") NVIDIA 在 MLPerf 測試中將推理帶到新高度
NVIDIA 在 MLPerf 測試中將推理帶到新高度

在最新 MLPerf 基準(zhǔn)測試中,NVIDIA H100 和 L4 GPU 將生成式 AI 和所有其他工作負(fù)載帶到了新的水平,Jetson AGX Orin 則在性能和效率方面都有所提升。
作為獨立的第三方基準(zhǔn)測試,MLPerf 仍是衡量 AI 性能的權(quán)威標(biāo)準(zhǔn)。自 MLPerf 誕生以來,NVIDIA 的 AI 平臺在訓(xùn)練和推理這兩個方面一直展現(xiàn)出領(lǐng)先優(yōu)勢,包括最新發(fā)布的 MLPerf Inference 3.0 基準(zhǔn)測試。
NVIDIA 創(chuàng)始人兼首席執(zhí)行官黃仁勛表示:“三年前我們推出 A100 時,AI 世界由計算機視覺主導(dǎo)。如今,生成式 AI 已經(jīng)到來。”
“這正是我們打造 Hopper 的原因,其通過 Transformer 引擎專為 GPT 進(jìn)行了優(yōu)化。最新的 MLPerf 3.0 凸顯了 Hopper 的性能比 A100 高出 4 倍。”
“下一階段的生成式 AI 需要高能效的新的 AI 基礎(chǔ)設(shè)施來訓(xùn)練大型語言模型。客戶正在大規(guī)模采用 Hopper,以構(gòu)建由數(shù)萬顆通過 NVIDIA NVLink 和 InfiniBand 連接的 Hopper GPU 組成的 AI 基礎(chǔ)設(shè)施。”
“業(yè)界正努力推動安全、可信的生成式 AI 取得新的進(jìn)展。而 Hopper 正在推動這項重要的工作。”
最新 MLPerf 結(jié)果顯示,NVIDIA 將從云到邊緣的 AI 推理性能和效率帶到了一個新的水平。
具體而言,在 DGX H100 系統(tǒng)中運行的 NVIDIA H100 Tensor Core GPU 在每項 AI 推理測試(即在生產(chǎn)中運行神經(jīng)網(wǎng)絡(luò))中均展現(xiàn)出最高的性能。得益于軟件優(yōu)化,該 GPU 在 9 月首次亮相時就實現(xiàn)了高達(dá) 54%的性能提升。
針對醫(yī)療領(lǐng)域,H100 GPU 在 3D-UNet(MLPerf 醫(yī)學(xué)影像基準(zhǔn)測試)中的性能相比 9 月提高了 31%。
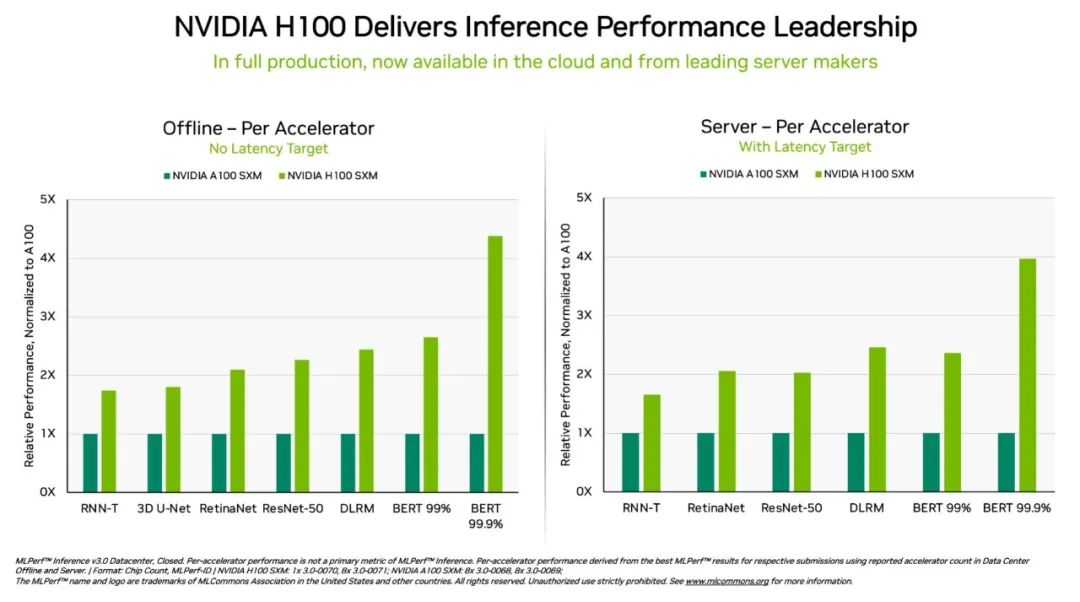
在 Transformer 引擎的加持下,基于 Hopper 架構(gòu)的 H100 GPU 在 BERT 上的表現(xiàn)十分優(yōu)異。BERT 是一個基于 transformer 的大型語言模型,它為如今已經(jīng)得到廣泛應(yīng)用的生成式 AI 奠定了基礎(chǔ)。
生成式 AI 使用戶可以快速創(chuàng)建文本、圖像、3D 模型等。從初創(chuàng)公司到云服務(wù)提供商,企業(yè)都在迅速采用這一能力,以實現(xiàn)新的業(yè)務(wù)模式和加速現(xiàn)有業(yè)務(wù)。
數(shù)億人現(xiàn)在正在使用 ChatGPT(同樣是一個 transformer 模型)等生成式 AI 工具,以期得到即時響應(yīng)。
在這個 AI 的 iPhone 時刻,推理性能至關(guān)重要。深度學(xué)習(xí)的部署幾乎無處不在,這推動了從工廠車間到在線推薦系統(tǒng)等對推理性能的無盡需求。
L4 GPU 精彩亮相
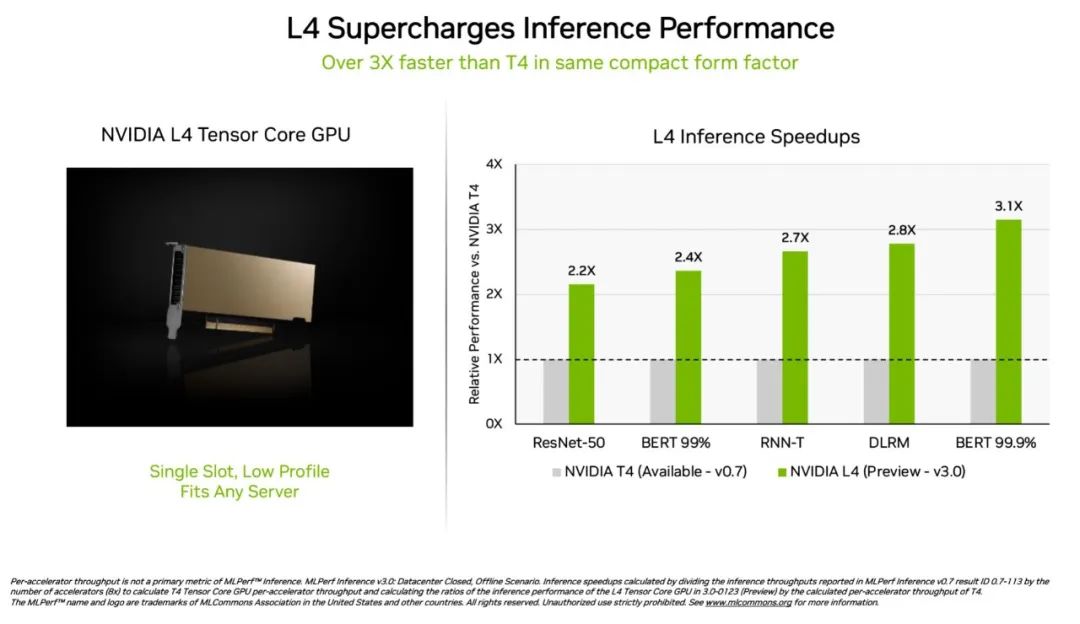
NVIDIA L4 Tensor Core GPU 在本次 MLPerf 測試中首次亮相,其速度是上一代 T4 GPU 的 3 倍以上。這些加速器具有扁平的外形,可在幾乎所有的服務(wù)器中提供高吞吐量和低延遲。
L4 GPU 運行了所有 MLPerf 工作負(fù)載。憑借對關(guān)鍵的 FP8 格式的支持,其在對性能要求很高的 BERT 模型上取得了非常驚人的結(jié)果。
除了出色的 AI 性能外,L4 GPU 的圖像解碼速度快了 10 倍,視頻處理速度快了 3.2 倍,同時圖形和實時渲染性能提高了 4 倍以上。
這些加速器兩周前在 GTC 上發(fā)布并已通過各大系統(tǒng)制造商和云服務(wù)提供商提供。L4 GPU 是 NVIDIA 在 GTC 上發(fā)布的 AI 推理平臺產(chǎn)品組合中的最新成員。
 ?
?軟件和網(wǎng)絡(luò)在系統(tǒng)測試中大放異彩
NVIDIA 的全棧式 AI 平臺在一項全新 MLPerf 測試中展現(xiàn)了其領(lǐng)先優(yōu)勢。
被稱之為 Network-division 的基準(zhǔn)測試將數(shù)據(jù)傳輸至一個遠(yuǎn)程推理服務(wù)器。它反映了企業(yè)用戶將數(shù)據(jù)存儲在企業(yè)防火墻后面、在云上運行 AI 作業(yè)的熱門場景。
在 BERT 測試中,遠(yuǎn)程 NVIDIA DGX A100 系統(tǒng)提供高達(dá) 96%的最大本地性能,其性能下降的原因之一是因為它們需要等待 CPU 完成部分任務(wù)。在單純依靠 GPU 進(jìn)行處理的 ResNet-50 計算機視覺測試中,它們達(dá)到了 100%的性能。
這兩個結(jié)果在很大程度上要歸功于 NVIDIA Quantum InfiniBand 網(wǎng)絡(luò)、NVIDIA ConnectX SmartNIC 以及 NVIDIA GPUDirect 等軟件。
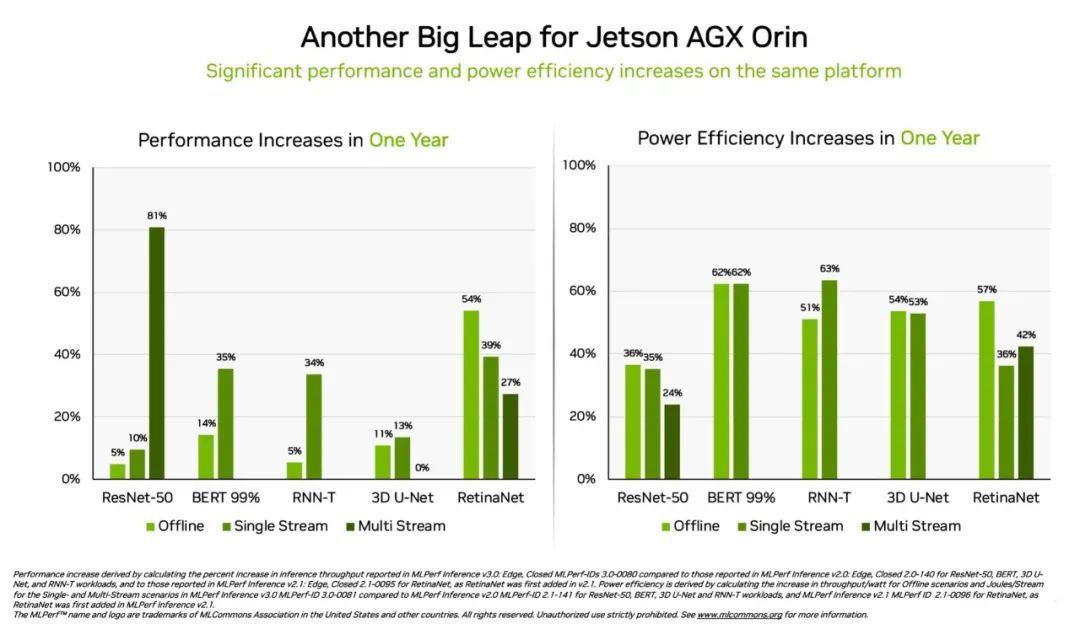
Orin 在邊緣的性能提升 3.2 倍
另外,相較于一年前的結(jié)果,NVIDIA Jetson AGX Orin 模塊化系統(tǒng)的能效提高了 63%,性能提高了 81%。Jetson AGX Orin 可在需要 AI 的狹小空間內(nèi)以低功率進(jìn)行推理,包括在由電池供電的系統(tǒng)上。
專為需要更小模塊、更低功耗的應(yīng)用而開發(fā)的 Jetson Orin NX 16G 在本次基準(zhǔn)測試中首次亮相便大放異彩。其性能是上一代 Jetson Xavier NX 處理器的 3.2 倍。
廣泛的 NVIDIA AI 生態(tài)
MLPerf 結(jié)果顯示,NVIDIA AI 得到了業(yè)內(nèi)最廣泛的機器學(xué)習(xí)生態(tài)系統(tǒng)的支持。
在這一輪測試中,有十家公司在 NVIDIA 平臺上提交了結(jié)果,包括華碩、戴爾科技、技嘉、新華三、聯(lián)想、寧暢、超微和超聚變等系統(tǒng)制造商和微軟 Azure 云服務(wù)。
他們所提交的結(jié)果表明,無論是在云端還是在自己的數(shù)據(jù)中心運行的服務(wù)器中,用戶都可以通過 NVIDIA AI 獲得出色的性能。
NVIDIA 的眾多合作伙伴也參與了 MLPerf,因為他們知道這是一個幫助客戶評估 AI 平臺和廠商的很有價值的工具。最新一輪結(jié)果表明,他們今天所提供的性能將隨著 NVIDIA 平臺的發(fā)展而不斷提升。
用戶需要的是“多面手”
NVIDIA AI 是唯一能夠在數(shù)據(jù)中心和邊緣計算中運行所有 MLPerf 推理工作負(fù)載和場景的平臺。其全面的性能和效率讓用戶能夠成為真正的贏家。
用戶在實際應(yīng)用中通常會采用許多不同類型的神經(jīng)網(wǎng)絡(luò),這些網(wǎng)絡(luò)往往需要實時提供答案。
例如,一個 AI 應(yīng)用可能需要先理解用戶的語音請求,對圖像進(jìn)行分類、提出建議,然后以人聲作為語音來回答用戶。每個步驟都需要用到不同類型的 AI 模型。
MLPerf 基準(zhǔn)測試涵蓋了這些以及其他流行的 AI 工作負(fù)載,所以這些測試能夠確保 IT 決策者獲得可靠且可以靈活部署的性能。
用戶可以根據(jù) MLPerf 的結(jié)果做出明智的購買決定,因為這些測試是透明的、客觀的。該基準(zhǔn)測試得到了包括 Arm、百度、Facebook AI、谷歌、哈佛大學(xué)、英特爾、微軟、斯坦福大學(xué)和多倫多大學(xué)在內(nèi)的廣泛支持。
可以使用的軟件
NVIDIA AI 平臺的軟件層 NVIDIA AI Enterprise 確保用戶能夠從他們的基礎(chǔ)設(shè)施投資中獲得最佳的性能以及在企業(yè)數(shù)據(jù)中心運行 AI 所需的企業(yè)級支持、安全性和可靠性。
這些測試所使用的所有軟件都可以從 MLPerf 庫中獲得,因此任何人都可以獲得這些領(lǐng)先的結(jié)果。
各項優(yōu)化措施不斷地被整合到 NGC(NVIDIA 的 GPU 加速軟件目錄)上的容器中。本輪測試中提交的每項工作均使用了該目錄中的 NVIDIA TensorRT 優(yōu)化 AI 推理性能。
掃描海報二維碼,或點擊“閱讀原文”,即可觀看 NVIDIA 創(chuàng)始人兼首席執(zhí)行官黃仁勛 GTC23 主題演講重播!
原文標(biāo)題:NVIDIA 在 MLPerf 測試中將推理帶到新高度
文章出處:【微信公眾號:NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
23文章
4087瀏覽量
99217
原文標(biāo)題:NVIDIA 在 MLPerf 測試中將推理帶到新高度
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
AI定義座艙新高度|搭載天璣座艙S1 Ultra的奇瑞風(fēng)云T9L

共推鴻蒙生態(tài)邁向新高度!拓維信息攜開鴻智谷亮相開源鴻蒙行業(yè)論壇

NVIDIA TensorRT LLM 1.0推理框架正式上線
NVIDIA Nemotron Nano 2推理模型發(fā)布

華為助力埃塞俄比亞電信通信網(wǎng)絡(luò)技術(shù)邁向新高度
海格天乘推動低空經(jīng)濟產(chǎn)業(yè)發(fā)展邁向新高度
麥格米特與鴻路鋼構(gòu)合作邁入全新高度
2.5MW全球首發(fā),綠能慧充引領(lǐng)行業(yè)新高度!




 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論