然而函數(shù)通常都很簡(jiǎn)單。
一旦對(duì)模型如何工作有了堅(jiān)實(shí)的理解,就可以使用預(yù)先存在的包來(lái)進(jìn)行擬合和調(diào)優(yōu):對(duì)于擬合,流行的scikit-learn庫(kù)提供了model.fit方法。而對(duì)于調(diào)優(yōu),像Optuna這樣的工具通過(guò)study.optimize提供了高效的學(xué)習(xí)優(yōu)化技術(shù)。通過(guò)專注于理解模型本身,數(shù)據(jù)科學(xué)家可以更好地為自己在該領(lǐng)域的成功做好準(zhǔn)備。
對(duì)于一些獨(dú)立模型,如果采用這種方法,可以提升對(duì)其的理解,這里有一些例子:
- 多項(xiàng)式回歸是對(duì)特征進(jìn)行不同次冪變換后的線性回歸。
- 線性回歸、ridge、LASSO和SVR是相同的模型,只是底層代價(jià)函數(shù)不同。
- 線性回歸、邏輯回歸和支持向量機(jī)是同一模型,只是底層代價(jià)函數(shù)不同。你可能會(huì)注意到線性回歸是回歸量而邏輯回歸和支持向量機(jī)是分類器,請(qǐng)閱讀SGDClassifier的文檔或查看關(guān)于SGDClassifier的這篇文章[2]。
10個(gè)最常見但最令人困惑的機(jī)器學(xué)習(xí)模型名稱說(shuō)明[3]這篇文章說(shuō)明理解模型并不總是直截了當(dāng)?shù)摹?/p>
5.3 模型可視化
在理解模型時(shí),可視化是一個(gè)非常有用的工具。當(dāng)使用機(jī)器學(xué)習(xí)模型時(shí),使用簡(jiǎn)單的數(shù)據(jù)集創(chuàng)建可視化可以幫助說(shuō)明模型是如何創(chuàng)建以及如何工作的。
下面一些文章涵蓋的主題包括線性回歸的可視化,也可以應(yīng)用于ridge、lasso、SVM以及神經(jīng)網(wǎng)絡(luò)。
另一種方法是在Excel中實(shí)現(xiàn)模型,因?yàn)樗梢蕴峁┮环N可視化的方式來(lái)查看數(shù)據(jù)和模型的輸出。
- Visualization of linear regression[4]
- Visualization of neural networks[5]
- Visualization of Decision Tree Regressors[6]
- Nearest Neighbors Regressors — A Visual Guide[7]
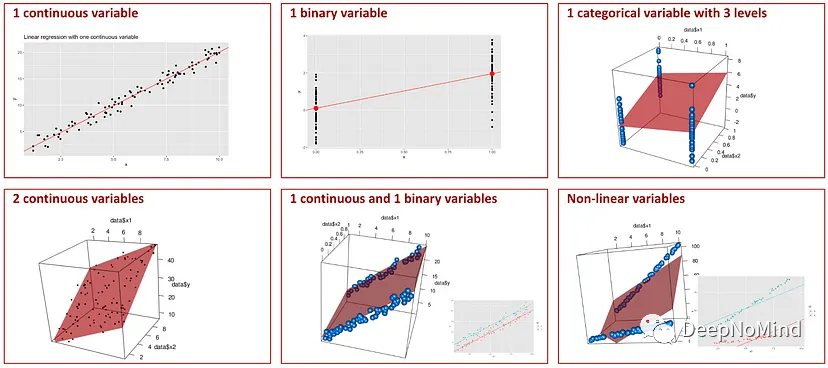 線性回歸的可視化
線性回歸的可視化
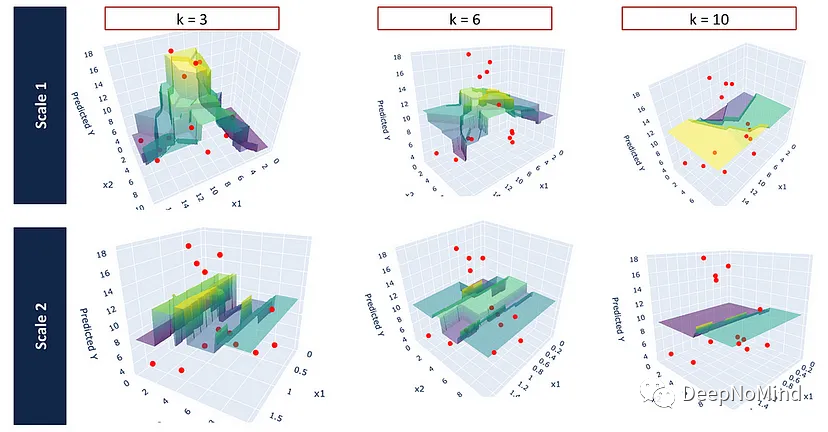
不同特征尺度的KNN回歸器
5.4 使用Excel了解擬合過(guò)程
一開始,了解擬合過(guò)程可能會(huì)讓人望而生畏。但是,如果想要學(xué)習(xí),那么首先要對(duì)模型的工作原理有一個(gè)堅(jiān)實(shí)的理解。在這方面,一個(gè)特別有用的工具是微軟Excel。
Excel是一個(gè)廣泛使用的電子表格程序,可用于可視化和操作數(shù)據(jù)。在機(jī)器學(xué)習(xí)領(lǐng)域,可以用來(lái)演示擬合過(guò)程是如何工作的簡(jiǎn)單模型(如線性回歸)。通過(guò)使用Excel,可以看到這個(gè)算法是如何一步步實(shí)現(xiàn)的。
要記住,雖然Excel可以是一種理解簡(jiǎn)單數(shù)據(jù)集的擬合過(guò)程的有效方法,但并不是機(jī)器學(xué)習(xí)最有效工具。
用Excel來(lái)理解擬合過(guò)程對(duì)于機(jī)器學(xué)習(xí)初學(xué)者來(lái)說(shuō)是一個(gè)有用的工具,它提供了一種簡(jiǎn)單易用的方法來(lái)可視化算法并了解它們是如何工作的。
下面是幾篇關(guān)于線性回歸、邏輯回歸和神經(jīng)網(wǎng)絡(luò)梯度下降的文章。
- K-Nearest neighbors in Excel[8]
- Linear Regression With Gradient Descent in Excel[9]
- Logistic Regression With Gradient Descent in Excel[10]
- Neural Network Classifier from Scratch in Excel[11]
- Decision Tree Regressors in Excel[12]
- Implementing KNN in Excel[13]
- K-means from Scratch in Excel[14]
- Neural Network with Backpropagation in Excel[15]

基于Excel的機(jī)器學(xué)習(xí)算法
5.5 使用簡(jiǎn)單數(shù)據(jù)集進(jìn)行測(cè)試
為了全面理解機(jī)器學(xué)習(xí)算法,從頭開始實(shí)現(xiàn)可能是一種有效方法,然而這種方法可能相當(dāng)耗時(shí),并且可能需要高水平的技術(shù)熟練度。另一種方法是使用預(yù)先訓(xùn)練好的包或庫(kù)來(lái)使用簡(jiǎn)單的數(shù)據(jù)集創(chuàng)建和可視化模型的輸出。
通過(guò)這些包,可以輕松試驗(yàn)不同參數(shù)并測(cè)試各種機(jī)器學(xué)習(xí)算法。這種方法可以幫助我們了解算法的內(nèi)部工作原理,同時(shí)也使我們能夠快速評(píng)估在特定數(shù)據(jù)集上的有效性。
通過(guò)使用這樣的數(shù)據(jù)集,可以很容易可視化模型的輸入和輸出。反過(guò)來(lái),也可以讓我們更深入了解模型是如何進(jìn)行預(yù)測(cè)的。此外,通過(guò)改變模型的超參數(shù)和其他方面,還可以可視化這些變化對(duì)模型預(yù)測(cè)的影響。
這種方法可以幫助初學(xué)者開始機(jī)器學(xué)習(xí),并更好地理解不同算法的工作原理。這是一種獲得實(shí)踐經(jīng)驗(yàn)和試驗(yàn)不同模型的極好方法,而無(wú)需在實(shí)現(xiàn)上花費(fèi)太多時(shí)間。
6. 結(jié)論
總之,機(jī)器學(xué)習(xí)是一個(gè)復(fù)雜的領(lǐng)域。然而,了解三種主要類型的機(jī)器學(xué)習(xí)算法(模型、擬合算法和調(diào)優(yōu)算法),并根據(jù)它們的目標(biāo)和復(fù)雜性進(jìn)行分類,可以幫助我們?nèi)媪私馄涔ぷ髟怼Mㄟ^(guò)優(yōu)先理解模型,將它們可視化,并在Excel等工具中實(shí)現(xiàn),可以揭開擬合和調(diào)優(yōu)過(guò)程的神秘面紗。
不斷學(xué)習(xí)機(jī)器學(xué)習(xí)的不同方面至關(guān)重要,例如分類與回歸、處理缺失值和變量權(quán)重,以不斷加深對(duì)該領(lǐng)域的理解。如果想了解更多,請(qǐng)查看這篇文章:監(jiān)督機(jī)器學(xué)習(xí)算法概述[16]。
你好,我是俞凡,在Motorola做過(guò)研發(fā),現(xiàn)在在Mavenir做技術(shù)工作,對(duì)通信、網(wǎng)絡(luò)、后端架構(gòu)、云原生、DevOps、CICD、區(qū)塊鏈、AI等技術(shù)始終保持著濃厚的興趣,平時(shí)喜歡閱讀、思考,相信持續(xù)學(xué)習(xí)、終身成長(zhǎng),歡迎一起交流學(xué)習(xí)。
微信公眾號(hào):DeepNoMind
-
人工智能
+關(guān)注
關(guān)注
1817文章
50098瀏覽量
265363 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8553瀏覽量
136948
發(fā)布評(píng)論請(qǐng)先 登錄
TPS25924x eFuse:高效電路保護(hù)與電源管理解決方案
TPS2595xx eFuse:高效電路保護(hù)與電源管理解決方案
MAX77659:低功耗應(yīng)用的高效電源管理解決方案
MAX14720:緊湊高效的電源管理解決方案
人工智能與機(jī)器學(xué)習(xí)在這些行業(yè)的深度應(yīng)用
機(jī)器學(xué)習(xí)和深度學(xué)習(xí)中需避免的 7 個(gè)常見錯(cuò)誤與局限性

兆芯攜手合作伙伴打造高效智能視頻管理解決方案
如何在機(jī)器視覺中部署深度學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)

再掀語(yǔ)音交互革命,廣和通AI解決方案加速機(jī)器人聽覺進(jìn)化
【「Yocto項(xiàng)目實(shí)戰(zhàn)教程:高效定制嵌入式Linux系統(tǒng)」閱讀體驗(yàn)】+基礎(chǔ)概念學(xué)習(xí)理解
FPGA在機(jī)器學(xué)習(xí)中的具體應(yīng)用
【「# ROS 2智能機(jī)器人開發(fā)實(shí)踐」閱讀體驗(yàn)】視覺實(shí)現(xiàn)的基礎(chǔ)算法的應(yīng)用
面向AI與機(jī)器學(xué)習(xí)應(yīng)用的開發(fā)平臺(tái) AMD/Xilinx Versal? AI Edge VEK280



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論