 一顆Jericho3-AI芯片,用來替代InfiniBand?
一顆Jericho3-AI芯片,用來替代InfiniBand?

多樣性不僅是生活的調味品,也是推動創新和降低風險的方式。這就是為什么我們看到交換機架構不斷發展以驅動特定類型的 AI 工作負載,就像我們在過去兩年半的時間里看到的 HPC 模擬和建模工作負載一樣。
Hyperion Research:SC22 HPC Market Update(2022.11)
Hyperion Research:ISC22 Market Update(2022.5)
Intersect360全球HPC-AI市場報告(2022—2026)
在橫向擴展人工智能訓練的早期——也就是從 2010 年到現在——InfiniBand 是 HPC 模擬和建模的首選低延遲網絡之一,它崛起成為主要的網絡互連,將擠滿了 GPU 的節點粘合在一起。但許多 AI 初創公司,如 Cerebras Systems、SambaNova Systems、GraphCore 和英特爾的 Gaudi 都有自己的互連,谷歌也是如此,其光開關是其 TPUv4 矩陣數學巨頭的核心。如果你想大方一點,你可以說 Cray(現在是惠普企業的一部分)創建的以太網的 Slingshot 變體也是一種自定義互連,可以(并且將會)以百億億次級運行 AI 工作負載。
在推動人工智能革命的超大規模和云構建巨頭中,博通在交換和路由半導體領域占據主導市場份額,它希望在人工智能網絡行動中分得一杯羹。因此,該公司采用“Jericho”系列交換機和路由 ASIC 及其深度數據包緩沖區,并專門重新設計它們以承擔 AI 工作負載,最初的 Jericho3-AI 交換機芯片是該設計的第一個實例。通過這種設計,Broadcom 已經將 InfiniBand 牢牢地放在了自己的視線之內,而且絕對是在爭取它。
這意味著,除其他外,Broadcom 將讓 Arista Networks 和云構建者和超大規模應用者使用的白盒交換機制造商集體在其主場 AI 領域與 Nvidia 競爭,其中包括強大的 AI 軟件堆棧、GPU 以及即將推出的 CPU 和 GPU內存互連以及Nvidia 從三年前完成的 69 億美元收購中獲得的InfiniBand 網絡硬件和軟件。
借助 Jericho3-AI 芯片,Broadcom 正在重新設計深度緩沖 Jericho 芯片系列,這些芯片通常被超大規模用戶和云構建者用來執行路由和交換功能,并為它們提供通常用于集體操作的性能。AI 和 HPC 使它們在 AI 工作負載方面與 InfiniBand 具有絕對競爭力,并賦予它們標準以太網 ASIC 所不具備的功能,包括在各種規模的數據中心中常用的“Trident”和“Tomahawk”系列中的功能。
Jericho3-AI 芯片使用相同的“Peregrine”系列 SerDes 信號電路,該電路在2022 年 8 月發布的“Tomahawk5”葉/主干以太網交換機 ASIC中首次亮相。Broadcom Trident 和 Tomahawk 交換機產品線的產品線經理 Peter Del Vecchio 向我們介紹了 Jericho3-AI,他說 Tomahawk5 ASIC 于今年 3 月開始批量出貨,這意味著我們應該很快就會看到它出現在交換機中。
Tomahawk5 在某些方面是比 Jericho3-AI 更強大的設備,但它具有更適度的緩沖區,并且專為在這些超大規模和云構建者的 Clos 網絡中完成的架頂和葉交換而設計。Tomahawk5 采用臺灣半導體制造公司的 5 納米工藝實現,其中 512 個 Peregrine SerDes 以 100 Gb/秒的速度運行(通過信號的 PAM-4 調制啟用)包裹在數據包處理引擎和適度的緩沖區周圍以創建一個設備總帶寬為 51.2 Tb/秒。Jericho3-AI 芯片也采用 TSMC 的 5 納米工藝蝕刻,具有 304 個相同的 SerDes,其中 144 個分配給下行鏈路,其中 160 個延伸到網絡中更高層的 Ramon 3 結構元素,充當leaf 和spine開關。像這樣:
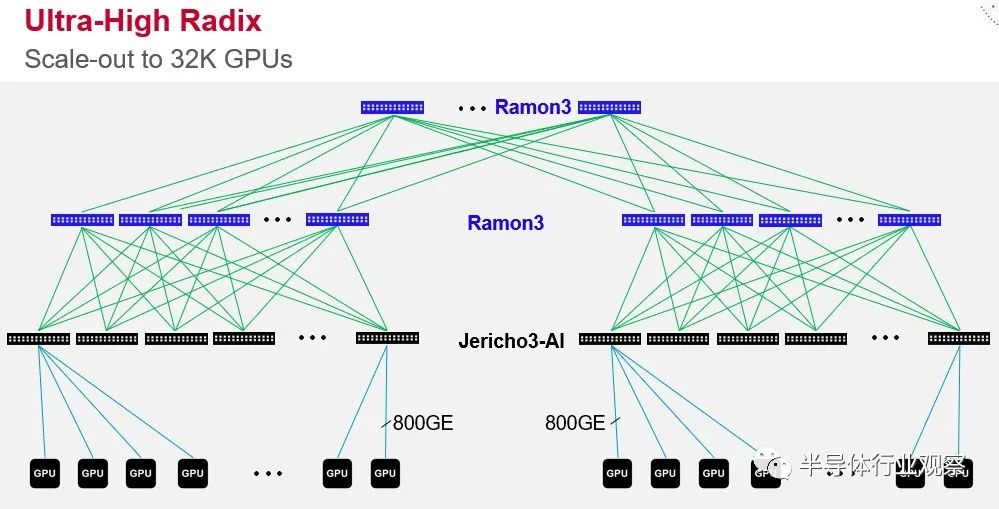
您會注意到圖中的交換機端口直接鏈接到 GPU,這不是錯誤。越來越多的架構將這樣做。為什么要通過服務器總線來鏈接 GPU?重要的是,Ramon 3 結構元素(本質上是spine互連)和 Jericho3-AI leaf或架頂式交換機的規模允許超過 32,000 個 GPU 在 Clos 拓撲中鏈接到一個龐大的 AI 訓練系統中,以 800 Gb/秒的速度運行的端口。不可否認,今天沒有服務器的端口運行速度超過 200 Gb/秒或 400 Gb/秒,因為適配卡還沒有以這些本機速度運行。在 2025 年時間框架內 PCI-Express 6.0 插槽在服務器中可用之前,這可能不會發生。
現在,當微軟為自己和它在 AI 框架中的合作伙伴 OpenAI 運行 GPT 訓練時,它使用標準的 HGX GPU 系統板綁定到服務器主機節點,并通過一個 400 Gb/秒的 ConnectX CX7 網絡接口相互鏈接,用于八 GPU 系統中的每個 GPU。微軟 Azure 在 InfiniBand 網絡上使用胖樹(fat tree)拓撲,就像許多 HPC 商店所做的那樣,并且還使用消息傳遞接口 (MPI) 協議來調度數據和計算,跨 4,000 個 GPU 鏈接到一個集群,以運行 GPT 和其他框架。作為單例。微軟將根據需要增加它,如果 Jericho3-AI 芯片為人工智能工作負載提供更好的性能和經濟性,那么微軟架構中的任何內容都不會阻止它遷移到基于 Broadcom Dune StrataDNX 系列的結構,其中 Jericho3 -AI和Ramon 3是一部分。
同上所有其他云和超大規模。
這是關于 Tomahawk5 和 Jericho3-A1 的巧妙之處,因為它們使用了 Peregrine SerDes。按照這些 SerDes 的設計方式,它們可以使用所謂的線性驅動光學器件直接驅動光學器件,這意味著 SerDes 可以直接與光學器件中的跨阻放大器對話,而無需在其前面安裝數字信號處理器。此外,Peregrine SerDes 可以將信號向下推送到 4 米直連銅 (DAC) 電纜——是 IEEE 規范電纜長度的兩倍——無需重定時器或中繼器。盡管此選項尚未商業化,但如果 Broadcom 的客戶希望進一步降低熱量、每比特成本和延遲,則可以使用 Peregrine SerDes 來驅動共同封裝的光學器件。

從技術上講,Jericho3-AI 芯片的額定速度為 14.4 Tb/秒,因為只有 144 個 SerDes 驅動下行鏈路,其余 160 個 SerDes,即 16 Tb/秒,不計入設備的官方吞吐量。芯片上可能有更多的物理SerDes,這是一個單片器件,不是由chiplet組成的,目的是在5納米器件上的反良率被屏蔽后,增加有效SerDes的數量。(這在當今所有復雜的半導體設備設計和制造中都很常見。)如果我們有 Jericho3-AI 的die照片,我們肯定會知道。。 . 。
Jericho3-AI 芯片專門設計用于在分布式模型中的每個計算步驟結束時執行集體操作(尤其是 all-to-all 或 all reduce 操作)時幫助處理網絡上的復雜流。這些功能在大型語言模型和推薦系統中至關重要,它們具有非常不同的特征并且需要稍微不同的硬件(這就是為什么“Hopper”GPU 需要緊密耦合的“Grace”CPU 用于未來專注于推薦系統的 Nvidia 系統) 。
Meta Platforms 基礎設施副總裁 Alexis Bjorlin在去年 10 月的開放計算項目峰會上的主題演講中談到了其“Grand Teton”AI 系統和配套“Grand Canyon”存儲陣列的設計,而我們并不知道她分享了下圖涉及四種不同的機器學習模型,這些模型是Meta Platforms 使用的深度學習推薦模型 (DLRM) 推薦系統的一部分,該系統于 2019 年 7 月開源:
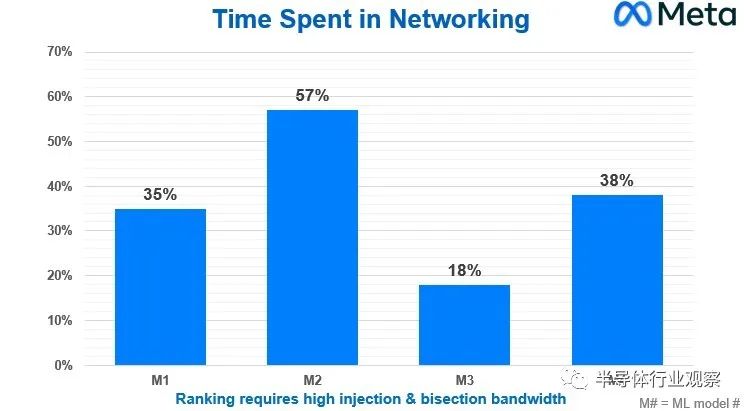
此圖表顯示的是在下一個計算步驟開始之前等待集體操作在網絡上運行所浪費的 CPU 時間百分比。它是掛鐘時間減去計算時間除以掛鐘時間,得到網絡時間。
現在,這些龐大的 AI 集群中的單個節點成本可能為 400,000 到 500,000 美元,根據模型的不同,有 18%、35%、38% 或 57% 的時間都在那里,這確實是一個非常昂貴的提議。 通過針對 AI 工作負載優化的網絡,集體操作的網絡效率的任何變化都意味著 CPU-GPU 硬件投資不會按比例浪費。
為了解 Jericho3-AI 如何與 InfiniBand 競爭,Broadcom 與其中一家超大規模廠商合作,更換了連接 GPU 加速計算節點的 200 Gb/秒 InfiniBand 交換機,并將該 InfiniBand 交換機替換為以太網交換機。這兩款交換機都運行 Nvidia 集體通信庫 (NCCL),這是一種由 Nvidia 創建的集體操作網絡軟件驅動程序,旨在為密集的 GPU 分組提供比在 CPU 內核或插槽上運行普通 MPI 更好的集體操作性能。NCCL 是拓撲感知的,這意味著它知道計算節點內的快速和fat NVLink 管道與跨節點的 InfiniBand 或以太網管道之間的區別。這些不是非此即彼的命題,NCCL 和 MPI 經常一起使用。
以下是在支持 InfiniBand 或以太網協議的 ConnectX-6 SmartNIC 上具有多達 16 個 200 Gb/秒端口的服務器與基于 Nvidia 的 Quantum 2 ASIC 或 Broadcom 的 Jericho3-AI ASIC 的交換機之間的性能差異:
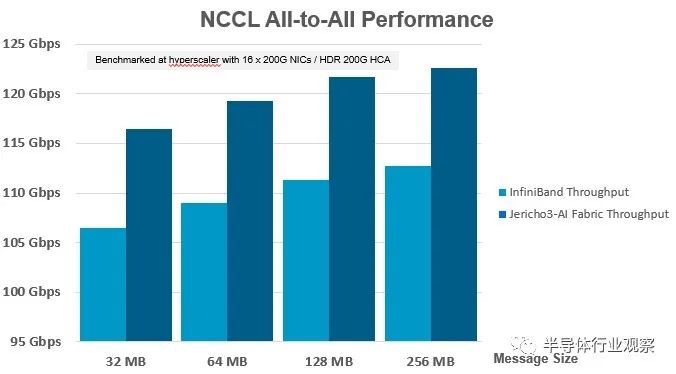
您必須仔細觀察 Y 軸,因為兩個交換機的整體集體操作性能不是從 0 Gb/秒到 125 Gb/秒,而是從 95 Gb/秒到 125 Gb/秒,這意味著此圖表中的性能增量在視覺上比實際大。結果是,幾乎無論消息大小如何,Jericho3-AI 芯片提供的吞吐量比運行相同 AI 訓練工作負載的 InfiniBand 交換機高出約 10%。
現在,如果您查看 Meta Platforms 提供的圖表,10% 是一個大問題。任何能提高網絡有效加速的東西都會縮短集體操作的掛鐘時間。Del Vecchio 告訴The Next Platform,Jericho3-AI switch 的性能提速對于所有 reduce 集體操作也有大約 10%(但我們沒有這方面的圖表)。這意味著完成 AI 訓練運行的時間也將縮短,如果時間就是金錢——通常是在涉及 AI 和 HPC 工作負載時——那么可以同時訓練更多模型。再加上節能和更長的 DAC,Broadcom 將在 AI 培訓方面擁有令人信服的價值主張,以與 InfiniBand 競爭。
Broadcom 如何為 InfiniBand 帶來熱度?Jericho3-AI 芯片有一些功能名稱看起來非常奇特,但歸根結底是更好的負載平衡和擁塞控制,可以減少網絡爭用并改善網絡延遲,坦率地說,這比降低延遲更重要在交換機內部端口到端口的跳躍上,與基于 ASIC(如 Tridents 和 Tomahawks)的傳統數據中心級以太網交換機及其來自 Cisco Systems 的競爭產品相比,InfiniBand 具有巨大的優勢——大約 3 到 4 倍或更多(那是我們說的,不是 Broadcom。但這是真的。)
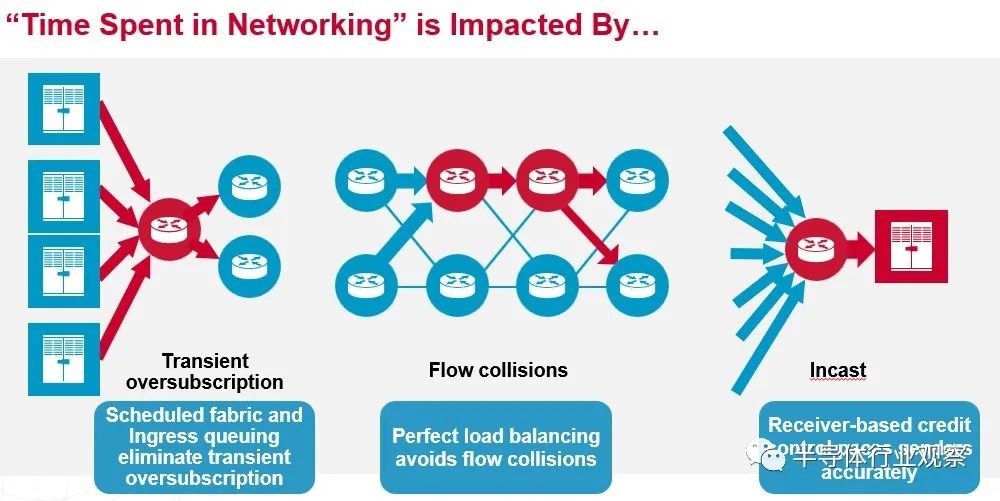
Jericho3-AI 芯片的兩個重要特性就是 Broadcom 夸張地稱之為完美的負載平衡和無擁塞操作。這是一張從概念上顯示它們如何協同工作的圖片:
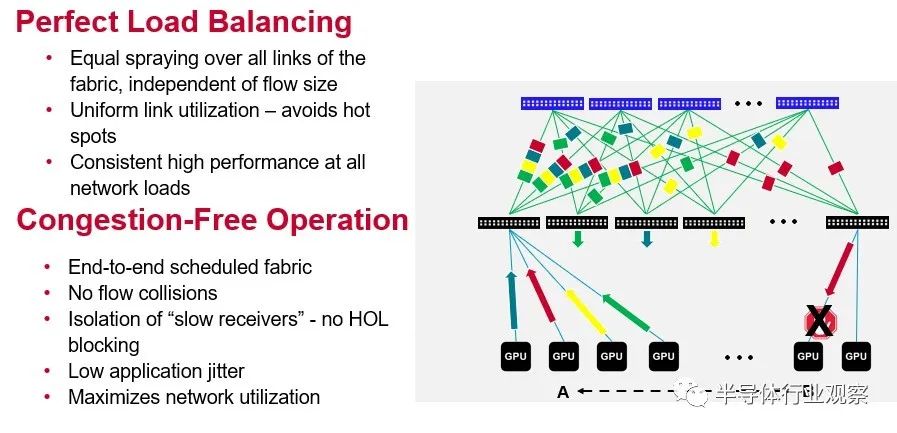
我們高度懷疑任何負載平衡是否“完美”或網絡操作是否可以“無擁塞”,但顯然,根據 Broadcom 展示的結果,Jericho3-AI 在 AI 訓練工作負載方面將比 Tomahawk 做得更好或 Trident ASIC 可以并且基于這組有限的性能數據,應該讓 InfiniBand 與 AI 訓練資金競爭。
我們的問題是:Jericho3-AI 芯片是否會像 InfiniBand 那樣幫助處理傳統的 HPC 模擬和建模工作負載?
“這取決于 HPC 的類型,”Del Vecchio 說。“但如果吞吐量對應用程序很重要,那當然是肯定的。HPC 應用程序也將獲得這些好處,您最終將獲得無擁塞操作、非常好的負載平衡以及更有效地利用鏈接。與 HPC 相比,AI 更傾向于關注整個網絡的原始吞吐量,后者才是最重要的端到端延遲。HPC 有很多非常短的消息,因此消息速率非常關鍵。所以有一些不同。但關鍵是要確保負載平衡,如果沒有擁塞——這些將同樣適用于 AI 和 HPC。”
Jericho3-AI 開關芯片現在正在出樣,預計會像 Tomahawk5 那樣有相對較快的提升。
審核編輯 :李倩
-
芯片
+關注
關注
463文章
54010瀏覽量
466104 -
gpu
+關注
關注
28文章
5194瀏覽量
135461 -
網絡硬件
+關注
關注
0文章
10瀏覽量
6356
原文標題:一顆Jericho3-AI芯片,用來替代InfiniBand?
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
小鵬自研芯片成了!G7首秀:搭載3顆圖靈AI芯片 L3級算力一顆頂3顆

如何用一顆低成本Flash語音芯片,同時實現高性能與設計自由?WTN6 F系列給出答案

浮思特 | 一顆芯片搞定多點觸控,敦泰 FT7311 電容觸控方案解析
深度解析國產電機驅動IC,一顆可替代DRV8813的雙通道集成電機驅動器

如何用一顆芯片搞定語音、顯示與傳感?解碼唯創高集成語音IC方案

為何一顆TMC5160芯片,就能解決電機驅動中的噪聲、振動與精度等問題?

一顆芯片賣爆了是什么感覺

MPN12AD160-MQ:替代ADI/TI/TOREX電源芯片
長晶接口電路CJLSF0102系列一顆料同時替代TI與安世

一顆優質的音頻功放芯片硬核素質有哪些?優質音頻功放芯片的全維度評估框架
一顆快充芯片給我的6個啟發:從規格書里讀懂精妙設計

博通新品Jericho4路由器,36000端口/3.2Tbps,突破AI計算瓶頸
3-16串一顆芯片搞定 全解AMG8816全集成BMS主控的參數真相

寒武紀思元370芯片參數特性詳解
如何用一顆SOP8芯片實現色溫+亮度精準控制?



 工商網監
工商網監
評論