") 微軟發(fā)布Visual ChatGPT:視覺模型加持ChatGPT實現(xiàn)絲滑聊天
微軟發(fā)布Visual ChatGPT:視覺模型加持ChatGPT實現(xiàn)絲滑聊天

近來,AI領(lǐng)域迎來各個領(lǐng)域的大突破,ChatGPT展現(xiàn)出強大的語言問答能力和推理能力,然而作為一個自然語言模型,它無法處理視覺信息。
與此同時,視覺基礎(chǔ)模型如Visual Transformer或者Stable Diffusion等,則展現(xiàn)出強大的視覺理解和生成能力。
Visual Transformer將ChatGPT作為邏輯處理中心,集成若干視覺基礎(chǔ)模型,從而達到如下效果:
視覺聊天系統(tǒng)Visual ChatGPT可以接收和發(fā)送文本和圖像
提供復(fù)雜的視覺問答,或者視覺編輯指令,可以通過多步推理調(diào)用工具來解決復(fù)雜視覺任務(wù)
可以提供反饋,總結(jié)答案,主動詢問模糊的指令等
這個工作開啟了ChatGPT借助視覺基礎(chǔ)模型作為工具,進行視覺任務(wù)處理的研究方向。
論文鏈接:
https://arxiv.org/abs/2303.04671
開源代碼:
https://github.com/microsoft/visual-chatgpt
論文作者:
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
機構(gòu):微軟亞洲研究院
模型效果
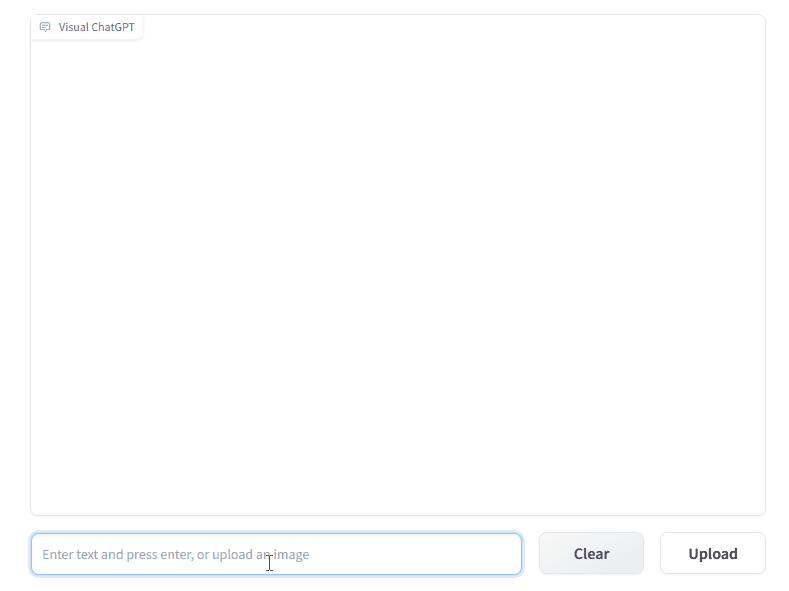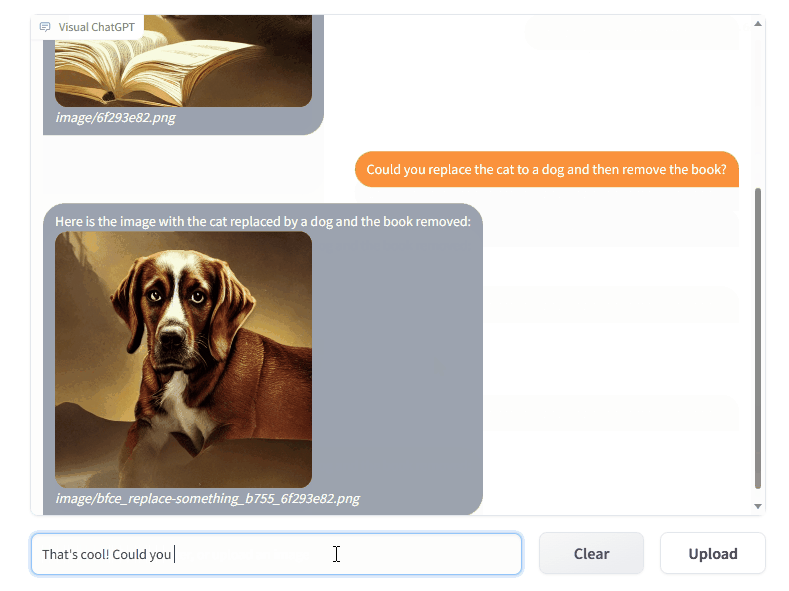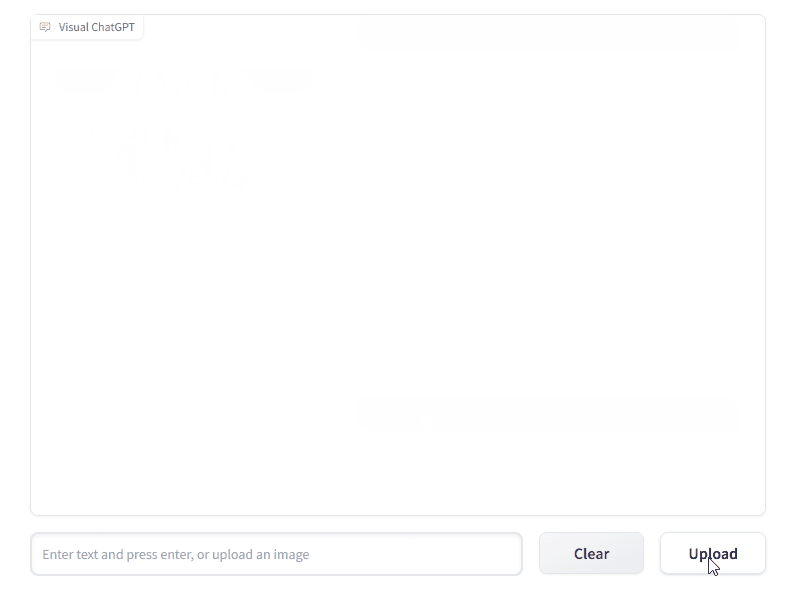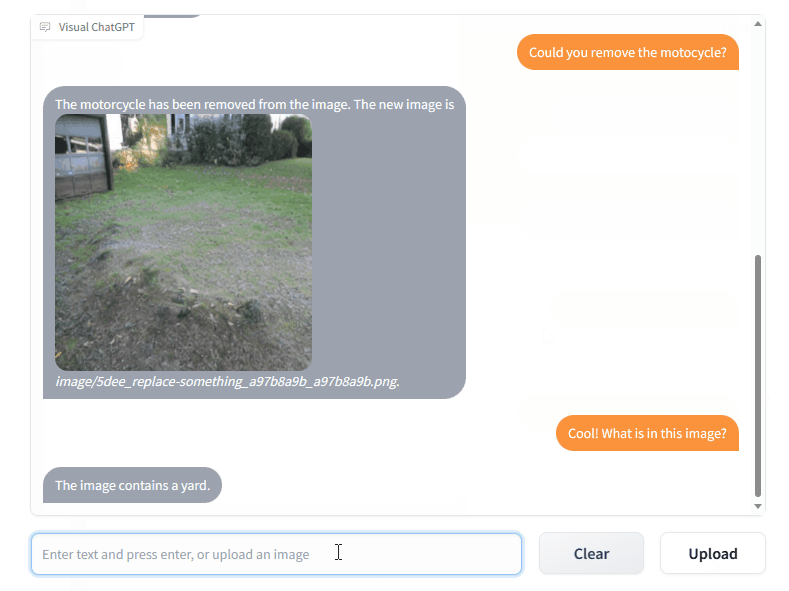
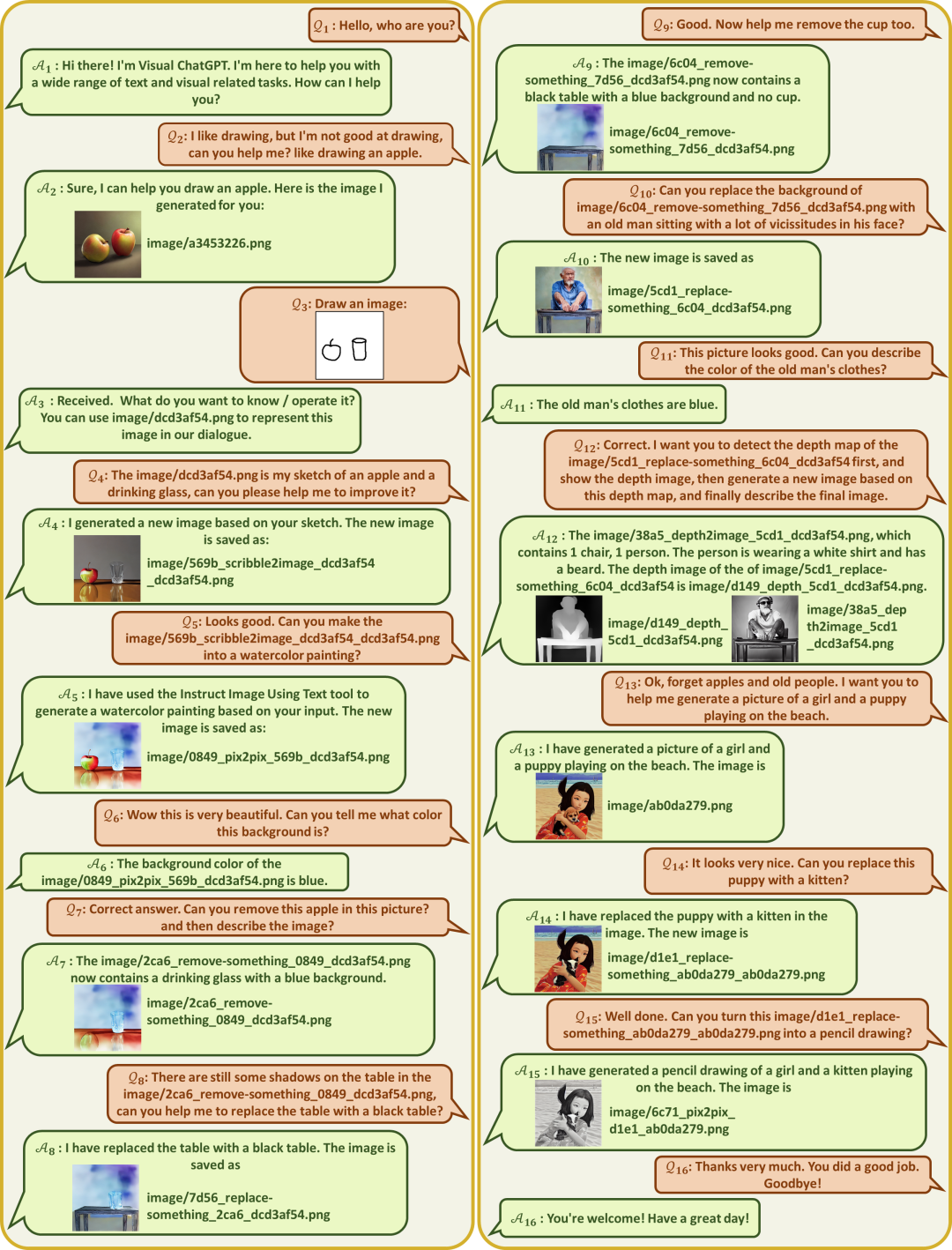
工作流程
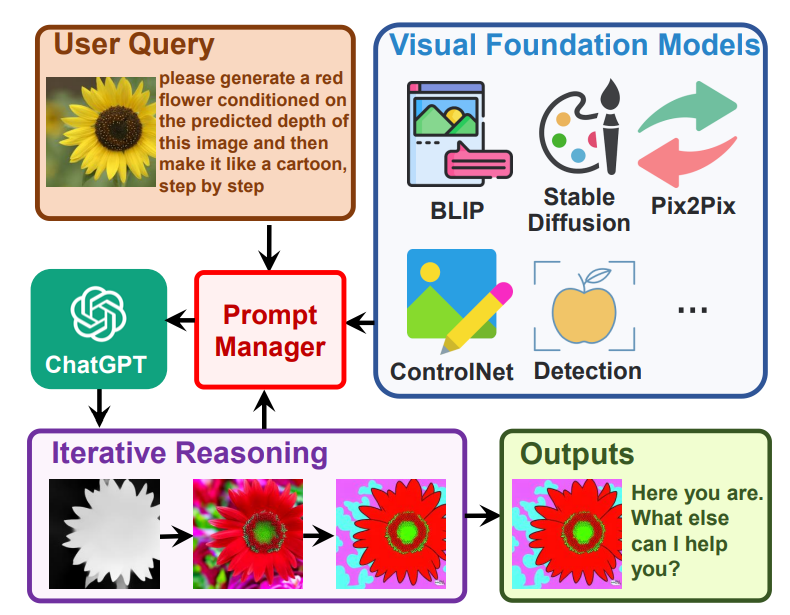
記對話,第i輪的回復(fù),是通過若干次思考調(diào)用工具的結(jié)果來最終總結(jié)出來的。我們記第i輪對話中,第j次的工具調(diào)用中間答案記作,那么
其中,是全局原則,是各個視覺基礎(chǔ)模型,是歷史會話記憶,是這一輪的用戶輸入,是這輪對話里思考和的歷史,是中間答案,是prompt manager,用于把上面各個功能轉(zhuǎn)化成合理的文本prompt,從而可以交給ChatGPT進行處理。以下圖為例進行講解:
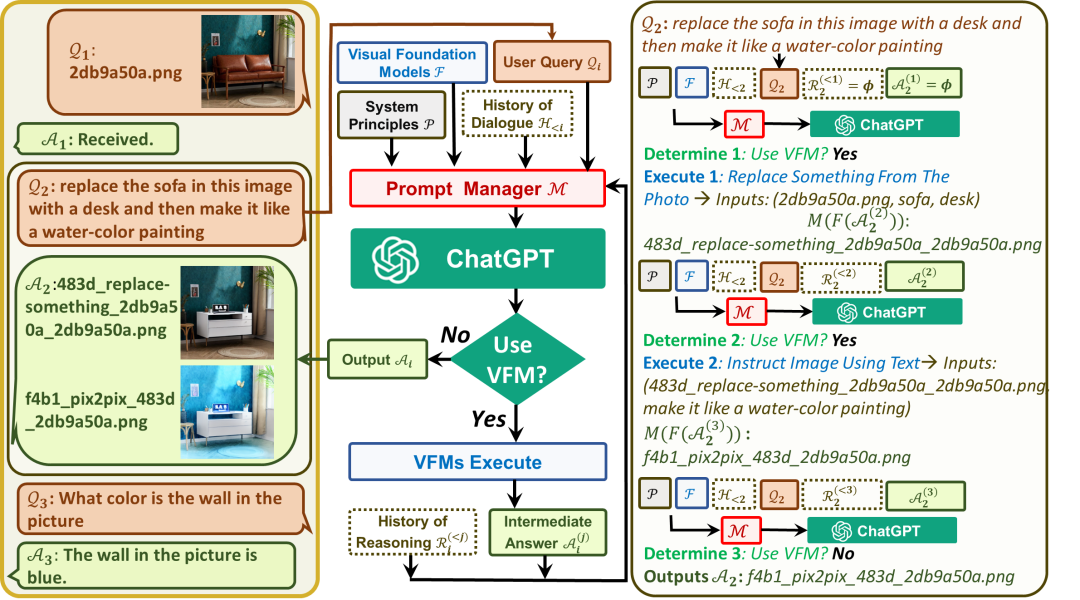
對于用戶輸入,添加于全局原則prompt,工具描述prompt,歷史會話prompt之后,送給ChatGPT進行邏輯推理(Use VFM?)得到推理結(jié)果(就是這一次得到的GPT文本輸出)。經(jīng)過正則匹配進行分析,如果工具調(diào)用結(jié)束,則直接提取總結(jié)輸出作為最終回復(fù),如果是需要繼續(xù)調(diào)用工具,則將提取到的工具名稱、工作參數(shù),輸入視覺基礎(chǔ)模型,從而得到,置于思考?xì)v史中,進行下一輪推理。或者說喂給GPT的內(nèi)容為:
第一次問答里,第一個API:
第一次問答里,第二個API:
第一次問答里,第三個API:
第二次問答里,第一個API:
第二次問答里,第二個API:
得到GPT的輸出后,正則匹配進行工具的判斷和解析,最終決定流程。API調(diào)用歷史在每次回答后清空,其中只有最后總結(jié)性的回復(fù)被記錄進入對話歷史
細(xì)節(jié)描述
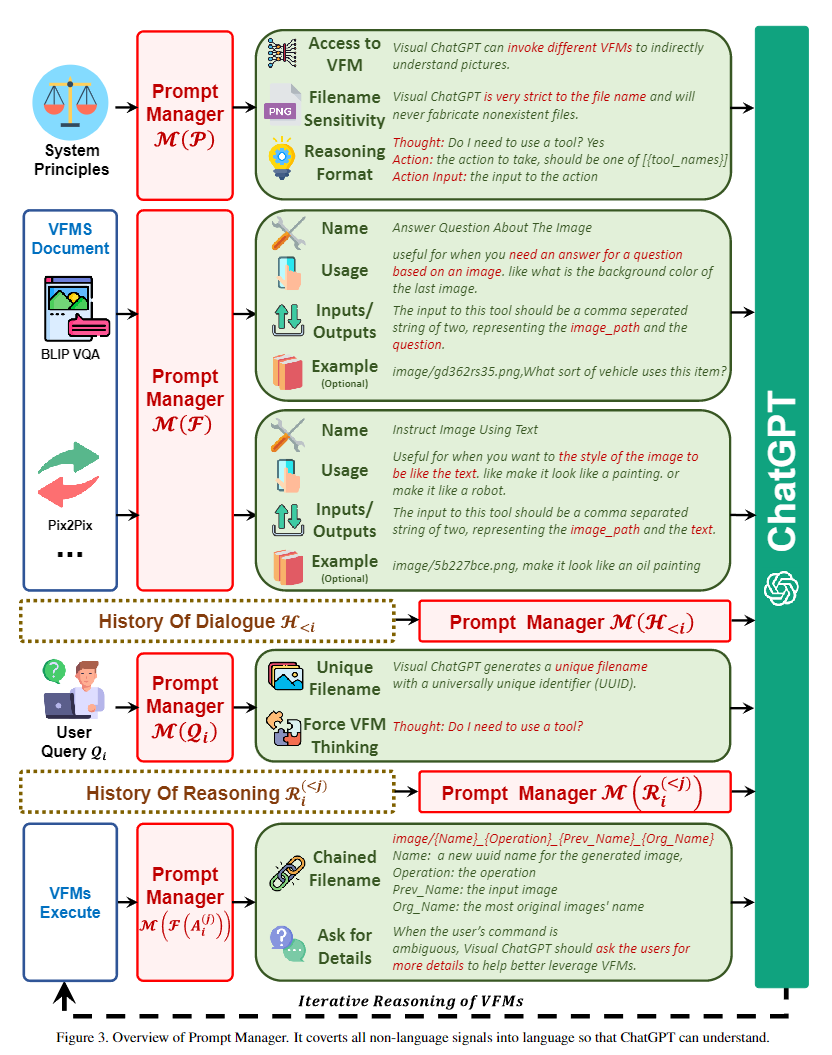
: 系統(tǒng)原則的提示符,“Visual ChatGPT是一個可以處理廣泛語言和視覺任務(wù)的助手,xxxxxx”。在這個prompt的部分,以下內(nèi)容被強調(diào):Visual ChatGPT的角色,可以訪問且需要盡可能使用視覺基礎(chǔ)模型,要對文件名稱非常敏感不可以捏造,可以且必須遵循嚴(yán)格的Chain-of-Thought思考鏈的格式進行思考(不然正則匹配不出來是否使用函數(shù)和函數(shù)名稱參數(shù)),可靠性等描述。
: 對每個視覺基礎(chǔ)模型的描述,包含工具名稱,使用方法,輸入輸出格式,實例
: 用戶的輸入會被改寫,用來理解圖片和強制GPT思考
:對輸出的處理,鏈?zhǔn)降奈募?imaga/{Name}_{Operation}_{Prev_Name}_{Org_Name}.png",強制修改GPT內(nèi)容,讓GPT降低思考難度,在指代不清時二次詢問用戶等。
Case Study
論文分析了在各個模塊,如果prompt manager設(shè)計不到位,會各自出現(xiàn)什么問題:
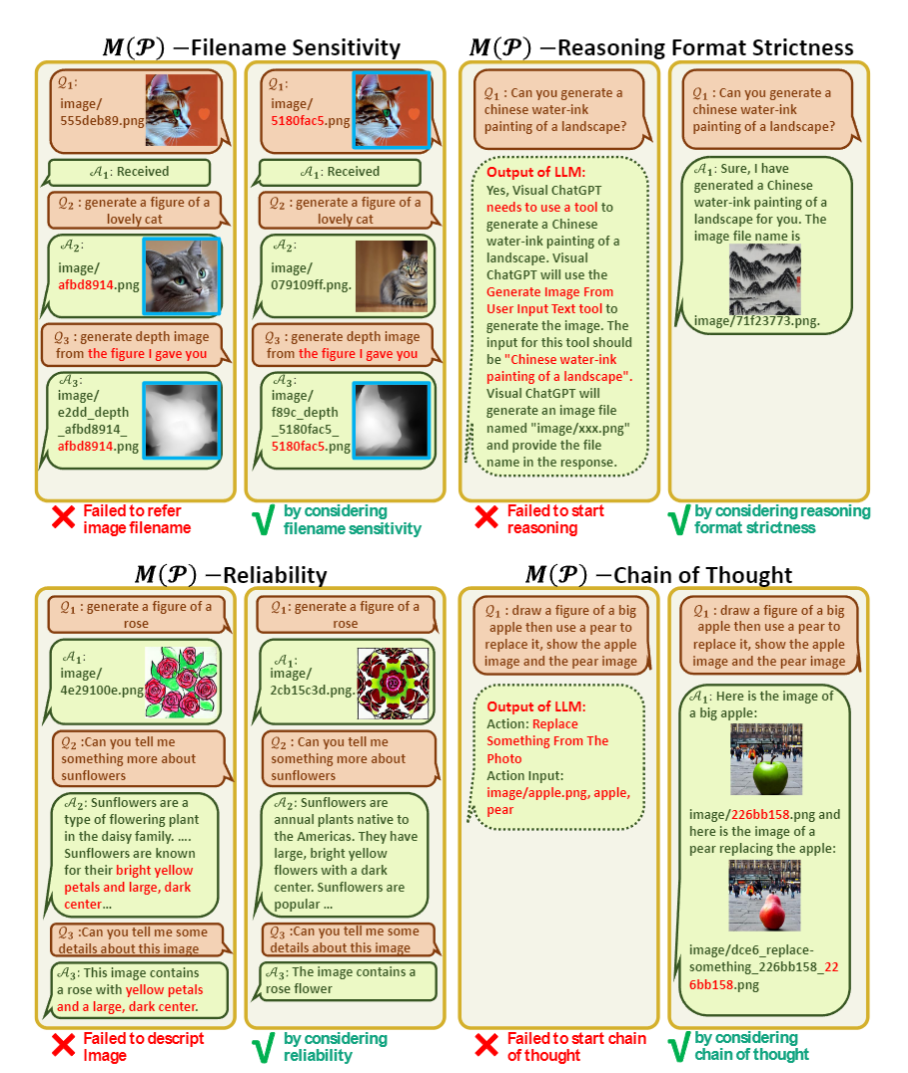
在中,如果不強調(diào)對圖片文件名的敏感,可能會發(fā)生指代錯誤。如果不強調(diào)思考鏈的格式嚴(yán)格,可能正則匹配匹不上。如果不強調(diào)可靠性,不要基于文本上下文腦補,可能會出現(xiàn)不讀圖片直接回答的情況。如果不強調(diào)可以鏈?zhǔn)绞褂霉ぞ撸瑒t可能出現(xiàn)一口吃個大胖子而不能一步一步思考的情況。
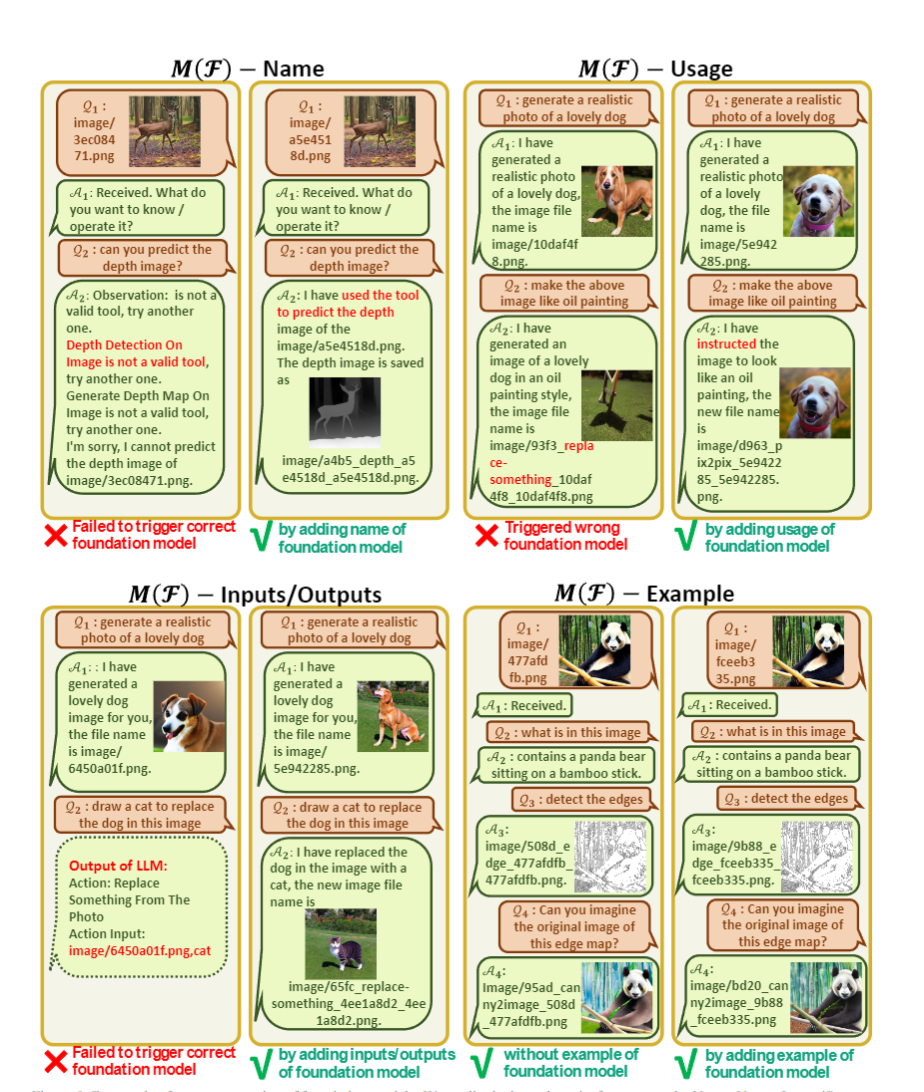
類似的,對于工具包的描述,也應(yīng)該對名稱、功能、輸入輸出格式進行嚴(yán)格的設(shè)計。其中,for example進行舉例影響不大,只要前面描述足夠清楚,GPT可以理解,可以刪掉保存token長度。
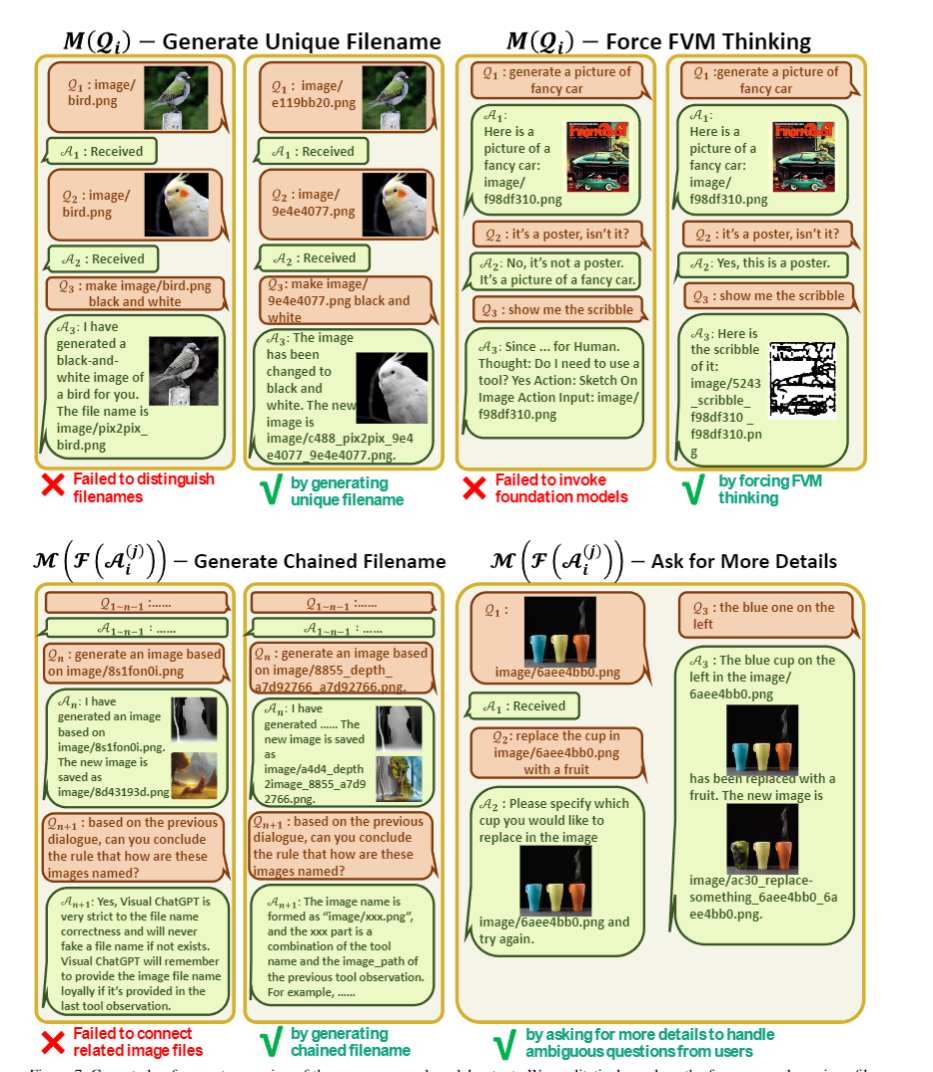
對于用戶輸入和工具包輸出的后處理,如圖。比較神奇的是,右上角的舉例里,用ChatGPT自己的口吻來說一些原則(從而讓ChatGPT以為是它自己說的,然后順著說),以及直接讓ChatGPT說到"Thought: Do I need a tool"繼續(xù)生成,能強制進入思考鏈,從而大幅度降低思考難度。左下角的舉例里,對于鏈?zhǔn)降奈募瑔朧isual ChatGPT能不能總結(jié)出來文件命名原則,基本總結(jié)正確,這說明此種命名方法,確實可以幫助Visual ChatGPT理解文件的內(nèi)容和依賴關(guān)系,生成路徑。
有意義的啟發(fā)
開啟了ChatGPT處理視覺任務(wù)的新大門
NLP --> Natural Language PhotoShop,自然語言文本描述下的圖片創(chuàng)作編輯和問答
可以通過系統(tǒng)設(shè)計和工具包設(shè)計的Prompt,做到無監(jiān)督的工具調(diào)用,類似于zero-shot的toolformer
ChatGPT本身對仿真場景的能力很強,也讀過圖片路徑和函數(shù)關(guān)系,從而善于使用基礎(chǔ)視覺模型
Prompt很重要,作為純語言模型,前文說它是啥他就仿照啥,除了細(xì)致的要求,一定要多夸一夸他,是能力很強的處理模型,那它順著說,能力才會真的強
Visual ChatGPT本身是一個語言模型,所謂的兩方多輪對話只是一個Human: AI: 的多輪特殊形式前文的繼續(xù)生產(chǎn),所以,完全可以強行給前文AI: 讓ai自己說一些東西出來,是它信了是它自己說的,這能夠極大的降低生成難度。這在本篇論文里對幾個場景的幫助很大。例如,用戶輸入圖片后,改寫為“Human: 上傳了一張圖片,描述為:{}。注意,這里的描述是幫助你理解圖片的,你不能基于它幻想而不調(diào)用工具。如果你理解了,就恢復(fù)收到。AI:收到。”注意,這里AI回復(fù)的收到,并不是真的GPT的生成內(nèi)容,而是我們強行寫入進dialogue history memory的,而且可以發(fā)現(xiàn),AI真的相信了。另外一個點是,在用戶的輸入后面,挨著的應(yīng)該是GPT自己的思考內(nèi)容,如果我們借它的口,自己說“推理信息僅自己可見,需要在最后總結(jié)的時候把重要信息復(fù)述給讀者”,效果比在最前文的prompt里效果好很多,可能是因為距離的原因,也可能是AI自己說出來的原因。另外,可以直接給到"Thought: do i need a tool?"去讓GPT繼續(xù)生成,從而一定進入推理鏈,可以匹配到遠處描述思維鏈格式的prompt內(nèi)容,極大的降低思考難度。
外網(wǎng)評價



審核編輯 :李倩
-
微軟
+關(guān)注
關(guān)注
4文章
6741瀏覽量
107852 -
AI
+關(guān)注
關(guān)注
91文章
39760瀏覽量
301366 -
ChatGPT
+關(guān)注
關(guān)注
31文章
1598瀏覽量
10264
原文標(biāo)題:微軟發(fā)布Visual ChatGPT:視覺模型加持ChatGPT實現(xiàn)絲滑聊天
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
巨頭競逐AI醫(yī)療健康:OpenAI推出ChatGPT Health,螞蟻阿福國內(nèi)領(lǐng)跑
今日看點|黃仁勛:物理AI的ChatGPT時刻已然到來;波士頓動力發(fā)布Atlas人形機器人量產(chǎn)版本
上線!國產(chǎn)AI語音開發(fā)板,定制你的聊天伙伴助手
微軟Visual Studio 2026 發(fā)布!AI 深度融合、性能提升

滑臺模組如何實現(xiàn)電子制造精密加工?


ChatGPT 智能體發(fā)布的觀點解析及對科義相關(guān)系統(tǒng)的現(xiàn)實意義
有源銅纜:大模型背后的隱形英雄

AI真會人格分裂!OpenAI最新發(fā)現(xiàn),ChatGPT善惡開關(guān)已開啟

樹莓派與EthernetHat:用ChatGPT實現(xiàn)的MQTT智能家居項目!

樹莓派遇上ChatGPT,魔法熱線就此誕生!

?VLM(視覺語言模型)?詳細(xì)解析


能和Ai-M61模組對話了?手搓一個ChatGPT 語音助手



 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論