 奔向大模型時代,存算一體成為突破算力瓶頸的關鍵技術?
奔向大模型時代,存算一體成為突破算力瓶頸的關鍵技術?

電子發燒友網報道(文/李彎彎)大模型的訓練和推理需要高性能的算力支持。以ChatGPT為例,據估算,在訓練方面,1746億參數的GPT-3模型大約需要375-625臺8卡DGXA100服務器訓練10天左右,對應A100GPU數量約3000-5000張。
在推理方面,如果以A100GPU單卡單字輸出需要350ms為基準計算,假設每日訪問客戶數量高達5,000萬人時,按單客戶每日發問ChatGPT應用10次,單次需要50字回答,則每日消耗GPU的計算時間將會高達243萬個小時,對應的GPU需求數量將超過10萬個。
大模型的訓練和推理依賴通用GPU
算力即計算能力,具體指硬件對數據收集、傳輸、計算和存儲的能力,算力的大小表明了對數字化信息處理能力的強弱,常用計量單位是FLOPS(Floating-pointoperationspersecond),表示每秒浮點運算次數。
當前大模型的訓練和推理多采用GPGPU。GPGPU是一種由GPU去除圖形處理和輸出,僅保留科學計算、AI訓練和推理功能的GPU。GPU芯片最初用于計算機系統圖像顯示的運算,但因其相比于擅長橫向計算的CPU更擅長于并行計算,在涉及到大量的矩陣或向量計算的AI計算中很有優勢,GPGPU應運而生。
在這波ChatGPT浪潮中長期押注AI的英偉達可以說受益最多,ChatGPT、包括各種大模型的訓練和推理,基本都采用英偉達的GPU。目前國內多個廠商都在布局GPGPU,包括天數智芯、燧原科技、壁仞科技、登臨科技等,不過當前還較少能夠應用于大模型。
事實上業界認為,隨著模型參數越來越大,GPU在提供算力支持上也存在瓶頸。在GPT-2之前的模型時代,GPU內存還能滿足AI大模型的需求,近年來,隨著Transformer模型的大規模發展和應用,模型大小每兩年平均增長240倍,實際上GPT-3等大模型的參數增長已經超過了GPU內存的增長。傳統的設計趨勢已經不能適應當前的需求,芯片內部、芯片之間或AI加速器之間的通信成為了AI計算的瓶頸。
存算一體技術如何突破算力瓶頸
而存算一體作為一種新型架構形式受到關注,存算一體將存儲和計算有機結合,直接在存儲單元中處理數據,避免了在存儲單元和計算單元之間頻繁轉移數據,減少了不必要的數據搬移造成的開銷,不僅大幅降低了功耗,還可以利用存儲單元進行邏輯計算提高算力,顯著提升計算效率。
大模型的訓練和部署不僅對算力提出了高要求,對能耗的要求也很高,從這個角度來看,存算一體降低功耗,提升計算效率等特性在大模型方面確實更具優勢。
因為獨具優勢,過去幾年已經有眾多企業進入到存算一體領域,包括知存科技、千芯科技、蘋芯科技、后摩智能、億鑄科技等。各企業的技術方向也有所不同,從介質層面來看,有的采用NORFlash,有的采用SRAM,也有的采用RRAM。
從目前的情況來看,基于NORFlash的存算一體產品,在算力上難以做大,應用場景主要是對算力要求不高,對功耗要求高的可穿戴設備等領域;基于SRAM的存算一體算力可以更大些,能夠用于自動駕駛領域;而真正能夠在算力上實現突破,可以稱之為大算力AI芯片的,目前只有億鑄科技主推的基于RRAM的存算一體技術。
在大模型對大算力的需求背景下,億鑄科技近期更是提出了存算一體超異構計算。超異構計算能夠把更多的異構計算整合重構,從而各類型處理器間充分地、靈活地進行數據交互而形成的計算。
簡單來說,就是結合DSA、GPU、CPU、CIM等多個類型引擎的優勢,實現性能的飛躍:DSA負責相對確定的大計算量的工作;GPU負責應用層有一些性能敏感的并且有一定彈性的工作;CPU啥都能干,負責兜底;CIM就是存內計算,超異構和普通異構的主要區別就是加入了CIM,由此可以實現同等算力,更低能耗,同等能耗,更高算力。另外,CIM由于器件的優勢,能負擔比DSA更大的算力。
億鑄科技創始人、董事長兼CEO熊大鵬博士表示,存算一體超異構計算的好處在于:一是在系統層,能夠把整體的效率做到最優;二是在軟件層,能夠實現跨平臺架構統一。
基于存算一體超異構概念,億鑄科技提出了自己的技術暢想:若能把新型憶阻器技術(RRAM)、存算一體架構、芯粒技術(Chiplet)、3D封裝等技術結合,將會實現更大的有效算力、放置更多的參數、實現更高的能效比、更好的軟件兼容性、從而突破性能瓶頸,抬高AI大算力芯片的發展天花板。
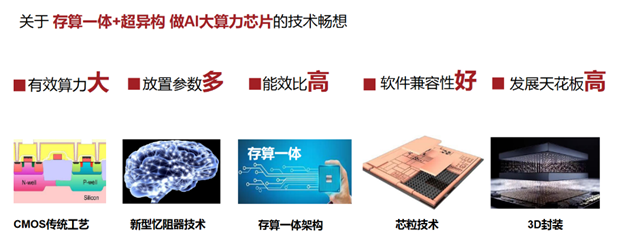
圖源:億鑄科技
目前國內已公開的能夠實現存算一體AI大算力的芯片公司僅有億鑄科技,其基于RRAM的存算一體AI大算力芯片將在今年回片。
小結
無論是大模型的訓練還是部署,對大算力芯片的需求都很大,從目前的情況來看,大模型的訓練在很長時間都將要依賴于英偉達的GPU芯片。
而在大模型的推理部署方面,除了GPU,存算一體將是非常合適的選擇。未來大模型的部署規模會很大,從前不久英偉達專門推出適合大型語言模型部署的芯片平臺也能看出來。據億鑄科技透露,公司規劃的產品,在同等功耗下,性能將超越英偉達H100系列的推理芯片。
-
AI
+關注
關注
91文章
39793瀏覽量
301407 -
大數據
+關注
關注
64文章
9063瀏覽量
143757 -
存算一體
+關注
關注
1文章
121瀏覽量
5135 -
大模型
+關注
關注
2文章
3650瀏覽量
5183
發布評論請先 登錄

曙光存儲兩大核心技術與全棧產品矩陣推動存力范式革新
算力革命下的隱形基石:存算一體時代呼喚更精準的“時間心跳”


載譽而歸 | 蘋芯科技斬獲AABI火炬技術轉移獎,存算一體技術探索跨境創新合作

后摩爾定律時代,3D-CIM+RISC-V打造國產存算一體新范式

在TR組件優化與存算一體架構中構建技術話語權
存算一體技術加持!后摩智能 160TOPS 端邊大模型AI芯片正式發布

一文看懂AI算力集群

緩解高性能存算一體芯片IR-drop問題的軟硬件協同設計
國際首創新突破!中國團隊以存算一體排序架構攻克智能硬件加速難題

蘋芯科技 N300 存算一體 NPU,開啟端側 AI 新征程
存力接棒算力,慧榮科技以主控技術突破AI存儲極限




 工商網監
工商網監
評論