") LLM底座模型:LLaMA、Palm、GLM、BLOOM、GPT結(jié)構(gòu)對(duì)比
LLM底座模型:LLaMA、Palm、GLM、BLOOM、GPT結(jié)構(gòu)對(duì)比

1
LLama
[GPT3] 使用RMSNorm(即Root Mean square Layer Normalization)對(duì)輸入數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化,RMSNorm可以參考論文:Root mean square layer normalization。
[PaLM]使用激活函數(shù)SwiGLU, 該函數(shù)可以參考PALM論文:Glu variants improve transformer。
[GPTNeo]使用Rotary Embeddings進(jìn)行位置編碼,該編碼可以參考論文 Roformer: Enhanced transformer with rotary position embedding。
使用了AdamW優(yōu)化器,并使用cosine learning rate schedule,
使用因果多頭注意的有效實(shí)現(xiàn)來(lái)減少內(nèi)存使用和運(yùn)行時(shí)間。該實(shí)現(xiàn)可在xformers
2
Palm
采用SwiGLU激活函數(shù):用于 MLP 中間激活,采用SwiGLU激活函數(shù):用于 MLP 中間激活,因?yàn)榕c標(biāo)準(zhǔn) ReLU、GELU 或 Swish 激活相比,《GLU Variants Improve Transformer》論文里提到:SwiGLU 已被證明可以顯著提高模型效果
提出Parallel Layers:每個(gè) Transformer 結(jié)構(gòu)中的“并行”公式:與 GPT-J-6B 中一樣,使用的是標(biāo)準(zhǔn)“序列化”公式。并行公式使大規(guī)模訓(xùn)練速度提高了大約 15%。消融實(shí)驗(yàn)顯示在 8B 參數(shù)量下模型效果下降很小,但在 62B 參數(shù)量下沒(méi)有模型效果下降的現(xiàn)象。
Multi-Query Attention:每個(gè)頭共享鍵/值的映射,即“key”和“value”被投影到 [1, h],但“query”仍被投影到形狀 [k, h],這種操作對(duì)模型質(zhì)量和訓(xùn)練速度沒(méi)有影響,但在自回歸解碼時(shí)間上有效節(jié)省了成本。
使用RoPE embeddings:使用的不是絕對(duì)或相對(duì)位置嵌入,而是RoPE,是因?yàn)?RoPE 嵌入在長(zhǎng)文本上具有更好的性能 ,
采用Shared Input-Output Embeddings:輸入和輸出embedding矩陣是共享的,這個(gè)我理解類(lèi)似于word2vec的輸入W和輸出W':
3
GLM
Layer Normalization的順序和殘差連接被重新排列,
用于輸出標(biāo)記預(yù)測(cè)的單個(gè)線性層;
ReLU s替換為GELU s
二維位置編碼
4
BLOOM
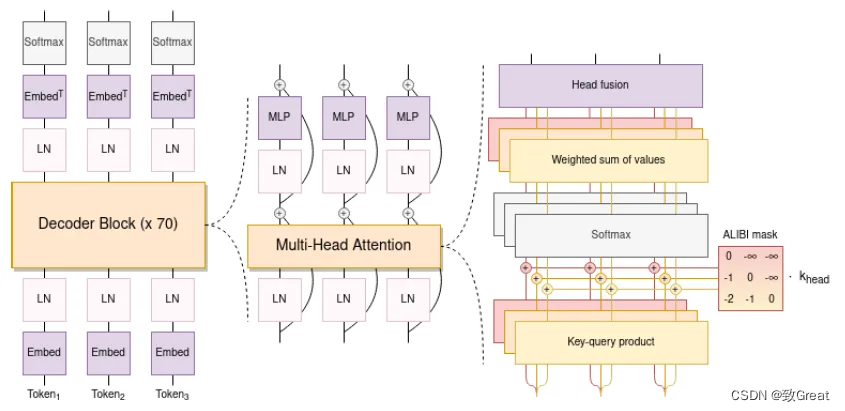
使用 ALiBi 位置嵌入,它根據(jù)鍵和查詢(xún)的距離直接衰減注意力分?jǐn)?shù)。與原始的 Transformer 和 Rotary 嵌入相比,它可以帶來(lái)更流暢的訓(xùn)練和更好的下游性能。ALiBi不會(huì)在詞嵌入中添加位置嵌入;相反,它會(huì)使用與其距離成比例的懲罰來(lái)偏向查詢(xún)鍵的注意力評(píng)分。
Embedding Layer Norm 在第一個(gè)嵌入層之后立即使用,以避免訓(xùn)練不穩(wěn)定。
使用了 25 萬(wàn)個(gè)標(biāo)記的詞匯表。使用字節(jié)級(jí) BPE。這樣,標(biāo)記化永遠(yuǎn)不會(huì)產(chǎn)生未知標(biāo)記
兩個(gè)全連接層: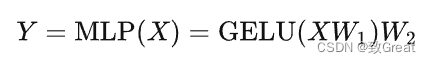
5
GPT
GPT 使用 Transformer 的 Decoder 結(jié)構(gòu),并對(duì) Transformer Decoder 進(jìn)行了一些改動(dòng),原本的 Decoder 包含了兩個(gè) Multi-Head Attention 結(jié)構(gòu),GPT 只保留了 Mask Multi-Head Attention,如下圖所示: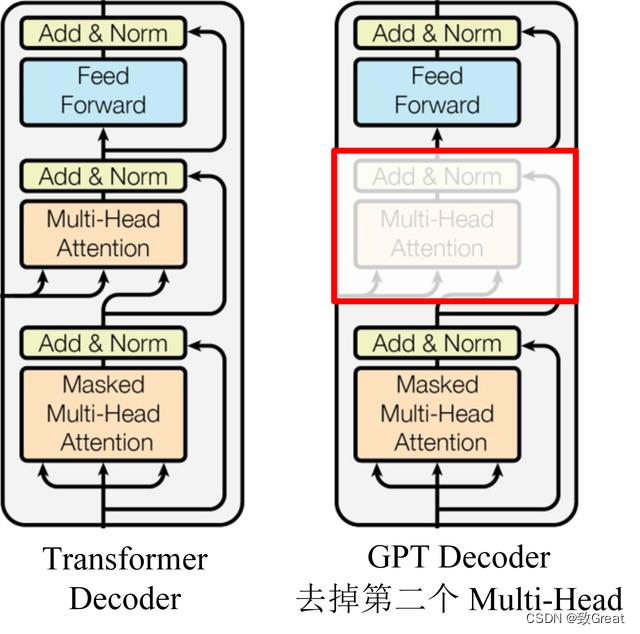
審核編輯:劉清
-
電源優(yōu)化器
+關(guān)注
關(guān)注
0文章
11瀏覽量
5522 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
16877 -
BPEKF算法
+關(guān)注
關(guān)注
0文章
2瀏覽量
1155 -
MLP
+關(guān)注
關(guān)注
0文章
57瀏覽量
4990 -
LLM
+關(guān)注
關(guān)注
1文章
346瀏覽量
1332
原文標(biāo)題:LLM底座模型:LLaMA、Palm、GLM、BLOOM、GPT結(jié)構(gòu)對(duì)比
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【飛騰派4G版免費(fèi)試用】仙女姐姐的嵌入式實(shí)驗(yàn)室之五~LLaMA.cpp及3B“小模型”O(jiān)penBuddy-StableLM-3B
【算能RADXA微服務(wù)器試用體驗(yàn)】+ GPT語(yǔ)音與視覺(jué)交互:1,LLM部署
無(wú)法在OVMS上運(yùn)行來(lái)自Meta的大型語(yǔ)言模型 (LLM),為什么?
各種大語(yǔ)言模型是徹底被解封了
號(hào)稱(chēng)「碾壓」LLaMA的Falcon實(shí)測(cè)得分僅49.08,HuggingFace決定重寫(xiě)排行榜代碼
Llama 2性能如何
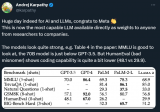
Meta推出Llama 2 免費(fèi)開(kāi)放商業(yè)和研究機(jī)構(gòu)使用
深入理解Llama模型的源碼案例

一文詳解GPT tokenizer 的工作原理




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論