 中文對話式大語言模型Firefly-2b6開源,使用210萬訓練數據
中文對話式大語言模型Firefly-2b6開源,使用210萬訓練數據

在文章Firefly(流螢): 中文對話式大語言模型中,我們介紹了關于Firefly(流螢)項目的工作,并且分享了我們訓練的firefly-1b4模型。這是Firefly項目開源的第一個模型,雖然取得了還不錯的效果,但無論是訓練數據還是模型參數量,都還有很大的優化空間。
所以,在firefly-1b4實驗的基礎上,我們對訓練數據進行清洗,并且增加了數據量,得到210萬數據,并用它訓練得到了firefly-2b6模型。
在本文中,我們將對該模型進行分享和介紹。與firefly-1b4相比,firefly-2b6的代碼生成能力取得了較大的進步,并且在古詩詞生成、對聯、作文、開放域生成等方面也有不錯的提升。
firefly-1b4和firefly-2b6的訓練配置如下表所示。無論是訓練數據量,還是訓練步數,firefly-2b6都更加充分。
| 參數 | firefly-1b4 | firefly-2b6 |
| batch size | 16 | 8 |
| learning rate | 3e-5 | 3e-5 |
| warmup step | 3000 | 3000 |
| lr schedule | cosine | cosine |
| max length | 512 | 512 |
| training step | 90k | 260k |
| 訓練集規模 | 160萬 | 210萬 |
項目地址:
https://github.com/yangjianxin1/Firefly
模型權重鏈接見文末。
模型使用
使用如下代碼即可使用模型:
from transformers import BloomTokenizerFast, BloomForCausalLM
device = 'cuda'
path = 'YeungNLP/firefly-2b6'
tokenizer = BloomTokenizerFast.from_pretrained(path)
model = BloomForCausalLM.from_pretrained(path)
model.eval()
model = model.to(device)
text = input('User:')
while True:
text = '{}'.format(text)
input_ids = tokenizer(text, return_tensors="pt").input_ids
input_ids = input_ids.to(device)
outputs=model.generate(input_ids,max_new_tokens=250,do_sample=True,top_p=0.7,temperature=0.35,
repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id)
rets = tokenizer.batch_decode(outputs)
output = rets[0].strip().replace(text, "").replace('', "")
print("Firefly:{}".format(output))
text = input('User:')
代碼生成
盡管在訓練集中,代碼的數據量不多,但令人驚喜的是,firefly-2b6已經具備一定的代碼生成能力。
在筆者的實測中,對于一些編程題,firefly-2b6生成的代碼可以做到無需修改,直接運行成功,并且得到正確的答案。下面將展示一些編程題的生成例子。
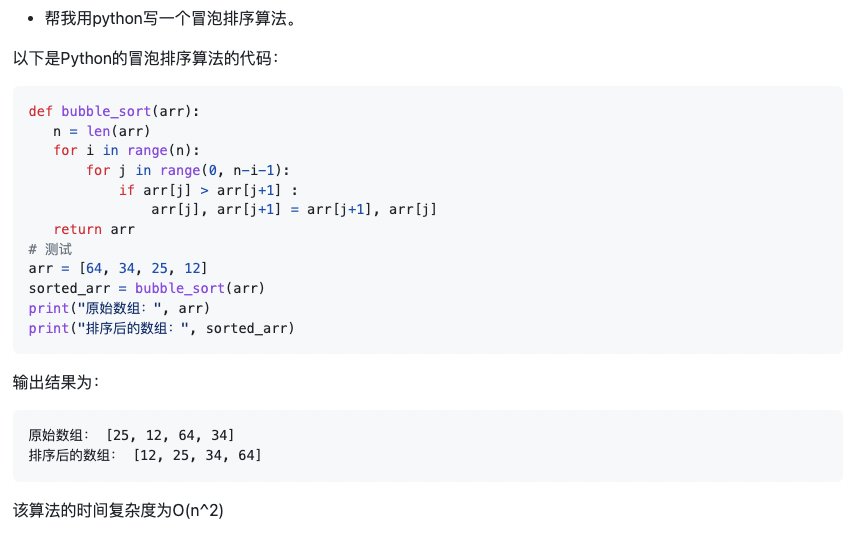
示例2:用python實現一個快速排序算法,輸入為一個數組,返回排序好之后的數組。

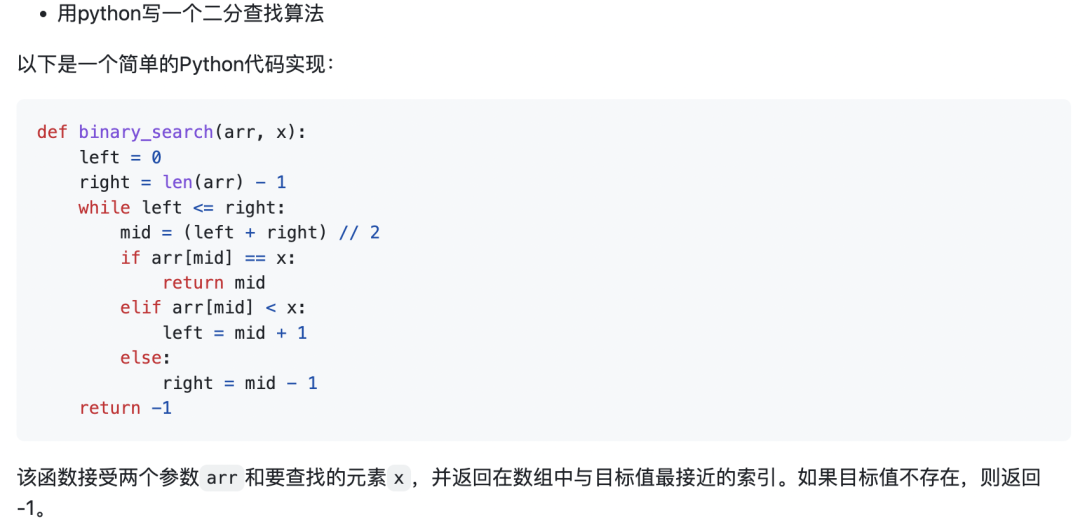
示例3:用python寫一個二分查找算法。
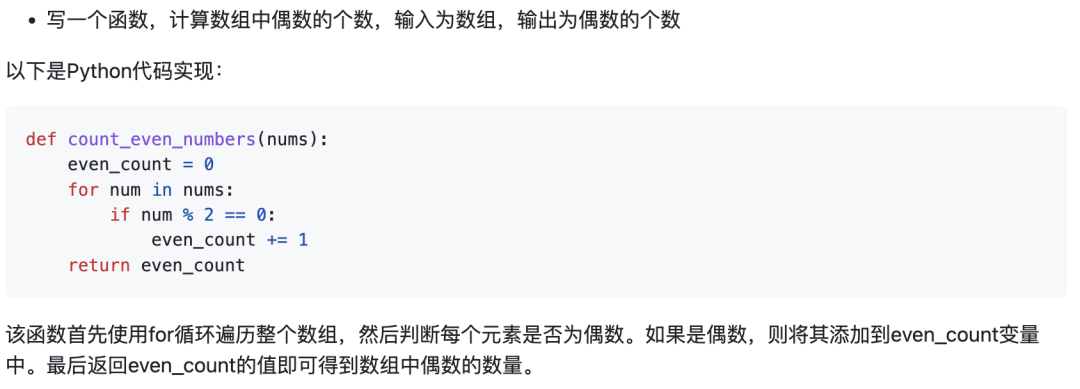
示例4:寫一個函數,計算數組中偶數的個數,輸入為數組,輸出為偶數的個數。
示例5:用html生成一個教務管理系統的登錄界面,要求包含用戶名、密碼輸入框和登錄按鈕。

該html代碼在瀏覽器中的效果如下圖:

其他樣例
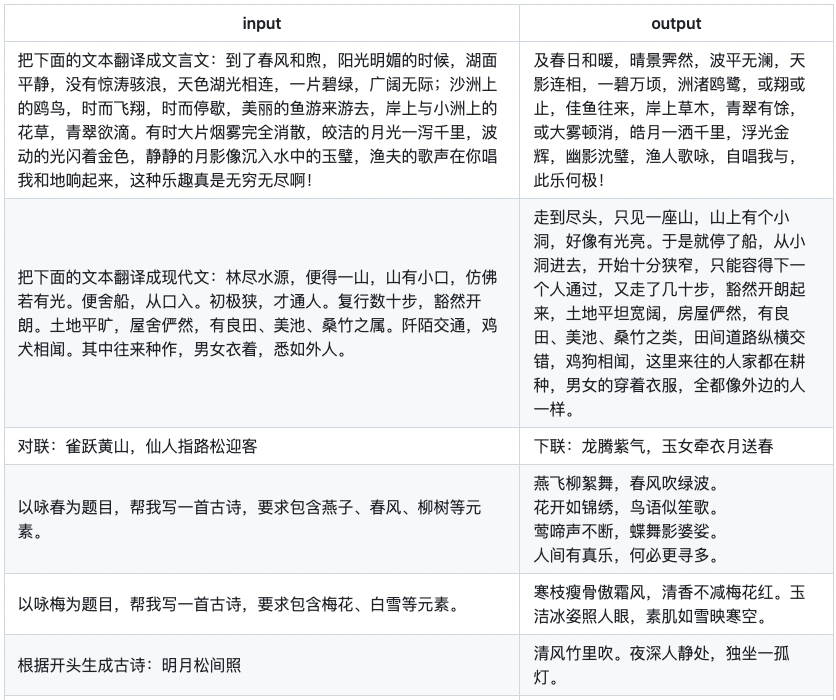
同樣,我們也對文言文、古詩詞、文章生成等數據進行了清洗,提高數據的質量。實測下來,我們發現firefly-2b6的生成效果,確實提升了不少。
數據質量的優化,對文言文翻譯任務的提升,尤為明顯。在訓練firefly-1b4時,文言文數據為較短的句子對。但在訓練firefly-2b6時,我們使用了較長篇幅的文本對。
下面為一些實測的例子。







文章小結
雖然firefly-2b6已經初步具備代碼生成能力,但由于訓練集中的代碼數據的數量不多,對于一些編程題,效果不如人意。我們覺得仍有非常大的優化空間,后續我們也將收集更多代碼數據,提升模型的代碼能力。
經過firefly-1b4和firefly-2b6兩個模型的迭代,能明顯感受到增加數據量、提升數據質量、增大模型參數量,對模型的提升非常大。
在前文中,我們提到,firefly-1b4在訓練數據量、訓練步數上都略有不足。為了探索"小"模型的效果上限,我們也將使用更多數量、更高質量的數據對firefly-1b4進行迭代。該項工作正在進行。
后續,我們也將在多輪對話、增大模型參數量、模型量化等方向上進行迭代,我們也將陸續開源訓練代碼以及更多的訓練數據。期待大家的意見和建議。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3751瀏覽量
52099 -
代碼
+關注
關注
30文章
4967瀏覽量
73960 -
語言模型
+關注
關注
0文章
571瀏覽量
11310
原文標題:中文對話式大語言模型Firefly-2b6開源,使用210萬訓練數據
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
什么是大模型,智能體...?大模型100問,快速全面了解!

openDACS 2025 開源EDA與芯片賽項 賽題七:基于大模型的生成式原理圖設計
NVIDIA ACE現已支持開源Qwen3-8B小語言模型
在Ubuntu20.04系統中訓練神經網絡模型的一些經驗
NVIDIA開源Audio2Face模型及SDK

米爾RK3576部署端側多模態多輪對話,6TOPS算力驅動30億參數LLM
OpenAI發布2款開源模型
ai_cube訓練模型最后部署失敗是什么原因?
【VisionFive 2單板計算機試用體驗】3、開源大語言模型部署
華為正式開源盤古7B稠密和72B混合專家模型
在阿里云PAI上快速部署NVIDIA Cosmos Reason-1模型
用PaddleNLP為GPT-2模型制作FineWeb二進制預訓練數據集

摩爾線程支持阿里云通義千問QwQ-32B開源模型




 工商網監
工商網監
評論